适用于深度学习硬件加速器的可配置精度的卷积硬件结构的制作方法
本发明涉及电子电路技术领域,具体地,涉及适用于深度学习硬件加速器的可配置精度的卷积硬件结构。
背景技术:
深度学习是机器学习中一个非常接近人工智能的领域,它的目的在于建立一个神经网络以模拟人脑的学习和分析的过程。深度学习的主要思想就是堆叠多个层,将低层的输出作为更高一层的输入,含多隐层的多层感知器就是一种深度学习结构的体现。通过这样的方式,深度学习能够通过组合低层特征来形成更为抽象的高层表示属性,从而发现数据的分布式特征表示。而如何使深度学习运行更高效是摆在不少工程师面前的难题。
业内最常用的方案有两种:硬件加速和软件(代码)加速。前者主要是提升算力,尤其是cpu和gpu的算力,例如公开号为cn108108813a的发明专利“一种大类别深度学习gpu并行加速的方法”。计算能力越好,这些简单的矩阵运算自然就越快。后者主要有两种路径,一是利用诸如二值网络模型等小网络模型来实现差与大网络差不多的效果,二是使用矩阵运算加速的库。
对于硬件加速而言,
深度学习神经网络的核心运算是卷积,卷积核由乘法和加法组成。随着神经网络算法的发展,计算所需要的精度已经从32bit下降到16bit,一些特殊的网络还可以使用8bit精度的卷积核。在卷积核的设计上,已有的方案集中在单精度的16bit运算和8bit运算。目前的技术方案虽然可以提高运算速度,但是运算精度单一,无法适配复杂多样的网络,且计算能力固定,也无法满足日益发展的神经网络对算力的需求。
技术实现要素:
针对现有技术中的缺陷,本发明的目的是提供一种适用于深度学习硬件加速器的可配置精度的卷积硬件结构。
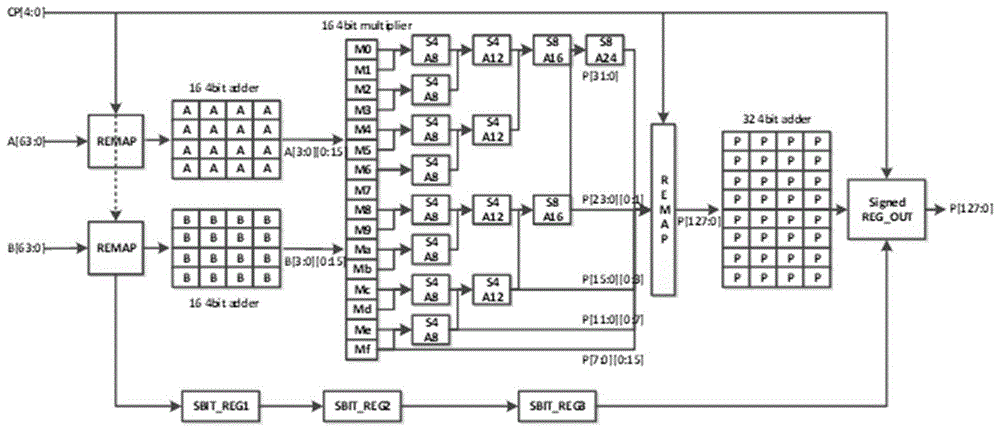
根据本发明提供的一种适用于深度学习硬件加速器的可配置精度的卷积硬件结构,包括:第一重映射模块、第二重映射模块、第三重映射模块、第一加法阵列、第二加法阵列、第三加法阵列、多个无符号乘法单元和部分积移位相加阵列;
所述第一重映射模块和所述第二重映射模块的输出端分别连接所述第一加法阵列和所述第二加法阵列的输入端,所述第一加法阵列和所述第二加法阵列的输出端连接所述多个无符号乘法单元的输入端,所述多个无符号乘法单元的输出端连接所述部分积移位相加阵列的输入端,所述部分积移位相加阵列的输出端连接所述第三重映射模块的输入端,所述第三重映射模块的输出端连接所述第三加法阵列的输入端;
其中所述第一重映射模块、所述第二重映射模块和所述第三重映射模块根据精度选择信号选择数据通路。
优选地,所述第一重映射模块、所述第二重映射模块和所述第三重映射模块根据精度选择信号对输入信号进行相应的变换。
优选地,所述第一加法阵列、所述第二加法阵列和所述第三加法阵列能够对输入数据进行补码;
所述第一加法阵列和所述第二加法阵列分别包括16个加法器构成的加法阵列;所述第三加法阵列包括32个加法器构成的加法阵列。
优选地,所述多个无符号乘法单元包括16个4bit精度的无符号乘法单元。
优选地,所述部分积移位相加阵列包括四级部分积移位相加阵列,所述四级部分积移位相加阵列包括:
8个s4a8单元:将两两4bit精度的无符号乘法单元的输出做移位相加,得到8个8bitx4bit的输出;
4个s4a12单元:将两两s4a8单元的输出做移位相加,得到4个8bitx8bit的输出;
2个s8a16单元:将两两s4a12单元的输出做移位相加,得到2个16bitx8bit的输出;
1个s8a24单元:将两个s8a16单元的输出做移位相加,得到1个16bitx16bit的输出。
优选地,所述无符号乘法单元包括:array乘法器或基于华莱士树的乘法器。
优选地,所述无符号乘法单元的最小精度为4bit。
优选地,所述精度选择信号包括cp[4:0];
当cp[0]为1,表示当前精度为16bitx16bit;
当cp[1]为1,表示当前精度为16bitx8bit;
当cp[2]为1,表示当前精度为8bitx8bit;
当cp[3]为1,表示当前精度为8bitx4bit;
当cp[4]为1,表示当前精度为4bitx4bit。
优选地,所述第一重映射模块、所述第二重映射模块和所述第三重映射模块分别根据精度选择信号将输入信号对应映射到所述第一加法阵列、所述第二加法阵列和所述第三加法阵列中的加法器上,经过加法阵列产生对应精度的结果。
根据本发明提供的一种适用于深度学习硬件加速器的可配置精度的卷积硬件结构,包括:第一重映射模块、第二重映射模块、第三重映射模块、第一加法阵列、第二加法阵列、第三加法阵列、多个无符号乘法单元和部分积移位相加阵列;
所述第一重映射模块和所述第二重映射模块的输出端分别连接所述第一加法阵列和所述第二加法阵列的输入端,所述第一加法阵列和所述第二加法阵列的输出端连接所述多个无符号乘法单元的输入端,所述多个无符号乘法单元的输出端连接所述部分积移位相加阵列的输入端,所述部分积移位相加阵列的输出端连接所述第三重映射模块的输入端,所述第三重映射模块的输出端连接所述第三加法阵列的输入端;
其中所述第一重映射模块、所述第二重映射模块和所述第三重映射模块根据精度选择信号选择数据通路;
所述第一重映射模块、所述第二重映射模块和所述第三重映射模块根据精度选择信号对输入信号进行相应的变换;
所述第一加法阵列、所述第二加法阵列和所述第三加法阵列能够对输入数据进行补码;
所述第一加法阵列和所述第二加法阵列分别包括16个加法器构成的加法阵列;所述第三加法阵列包括32个加法器构成的加法阵列;
所述多个无符号乘法单元包括16个4bit精度的无符号乘法单元;
所述部分积移位相加阵列包括四级部分积移位相加阵列,所述四级部分积移位相加阵列包括:
8个s4a8单元:将两两4bit精度的无符号乘法单元的输出做移位相加,得到8个8bitx4bit的输出;
4个s4a12单元:将两两s4a8单元的输出做移位相加,得到4个8bitx8bit的输出;
2个s8a16单元:将两两s4a12单元的输出做移位相加,得到2个16bitx8bit的输出;
1个s8a24单元:将两个s8a16单元的输出做移位相加,得到1个16bitx16bit的输出;
所述无符号乘法单元包括:array乘法器或基于华莱士树的乘法器;
所述无符号乘法单元的最小精度为4bit;
所述精度选择信号包括cp[4:0];
当cp[0]为1,表示当前精度为16bitx16bit;
当cp[1]为1,表示当前精度为16bitx8bit;
当cp[2]为1,表示当前精度为8bitx8bit;
当cp[3]为1,表示当前精度为8bitx4bit;
当cp[4]为1,表示当前精度为4bitx4bit;
所述第一重映射模块、所述第二重映射模块和所述第三重映射模块分别根据精度选择信号将输入信号对应映射到所述第一加法阵列、所述第二加法阵列和所述第三加法阵列中的加法器上,经过加法阵列产生对应精度的结果。
与现有技术相比,本发明具有如下的有益效果:
本发明设计的卷积核单元可以动态切换多种计算精度,与此相对应的多种级别的神经网络的计算能力可以满足大多数应用的需求。与此同时,本发明设计了可以复用的硬件单元,辅助流水线的结构,既能够达到很快的工作频率,也能够节省硬件面积。
附图说明
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
图1为本发明的结构框图。
具体实施方式
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于本发明的保护范围。
本发明提供的一种适用于深度学习硬件加速器的可配置精度的卷积硬件结构,包括:第一重映射(remap)模块、第二重映射模块、第三重映射模块、第一加法阵列、第二加法阵列、第三加法阵列、多个无符号乘法单元和部分积移位相加阵列;
第一重映射模块和第二重映射模块的输出端分别连接第一加法阵列和第二加法阵列的输入端,第一加法阵列和第二加法阵列的输出端连接多个无符号乘法单元的输入端,多个无符号乘法单元的输出端连接部分积移位相加阵列的输入端,部分积移位相加阵列的输出端连接第三重映射模块的输入端,第三重映射模块的输出端连接第三加法阵列的输入端;
其中第一重映射模块、第二重映射模块和第三重映射模块根据精度选择信号进行相应的变换,选择数据通路。
在16bit精度下,输入乘数a[15:0]与被乘数b[15:0]可以拆分为4个4比特的数移位相加,如下所示:
a[15:0]=(a[15:12]<<12)+(a[11:8]<<8)+(a[7:4]<<4)+(a[3:0])
b[15:0]=(b[15:12]<<12)+(b[11:8]<<8)+(b[7:4]<<4)+(b[3:0])
因此,乘法a[15:0]*b[15:0]代入上述公式然后展开可得16个4比特的乘法,如下公式所示,
a[15:0]*b[15:0]=
((a[15:12]*b[3:0])<<12)+((a[11:8]*b[3*0])<<8)+((a[7:4]*b[3*0])<<4)+((a[3:0]*b[3*0])<<0)+((a[15:12]*b[7*4])<<16)+((a[11:8]*b[7*4])<<12)+((a[7:4]*b[7*4])<<8)+((a[3:0]*b[7*4])<<4)+((a[15:12]*b[11*8])<<20)+((a[11:8]*b[11*8])<<16)+((a[7:4]*b[11*8])<<12)+((a[3:0]*b[11*8])<<8)+((a[15:12]*b[15*12])<<24)+((a[11:8]*b[15*12])<<20)+((a[7:4]*b[15*12])<<16)+((a[3:0]*b[15*12])<<12)
如上16比特精度的重映射所示,第一重映射模块根据精度将乘数a拆分为适用于乘法器的对应输入;第二重映射模块根据精度将被乘数b拆分为适用于乘法器的对应输入;第三重映射模块根据精度将16个乘法器的输出进行合并。其他精度的拆分与合并原理与16比特精度的原理相同。
优选实施例:
如图1所示,输入信号有cp[4:0](精度选择信号),a[63:0](乘数),b[63:0](被乘数)。输出信号有p[127:0](积)。
其中cp为输入精度选择信号,通过配置cp以控制硬件中的remap模块和数据通路,这样选择不同精度的部分积模块进入加法阵列,最后输出不同精度的计算结果。
1.cp[0]为1,表示当前精度为16bitx16bit
2.cp[1]为1,表示当前精度为16bitx8bit
3.cp[2]为1,表示当前精度为8bitx8bit
4.cp[3]为1,表示当前精度为8bitx4bit
5.cp[4]为1,表示当前精度为4bitx4bit
本实施例包括三个remap模块,三个加法阵列,16个4bit精度的无符号乘法单元和4级部分积的移位相加阵列。其中remap模块根据精度选择信号将输入的信号a和b做相应的变换,同时将乘法器产生的结果做相应的变换。两组16个加法阵列和一组32个加法阵列作用是求取输入数据和输出结果的补码。16个4bit精度的乘法器是硬核单元,处理4bit精度的无符号乘法运算。8个s4a8单元将两两4bit乘法结果做移位相加,可以得到8个8bitx4bit的乘法结果。4个s4a12单元将两两s4a8的输出结果做移位相加,可以得到4个8bitx8bit的乘法结果。2个s8a16单元将两两s4a12的输出结果做移位相加,可以得到2个16bitx8bit的乘法结果。1个s8a24单元将两两s8a16的输出结果做移位相加,可以得到1个16bitx16bit的乘法结果。
输入的信号a经过remap模块,在精度选择控制信号的作用下,根据不同的模式映射到后级的16个加法器阵列的输入口上,经过加法器阵列后,产生了对应不同精度的a的补码,输出给16个无符号乘法器的乘数输入端口。输入的信号b经过remap模块,在精度选择控制信号的作用下,根据不同的模式映射到后级的16个加法器阵列的输入口上,经过加法器阵列后,产生了对应不同精度的b的补码,输出给16个无符号乘法器的被乘数输入端口。
16个无符号乘法器不限于结构,可以使用array乘法器,可以使用基于华莱士树的乘法器,本发明不限制乘法器的内部结构。变换后的乘数a的补码和被乘数b的补码经过乘法器后输出16个4bitx4bit的结果p[15:0][7:0]。然后,16个结果同时输送给8个s4a8单元和第三级remap模块,经过s4a8单元后产生8个8bitx4bit的结果p[7:0][11:0]。然后,8个结果同时输送给4个s4a12单元和第三级remap模块,经过s4a12单元后产生4个8bitx8bit的结果p[3:0][15:0]。然后,4个结果同时输送给2个s8a16单元和第三级remap模块,经过s8a16单元后产生2个16bitx8bit的结果p[1:0][23:0]。然后,2个结果同时输送给1个s8a24单元和第三级remap模块,经过s8a24单元后产生1个16bitx16bit的结果p[31:0]。
第三级remap模块汇总4bitx4bit、8bitx4bit、8bitx8bit、16bitx8bit和16bitx16bit的结果,根据精度选择信号再一次变换,产生不同精度的补码,输出给32个加法器阵列。经过加法器阵列后,得到不同精度的乘法结果的补码,即为有符号数的乘法结果。
本发明的结构清晰,可以根据实际需求插入寄存器流水线以满足不同时钟频率的要求。
上述实施例采用了三组共享的加法阵列来变换乘数、被乘数与积的符号,对于不同精度的运算,加法阵列可以共享,减小了硬件面积。采用了一组最小精度为4bit的乘法器阵列,阵列中的乘法单元可以按照规则组成高精度的8bit、16bit乘法器单元,灵活且可配置。采用了4级移位加法运算单元,每一级单元使用上一级单元产生的结果进行运算,在产生16bit精度的乘法运算的过程中,同时可以得到不同精度的乘法运算结果,复用了移位加的阵列。
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改,这并不影响本发明的实质内容。在不冲突的情况下,本申请的实施例和实施例中的特征可以任意相互组合。
- 还没有人留言评论。精彩留言会获得点赞!