一种语言冲突的预测方法与流程
本发明涉及自然语言处理技术,具体为语言冲突的预测方法。
背景技术:
情感分析,又称极性分析,近年来已逐渐发展成为自然语言处理领域中最热门的研究方向之一。研究方法也从一开始的基于词典的规则方法,逐步转变成基于机器学习的方法。
自然语言处理的目标是计算机能学习、理解并能够生成人的语言,实现智能处理的效果。随着机器学习方法突飞猛进的发展,特别是深度学习技术的蓬勃发展和广泛应用,研究者根据现实世界中巨大的任务需求,借助并充分运用了先进的机器学习方法,在机器翻译、语音对话系统、社会媒体挖掘、情感分析等任务中取得了突破性进展。自然语言处理的进展为人类理解语言生成机制和受其启发而开发出更多的社会应用提供了广阔途径,具有重要意义。
此外,在网络对话中,往往会出现人身攻击或言语冲突的情形。然而,目前尚未有对人身攻击或言语冲突进行预测的技术,因而无法把网络矛盾控制在萌芽之中。
技术实现要素:
为解决现有技术所存在的技术问题,本发明提供一种语音冲突的预测方法,对网络对话是否可能恶化进行有效预测,有利于网络矛盾的防治处理。
本发明采用以下技术方案来实现:一种语言冲突的预测方法,包括以下步骤:
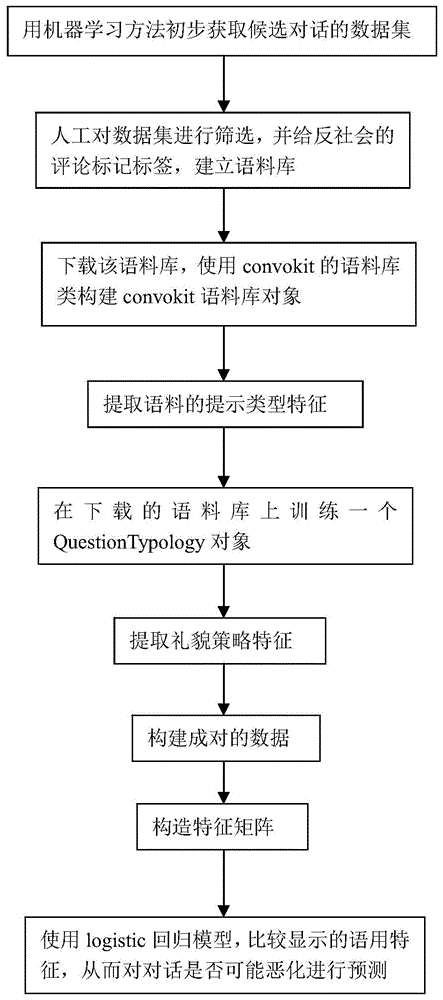
S1、用机器学习方法获得候选对话数据集;
S2、对数据集进行筛选,筛选出开始为文明对话而随后恶化为有害对话的对话数据,并在有害对话的上下文中标注其标签;在个人攻击的语境中给反社会评论贴上标签,建立语料库;
S3、下载所建立的语料库,使用convokit语料库类构建convokit语料库对象;
S4、提取语料的提示类型特征;
S5、在下载的语料库上训练一个QuestionTypology对象,将Wiki语料库加载到数据集对象;
S6、提取礼貌策略特征;
S7、创建成对的数据;
S8、根据提示类型特征、礼貌策略特征和成对数据,构造特征矩阵;
S9、使用logistic回归模型,比较显示的语用特征,从而对网络对话是否可能恶化进行预测。
优选地,步骤S4使用convokit语料库的QuestionTypology分类器为每个话语学习提示类型特征,并计算出提示类型。
优选地,步骤S7中,首先建立一个数据框架将注释ID映射到它们的会话;然后使用每个对话的第一个和第二个评论的ID来补充用于恶化对话和良好对话的成对数据框架。
优选地,步骤S8中,在成对数据基础上,为每对对话构造语用特征表,用于预测语言冲突;所述语用特征表将由对每个对话的第一个和第二个评论的提示类型和礼貌策略组成。
本发明与现有技术相比,具有如下优点和有益效果:本发明预测方法对获得的候选对话数据集进行人工筛选,得到开始为文明对话而随后恶化为有害对话的对话数据,采用建立语料库、创建成对数据及logistic回归模型等技术,对网络对话是否可能恶化进行有效预测,有利于网络矛盾的防治处理。
附图说明
图1是本发明的预测流程图;
图2是恶化会话与保持文明的对话中语用特征标记的对数比值比较结果图,其中A为第一个和第二个评论的对数几率比例系数,B为攻击者发起的会话的对数几率比例系数,C为非攻击者发起的会话的对数几率比例系数。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
实施例
如图1所示,本发明语言冲突的预测方法,包括以下步骤:
S1、用机器学习方法获得候选对话数据集,其中包括初始为文明对话而从第n句开始被标记为有害对话(n>2)的对话数据。
S2、人工对数据集进行筛选,筛选出开始为文明对话而随后恶化为有害对话的对话数据,并在有害对话的上下文中标注其标签;在个人攻击的语境中给反社会的评论贴上标签,建立语料库。
S3、下载所建立的语料库,使用convokit语料库类构建convokit语料库对象。语料库类提供用于方便操作语料库的功能。
S4、提取语料的提示类型特征。在这一步中,我们将提取文本中两种语用特征中的第一种:提示类型。使用convokit语料库的QuestionTypology分类器为每个话语学习提示类型特征,并计算出提示类型。
S5、在下载的语料库上训练一个QuestionTypology对象,将Wiki语料库加载到数据集对象。训练了QuestionTypology对象后,就可以使用它来计算对话恶化语料库的提示类型了(注意,这是与QuestionTypology对象所训练的语料库不同的语料库);以提取提示类型的原始特征,这些原始特征是与每个提示类型相对应的K均值聚类中心的距离。
S6、提取礼貌策略特征。将convokit语料库的PolitenessStrategies分类器直接应用到数据集中。
S7、创建成对的数据。
首先,建立一个数据框架将注释ID映射到它们的会话。在数据集中包含了完整的节标题,但是为了预测,我们需要将其忽略,因为它们不是对话内容。我们将使用恶化对话的ID作为参考线索来构建结构。
然后,使用每个对话的第一个和第二个评论的ID来补充用于恶化对话和良好对话的成对数据框架,这将用于构造特征矩阵。
S8、根据提示类型特征、礼貌策略特征和成对数据,构造特征矩阵。在成对数据基础上,可以为每对对话构造语用特征表,用于预测语言冲突。这个语用特征表将由对每个对话的第一个和第二个评论的提示类型和礼貌策略组成。
计算所提取的语用特征在会话初始交换后出现恶化的频率、继续保持文明对话的频率,比较出现恶化的频率和继续保持文明对话的频率,即比较两个频率值。我们将计算每个语用特征的对数优势比,比较恶化的和保持文明的会话;我们还将计算来自二项分布测试的显著性值(衡量影响的大小的值),该二项分布测试将显示特定语用特征的恶化会话的比例与保持文明会话的比例进行比较的结果。由于我们已经预先计算了语用特征,并且编译了成对的数据集,因此仍然需要计算影响大小和统计意义,并绘制这些值;具体地说,为了量化语言标记在恶化的对话开始时出现的相对倾向,我们计算在恶化会话的初始交流(即第一次或第二次评论)中语用特征标记的对数比值,与保持文明对话的初始交流进行比较。
产生的结论如图2所示。在随后恶化对话中的第一个和第二个评论中表现的礼貌策略和提示类型的对数几率比例系数,与那些保持文明的对话相对。图2中标记了在第一个和第二个评论中各特征对数几率的比例系数,其中实心标记表示显著的(p<0.05)对数几率(有着至少0.2的效应量)。
图2的A图中:菱形和正方形分别表示第一个和第二个评论的对数几率;*代表统计上的显著差异,其中概率p<0.05(*),p<0.01(**),p<0.001(***)级别标注第一个评论(使用了双侧二项检验);+代表第二个评论相应的统计显著性。
图2的B图和C图中:三角形和圆形分别表示由攻击者和非攻击者发布的评论句中的对应效应量,分为由攻击者发起(B)和由非攻击者发起(C)的对话。
S9、使用logistic回归模型,比较显示的语用特征(即提示类型与礼貌策略的混合特征),从而对网络对话是否可能恶化进行预测。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!