一种基于网络表示学习的网约共享出行人员匹配方法与流程
本发明属于群体推荐领域,具体涉及一种基于网络表示学习的网约共享出行人员匹配方法。
背景技术:
随着网约车平台和app的日益发展,共乘出行逐渐被大众认知和接受,同时随着相关出行技术的发展,例如出行路线匹配、出行群体发现、路线规划、出行行为分析等相关工作的研究,共乘也成为了一种方便可行的出行模式。通过对共乘匹配的研究可以为用户提供更好的出行体验和更高的出行效率。
网络表示学习以及共乘出行的使用与影响使得共乘匹配方法的研究受到了很多的关注。在共乘匹配的研究中,主要的问题是如何将乘客准确地分配给司机,以及如何将不同出行群体之间的共乘匹配最优化。传统的匹配方法仅仅依赖于乘客和驾驶员之间的地理距离,并没有考虑到乘客或驾驶员与其他特征的关系,比如出行者和目的地、时间之间的关系。而异构信息网络能为共乘匹配提供更加有效的分析方法。因此通过利用用户、时间与地点位置信息构建的异构网络来从共乘信息中学习潜在语义,并且从用户轨迹和情感中提取特征,可以更好地为用户提供合适的共乘匹配关系。
技术实现要素:
针对共乘出行的用户匹配问题,本发明的目的是提出一种基于网络表示学习的网约共享出行人员匹配方法。本发明采用异构信息网络中的元路径理论,将司机与乘客之间的匹配转换为异质共乘网络中节点的相似性度量问题,建立基于“司机-乘客”结构的共乘行为特征模型,并根据不同的共乘情况将模型分为端点共乘和沿途共乘。模型从司机和乘客各自的出发时间、上下车位置出发,结合机器学习中的skip-gram模型,分析特征间关系,推理司机和乘客间的共乘可能性,为共乘出行的优质服务提供支持。
为实现上述目的,本发明采用如下的技术方案:
一种基于网络表示学习的网约共享出行人员匹配方法,包括以下步骤:
步骤一:共乘分类
在司机原始路径确定的情况下,根据乘客的起点和终点与司机原始路径的关系,将共乘分为两类:第一类是端点共乘,乘客的起点和终点在司机的原始路径上;另一类是沿途共乘,乘客的起点和终点都不在司机的原始路径上,乘客需要从起点步行至上车点,然后达成共乘,再由下车点步行至目的地,共乘路径轨迹是乘客轨迹的一部分;
步骤二:构建异质共乘网络
将司机与乘客的请求信息表示为异质共乘网络形式,乘客与司机之间通过位置与时间信息相连接,从而构建异质共乘网络,该异质共乘网络中节点的类型包括用户、地点、时间段以及活动;
步骤三:使用网络表示学习模型对异质共乘网络进行表示学习,得到用户节点的低维向量表示;
步骤四:根据用户节点的低维向量表示计算司机与乘客节点的余弦相似度,并将计算得到的余弦相似值由大到小排序,返回与司机相似度数值最高的前k个乘客,作为可以共乘的乘客,达成共乘。
本发明进一步的改进在于,步骤一中,司机与乘客的请求信息包括司机起点和终点、离开时间、司机轨迹、上下车位置、乘客起点和终点以及上下车时间。
本发明进一步的改进在于,步骤二中,异质共乘网络中节点的类型包括用户、地点、时间段以及活动。
本发明进一步的改进在于,步骤三中,进行表示学习的过程具体包括以下两个步骤:
1)生成节点序列集:元路径指导节点在异质共乘网络中的游走,生成固定长度的节点序列集;
2)将生成的固定长度的节点序列集输入到skip-gram模型中进行训练,获取司机与乘客节点的向量表示。
本发明进一步的改进在于,步骤1)中,对于端点共乘,构建结构为ultlu的元路径;对于沿途共乘,在时间段相同的约束下,构建结构为ulu的元路径。
本发明进一步的改进在于,步骤三中,进行表示学习的具体过程如下:
首先,给定具体的元路径
其中,na(vu)是节点vu邻居节点的集合,
在假设各个节点间相互独立的情况下,在已知中心节点的条件下,上下文的条件概率为logp(vj-c,…,vj+c|vu;θ)进一步分解为
其中
根据给定节点vu的上下文节点vk的条件概率生成表示向量,再采用负采样来优化表示向量,得到异质共乘网络中每个用户节点的低维向量表示。
本发明进一步的改进在于,随机游走的游走概率
公式(1)中,a表示节点类型,
公式(2)表示选取的元路径均为对称元路径。
本发明进一步的改进在于,采用负采样来优化表示向量的具体过程如下:
其中
然后使用随机梯度下降方法使得对数似然函数
其中
与现有技术相比,本发明的有益效果在于:
与普通的共乘推荐机制不同,本发明采用乘客和司机的地点和时间信息构造共乘异构网络,并区分出两种不同的共乘类型。对这两种类型选取生成对称元路径,并针对不同的共乘类型对元路径序列集的生成添加了不同的限制。通过负采样skip-gram对序列集进行表示学习,生成表示向量,最后使用余弦相似度计算用户表示向量间的相似值进行共乘推荐。本发明提出的共乘推荐方法比传统的仅使用距离推荐的方法更加可靠,语义理解性直观,能够准确发现潜在的共乘用户,为其提供更为快捷方便的服务。
附图说明
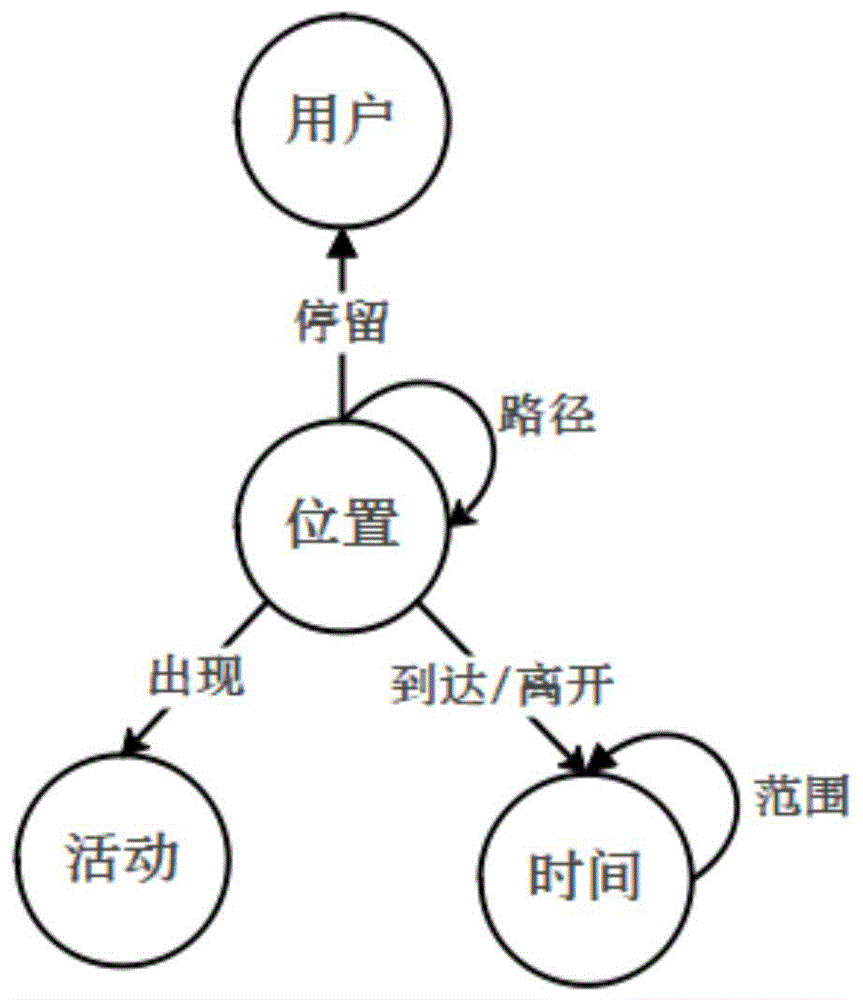
图1为本发明构建的异质共乘网络的拓扑结构图。
具体实施方式
以下结合附图对本发明提出的共乘匹配方法进行具体说明。
本发明的一种基于网络表示学习的网约共享出行人员匹配方法,包括以下步骤:
步骤一:共乘分类
在司机原始路径确定的情况下,根据乘客的起点和终点与司机原始路径的关系,将共乘分为两类:第一类是端点共乘,乘客的起点和终点在司机的原始路径上;另一类是沿途共乘,乘客的起点和终点都不在司机的原始路径上,乘客需要从起点步行至上车点,然后达成共乘,再由下车点步行至目的地,共乘路径轨迹是乘客轨迹的一部分;
司机与乘客的请求信息包括司机起点和终点、离开时间、司机轨迹、上下车位置、乘客起点和终点以及上下车时间。
步骤二:构建异质共乘网络
将司机与乘客的请求信息表示为异质共乘网络形式,乘客与司机之间通过位置与时间信息相连接,从而构建异质共乘网络,该异质共乘网络中节点的类型包括用户、地点、时间段以及活动;
步骤三:使用网络表示学习模型对异质共乘网络进行表示学习,得到用户节点的低维向量表示;
步骤三中,进行表示学习的过程具体包括以下两个步骤:
1)生成节点序列集:元路径指导节点在异质共乘网络中的游走,生成固定长度的节点序列集。对于端点共乘,构建结构为ultlu的元路径;对于路途共乘,在时间段相同的约束下,构建结构为ulu的元路径。
2)将生成的固定长度的节点序列集输入到skip-gram模型中进行训练,获取司机与乘客节点的向量表示。
根据不同的共乘类型,使用不同的对称元路径来进行表示学习。对于端点共乘,使用ultlu元路径,意味着在相同的时间到达相同地点的乘客与司机可以共乘,ultlu中的第一个u表示用户节点,此处代表司机,第二个u表示用户节点,此处代表乘客,l表示乘车地点或下车地点,t表示对应地点上下车时间所处的时间段。对于沿途共乘,由于司机和乘客的出发地和目的地不同,因此乘客乘车前和下车后,仍需要花费额外的时间步行到乘车点和目的地,由此,基于ulu元路径,在司机和乘客对处于同一时间段的条件限定下,获取到最佳上车地点作为乘车地点l,(l表示乘车地点或下车地点)该元路径意味着司机和乘客在该时间段有最佳相遇点作为乘车地点l,可以共乘。
步骤三中,进行表示学习的具体过程如下:
首先,给定具体的元路径
公式(1)中,a表示节点类型,
公式(2)表示选取的元路径均为对称元路径。
其次,对于固定长度的节点序列集中任意用户节点vu,假设某一节点在序列集中的位置序号是j,则该方法会选取节点集vj-c,…,vj+c作为邻居节点,c是skip-gram中窗口大小的一半;因此,给定用户节点vu,skip-gram模型的目标是最大化具有异构邻居节点的上下文的条件概率:
其中,na(vu)是节点vu邻居节点的集合,
在假设各个节点间相互独立的情况下,在已知中心节点的条件下,上下文的条件概率为logp(vj-c,…,vj+c|vu;θ)进一步分解为
其中
根据给定节点vu的上下文节点vk的条件概率生成表示向量,再采用负采样来优化表示向量,得到异质共乘网络中每个用户节点的低维向量表示。
采用负采样来优化表示向量的具体过程如下:
其中
然后使用随机梯度下降(sgd)方法使得对数似然函数
其中
步骤四:根据用户节点的低维向量表示计算司机与乘客节点的余弦相似度,并将计算得到的余弦相似值由大到小排序,返回与司机相似度数值最高的前k个乘客,作为可以共乘的乘客,达成共乘。其中k的大小由司机所能搭载的最大乘客量决定。
实施例1
步骤一:数据分类提取;
本发明的实验数据来源于滴滴盖亚数据开放计划提供的成都局部地区数据,包括司机的gps轨迹数据和乘客的订单数据,实验中对司机和乘客进行编号,提取乘客的出发地和目的地以及司机的轨迹和对应时间,其中,司机轨迹的第一个点当做司机的出发点,轨迹终止点作为司机的目的地。本发明根据乘客的起始点与司机轨迹的关系,将共乘类型分为端点共乘和沿途共乘两类。
具体地,对于端点共乘,乘客的起点和终点在司机的原始路径上;沿途共乘则是乘客的起点和终点都不在司机的原始路径上,乘客需要从起点步行至上车点,然后达成共乘,再由下车点步行至目的地,共乘路径轨迹只是乘客轨迹的一部分。
此外对于两类共乘,还需满足以下条件。此处使用如下符号进行分析。将d表示为司机,p表示为乘客,每位司机和乘客都有自己的出发地o和目的地d。对于共乘,x表示为乘客的上车位置,y表示为乘客的下车位置。tt(o,d)表示乘客p或司机d的出发地o到目的地d所需的行驶时间,dtimed表示司机d从某个位置的出发时间,dtimep表示乘客p从某个位置的出发时间。对于端点共乘类型,只有当符合以下条件时,司机d才能将p作为共乘乘客进行端点共乘:
式中,tt(op,dp)表示乘客p的出发地o到目的地d所需的行驶时间,tt(od,dd)表示司机d的出发地o到目的地d所需的行驶时间;
沿途共乘是一种典型的出行方式,乘客从出发地点步行到最佳相遇点,在出发时间出行,共乘一段时间后,选择司机轨迹上离乘客目的地最近的地点下车,然后步行到目的地。此处使用mtp表示乘客p从起始出发地到乘车地与最终目的地到下车地之间的最大步行时间。因此对于沿途共乘,如果符合以下情况,司机可以让该乘客进行共乘:
式中,tt(xp,yp)表示乘客p的出发地o到目的地d所需的行驶时间。
对于最佳相遇点的选择,本发明采用迪杰斯特拉算法得到司机与乘客的最佳相遇点,并将该点作为乘客的上车位置。
步骤二:将步骤一提取的地点和时间数据进行预处理,构建共乘异构信息网络:
定义1异构信息网络(hin)被定义为具有多种类型的节点和/或多种类型的链路的网络。它可以表示为h=(v,ε),其中v是一组节点,ε是一组链接。链接可以是加权的,未加权的,定向的或无向的。节点类型映射函数
异构信息网络由通过网络间边缘连接的不同但相关的节点组成。此处的“不同”意味着-网络的顶点具有不同类型,“相关”则意味着两个节点具有特定类型的交互或关系。
本发明构造的异质共乘网络如图1所示。对于两种类型的共乘,本发明构造了相同的网络模式,两类共乘均是以司机和乘客的时间和地点约束来匹配司机和乘客,该网络模式中的节点类型包括:位置(l),时间(t),活动(a)和用户(即乘客或司机)(u)。其中用户类型节点(u)包括司机和乘客,其中乘客以p开头从1开始顺序编号,司机以d开头从1开始顺序编号;本发明对时间进行了序列化模糊化处理,其按照每隔半个小时将一天24小时划分为了48个时段,具体为从00:00:00开始,每半个小时为一个时间段,将时间段进行编号(1~48),将每个时间段对应的编号作为时间类型节点(t)。对于位置类型的节点(l),选取乘客的上下车地点做为位置类型节点,在端点共乘中,以乘客的o和d做为位置类型节点,因为在端点共乘中,乘客的od在司机轨迹上,乘客的上下车地点就是乘客的od点,在沿途共乘中,以司机和乘客的最佳相遇点做为位置类型节点,因为在沿途共乘中,乘客和司机均需要到达最佳相遇点才能达成共乘。对于活动类型节点(a),本发明通过百度api转换得到每个位置的类型,包括房地产、教育机构等。异质共乘网络中的链接类型
步骤三:根据不同的共乘类型,选择相应的元路径,使用网络表示学习模型对异质共乘网络进行表示学习,得到用户节点的低维向量表示;
构建异质共乘网络的目的是在司机和乘客之间建立联系,为了体现出二者具有相同的目的或要求,此处使用对称元路径来表示这种关系。其中元路径定义如下:
定义2(元路径)元路径是在网络模式
对于端点共乘,使用ultlu元路径,意味着在相同的时间到达相同地点的乘客与司机可以共乘。其中的两个u分别作为司机和乘客,l表示乘车地点或下车地点,t表示对应地点上下车时所处的时间段。对于沿途共乘,由于司机和乘客的出发地和目的地不同,因此乘客乘车前和下车后,仍需要花费额外的时间步行到乘车点和目的地,这类共乘相比端点共乘更具有复杂性。基于ulu元路径,该元路径中的l代表最佳相遇点。表示能够在同一时段到达同一相遇点的司机和乘客可以达到共乘。对于获取最佳相遇点的迪杰斯特拉算法,首先将包含对应司机和乘客轨迹的轨迹网络作为输入,通过该算法获取到二者od在路网上的最短路径,将其作为最佳相遇点。
网络表示学习能够将网络中的节点表示成低维稠密的实值的向量形式,本发明通过输入基于对称元路径的节点序列集,将节点以one-hot编码方式编码为初始向量后再进行低维向量的转换。
本发明中,网络表示学习分为两个阶段:首先第一阶段是元路径指导节点在异质共乘网络中的随机游走,进一步生成固定长度的节点序列集。
以端点共乘使用的ultlu类型元路径为例,如果当前节点为用户(u)类型,则ultlu元路径指导下的下一跳节点为l类型,跳转概率如公式(1)所示,l类型的下一节点为t类型,本发明所生成的每个节点序列长度为5。
随机游走的游走概率
公式(1)中,其中的节点用a来表示节点类型,
第二阶段将长度为5的节点序列集输入到skip-gram模型中进行训练,获取司机与乘客节点的向量表示。
此处使用skip-gram模型来为每个用户类型u的节点构建特征向量,并在skip-gram模型中使用了负采样来优化表示向量。对于序列集中任意用户节点vu,假设该节点在某个序列中的位置序号是j,该方法会选取t类型的节点集vj-c,…,vj+c作为邻居节点,c是skip-gram中设置的窗口大小的一半。因此,给定用户节点vu,skip-gram模型的目标是最大化具有异构邻居节点的上下文的条件概率:
na(vu)是节点vu邻居节点的集合,
其中
除了使用上下文节点集的关系来生成向量,还使用了负采样的方法来优化表示向量,该方法能够去除无关节点对目标向量的影响,使得不同分类的向量间的区分更加明显。该方法的似然函数如下:
其中
其中
步骤四:根据用户节点的低维向量表示通过余弦相似度算法计算司机和乘客的相似度,将相似度结果从大到小排列,因此获得与司机相似度数值最高的前k个乘客,作为可以共乘的乘客,达成共乘。其中k的大小由司机所能搭载的最大乘客量决定。
通过余弦相似度算法计算司机和乘客的相似度的具体过程如下:
对于任意一对用户节点vi,vj,其表示向量xi,xj的余弦相似度sim(vi,vj)定义如下
其中,xi为节点vi的向量,xj为节点vj的向量;当||xi||=||xj||=1时,余弦相似度等价于欧几里得距离,这允许在归一化之后使用近似最近邻搜索能够有效地定位给定节点vi的前k个相似节点(乘客)。因此,给定先前学习的用户(司机)向量,通过计算其表示向量xi和xj之间的余弦相似性来找到给定司机的潜在乘客。具有最大相似性的k个乘客被识别为共乘参与者,然后可以对候选人进行排名并观察共乘类型。
本发明使用滴滴用户的轨迹数据集构造异构共乘异构网络模型,并对不同类型的共乘进行了分类。提出两类元路径的定义,并在共乘网络中生成出元路径序列集,对其进行负采样skip-gram生成用户的表示向量,最后采用余弦相似性算法实现用户间的相似性计算,使用前k相似度预测可以进行共乘的乘客。本发明提出的共乘推荐方法比传统的仅使用距离推荐的方法更加可靠,语义理解性直观,能够准确发现潜在的共乘用户,为其提供更为快捷方便的服务。
- 还没有人留言评论。精彩留言会获得点赞!