一种面向离散制造车间的三维射频识别网络布局优化方法与流程
本发明属于射频识别领域,尤其涉及一种面向离散制造车间的三维射频识别网络布局优化方法。
背景技术:
离散制造车间具有产品结构复杂、零部件众多、生产周期长和车间面积大等特点。为实现对离散制造车间生产数据的动态采集、制造过程的实时监控和产品质量的高效回溯等,将rfid技术应用于离散制造车间。为控制rfid硬件成本及扩大rfid感知范围,多选用超高频无源rfid标签、多通道读写器和定向圆极化天线,构成rfid系统的硬件底层。
目前,随着rfid技术应用领域的不断扩大,rfid网络规划问题受到了广泛关注。大部分学者在求解该问题时,预先定义rfid标签的数量及各标签的分布情况,通过改变rfid读写器的数量和移动rfid读写器的位置,实现读写器对标签最大范围覆盖,读写器间交叉覆盖区域最小,所需读写器数量最少,同时各读写器所负载的标签数量均衡。而离散制造车间内rfid标签数量由具体的生产订单决定,且标签随车间工人转运或加工等操作出现在不同位置,无法预先确定rfid标签位置和数量,因此需通过rfid读写器对可能出现rfid标签的区域进行覆盖,有效采集离散制造现场的生产数据。
在离散制造车间,大量存储生产要素信息的rfid标签在各工位间流转,分散于工作区域内不同位置和高度。传统的二维射频识别网络规划方法将rfid标签位置理想化为同一平面,未考虑标签在高度上的差异;同时,离散制造车间存在大量固定的金属结构,如支架、工作台等,而射频信号难以穿透金属障碍物,将对rfid读写器与标签的通讯建立造成较大影响。
技术实现要素:
发明目的:针对上述,现有技术未考虑标签在高度上存在差异的缺陷;和离散制造车间中大量固定的金属结构影响rfid读写器与标签通讯的问题;本发明提供一种面向离散制造车间的三维射频识别网络布局优化方法。
技术方案:本发明提供一种面向离散制造车间的三维射频识别网络布局优化方法。该方法具体包括如下步骤:
步骤1:将目标空间离散为若干个单位立方体,并将存在金属障碍物的立方体的状态属性值bxyz赋值为0,将工人的操作区域或生产要素流转区域所在的单位立方体的状态属性值bxyz赋值为1,排除状态属性值被赋为0和1的单位立方体后选择高度在0.1~2米的区域所在的单位立方体并给该单位立方体的状态属性值bxyz赋值为2;除状态属性值被赋为0、1、2的单位立方体外,将其他的单位立方体的状态属性值bxyz赋值为3;
步骤2:将标签与读写器的空间距离小于读写器的感知距离lr、标签与读写器的空间连线与rfid天线平面法向量的夹角小于读写器的感知夹角θr,且标签与读写器之间不存在状态属性值bxyz为0的单位立方体,作为标签能够被该读写器感知的条件;
步骤3,基于上述感知条件,构建多目标优化模型;
步骤4:利用多目标混合粒子群算法求解上述多目标优化模型,且在粒子群中的粒子相似时引入遗传算法,即进行交叉和变异的操作,从而得到rfid网络优化的解集。
进一步的,所述多目标优化模型包括标签覆盖率cov,读写器间的相互干扰率inf,和读写器的部署成本cos;具体的标签覆盖率cov的表达式如下所示:
其中nt表示状态属性值bxyz为1的单位立方体的总数量,;
读写器间的相互干扰率inf表达式如下所示:
其中;nr为读写器的个数,
读写器的部署成本cos表达式如下所示:
cos=nr*c
其中,c为单个读写器的部署成本。
进一步的,所述步骤4的具体方法为:
步骤4.1:初始化粒子群规模即粒子的个数为m,令迭代次数t=1;将nr个读写器投入使用,则每个粒子中有nr个读写器状态值为1,逐个初始化读写器的位置和方向,并验证初始化后的该读写器的位置是否合理,如果合理则初始化下一个读写器,否则重新初始化该读写器直至该读写器位置合理;nr=nmin,nmin+1,...,nmax;nr、nmin和nmax均为自然数,nmax为被投入使用的读写器的最大个数,nmin为被投入使用的读写器的最小个数;t=1,2,3,...,gt;gt为最大迭代次数;
步骤4.2:如果t=1,根据多目标优化模型,遍历每个粒子,确定每个粒子之间的支配关系,并将不被其他粒子支配的粒子作为非劣解存储,得到非劣解集;否则根据多目标优化模型,遍历第t次迭代计算中的每个粒子和第t-1次迭代计算得到的非劣解集中的非劣解;确定第t次迭代计算中的各粒子之间以及各个粒子与第t-1次迭代计算中的所有非劣解之间的支配关系,将第t次迭代计算得到的非劣解集替换第t-1次迭代计算得到的非劣解集并保存;
步骤4.3:如果t<gt,则转步骤4.4,否则转步骤4.5;
步骤4.4:依次更新所有粒子,并计算更新后所有粒子的多目标优化模型中各函数的值,根据更新后的粒子群的标签覆盖率方差
步骤4.5:如果nr<nmax,则nr+1并转步骤4.1;否则转步骤4.6;
步骤4.6:得到na=nmax-nmin+1个非劣解集,令该na个非劣解集为集合a,在集合a中,将第g个非劣解集中的每个非劣解与其余的非劣解集中的所有的非劣解进行支配关系判断,再次提取非劣解并保存;将得到的非劣解集作为rfid网络优化的解集;g=1,2,...,na。
进一步的,步骤4.1种具体判断读写器位置是否合理的方法为:如果读写器没有出现在状态属性值bxyz为0的单位立方体中并且该读写器与相邻读写器的空间距离大于1米,则该读写器的位置合理。
进一步的,步骤4.2中所述的每个粒子之间的支配关系的具体方法为:
比较粒子o与p的标签覆盖率covo、covp和粒子o、p中读写器间的相互干扰率info、infp,如果covo>covp并且info<infp,则粒子o支配粒子p;如果covo<covp,且info>infp,则粒子p支配粒子o;否则粒子o与粒子p互不支配。
进一步的,步骤4.4所述的更新所有的粒子,具体包括所有粒子的位置更新和个体极值的更新,具体的方法为:
步骤4.4.1:依次将每个粒子向个体极值和粒子群的群体极值飞行,从而更新每个粒子的位置;所示个体极值为每个粒子本身的极值;
步骤4.4.2:将更新位置后的每个粒子依次与其个体极值进行支配关系比较;若更新位置后的粒子能够支配其个体极值,则将更新位置后的粒子更新为新的个体极值;若个体极值能够支配更新位置后的粒子,则个体极值不变,若两者互不支配则在两者之间随机选择一个作为新的个体极值。
进一步的,所述群体极值为非劣解集中拥挤距离最大的粒子。
进一步的,步骤4.4中所述遗传算法的具体方法为:
步骤a:对某个优秀的粒子以0.85的概率判断是否进行交叉操作,若进行交叉操作,则令该粒子中第k个读写器的空间位置和方向与群体极值中第k个读写器的空间位置和方向一致,得到一个新的粒子,若该新粒子支配旧粒子,则保留新粒子;否则保留旧粒子;如果不进行交叉操作则直接保留该优秀的粒子;k为随机值,且k∈[1,nr];
步骤b:将步骤a中保留的粒子以0.1的概率判断是否进行变异操作,若进行变异操作,则利用如下公式对该粒子的第i个读写器的第j个变量进行变异操作:
进一步的,步骤4.4中所述的判断种群中的粒子是否相似的具体方法为:如果
其中covm为粒子m的标签覆盖率,m=1,2,...,m;
读写器之间干扰率方差
其中infm为粒子m中读写器间的相互干扰率。
进一步的,所述步骤4.6中具体支配关系判断的方法为:如果covy>covx,且infy<infx,cosy<cosx;则粒子y支配粒子x;如果covy<covx,且infy>infx,cosy>cosx则粒子x支配粒子y;其他情况下粒子y与粒子x互不支配,其中covy、infy、cosy分别为粒子y的标签覆盖率、粒子y中读写器间的相互干扰率和粒子y中读写器的部署成本;covx、infx、cosx分别为粒子x的标签覆盖率、粒子x中读写器间的相互干扰率和粒子x中读写器的部署成本;y∈a;x∈a并且粒子y与粒子x不属于同一个非劣解集。
有益效果:
1.本发明实用性强,设计了一种面向离散制造车间的三维射频识别网络布局优化方法,与传统二维射频识别网络布局优化模型相比,三维空间中的rfid网络模型更接近实际应用场景,可求解获得合适的rfid网络布局方案。
2.本发明在构造rfid读写器感知模型时,考虑了空间中存在的金属障碍物对射频信号的遮挡,有效地解决了离散制造车间射频信号遮挡严重的问题。
3.本发明同时优化多个目标,包括标签覆盖率、读写器间相互干扰率和部署成本,最后输出部署方案的多组非劣解,供车间决策者根据情况选择最合适的部署方案,克服传统rfid网络规划问题中将多个优化目标采用加权系数方法转换成单目标问题所引入的人为主观性。
4.本发明将粒子群算法和遗传算法相结合,改善了粒子群算法易陷入局部最优的缺陷,提高了算法的全局搜索能力,能够得到多组优秀的rfid网络布局方案。
附图说明
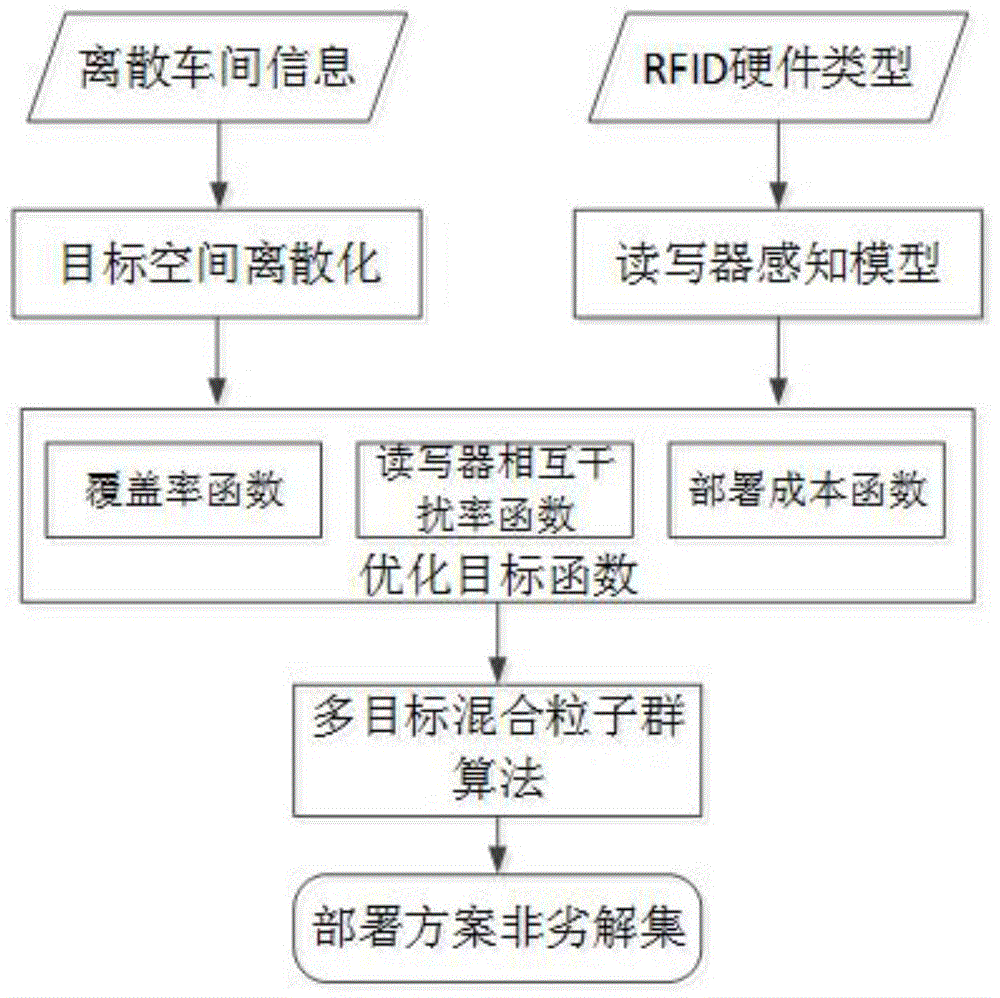
图1是本发明的总体体系结构图;
图2是本发明的硬件系统结构图;
图3是本发明rfid读写器模型示意图;
图4是本发明的多目标混合粒子群算法主流程图;
图5是本发明比较两个粒子支配关系的算法流程图;
图6是本发明的遗传操作流程图。
具体实施方式
由于目前大多数rfid设备读写速率较高,负载平衡对rfid网络性能大幅降低,且rfid标签的运动具有不确定性,各读写器覆盖的rfid标签数量不固定,因此本实施例中面向离散制造车间的三维rfid网络布局优化目标不包括负载平衡,仅考虑标签覆盖率、读写器间相互干扰率和部署成本。
本实施例为降低三维rfid网络规划问题的求解难度,需将目标空间离散为数量有限的单位立方体,并根据车间实际布局情况及标签的运动情况,记录各单位立方体的状态属性值。具体的为:将目标空间离散为若干个单位立方体,并将存在金属障碍物的立方体的状态属性值bxyz赋值为0,将工人的操作区域或生产要素流转区域所在的单位立方体(即存在rfid标签概率较大的单位立方体)的状态属性值bxyz赋值为1,排除状态属性值被赋为0和1的单位立方体后选择高度在0.1~2米的区域所在的单位立方体(即存在rfid标签概率较小的单位立方体)并给该单位立方体的状态属性值bxyz赋值为2;除状态属性值被赋为0、1、2的单位立方体外(即完全不可能出现rfid标签的单位立方),将其他的单位立方体的状态属性值bxyz赋值为3;
如图1所示,本实施例主要包括对目标空间离散化处理、rfid读写器三维感知模型构建、建立多目标优化模型、采用多目标混合粒子群算法求解模型等步骤。本实施例基于该三维射频识别网络布局优化方法,实现对离散制造车间rfid标签区域最大范围覆盖,减少读写器间的相互干扰率,使rfid数据准确性高,同时可大幅降低rfid部署成本。
结合离散制造车间特点,选择如图2所示的rfid硬件构建低成本高性能的rfid系统。该rfid系统由计算机、多通道固定式读写器、定向圆极化天线和超高频无源rfid标签组成。基于该rfid系统,对于多通道读写器网络规划问题,其实质为读写器所连接的rfid天线的布局优化问题,以下所提离散制造车间的rfid读写器均代指rfid天线。
带定向天线的rfid读写器三维感知模型如图3示,当标签与读写器的空间距离小于读写器的感知距离lr、标签与读写器的空间连线与rfid天线平面法向量的夹角小于读写器的感知夹角θr,且两者间不存在金属障碍物时,该标签被该读写器感知。具体的感知模型如下所示:
其中,(xr,yr,zr)为读写器在单位立方体内的坐标,(a,b,c)为天线平面法向量;(xt,yt,zt)为标签在空间内的坐标。barrier=0表明读写器坐标点与标签坐标点构成的空间连线所经过的单位立方体状态属性值bxyz均不为0,即读写器与标签间不存在金属障碍物。
本发明将标签覆盖率函数、读写器相互干扰率函数和部署成本函数作为优化目标函数,基于多目标混合粒子群算法同时优化以上目标。算法的主流程图如图4所示。
算法主流程步骤特征是:
步骤101.开始面向离散制造车间的三维rfid射频网络布局优化方法;
步骤102.输入离散化处理后的目标空间信息和读写器感知距离、感知夹角等性能参数,并由目标空间大小及读写器的性能参数确定所需读写器数量的最小值nmin和最大值nmax,同时设定算法相关参数;
步骤103.设定粒子位置的编码方式为
步骤104.初始化粒子群规模为m,令迭代次数t=1,将nr个读写器投入使用,则每个粒子中有nr个读写器状态值为1,逐个初始化读写器的位置和方向,并验证初始化后的该读写器的位置是否合理,使初始粒子群具有较好的性能,减少粒子的盲目飞行次数,加快算法求解;如果合理则初始化下一个读写器,否则重新初始化该读写器直至该读写器位置合理后再初始化下一个读写器;nr=nmin,nmin+1,...,nmax;t=1,2,3,...,gt;具体判断读写器位置是否合理的方法为:如果读写器没有出现在状态属性值bxyz为0的单位立方体中并且该读写器与相邻读写器的空间距离大于1米,则该读写器的位置合理。
步骤105.计算各粒子优化目标函数值如下:
标签覆盖率cov:
其中nt表示状态属性值bxyz为1的单位立方体的总数量,t∈nt;
读写器间相的互干扰率inf:
其中t2∈n;nr为读写器的个数,
读写器的部署成本cos:
cos=nr*c
其中,c为单个读写器的部署成本;
步骤106.如果t=1,根据多目标优化模型,遍历每个粒子,确定每个粒子之间的支配关系,并将不被其他粒子支配的粒子作为非劣解存储,得到非劣解集;否则根据多目标优化模型,遍历第t次迭代计算中的每个粒子和第t-1次迭代计算得到的非劣解集中的非劣解;确定第t次迭代计算中的各粒子之间以及各个粒子与第t-1次迭代计算中的所有非劣解之间的支配关系,将第t次迭代计算得到的非劣解集替换第t-1次迭代计算得到的非劣解集并保存;
步骤107.若迭代次数t≥gt,则转至步骤109,否则令迭代次数加1,并转至步骤108;gt为迭代次数的最大次数,本实施例设置为200次;
步骤108.依次更新所有粒子,并计算更新后所有粒子的多目标优化模型中各函数的值,根据更新后的粒子群的标签覆盖率方差
步骤109.若当前投入部署的读写器数量已达到预先设定的读写器数量最大值,则输出rfid网络优化解集,否则令nr=nr+1,即使第nr+1个读写器状态属性值为1,并跳转至步骤103;
步骤110.结束多目标混合粒子群算法;
如图5所示,所述步骤106,包括以下详细步骤:
步骤201:开始比较粒子间的支配关系;
步骤202:计算各粒子优化目标函数值,由于同一种群中投入部署的读写器数量相同,即部署成本相同,因此在迭代计算中仅需计算粒子的覆盖率cov和读写器相互干扰率inf;
比较粒子o与p的标覆盖率covo、covp和粒子o、p中读写器间的相互干扰率info、infp,如果covo>covp并且info<infp,则粒子o支配粒子p;如果covo<covp,且info>infp,则粒子o支配粒子p;否则粒子o与粒子p互不支配。
如图6所示为步骤108的流程图,具体如下:
步骤301:开始遗传操作算法;
步骤302:计算种群优化目标函数值方差第t代种群标签覆盖率方差
步骤303:若标签覆盖率方差
步骤304:对某个优秀的粒子以0.85的概率判断是否进行交叉操作,若进行交叉操作,则令该粒子中第k个读写器的空间位置和方向与群体极值中第k个读写器的空间位置和方向一致,得到一个新的粒子,若该新粒子支配旧粒子,则保留新粒子;否则保留旧粒子;如果不进行交叉操作则直接保留该优秀的粒子;k为随机值,且k∈[1,nr];
步骤305:将步骤304中保留的粒子以0.1的概率判断是否进行变异操作,若进行变异操作,则利用如下公式对该粒子的第i个读写器的第j个变量进行变异操作:
步骤306:结束遗传操作算法。
步骤108中更新粒子包括粒子的位置更新和个体极值更新;
粒子的位置更新为:依次将每个粒子向个体极值和粒子群的群体极值飞行,从而更新每个粒子的位置;所示个体极值为每个粒子本身的极值;
个体极值更新为:将更新位置后的每个粒子依次与其个体极值进行支配关系比较;若更新位置后的粒子能够支配其个体极值,则将更新位置后的粒子更新为新的个体极值;若个体极值能够支配更新位置后的粒子,则个体极值不变,若两者互不支配则在两者之间随机选择一个作为新的个体极值。
本实施例中群体极值选择非劣解集中拥挤距离最大的粒子。
本实施例中步骤109由于最后在所有非劣解集中选择非劣解需要考虑读写器的部署成本,具体的方法为:令得到的na=nmax-nmin+1个非劣解集为集合a,在集合a中,将第g个非劣解集中的每个非劣解与其余的非劣解集中的所有的非劣解进行支配关系判断,再次提取非劣解并保存;将得到的非劣解集作为rfid网络优化的解集;g=1,2,…,na。具体的支配关系判断为:如果covy>covx,且infy<infx,cosy<cosx;则粒子y支配粒子x;如果covy<covx,且infy>infx,cosy>cosx则粒子x支配粒子y;其他情况下粒子y与粒子x互不支配,其中covy、infy、cosyf分别为粒子y的标签覆盖率、粒子y中读写器间的相互干扰率和粒子y中读写器的部署成本;covx、infx、cosx分别为粒子x的标签覆盖率、粒子x中读写器间的相互干扰率和粒子x中读写器的部署成本;y∈a;x∈a并且粒子y与粒子x不属于同一个非劣解集。
本发明针对离散制造车间rfid网络布局环境及部署需求,构建多目标rfid网络布局优化模型,并将遗传算法与粒子群算法结合,求解该多目标优化问题,获得多个rfid读写器部署方案,以供离散制造车间决策者选择。本发明对离散制造车间部署rfid设备具有重要的理论指导意义,可有效推动rfid技术在车间的高效应用。
本发明未涉及部分均与现有技术相同或可采用现有技术加以实现。
另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合。为了避免不必要的重复,本发明对各种可能的组合方式不再另行说明。
- 还没有人留言评论。精彩留言会获得点赞!