一种基于蚁群算法的云副本放置方案的制作方法
本发明针对云计算中的数据调度和访问效率问题,具体是一种基于蚁群算法的云副本放置方案。
背景技术:
随着互联网的发展,复杂而庞大的数据需要被处理。据互联网数据中心的研究报告显示,未来数据的增长是几何式的,特别是移动终端。因此,海量数据的及时有效处理就成为了亟待解决的问题。云计算技术的兴起,尤其是云存储技术的出现,使多种类型的存储设备连接起来进行信息交互,并实现了协同合作。云计算环境由于数据量大和存储设备和网络设备差异的原因,会导致数据的丢失和出错,而副本技术的出现,能够有效的解决这种问题。通常在存储系统中采用多个副本,这样可以保证存储系统中数据的高可用性和高容错率。
由于系统性能和节点负载密切相关,云存储记录会表现新近数据的局部性特点。如果系统负载不均衡,单个节点的数据存储负载量会增大,用户对节点的访问性能将大大降低。同样,热点数据分布不均衡也会影响用户的读写性能。因此,如何在云存储系统中合理放置副本是一个值得研究的问题。
蚁群算法是意大利学者dorigom从自然界中蚂蚁觅食行为中发现其觅食路径会逐渐收敛,最终找到最佳的觅食路径。根据这一现象,抽象出蚁群算法这一仿生算法。蚂蚁在外出四处觅食时,所经过的地方都会留下挥发性物质,学界称之为蚂蚁的“信息素”,蚂蚁对路径中留下的信息素有感知能力,能够感受到信息素的强弱,并趋向于信息素浓度高的路径。设想有一食物放在远处,蚂蚁从巢穴去觅食。有不同距离的路径,但路径长的信息素也会挥发快。距离食物近的路径信息素就会高,这样就会吸引更多的蚂蚁前来觅食,这种正反馈机制使距离食物近的路径的信息素浓度越来越高,蚂蚁也逐渐收敛到最佳的路径中。
根据前面对蚁群算法介绍可得,蚂蚁k(k=1,2,..m)在觅食的过程中,会留下信息素。信息素在路径上的浓度可以决定蚂蚁的数量和行走的方向,而蚁群中最佳路径上的信息素会越来越浓,蚂蚁的活动范围也会逐渐收敛到一条路径上,此条路径便是解决工程问题的解。为了方便表示这一过程,可以把路径的集合映射到tabuk(k=1,2..m)中表示。蚂蚁在整个觅食过程中,蚁群的路径使动态变化的,而集合中的数据也会根据这些变化做出调整。设τij(t)是t时刻从i节点到节点的信息素浓度,则t时刻蚂蚁k在(i,j)区间上的概率可表示为
公式α表示启发因子,β表示期望启发因子,ηij表示哈数属性。在所有蚂蚁觅食路径中,蚂蚁数量越多说明此路径信息素的浓度越高。为了避免信息素随着时间而挥发,造成整个蚁群的收敛性变差,所以需要对信息素进行必要的更新。用1-ρ表示挥发程度,
τij(t+w)=(1-ρ)×τij(t)+δτij(t)
蚁群算法作为一种受自然界蚁群启发的仿生算法有很多应用领域,最早应用于旅行商问题,并取得了良好的优化效果。最近几年,学界对蚁群算法也做出了各种各样的改进,应用领域也延申到了任务调度、数据挖掘、车辆路径等领域。蚁群算法也会和各种其它的算法进行结合,如遗传算法、模拟退火算法等。蚁群算法中启发因子、期望启发因子、信息素挥发因子等关键参数的设定会影响算法的收敛性。
现有技术对云计算中的数据调度和访问效率方面的研究仍有所欠缺,且在副本管理技术中,作为关键问题的副本放置研究相对较少,还需进一步研究。
技术实现要素:
本发明的目的是针对现有技术的不足,而提供一种基于蚁群算法的云副本放置方案。这种方案能改进蚁群的信息素更新策略和结合拉普拉斯概率分布优化副本放置过程,最终实现副本的数量和位置的调整和优化。
实现本发明目的的技术方案是:
一种基于蚁群算法的云副本放置方案,与现有技术不同的是,包括如下步骤:
1)确定副本放置模型:
在云存储系统中,在副本被创建之后,用户需要对副本进行合理的放置以保证数据的访问的性能,系统会在一系列副本中选出最佳的副本进行放置,不同系统的副本放置的标准也会不同,当有符合系统要求多个副本需要放置时,通过统计不同文件的访问开销,首先对文件访问频率贡献大的副本进行放置,定义文件的访问频率为公式(1):
r表示整个系统中的副本的个数,filer(f)表示高频率文件在副本r中频率的大小,用
文件所应放置的副本的数量
最后响应给请求的用户,副本放置中有以下两个关键的过程:
(1)根据用户请求中给定的检索文件名,通过云存储系统的副本管理器查找该检索文件名对应的若干个副本位置信息集合;
(2)在问题(1)的基础上,查找出的若干个副本信息集合后,利用相关副本放置策略再进行相关副本的放置,为了提高存储资源的利用率和数据文件的可靠性,应该综合考虑网络的访问性能、负载均衡、响应延迟和存储开销等方面,满足用户的动态需求,如放置副本时,需考虑是放置在本地还是远程放置,因此,可以说副本放置问题是综合多种因素进行求解优化的过程;
2)定义蚁群优化算法与副本放置结合:结合的3个原则为:
(1)把蚂蚁觅食时行走的路径抽象成目标放置前选择的过程,把路径集合抽象成一个解空间;
(2)蚂蚁移动过程中,会留下信息素,信息素会随着时间在较短路径上越来越浓,选择这条路的蚂蚁也会越来越多;
(3)蚁群信息素的正反馈作用,使蚁群的行走路径逐渐变得统一,最终到达目的地,完成对目标的放置,此条路径便是目标放置的最优解;
依据以上原则,则有把蚁群抽象成选择放置副本的检索文件rf(retrievefiles,简称rf),同时会为该文件创建和寻找相应的副本,把蚂蚁行走路径的集合抽象为副本对象的集合r={r1,r2,...rn},这样蚂蚁觅食的过程就变成了检索文件寻找相应副本并放置的过程;
假设蚂蚁寻食行走的路径集合为p={p1,p2,...,pn},这里n为蚂蚁的个数;觅食过程中所产生的信息素表示为集合γ={τ1,τ2,...τn},
设置整个蚁群是一个可行解的解空间,整个蚁群表示为a,整个流程开始之前,需要对副本的信息素值进行初始化如公式(3):
其中,replicasize指的是副本大小,readspeed指的是读取的速度,从公式(3)中可以看出读取速度越大,副本越小,信息素的初值就会越大,
当副本被访问多次之后,信息素会相应的发生变化,信息素相应的属性值也需要调整,表达式为公式(4):
τi(t+1)=ρ·τi(t)+δτi(t)(4)
信息素挥发系数ρ的设定是否合理会影响蚁群的搜索能力和计算效率,在结合传统信息素更新方法上,引入动态改变ρ值,使ρ能自适应的改变大小,从而保证算法的综合性能,调整策略如公式(5)、如公式(6):
ρa(t)=1-ln(t)/ln(t+c)(5)
其中c为常数,ρ的取值是信息素动态更新的关键,ρ太大会使全局搜索能力下降,ρ太小会使局部搜索能力变差,收敛的速度也会变慢,为了使信息素挥发性系数ρ在一定范围内具有自适应性,信息素挥发系数ρ控制在[ρmin,ρmax],并对其取值为[0.2,0.8],这样可以拉开副本间信息素的差距,并在后期加快收敛的速度;
蚁群在路径上留下的信息素的浓度和副本能否被放置有着密切的联系,在信息素浓度越高的地方,副本被放置的概率就会越大,副本放置的概率公式定义如公式(7):
其中τj(t)指的是副本j在t时刻的信息素的浓度,ηj表示副本本身的固有属性,α和β分别分别指代副本当前的信息素启发因子和期望启发因子,如果α比β的值大,说明在节点选择中,信息素浓度的作用比副本固有属性的影响大,为避免蚁群算法过早陷入局部最优,使算法综合求解性能较好,取α为3,β为1.5;
在传统的蚁群算法中,副本放置的概率选择都是采用随机概率rand结合公式(7)进行概率匹配,随机性概率选择策略可以避免出现停滞现象,但是收敛的速度慢,为使算法能较快的收敛于最优解,引入了拉普拉斯概率分布的思想,采用最大概率选择的方法,在原有蚁群算法的基础上进行了改进,在副本放置的过程中,先计算出转移概率最大的对象maxp,再进行循环遍历,计算出副本放置对象的概率和最大概率maxp之间的距离,选取最靠近maxp的副本进行放置,可得公式(8):
p(i)=[maxp-rand,maxp+rand],i={1,2,...m}(8)
则第i个副本对象将会被选择放置;
由公式(7)可得副本信息素的浓度越高,则副本在被选择放置的时候,被选中的概率就会越大,但是在考虑放置副本的时候,节点的负载和网络的畅通也是考虑的重要的因素,引入类拉普拉斯概率分布选择最大概率副本进行放置的方法,可以有效防止网络的拥塞并在一定的程度上节省了存储的空间;
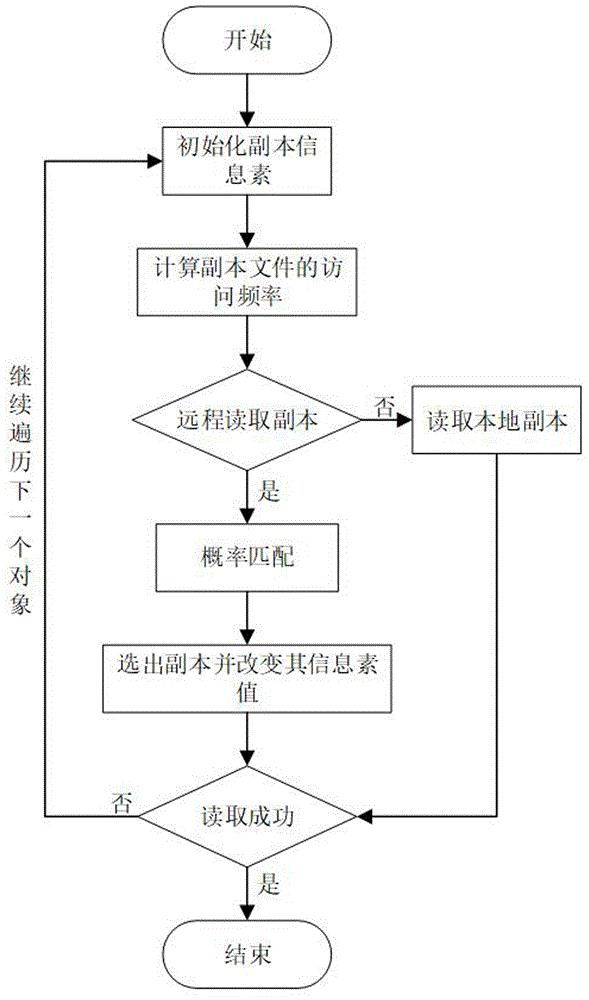
3)蚁群优化副本放置:云存储系统在受到副本文件rf的请求后,对信息素的副本依次进行放置,包括:
(1)初始化副本信息素,客户端对系统提出访问请求,确定分布式文件系统的集群是否可用的;
(2)统计周期t中的各个文件被访问的次数,根据式(1)计算副本文件rf的访问频率和存储的节点情况;
(3)根据文件的热度情况设立热度阈值hmax、hmin,规定增加副本数量的临界值hmax和减少副本副本数量的临界值hmin;
(4)确定副本的数量:将计算出的热度值与hmax、hmin进行比较,若大于hmax,则增加副本数,若小于hmin,则减少副本数,若在[hmin、hmax]区间内则保持副本数量不变;
(5)若副本文件存储在远程节点,则依据改进蚁群策略进行副本的放置;
(6)对副本对象进行概率匹配,据选择的概率根据公式(7)、(8)选出合适的副本;
(7)选择出副本之后,数据传往终端,终端在获取副本之前,使用公式(5)减小副本信息值,降低被重复访问的概率,平衡节点负载;
(8)若副本在本地进行存储,则直接读取本地副本,不必执行蚁群副本放置;
(9)若副本的相关数据没有被读取成功,则跳转到步骤(2)进行下一个副本对象的读取;
(10)当副本被读取成功的时候,判断是不是最后一个副本对象,如果是,则结束副本放置,如果不是,再次读取下一个副本对象,进行改进蚁群副本放置。
本技术方案是针对现有副本放置策略在数据调度和访问效率方面的不足,提出一种改进的副本放置策略,提出统计文件的访问频率,根据访问频率设置访问频率的阈值,完成副本数量的调整,然后结合改进的蚁群算法完成副本的放置,主要改进蚁群的信息素更新策略和结合拉普拉斯概率分布优化副本放置过程,最终实现副本的数量和位置的调整和优化。
这种方案能改进蚁群的信息素更新策略和结合拉普拉斯概率分布优化副本放置过程,最终实现副本的数量和位置的调整和优化。
附图说明
图1为实施例方案中蚁群优化副本放置流程示意图。
具体实施方式
下面结合附图和实施例对本发明的内容作进一步的阐述,但不是对本发明的限定。
实施例:
参照图1,一种基于蚁群算法的云副本放置方案,包括如下步骤:
1)确定副本放置模型:
在云存储系统中,在副本被创建之后,用户需要对副本进行合理的放置以保证数据的访问的性能,系统会在一系列副本中选出最佳的副本进行放置,不同系统的副本放置的标准也会不同,当有符合系统要求多个副本需要放置时,通过统计不同文件的访问开销,首先对文件访问频率贡献大的副本进行放置,定义文件的访问频率为公式(1):
r表示整个系统中的副本的个数,filer(f)表示高频率文件在副本r中频率的大小,用
文件所应放置的副本的数量
最后响应给请求的用户,副本放置中有以下两个关键的过程:
(1)根据用户请求中给定的检索文件名,通过云存储系统的副本管理器查找该检索文件名对应的若干个副本位置信息集合;
(2)在问题(1)的基础上,查找出的若干个副本信息集合后,利用相关副本放置策略再进行相关副本的放置,为了提高存储资源的利用率和数据文件的可靠性,应该综合考虑网络的访问性能、负载均衡、响应延迟和存储开销等方面,满足用户的动态需求,如放置副本时,需考虑是放置在本地还是远程放置,因此,可以说副本放置问题是综合多种因素进行求解优化的过程;
2)定义蚁群优化算法与副本放置结合:结合的3个原则为:
(1)把蚂蚁觅食时行走的路径抽象成目标放置前选择的过程,把路径集合抽象成一个解空间;
(2)蚂蚁移动过程中,会留下信息素,信息素会随着时间在较短路径上越来越浓,选择这条路的蚂蚁也会越来越多;
(3)蚁群信息素的正反馈作用,使蚁群的行走路径逐渐变得统一,最终到达目的地,完成对目标的放置,此条路径便是目标放置的最优解;
依据以上原则,则有把蚁群抽象成选择放置副本的检索文件rf,同时会为该文件创建和寻找相应的副本,把蚂蚁行走路径的集合抽象为副本对象的集合r={r1,r2,...rn},这样蚂蚁觅食的过程就变成了检索文件寻找相应副本并放置的过程;
假设蚂蚁寻食行走的路径集合为p={p1,p2,...,pn},这里n为蚂蚁的个数;觅食过程中所产生的信息素表示为集合γ={τ1,τ2,...τn},
设置整个蚁群是一个可行解的解空间,整个蚁群表示为a,整个流程开始之前,需要对副本的信息素值进行初始化如公式(3):
其中,replicasize指的是副本大小,readspeed指的是读取的速度,从公式(3)中可以看出读取速度越大,副本越小,信息素的初值就会越大,
当副本被访问多次之后,信息素会相应的发生变化,信息素相应的属性值也需要调整,表达式为公式(4):
τi(t+1)=ρ·τi(t)+δτi(t)(4)
信息素挥发系数ρ的设定是否合理会影响蚁群的搜索能力和计算效率,在结合传统信息素更新方法上,引入动态改变ρ值,使ρ能自适应的改变大小,从而保证算法的综合性能,本例的调整策略如公式(5)、如公式(6):
ρa(t)=1-ln(t)/ln(t+c)(5)
其中c为常数,ρ的取值是信息素动态更新的关键,ρ太大会使全局搜索能力下降,ρ太小会使局部搜索能力变差,收敛的速度也会变慢,为了使信息素挥发性系数ρ在一定范围内具有自适应性,信息素挥发系数ρ控制在[ρmin,ρmax],并对其取值为[0.2,0.8],这样可以拉开副本间信息素的差距,并在后期加快收敛的速度;
蚁群在路径上留下的信息素的浓度和副本能否被放置有着密切的联系,在信息素浓度越高的地方,副本被放置的概率就会越大,副本放置的概率公式定义如公式(7):
其中τj(t)指的是副本j在t时刻的信息素的浓度,ηj表示副本本身的固有属性,α和β分别分别指代副本当前的信息素启发因子和期望启发因子,如果α比β的值大,说明在节点选择中,信息素浓度的作用比副本固有属性的影响大,为避免蚁群算法过早陷入局部最优,使算法综合求解性能较好,本例取α为3,β为1.5;
在传统的蚁群算法中,副本放置的概率选择都是采用随机概率rand结合公式(7)进行概率匹配,随机性概率选择策略可以避免出现停滞现象,但是收敛的速度慢,为使算法能较快的收敛于最优解,本例引入了拉普拉斯概率分布的思想,采用最大概率选择的方法,在原有蚁群算法的基础上进行了改进,在副本放置的过程中,先计算出转移概率最大的对象maxp,再进行循环遍历,计算出副本放置对象的概率和最大概率maxp之间的距离,选取最靠近maxp的副本进行放置,可得公式(8):
p(i)=[maxp-rand,maxp+rand],i={1,2,...m}(8)
则第i个副本对象将会被选择放置;
由公式(7)可得副本信息素的浓度越高,则副本在被选择放置的时候,被选中的概率就会越大,但是在考虑放置副本的时候,节点的负载和网络的畅通也是考虑的重要的因素,本例引入类拉普拉斯概率分布选择最大概率副本进行放置,可以有效防止网络的拥塞并在一定的程度上节省了存储的空间;
3)蚁群优化副本放置:云存储系统在受到副本文件rf的请求后,对信息素的副本依次进行放置,包括:
(1)初始化副本信息素,客户端对系统提出访问请求,确定分布式文件系统的集群是否可用的;
(2)统计周期t中的各个文件被访问的次数,根据式(1)计算副本文件rf的访问频率和存储的节点情况;
(3)根据文件的热度情况设立热度阈值hmax、hmin,规定增加副本数量的临界值hmax和减少副本副本数量的临界值hmin;
(4)确定副本的数量:将计算出的热度值与hmax、hmin进行比较,若大于hmax,则增加副本数,若小于hmin,则减少副本数,若在[hmin、hmax]区间内则保持副本数量不变;
(5)若副本文件存储在远程节点,则依据改进蚁群策略进行副本的放置;
(6)对副本对象进行概率匹配,据选择的概率根据公式(7)、(8)选出合适的副本;
(7)选择出副本之后,数据传往终端,终端在获取副本之前,使用公式(5)减小副本信息值,降低被重复访问的概率,平衡节点负载;
(8)若副本在本地进行存储,则直接读取本地副本,不必执行蚁群副本放置;
(9)若副本的相关数据没有被读取成功,则跳转到步骤(2)进行下一个副本对象的读取;
(10)当副本被读取成功的时候,判断是不是最后一个副本对象,如果是,则结束副本放置,如果不是,再次读取下一个副本对象,进行改进蚁群副本放置。
实验验证:
实验验证采用cloudsim云计算仿真器进行实验的仿真。cloudsim支持云计算环境的资源模拟,可以对副本管理中相关环境进行仿真模拟,利用cloudsim的扩展性,修改host和datacenter类,添加新的副本放置组件完成副本放置工作,比较副本访问时间的开销、网络利用率和负载均衡度。本实验验证对改进蚁群算法、原始蚁群算法和min-min算法进行仿真,实验环境为:软件采用window10操作系统cloudsim3.0.3,硬件采用i5-7300hq@2.5ghz,内存为8gb。
cloudsim仿真实验步骤:
step1:初始化cloudsim包;
step2:创建数据中心;
step3:创建数据代理中心;
step4:创建云任务;
step5:读取副本,并进行副本对象的放置;
step6:启动仿真;
step7:仿真结束后分析结果。
实验验证说明本例提供的方案在系统平均作业完成时间、网络利用率和负载均衡等方面有较好的表现。
- 还没有人留言评论。精彩留言会获得点赞!