一种自动应答装置及方法与流程
本发明涉及计算机通信领域,尤其是自动应答领域。
背景技术:
在自动应答领域,由于知识领域、社会背景、教育经历、语言表达方式的差异,不同客户对同一问题的表述方式有着或多或少的区别,而计算机要对各式各样的表述进行准确理解并给出正确的话术应答的难度非常大。现有技术主要采用同/近义词库、句库等手段匹配用户输入的问题,采用这些方法的缺点是需要庞大的词库、句库且需要不断增加词句知识库以应对新出现的问题,占用大量存储资源的同时匹配的效率也越来越低。
技术实现要素:
本发明针对现有技术存在的缺陷,提出一种结合词向量技术和句向量技术快速、准确匹配用户输入的装置及方法。
为实现上述目的,本发明采用了如下技术方案:
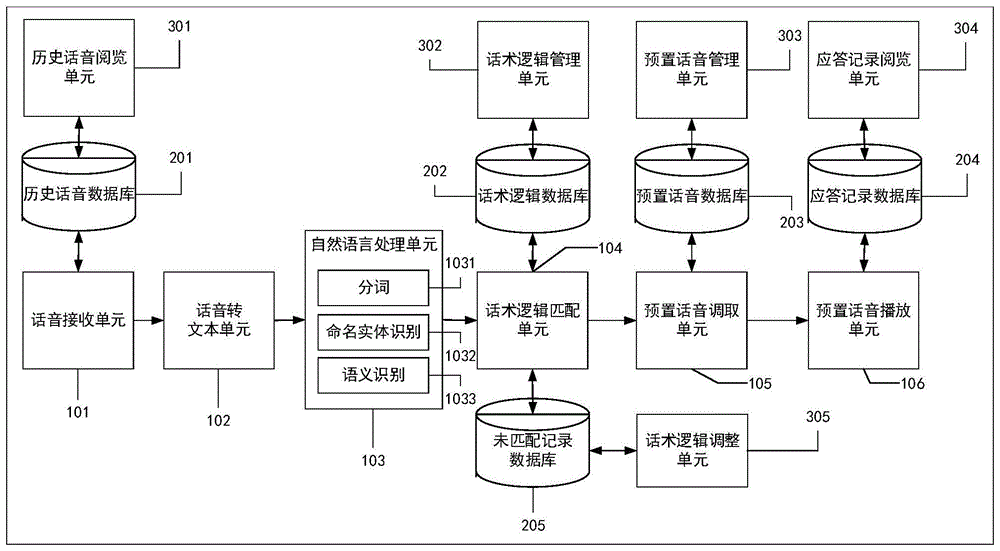
一种验证自动应答电话机器人应答话术逻辑匹配准确性的装置,包括:
话音接收单元101,用于从外部环境接收用户输入的话音数据;
话音转文本单元102,用于将话音接收单元接收的话音数据转化为文本数据;
自然语言处理单元103,包括分词1031、命名实体识别1032、语义识别1033,通过对转化的文本数据分别进行分词处理、命名实体识别、文本语义识别处理,用于提取用户输入的语义信息,生成相应的词向量矩阵和句向量矩阵,传统上使用词向量技术实现词语相似度匹配、句向量技术实现语句相似度匹配,本发明结合两种技术对客户输入信息与话术逻辑数据库中预置话术进行分析匹配,能够进一步提高文本数据匹配的准确率,使得对客户的回答更加准确,提高客户的使用体验;
话术逻辑匹配单元104,根据自然语言处理单元103提取的向量矩阵到话术逻辑数据库匹配对应的应答逻辑;
预置话音调取单元105,根据话术逻辑匹配结果到话音数据库调取对应的话音文件;
预置话音播放单元106,用于调用话音播放模块对预置话音调取单元调取的话音文件进行播放控制;
历史话音数据库201,用于存储所有用户输入的历史话音数据,对所有客户输入的历史话音数据单独存储管理,能够方便人工进行自动应答过程的复盘分析,对话音转录准确性进行验证并及时对算法进行反馈,有助于逐步提高话音转录的准确率;
历史话音阅览单元301,用于调取听阅历史话音数据;
话术逻辑数据库202,用于存储预置的话术应答逻辑数据;
话术逻辑管理单元302,用于对话术逻辑数据库中存储的话术逻辑进行增、删、改、查、导入、导出等管理操作,单独的话术逻辑管理单元设置,可以方便人工对话术逻辑应答策略进行即时校正,利于逐步提高自动应答效率和准确率,提高客户体验;
预置话音数据库203,用于存储预置的话音文件数据;
预置话音管理单元303,对预置话音数据库中的预置话音数据进行增、删、改、查操作;
应答记录数据库204,用于存储所有自动应答记录相关数据;
应答记录阅览单元304,用于对应答记录数据库中存储的自动应答历史记录进行可视化调阅浏览;
未匹配记录数据库205,用于存储所有未能匹配上话术逻辑的记录信息;
话术逻辑调整单元305,用于对未匹配上话术逻辑的记录进行人工判证和对相应的话术逻辑设置进行调整。
本发明提出一种自动应答装置及方法,采用词向量技术和句向量技术相结合的方法实现语义分析和语义匹配,实现了应答过程的自动化,优点如下:
1、提高了自动应答的效率;
2、提高了自动应答的准确率;
3、防止知识库过度膨胀,节约了存储资源。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1是本发明的自动应答装置组成结构图;
图2是本发明的自动应答方法实施例的流程图;
图3是本发明的文本数据自然语言处理实施例的流程图。
具体实施方式
下面结合附图对本发明的具体实施方式作进一步说明。在此需要说明的是,对于这些实施方式的说明用于帮助理解本发明,但并不构成对本发明的限定。基于本发明的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
参照图1,示出了本发明的一种自动应答装置的组成结构图,具体包括如下组成结构:
话音接收单元101,用于从外部环境接收用户输入的话音数据;
接收到的话音数据直接存入历史话音数据库并将话音数据转送到话音转文本单元,话音数据全部存入历史话音数据库可以随时对历史话音进行调阅,方便进行复盘分析;
话音转文本单元102,用于将话音接收单元接收的话音数据转化为文本数据;
所述话音转文本单元使用的语音转文本引擎包括但不限于谷歌语音引擎、科大讯飞语音引擎、度秘语音引擎等;
自然语言处理单元103,包括分词1031、命名实体识别1032、语义识别1033,通过对转化的文本数据分别进行分词处理、命名实体识别、文本语义识别处理,用于提取用户输入的语义信息,生成相应的词向量矩阵和句向量矩阵;
所述自然语言处理单元的过程包括:
文本分词处理,调用分词算法对文本数据按照词性进行分词处理,分词算法包括但不限于JieBa分词、盘古分词、Hanlp分词、斯坦福分词器、ZPar分词器等;
命名实体识别,根据分词处理结果区分文本数据中的时间、地点、人名、地名、组织机构名、国家名、号码、银行卡等实体信息,同时提取出文本数据中出现的代表情感的实体词;
语义识别分析,根据分词和命名实体识别处理结果构建词向量矩阵和句向量,调用语义匹配算法生成文本数据表达的标准语义内容,文本语义分析算法引擎包括但不限于sen2vel、doc2vel等;
话术逻辑匹配单元104,根据自然语言处理单元提取的语义信息到话术逻辑数据库获取对应的应答逻辑,话术逻辑数据库返回应答话术在预置话音数据库的映射信息,通过映射信息从预设话音数据库中获取对应的话音数据;
预置话音调取单元105,根据话术逻辑匹配结果到话音数据库调取对应的话音数据文件;
预置话音播放单元106,用于调用话音播放模块对预置话音调取单元调取的话音文件进行播放控制;
历史话音数据库201,用于存储所有用户输入的历史话音数据,存储的历史话音数据可以在进行复盘分析时供人工调阅,以分析话音转文本引擎的准确性并对话音转文本引擎进行反馈以提高引擎的准确率,历史话音数据库为文件型数据库,包括但不限于MongoDB、RavenDB、CouchDB、OrientDB、SequoiaDB等数据库;
历史话音阅览单元301,用于调取听阅历史话音数据;
话术逻辑数据库202,用于存储预置的话术应答逻辑数据,话术逻辑数据库为关系型数据库,包括但不限于Oracle、SQL Server、MySQL等数据库;
话术逻辑管理单元302,用于对话术逻辑数据库中存储的话术逻辑进行增、删、改、查操作;
预置话音数据库203,用于存储预置的话音文件数据,预置话音数据库类型同历史话音数据库201;
预置话音管理单元303,对预置话音数据库中的预置话音数据进行增、删、改、查操作;
应答记录数据库204,用于存储所有自动应答记录相关数据,应答记录数据库类型同话术逻辑数据库202;
应答记录阅览单元304,用于对应答记录数据库中存储的自动应答历史记录进行可视化调阅浏览;
未匹配记录数据库205,用于存储所有未能匹配上话术逻辑的记录信息,未匹配记录数据库类型同话术逻辑数据库202;
话术逻辑调整单元305,用于对未匹配上话术逻辑的记录进行人工判证和对相应的话术逻辑设置进行调整,人工定时或者随时对当前积累的未匹配上应答话术的记录进行人工判证,分析为匹配原因,相应补录或调整应答话术匹配逻辑。
参照图2,示出了本发明的一种自动应答方法实施例的流程图,具体包括以下步骤:
S101、接收用户输入话音数据;
S102、将话音数据存入历史话音数据库;
S103、调用话音转文本引擎,将用户话音类型数据转化为文本类型数据;
S104、对文本类型数据进行自然语言处理,得到用户输入信息的句向量数据;
S105、根据S104生成的句向量,与话术逻辑数据库中预置的话术进行相似度匹配,查找对应的话术逻辑匹配结果;
S106、判断是否从话术逻辑数据库中匹配到对应的话术逻辑,如匹配成功进入S107,如匹配失败则进入S110;
S107、根据S106的匹配结果从预置话音数据库中调取对应的话音数据文件;
S108、调用话音播放模块向用户播放话音文件;
S109、将整个自动应答过程存入应答记录数据库;
S110、将未匹配到结果的用户输入信息存入未匹配记录数据库,并向用户播放未找到应答信息的话音文件。
参照图3,示出了本发明的一种文本数据自然语言处理实施例的流程图,具体包括以下步骤:
S201、调用分词引擎,对话音转录的文本数据进行分词处理;
S202、解析S201的分词处理结果,提取其中的重要命名实体数据;
S203、根据S201和S202的分词、命名实体识别结果,调用语义分析引擎进行文本的语义分析;
S204、调用句向量生成算法根据S203分析结果生成用户本次输入的词向量矩阵和句向量矩阵。
- 还没有人留言评论。精彩留言会获得点赞!