基于VLAD卷积模块的图像信息强化方法与流程
本发明涉及数字图像处理技术领域,更具体地,涉及一种基于vlad卷积模块的图像信息强化方法。
背景技术:
卷积神经网络(cnn)是常用于计算机视觉任务上的实用模型,为了提高卷积神经网络的性能,最近的实验工作主要研究对于在深度神经网络的中间层分支进行深度融合,产生潜在可以共享有用信息的基础网络,从而优化信息流动,提升深度神经网络的性能。
对此研究者提出残差注意力网络,综合了resnext和inception的方法,通过bottom-uptop-down的形式构建旁路,通过一系列的卷积层与池化操作,逐渐提取特征图中的高级特征并增大模型的感受域,由于高层特征中所激活的特征值能够反映注意力所在的区域,于是再通过相同数量的upsample将特征图的尺寸放大到原来的输入大小,再与干路特征结合,能够增强干路上特征图中有用信息的权重。然而该方法对特征图的信息强化结果仍不能满足现有的需求,且该方法中的基础网络的两路都是以3d形式进行数据流动,对此基础网络参数将会相应地增加,而以此构建的深度神经网络的训练时间与能耗会相应地大量增加。
jegouetal.在2010年提出一种局部聚合描述子向量(vectoroflocallyaggregateddescriptors,vlad)卷积模块,一般用于将图像的局部描述进行聚合操作,然后通过一个长向量来表征一副图像,主要应用于图像检索领域。然而现有技术中采用vlad卷积模块的图像特征检索中由于图像特征的检索结果主要依赖于聚类中心,因此存在不稳定性,无法确保能够精确检索图像特征从而进行强化。
技术实现要素:
本发明为克服上述现有技术所述的图像信息强化的结果不能满足需求等缺陷,提供一种基于vlad卷积模块的图像信息强化方法。
为解决上述技术问题,本发明的技术方案如下:
基于vlad卷积模块的图像信息强化方法,包括以下步骤:
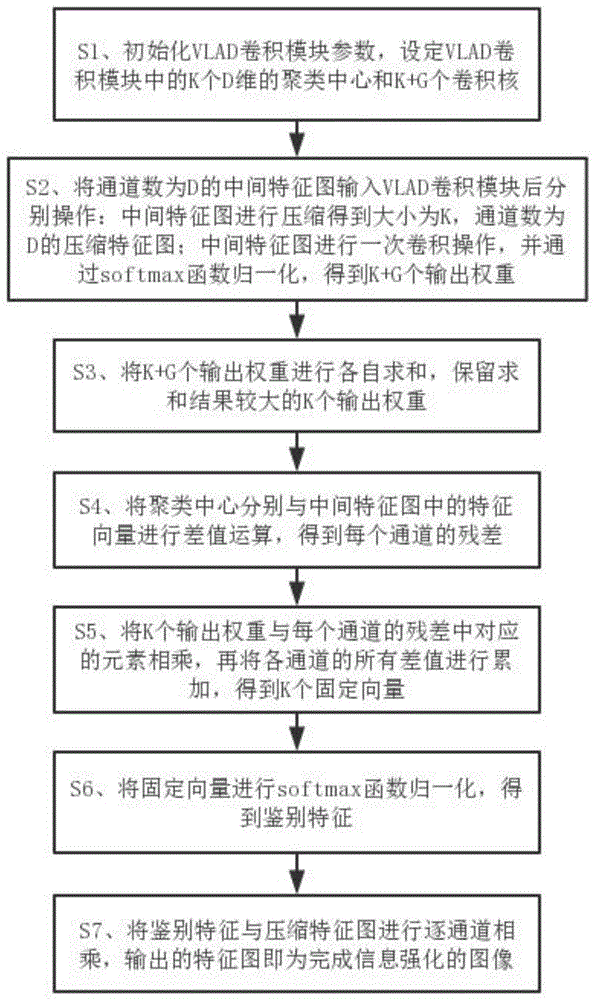
s1、初始化vlad卷积模块参数,设定vlad卷积模块中的k个d维的聚类中心和k+g个卷积核,其中,d、k、g为正整数;
s2、将通道数为d的中间特征图输入vlad卷积模块后分别进行以下操作:中间特征图进行压缩得到大小为k,通道数为d的压缩特征图;中间特征图进行一次卷积操作,并通过归一化指数函数(softmax函数)进行归一化处理,得到k+g个输出权重;
s3、将k+g个输出权重进行各自求和,保留求和结果较大的k个输出权重;
s4、将聚类中心分别与中间特征图中的特征向量进行差值运算,得到每个通道的残差;
s5、将s3步骤保留的k个输出权重与每个通道的残差中对应的元素相乘,再将各通道的所有差值进行累加,得到k个固定向量;
s6、将固定向量通过softmax函数进行归一化处理,得到鉴别特征;
s7、将鉴别特征与压缩特征图进行逐通道相乘,输出的特征图即为完成信息强化的图像。
本技术方案中,以中间特征图作为输入,与初始化的卷积核进行卷积操作,获取输出权重,其中输出权重为矩阵,每个权重值代表特征图与聚类中心的远近关系,距离越近权重值越大;然后将输出权重进行各自求和,将求和结果最小的g个权重进行丢弃,即表示将低质量的图像特征对应的权重进行丢弃,保留图像质量较高的图像特征,从而实现图像信息的强化;将中间特征图与初始化的聚类中心做差值运算,并将差值与输出权重对应的元素相乘处理,再将该通道的所有差值进行累加,从而把原本的中间特征图压缩成k个固定向量,避免与最终处理的压缩特征图大小不一致;将固定向量通过softmax函数进行归一化处理后与经过压缩的特征图进行逐通道相乘,达到强化有用信息,抑制无用信息的效果,最终得到完成信息强化的图像。本技术方案可应用于图像识别或图像鉴别的深度神经网络中。
优选地,vlad卷积模块包括树干分支和旁路分支,其中树干分支由两组残差模块构成并与深度神经网络衔接,旁路分支为vlad层,vlad层包括k+g个卷积核和k个聚类中心。其中旁路分支为改进的vlad层,其改进在于:在现有的vlad层中额外增加了g个卷积核,用于得到额外的输出权重。具体地,根据各输出权重各自求和的结果大小,判断中间特征图中低质量的图像特征对应的输出权重,然后将该输出权重划分到额外的输出权重中进行丢弃,实现对中间特征图中低质量的图像特征进行丢弃,从而提高图像特征提取效果,能够强化树干分支对图像特征的鉴别性,同时对特征图进行降维。此外,卷积核能够使vlad层具有学习可训练性能,在构建模型时通过迭代更新模型参数。
优选地,步骤s2的具体步骤如下:
s201、将通道数为d,大小为h×w的中间特征图输入vlad卷积模块中,中间特征图通过vlad卷积模块的树干分支得到大小为k,通道数为d的压缩特征图;
s202、中间特征图通过vlad卷积模块的旁路分支,中间特征图被处理为d个h×w维的特征向量,然后对特征向量进行一次卷积操作,并通过softmax函数进行归一化处理,得到k+g个输出权重,其中输出权重为h×w大小的矩阵。
优选地,s1步骤中卷积核的大小为(d,1),即卷积核的大小与输入的中间特征图的通道数相同。
优选地,vlad卷积模块参数还包括k+g个偏置项,其中偏置项用于参与中间特征图的卷积操作。
优选地,s5步骤中的固定向量的计算公式如下:
其中,v(j,k)为固定向量,表示第j个通道维度上的中间特征图与第k个聚类中心的差值之和,xi(j)表示通道维度为j的中间特征图上第i个值,ck表示第k个聚类中心上第j维度上的值,wk表示第k个聚类中心的输出权重。
优选地,s6步骤中的鉴别特征的范围为0~1。
优选地,本图像信息强化方法应用于resnet50深度残差网络中。
与现有技术相比,本发明技术方案的有益效果是:通过提高高质量图像特征的权重,丢弃低质量图像特征的权重,实现强化中间特征图的有用信息,有效增强应用本发明的网络模型对图像的鉴别性能;具有计算量小、检索精度高的特点,能够有效减少构建深度网络的训练时间和能耗。
附图说明
图1为本实施例的基于vlad卷积模块的图像信息强化方法的流程图。
图2为本实施例的vlad卷积模块的结构示意图。
图3为本实施例的处理结果对照图。
图4为现有技术的处理结果对照图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
下面结合附图和实施例对本发明的技术方案做进一步的说明。
如图1所示,为本实施例的基于vlad卷积模块的图像信息强化方法的流程图。
本实施例的基于vlad卷积模块的图像信息强化方法包括以下步骤:
步骤一:初始化vlad卷积模块参数,设定vlad卷积模块中的k个d维的聚类中心、k+g个卷积核和k+g个偏置项,其中,d、k、g为正整数。
步骤二:将中间特征图输入vlad卷积模块后分别进行以下操作:中间特征图进行压缩得到大小为k,通道数为d的压缩特征图;中间特征图进行一次卷积操作,并通过softmax函数进行归一化处理,得到k+g个输出权重。其具体步骤如下:
s201、将通道数为d,大小为h×w的中间特征图输入vlad卷积模块中,中间特征图通过vlad卷积模块的树干分支得到大小为k,通道数为d的压缩特征图;
s202、中间特征图通过vlad卷积模块的旁路分支,中间特征图被处理为d个h×w维的特征向量,然后对特征向量进行一次卷积操作,并通过softmax函数进行归一化处理,得到k+g个输出权重,其中输出权重为h×w大小的矩阵。
步骤三:将k+g个输出权重进行各自求和,保留求和结果较大的k个输出权重。
步骤四:将聚类中心分别与中间特征图中的特征向量进行差值运算,得到每个通道的残差。
步骤五:将步骤三保留的k个输出权重与每个通道的残差中对应的元素相乘,再将各通道的所有差值进行累加,得到k个固定向量。其中,固定向量的计算公式如下:
其中,v(j,k)为固定向量,表示第j个通道维度上的中间特征图与第k个聚类中心的差值之和,xi(j)表示通道维度为j的中间特征图上第i个值,ck表示第k个聚类中心上第j维度上的值,wk表示输出权重。
步骤六:将固定向量通过softmax函数进行归一化处理,得到鉴别特征。
步骤七:将鉴别特征与压缩特征图进行逐通道相乘,输出的特征图即为完成信息强化的图像。
如图2所示,为本实施例的vlad卷积模块的结构示意图。本实施例中的vlad卷积模块包括树干分支和旁路分支,其中树干分支由两组残差模块构成并与深度神经网络衔接,旁路分支为vlad层,vlad层中包括k+g个卷积核和k个聚类中心。
本实施例中的卷积核的大小根据输入的中间特征图的通道数决定,其大小为(d,1)。
在具体实施过程中,将本实施例提出的方法应用于resnet50深度残差网络中。
步骤一:初始化vlad卷及模块参数,设定vlad卷积模块中56×56个128维的聚类中心、56×56+14×14个大小为(128,1)的卷积核以及56×56+14×14个偏置项。
步骤二:将大小为128×128,通道数为128的中间特征图输入vlad模块,中间特征图通过树干分支的两组残差模块后得到大小为56×56,通道数为128的压缩特征图;中间特征图进入旁路分支后被处理为128个128×128维的特征向量,然后进行一次卷积操作,并通过softmax函数进行归一化处理,得到56×56+14×14个输出权重,其中输出权重为128×128大小的矩阵,代表中间特征图的特征位置与聚类中心位置的远近关系。
步骤三:将56×56+14×14个输出权重进行各自求和,保留求和结果较大的56×56个大小为128×128的输出权重矩阵,将求和结果最小的14×14个输出权重舍弃,使中间特征图中质量较低的图像特征,即中间特征图中的无用信息舍弃,从而降低低质量图像的权重,增强模型对图像的鉴别性能。
步骤四:将56×56个128维的聚类中心分别与中间特征图的128个128×128维的特征向量进行差值运算,每个通道上的128×128维的向量元素与该通道的一个聚类中心值分别进行差值运算,最终每个通道上得到128×128个差值作为残差。
步骤五:将步骤三中保留的56×56个大小为128×128的输出权重矩阵与步骤四中得到的128×128个残差中对应的元素相乘,再将这通道的所有差值进行累加,得到56×56个128维的固定向量,即把原输入的128×128个128维的中间特征图压缩成56×56个128维的固定向量,使旁路分支的输出与树干分支输出的特征图尺寸大小一致。
步骤六:将56×56个128维的固定向量通过softmax函数进行归一化处理,输出0~1的值,即为鉴别特征。
步骤七:将鉴别特征与树干分支输出的大小为56×56,通道数为128的特征图进行逐通道相乘,达到强化有用信息抑制无用信息的效果。
如图3、4所示,图3为本实施例的处理结果对照图,图4为现有技术的处理结果对照图。其中输入的中间特征图为人脸表情照片,因此特征图中需要强化的信息为人脸的五官等。由图示可看出,本实施例能够对特征图中高质量的图像特征进行强化,舍弃低质量的图像特征,从而增强网络模型对图像的鉴别性能。
本实施例的基于vlad卷积模块的图像信息强化方法能够强化输入的中间特征图中的有用信息,丢弃无用信息,从而增强网络模型对图像的鉴别性能,同时本实施例的图像信息强化方法中的计算量较小,在应用过程中能够有效减少构建深度神经网络的训练时间和能耗。
相同或相似的标号对应相同或相似的部件;
附图中描述位置关系的用语仅用于示例性说明,不能理解为对本专利的限制;
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!