一种人物关系补全方法及装置与流程
本发明涉及自然语言处理技术,尤其涉及一种人物关系补全方法及装置。
背景技术:
阅读,是一项非常好的习惯,可以给人带来丰富的知识,增强孩子们的知识面;也可以提升孩子的语言能力,发展孩子的思维能力等。因此家长们也越来越重视对孩子阅读习惯的培养。
而在孩子们在阅读时,如果书中人物关系复杂,常常会搞不清里面的人物关系,导致在阅读的时候不能很好的理解里面的内容。而家长的教育能力有强有弱,或不能付出足够的时间或精力来陪孩子们阅读,帮助其梳理书中的人物关系。因此,如何帮助孩子们理清人物关系,以便于他们更好的进行阅读理解是一个需要解决的技术问题。
技术实现要素:
为解决上述技术问题,本发明提供一种人物关系补全方法及装置,具体的,本发明的技术方案如下:
一方面,本发明公开了一种人物关系补全方法,包括:
采集用户语音信息;
根据所述用户语音信息,获取包含人物实体词或人物关系词的目标句式;
判断所述目标句式是否存在人物关系词残缺或人物实体词残缺;
当判定所述目标句式中存在人物关系词残词缺或人物实体词残缺时,获取所述用户当前阅读的书页图像;
识别所述书页图像中的文字信息,获取对应的书页文本信息;
通过训练好的人物关系抽取模型,对所述书页文本信息进行人物关系抽取,获得所述书页文本信息包含的人物实体词对及对应的人物关系词;
根据所述书页文本信息包含的人物实体词对及对应的人物关系词,补全所述目标句式中残缺的人物实体词或人物关系词;
根据补全后的目标句式,给所述用户以相应反馈。
优选地,在采集用户语料之前还包括:
获取标注了人物实体与人物关系的实体关系抽取训练样本;
将所述实体关系抽取训练样本输入初始模型进行训练学习,获得人物关系抽取模型。
优选地,所述通过训练好的人物关系抽取模型,对所述书页文本信息进行人物关系抽取,获得所述书页文本信息包含的人物实体词对及对应的人物关系词包括:
当判定所述目标句式中存在人物实体词残缺时,根据所述目标句式中已有的人物实体词及人物关系词,在所述书页文本信息中查找关联目标语句;
当判定所述目标句式中存在人物关系词残缺时,根据所述目标句式中已有的人物实体词对,在所述书页文本信息中查找关联目标语句;
将所述查找到的关联目标语句输入所述训练好的人物关系抽取模型进行人物关系抽取,获得若干组人物实体词对及其对应的人物关系词。
优选地,所述根据所述目标句式中已有的人物实体词及人物关系词,在所述书页文本信息中查找关联目标语句包括:
获取所述目标句式中已有的人物实体词的同义实体词;
获取所述目标句式中已有的人物关系词的同义关系词;
在所述书页文本信息中,查找与所述目标句式中的人物实体词、所述同义实体词、所述目标句式中已有的人物关系词、或所述同义关系词之中任意一个关键词相关的语句作为关联目标语句。
优选地,所述根据所述用户语音信息,获取包含人物实体词或人物关系词的目标句式包括:
识别所述语音信息,将所述语音信息转换为对应的文字信息;
将所述转换后的文字信息输入到所述人物关系抽取模型进行人物关系抽取,输出抽取出的人物实体词和/或人物关系词;
根据抽取出的人物实体词和/或人物关系词,生成对应的目标句式。
另一方面,本发明还公开了一种人物关系补全装置,包括:
语音采集模块,用于采集用户语音信息;
提取生成模块,用于根据所述用户语音信息,获取包含人物实体词或人物关系词的目标句式;
残缺判断模块,用于判断所述目标句式是否存在人物关系词残缺或人物实体词残缺;
图像采集模块,用于当判定所述目标句式中存在人物关系词残词缺或人物实体词残缺时,获取所述用户当前阅读的书页图像;
图像识别模块,用于识别所述书页图像中的文字信息,获取对应的书页文本信息;
人物关系抽取模块,用于通过训练好的人物关系抽取模型,对所述书页文本信息进行人物关系抽取,获得所述书页文本信息包含的人物实体词对及对应的人物关系词;
补全模块,用于根据所述书页文本信息包含的人物实体词对及对应的人物关系词,补全所述目标句式中残缺的人物实体词或人物关系词;
反馈模块,用于根据补全后的目标句式,给所述用户以相应反馈。
优选地,所述人物关系补全装置还包括:
样本获取模块,用于获取标注了人物实体与人物关系的实体关系抽取训练样本;
学习训练模块,用于将所述实体关系抽取训练样本输入初始模型进行训练学习,获得人物关系抽取模型。
优选地,所述人物关系抽取模块包括:
查找子模块,用于当判定所述目标句式中存在人物实体词残缺时,根据所述目标句式中已有的人物实体词及人物关系词,在所述书页文本信息中查找关联目标语句;当判定所述目标句式中存在人物关系词残缺时,根据所述目标句式中已有的人物实体词对,在所述书页文本信息中查找关联目标语句;
抽取子模块,用于将所述查找到的关联目标语句输入所述训练好的人物关系抽取模型进行人物关系抽取,获得若干组人物实体词对及其对应的人物关系词。
优选地,所述查找子模块包括:
同义词获取单元,用于获取所述目标句式中已有的人物实体词的同义实体词;还用于获取所述目标句式中已有的人物关系词的同义关系词;
关联查找单元,用于在所述书页文本信息中,查找与所述目标句式中的人物实体词、所述同义实体词、所述目标句式中已有的人物关系词、或所述同义关系词之中任意一个关键词相关的语句作为关联目标语句。
优选地,所述提取生成模块包括:
识别转换子模块,用于识别所述语音信息,将所述语音信息转换为对应的文字信息;便于所述人物关系抽取模块将所述转换后的文字信息输入到所述人物关系抽取模型进行人物关系抽取,输出抽取出的人物实体词和/或人物关系词;
目标句式生成子模块,用于根据抽取出的人物实体词和/或人物关系词,生成对应的目标句式。
本发明至少具备以下一项有益技术效果:
(1)采用本发明的人物关系补全方法,用户在读某本书时,不清楚人物关系词,则可随时提问,本发明在不用建立庞大的实体关系库的情况下,实时采集书面信息进行人物关系抽取,然后结合用户的语音信息配对给出用户答案,帮助用户快速理清人物关系,从而辅助用户理解阅读。
(2)本发明在采集到的书页信息中进行了信息筛选,选取出了关联目标语句,只需从这些关联目标语句中去抽取人物关系即可,降低了人物关系抽取难度和复杂度,提高了处理速度,从而提升了用户体验。
(3)本发明采用的人物关系抽取模型是基于神经网络技术通过训练学习获得,尤其是采用了有监督的学习方法来进行训练学习,使得获得的人物关系抽取模型的抽取速度和准确度也更高。
(4)本发明根据目标句式获得现有的人物实体词或人物关系词来获取对应的人物实体同义词或人物关系同义词,从而提高在书页信息中寻找关联目标语句的全面性,避免由于表达方式的不同而漏掉关联目标语句。提高了后续的人物关系补全概率。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简要介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明一种人物关系补全方法的一个实施例的流程图;
图2为本发明一种人物关系补全方法的另一实施例的流程图;
图3为本发明一种人物关系补全方法的另一实施例的流程图;
图4为本发明一种人物关系补全方法的另一实施例的流程图;
图5为本发明一种人物关系补全装置的一个实施例的结构框图;
图6为本发明一种人物关系补全装置的另一实施例的结构框图;
图7为本发明一种人物关系补全装置的另一实施例的结构框图。
附图标记:
100--语音采集模块;200--提取生成模块;300--残缺判断模块;400--图像采集模块;500--图像识别模块;600--人物关系抽取模块;700--补全模块;800--反馈模块;900--样本获取模块;1000--学习训练模块;210--识别转换子模块;220--目标句式生成子模块;610--查找子模块;620--抽取子模块;611--同义词获取单元;612--关联查找单元。
具体实施方式
以下描述中,为了说明而不是为了限定,提出了诸如特定系统结构、技术之类的具体细节,以便透彻理解本申请实施例。然而,本领域的技术人员应当清楚,在没有这些具体细节的其他实施例中也可以实现本申请。在其他情况中,省略对众所周知的系统、装置、电路以及方法的详细说明,以免不必要的细节妨碍本申请的描述。
应当理解,当在本说明书和所附权利要求书中使用时,术语“包括”指示所述描述特征、整体、步骤、操作、元素和/或组件的存在,但并不排除一个或多个其他特征、整体、步骤、操作、元素、组件和/或集合的存在或添加。
为使图面简洁,各图中只示意性地表示出了与本发明相关的部分,它们并不代表其作为产品的实际结构。另外,以使图面简洁便于理解,在有些图中具有相同结构或功能的部件,仅示意性地绘出了其中的一个,或仅标出了其中的一个。在本文中,“一个”不仅表示“仅此一个”,也可以表示“多于一个”的情形。
还应当进一步理解,在本申请说明书和所附权利要求书中使用的术语“和/或”是指相关联列出的项中的一个或多个的任何组合以及所有可能组合,并且包括这些组合。
具体实现中,本申请实施例中描述的终端设备包括但不限于诸如具有触摸敏感表面(例如,触摸屏显示器和/或触摸板)的移动电话、膝上型计算机、家教机或平板计算机之类的其他便携式设备。还应当理解的是,在某些实施例中,所述终端设备并非便携式通信设备,而是具有触摸敏感表面(例如:触摸屏显示器和/或触摸板)的台式计算机。
在接下来的讨论中,描述了包括显示器和触摸敏感表面的终端设备。然而,应当理解的是,终端设备可以包括诸如物理键盘、鼠标和/或控制杆的一个或多个其他物理用户接口设备。
终端设备支持各种应用程序,例如以下中的一个或多个:绘图应用程序、演示应用程序、网络创建应用程序、文字处理应用程序、盘刻录应用程序、电子表格应用程序、游戏应用程序、电话应用程序、视频会议应用程序、电子邮件应用程序、即时消息收发应用程序、锻炼支持应用程序、照片管理应用程序、数码相机应用程序、数字摄像机应用程序、web浏览应用程序、数字音乐播放器应用程序和/或数字视频播放器应用程序。
可以在终端设备上执行的各种应用程序可以使用诸如触摸敏感表面的至少一个公共物理用户接口设备。可以在应用程序之间和/或相应应用程序内调整和/或改变触摸敏感表面的一个或多个功能以及终端上显示的相应信息。这样,终端的公共物理架构(例如,触摸敏感表面)可以支持具有对用户而言直观且透明的用户界面的各种应用程序。
另外,在本申请的描述中,术语“第一”、“第二”等仅用于区分描述,而不能理解为指示或暗示相对重要性。
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对照附图说明本发明的具体实施方式。显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图,并获得其他的实施方式。
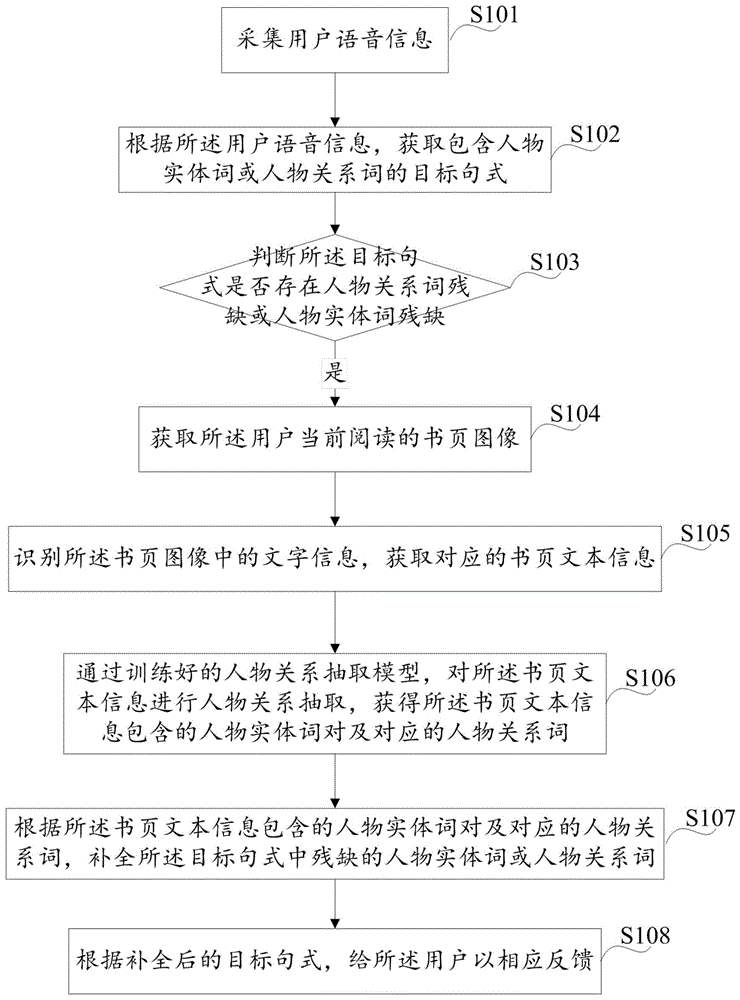
图1示出了本发明一种人物关系补全方法的一个实施例的流程图,该人物关系补全方法可以应用于终端设备(例如:学习机,家教机等智能设备,本实施例中为方便理解,都以家教机作为主语解释,但本领域的技术人员均明白该人物关系补全方法也可应用于其他终端设备,只要能实现相应功能即可),所述意图识别方法包括以下步骤:
s101,采集用户语音信息;
具体的,比如,用户在读某本书时,难以理清书中的人物关系,这时便可向家教机发问:“小花和小兰是什么关系”,家教机上的麦克风设备便可采集该用户的语音信息。
s102,根据所述用户语音信息,获取包含人物实体词或人物关系词的目标句式;
具体的,本方案中的目标句式实际是一种结构化文本数据,具体的是包含了人物实体词、人物关系词的指定结构的句子。目标句式的结构可以有多种,比如,人物实体a和人物实体b是c关系;或者人物实体a的d关系是人物实体b;比如,用户问:“小花和小兰是什么关系”;那么根据该语音信息,可获取目标句式:小花和小兰是(关系词)。
s103,判断所述目标句式是否存在人物关系词残缺或人物实体词残缺;若是,进入步骤s104;
获取到目标句式后,则需要对该目标句式进行完整性判断,看其是否存在人物实体残缺或者说是人物关系残缺,一旦发现残缺,则需进行后续的补全操作。一般的,如果提取到了人物实体词对(包含两个人物实体词)及其对应的人物关系词,则认为该目标句式是完整的。如果只提取到一个人物实体词及人物关系词,或者说只提取到了人物实体词对而没有对应的人物关系词,则该目标句式都是存在残缺的。
s104,获取所述用户当前阅读的书页图像;
具体的,在判定目标句式存在残缺时,则需对残缺部分进行补全。此时,可以通过家教机上的摄像头来拍摄用户当前阅读的书页图像,因为一般用户提出人物关系时,很可能是正在看的书中的人物关系,用户读了后可能书中人物多,关系复杂,从而难以捋清,故而发问。
s105,识别所述书页图像中的文字信息,获取对应的书页文本信息;
具体的,获取到用户当前阅读的书页的图像后,对其图像进行识别处理,获取该图像中的文字信息。本实施例可采用现有的各种图像识别处理技术,具体的识别技术细节可参考现有的图像识别技术,本发明不再重复。
s106,通过训练好的人物关系抽取模型,对所述书页文本信息进行人物关系抽取,获得所述书页文本信息包含的人物实体词对及对应的人物关系词;
人物关系抽取是实体关系抽取的重要分支。实体关系是指实体之间存在的语义联系。automaticcontentextraction(ace)会议将实体关系抽取定义为:根据预先给定的实体关系类型,判定实体之间是否存在语义关系或是否属于给定的关系类型。人物关系抽取将实体关系抽取中的实体限定为人物,关系类型限定为人物之间的关系进行抽取,目前人物关系抽取的主要方法包括:模式匹配、语义分析、特征分类等。
由于书页中包含的文字信息可能比较多,人物关系复杂,因此,本实施例采用神经网络技术获取一人物关系抽取模型,从而可以快速而准确的获取到书页文本信息中的人物关系。
较佳的,获取到该书页中包含的人物关系后,还可据此生成人物关系图谱,从而使得人物关系一目了然。
s107,根据所述书页文本信息包含的人物实体词对及对应的人物关系词,补全所述目标句式中残缺的人物实体词或人物关系词;
具体的,由于从书页文本信息中提取到的人物关系可能涉及多组人物实体词对,也对应多种人物关系词。因而还需要根据具体的目标句式来选取合适的人物实体词或人物关系词来进行填充。比如,从书页文本信息中获取到的人物关系有以下几组:
第一组:人物实体词对:小兰小花人物关系词:姐妹;
第二组:人物实体词对:小兰小红人物关系词:同学;
第三组:人物实体词对:大刘小兰人物关系词:父女;
第四组:人物实体词对:王娟小兰人物关系词:师生。
而之前根据用户语音信息获取的目标句式为:小花和小兰是(关系词),因此,可在书页文本信息抽取出的几组人物关系中进行查找,获得小花和小兰是同学的关系,进而可以将该目标句式进行补充:小花和小兰是同学。
s108,根据补全后的目标句式,给所述用户以相应反馈。
具体的,获取到补全后的目标句式后,便可解答用户的疑问,将人物关系反馈给用户。
上述实施例中,人物关系抽取模型需要通过学习训练方可获得。具体的,现有主流的基于神经网络的实体关系抽取技术分为有监督的学习方法、半监督的学习方法和无监督的学习方法三种,通过以下三种学习方法中的任一方法训练学习均可获得本发明的人物关系抽取模型。
1、有监督的学习方法将关系抽取人物当做分类问题,根据训练数据设计有效的特征,从而学习各种分类模型,然后使用训练好的分类器(相当于上述的人物关系抽取模型)预测关系。具体的,先要获取标注了人物实体与人物关系的实体关系抽取训练样本;然后将所述实体关系抽取训练样本输入初始模型进行训练学习,获得人物关系抽取模型。
具体的,本发明中人物关系抽取模型的获得即可通过上述有监督的学习方法来训练学习获得。具体可包含以下步骤:
1.1收集大量含有人物关系的文本信息,然后对这些文本信息进行标注,标注出人物实体词对及对应的人物关键词对;这些标注好的文本信息便可作为学习训练的样本;
1.2将获取到的学习训练的样本,输入初始模型进行训练学习,经过大量的训练样本的学习之后,从而获得了人物关系抽取模型。采用该有监督的学习方法能够抽取更有效的特征,其准确率也更高。
2、半监督的学习方法主要采用bootstrapping进行关系抽取。对于要抽取的关系,该方法首先手工设定若干种子实例,然后迭代地从数据中抽取关系对应的关系模板和更多的实例。其中,bootstrapping算法,指的就是利用有限的样本资料经由多次重复抽样,重新建立起足以代表母体样本分布的新样本。
3、无监督的学习方法假设拥有相同语义关系的实体对拥有相似的上下文信息。因此可以利用每个实体对对应上下文信息来代表该实体对的语义关系,并对所有实体对的语义关系进行聚类。
与其他两种方法相比,有监督的学习方法能够抽取更有效的特征,其准确率和召回率都更高。
本发明方法的另一实施例,如图2所示,包括:
s201,采集用户语音信息;
s202,根据所述用户语音信息,获取包含人物实体词或人物关系词的目标句式;
s203,判断所述目标句式是否存在人物关系词残缺或人物实体词残缺;
s204,当判定所述目标句式中存在人物关系词残词缺或人物实体词残缺时,获取所述用户当前阅读的书页图像;
s205,识别所述书页图像中的文字信息,获取对应的书页文本信息;
s206,判断所述目标句式的残缺类型,当判定所述目标句式中存在人物实体词残缺时,进入步骤s207;当判定所述目标句式中存在人物关系词残缺时,进入步骤s208;
s207,根据所述目标句式中已有的人物实体词及人物关系词,在所述书页文本信息中查找关联目标语句;
具体的,比如,获取到的目标句式为:“张燕的妹妹是(人物实体词)”,该目标句式中包含有一个人物实体词:张燕;一个人物关系词:妹妹;但还缺乏一个人物实体词,属于人物实体词残缺;此时,可根据已有的人物实体词和人物关系词,在书页文本信息中查找关联目标语句;这里的所谓关联目标语句即与目标句式中已有的人物实体词或人物关系词相关的的语句。
s208,根据所述目标句式中已有的人物实体词对,在所述书页文本信息中查找关联目标语句;
同样的,比如,获取到的目标句式为:“张燕和张兰是_(人物关系词)_”,该目标句式中包含有人物实体词对:张燕、张兰;但还缺乏人物关系词,属于人物关系词残缺;此时,可根据已有的人物实体词对,在书页文本信息中查找关联目标语句;这里的所谓关联目标语句即与目标句式中已有的任一人物实体词相关的的语句。
s209,将所述查找到的关联目标语句输入所述训练好的人物关系抽取模型进行人物关系抽取,获得若干组人物实体词对及其对应的人物关系词;
通过步骤s207或者步骤s208获取到关联目标语句后,则只需将这些关联目标语句输入到人物关系抽取模型中进行人物关系抽取即可,而不需要将整个书页文本信息都输入到人物关系抽取模型中,降低了抽取难度,也提高了数据处理速度。
s210,根据所述书页文本信息包含的人物实体词对及对应的人物关系词,补全所述目标句式中残缺的人物实体词或人物关系词;
s211,根据补全后的目标句式,给所述用户以相应反馈。
本实施例在不用建立庞大的实体关系库的情况下,用户在读某本书时,不清楚人物关系词,则可向家教机提问,家教机实时采集书面信息进行关系抽取,然后配对给出用户答案。且本实施例中,在采集到的书页信息中进行了信息筛选,选取出了关联目标语句,只需从这些关联目标语句中去抽取人物关系即可,降低了人物关系抽取难度和复杂度,提高了处理速度,从而提升了用户体验。
较佳的,在上述实施例中,步骤s207中根据所述目标句式中已有的人物实体词及人物关系词,在所述书页文本信息中查找关联目标语句包括:
s2071,获取所述目标句式中已有的人物实体词的同义实体词;
具体的,由于同一个人物,可能有不同的人物实体词表示,因此,在获取到目标句式中的人物实体词后,还需要获取与该人物实体词语义相同的其它实体词,也就是同义实体词。比如,目标句式中的人物实体词为“张小兰”,由于在书中描写时,有的地方可能为显得更亲切而称呼为“小兰”,将姓氏去掉了,而实际上小兰和张小兰是同一个人,“小兰”便是“张小兰”的同义实体词。
s2072,获取所述目标句式中已有的人物关系词的同义关系词;
同样的,同一种人物关系也可能存在不同的表达方式,因此还需要根据人物关系词的同义关系词,比如“朋友关系”,也可称为“好友关系”。
s2073,在所述书页文本信息中,查找与所述目标句式中的人物实体词、所述同义实体词、所述目标句式中已有的人物关系词、或所述同义关系词之中任意一个关键词相关的语句作为关联目标语句。
具体的,比如目标句式中已有的人物实体词为:张小兰,目标句式中已有的人物关系词为:朋友;获取到同义实体词为:小兰,获取到的同义关系词为:好友。然后再书页信息中进行查找,只要与“张小兰”、“小兰”、“朋友”、“好友”之中任意一个词相关的语句都可作为关联目标语句。
同样的,上述实施例的步骤s208中,根据所述目标句式中已有的人物实体词对,在所述书页文本信息中查找关联目标语句包括:
s2081,获取所述目标句式中人物实体词对中的一个人物实体词的同义实体词;
s2082,获取所述目标句式中人物实体词对中的另一个人物实体词的同义实体词;
s2083,在所述书页文本信息中,查找与所述目标句式中的任一人物实体或任一同义实体词相关的语句作为关联目标语句。
具体的,在获取到目标句式中的人物实体词的同义实体词后,再在书页信息中进行查找,只要与目标句式中的任意一个人物实体词相关,或者与获取到的任意一个同义实体词相关的语句都可以作为关联目标语句。
本发明方法的另一实施例,如图3所示,包括:
s301,采集用户语音信息;
s302,识别所述语音信息,将所述语音信息转换为对应的文字信息;
具体的,采集到语音信息后,将该语音信息进行识别处理,转换为对应的文字信息。具体的语音识别处理技术为现有技术,可参照现有的各类语音识别处理技术即可,因不是本发明的创新点,故此处不再赘述。
s303,将所述转换后的文字信息输入到所述人物关系抽取模型进行人物关系抽取,输出抽取出的人物实体词和/或人物关系词;
具体的,语音识别获取到对应的文字信息后,再将该文字信息输入到人物关系抽取模型进行人物关系抽取,获取其中的人物实体词及对应的人物关系词。
s304,根据抽取出的人物实体词和/或人物关系词,生成对应的目标句式。
获取到抽取出的人物实体词及对应的人物关系词后,再将其组成结构化的句子,也就是目标句式。目标句式的结构需先行设定,比如结构为:人物实体a和人物实体b是c关系;或者人物实体a的d关系是人物实体b。
s305,判断所述目标句式是否存在人物关系词残缺或人物实体词残缺;若是,进入步骤s306;
s306,获取所述用户当前阅读的书页图像;
s307,识别所述书页图像中的文字信息,获取对应的书页文本信息;
s308,通过训练好的人物关系抽取模型,对所述书页文本信息进行人物关系抽取,获得所述书页文本信息包含的人物实体词对及对应的人物关系词;
s309,根据所述书页文本信息包含的人物实体词对及对应的人物关系词,补全所述目标句式中残缺的人物实体词或人物关系词;
s310,根据补全后的目标句式,给所述用户以相应反馈。
本实施例在上述任一实施例基础上,增加了获取到用户语音信息后如何生成目标句式的详细步骤,该方案中,同样利用了人物关系抽取模型来对语音识别处理后的文字信息进行了人物关系抽取,该人物关系抽取模型是通过神经网络技术构建的,已经经过了训练学习,人物关系抽取效率高,抽取的准确率也比较高。
本发明的另一实施例,在上述任一实施例的基础上,对于从当前用户阅读的书页信息中无法补全目标句式的情况下,可根据书页信息进而查找到用户当前阅读的是哪篇文章,或者说是哪本书,查找到目标文章或者说目标书本后,再根据该目标文章或目标书本,结合人物关系抽取模型来抽取出该目标文章或目标书本中的人物关系,较佳的,再根据抽取出的人物关系构建人物关系图谱,进而可以将该人物关系图谱展示给用户,让用户在阅读时对书中的人物关系一目了然。具体的,本实施例的流程图如图4所示,包括:
s401,采集用户语音信息;
s402,根据所述用户语音信息,获取包含人物实体词或人物关系词的目标句式;
s403,判断所述目标句式是否存在人物关系词残缺或人物实体词残缺;
s404,当判定所述目标句式中存在人物关系词残词缺或人物实体词残缺时,获取所述用户当前阅读的书页图像;
s405,识别所述书页图像中的文字信息,获取对应的书页文本信息;
s406,通过训练好的人物关系抽取模型,对所述书页文本信息进行人物关系抽取,获得所述书页文本信息包含的人物实体词对及对应的人物关系词;
s407,将所述目标句式与所述书页文本信息包含的人物实体词对及对应的人物关系词进行匹配;
s408,当所述目标句式与所述书页文本信息包含的人物实体词对及对应的人物关系词匹配成功时,补全所述目标句式中残缺的人物实体词或人物关系词;进入步骤s41211;
s409,当所述目标句式与所述书页文本信息包含的人物实体词对及对应的人物关系词匹配不成功时,根据所述书页文本信息获取所述书页文本信息对应的目标文章或者目标书本;
s410,获取所述目标文章或者目标书本包含的文字信息,并将其输入到人物关系抽取模型中进行人物关系抽取;获得所述目标文章或目标书本包含的人物实体词对及对应的人物关系词;
s411,根据所述目标文章或者目标书本包含的人物实体词对及对应的人物关系词,补全所述目标句式中残缺的人物实体词或人物关系词;
s412,根据补全后的目标句式,给所述用户以相应反馈。
较佳的,上述实施例还包括:
s413,根据所述人物关系抽取模型对所述书页文本信息的抽取结果,构建人物关系图谱,并展示给所述用户。或:
s450,根据所述人物关系抽取模型对所述目标文章或目标书本的抽取结果,构建人物关系图谱,并展示给所述用户。
基于相同的技术构思,本发明还公开了一种人物关系补全装置,该装置可采用本发明上述的任一人物关系补全方法进行人物关系补全。具体的,本发明的人物关系补全装置如图5所示,包括:
语音采集模块100,用于采集用户语音信息;该语音采集模块100可通过麦克风或其它语音收集设备即可实现语音采集功能。
提取生成模块200,用于根据所述用户语音信息,获取包含人物实体词或人物关系词的目标句式;具体的,本方案中的目标句式实际是一种结构化文本数据,具体的是包含了人物实体词、人物关系词的指定结构的句子。目标句式的结构可以有多种,比如,人物实体a和人物实体b是c关系;或者人物实体a的d关系是人物实体b;比如,用户问:“小明和小宇是什么关系”;那么根据该语音信息,可获取目标句式:小明和小宇是(关系词)。
残缺判断模块300,用于判断所述目标句式是否存在人物关系词残缺或人物实体词残缺;残缺判断模块300接收到提取生成模块200获取的目标句式后,则需要对该目标句式进行完整性判断,看其是否存在人物实体残缺或者说是人物关系残缺,一旦发现残缺,则需进行后续的补全操作。一般的,如果提取到了人物实体词对(包含两个人物实体词)及其对应的人物关系词,则认为该目标句式是完整的。如果只提取到一个人物实体词及人物关系词,或者说只提取到了人物实体词对而没有对应的人物关系词,则该目标句式都是存在残缺的。
图像采集模块400,用于当判定所述目标句式中存在人物关系词残词缺或人物实体词残缺时,获取所述用户当前阅读的书页图像;具体的,该图像采集模块400可通过摄像头来实现,在残缺判断模块300判断出目标句式存在残缺时,则通过摄像头来获取用户当前阅读的书页图像。
图像识别模块500,用于识别所述书页图像中的文字信息,获取对应的书页文本信息;具体的,图像采集模块400获取到用户当前阅读的书页的图像后,图像识别模块500开始对该图像进行识别处理,获取该图像中的文字信息。该图像识别模块500可采用现有的各种图像识别处理技术来识别采集到的书页图像中的文字信息。
人物关系抽取模块600,用于通过训练好的人物关系抽取模型,对所述书页文本信息进行人物关系抽取,获得所述书页文本信息包含的人物实体词对及对应的人物关系词;一般的,由于书页中包含的文字信息可能比较多,人物关系复杂,因此,人物关系抽取模块600可采用神经网络技术获取一人物关系抽取模型,通过该人物关系抽取模块600可以快速而准确的获取到书页文本信息中的人物关系。
补全模块700,用于根据所述书页文本信息包含的人物实体词对及对应的人物关系词,补全所述目标句式中残缺的人物实体词或人物关系词;
具体的,由于从书页文本信息中提取到的人物关系可能涉及多组人物实体词对,也对应多种人物关系词。因而还需要根据具体的目标句式来选取合适的人物实体词或人物关系词来进行填充。比如,从书页文本信息中获取到的人物关系有以下几组:
第一组:人物实体词对:小宇小明人物关系词:朋友;
第二组:人物实体词对:小宇小红人物关系词:同学;
第三组:人物实体词对:大宇小宇人物关系词:父子;
第四组:人物实体词对:王娟小宇人物关系词:师生。
而之前根据用户语音信息获取的目标句式为:小明和小宇是(关系词),因此,可在书页文本信息抽取出的几组人物关系中进行查找,获得小明和小宇是同学的关系,进而可以将该目标句式进行补充:小明和小宇是同学。
反馈模块800,用于根据补全后的目标句式,给所述用户以相应反馈。具体的,获取到补全后的目标句式后,便可将人物关系反馈给用户,解除用户的疑惑。
本实施例在不用建立庞大的实体关系库的情况下,用户在读某本书时,不清楚人物关系词,则可向家教机提问,家教机实时采集书面信息进行关系抽取,然后配对给出用户答案。
上述实施例中的人物关系抽取模块600采用的人物关系抽取模型需要通过学习训练获得。具体的,现有主流的基于神经网络的实体关系抽取技术分为有监督的学习方法、半监督的学习方法和无监督的学习方法三种,通过以下三种学习方法中的任一方法训练学习均可获得本发明的人物关系抽取模型。由于有监督的学习方法能够抽取更有效的特征,其准确率也比较高,因此下面简单说下有监督的学习方法:
有监督的学习方法将关系抽取人物当做分类问题,根据训练数据设计有效的特征,从而学习各种分类模型,然后使用训练好的分类器(相当于上述的人物关系抽取模型)预测关系。具体的,先要获取标注了人物实体与人物关系的实体关系抽取训练样本;然后将所述实体关系抽取训练样本输入初始模型进行训练学习,获得人物关系抽取模型。本发明装置的另一实施例,如图6所示,在上一装置实施例的基础上,所述人物关系补全装置还包括:
样本获取模块900,用于获取标注了人物实体与人物关系的实体关系抽取训练样本;由于人物关系抽取模型的训练需要大量训练样本,因此,先需要收集大量含有人物关系的文本信息;具体的,可以通过网络爬取技术来爬取获得大量含有人物关系的文本信息,然后再对这些文本信息进行标注,标注出人物实体词对及对应的人物关键词对;这些标注好的文本信息便可作为学习训练的样本。
学习训练模块1000,用于将所述实体关系抽取训练样本输入初始模型进行训练学习,获得人物关系抽取模型。将获取到的学习训练的样本,输入初始模型进行训练学习,经过大量的训练样本的学习之后,从而获得了人物关系抽取模型。
本发明装置的另一实施例,如图7所示,在上述任一装置实施例的基础上,所述人物关系抽取模块600包括:
查找子模块610,用于当判定所述目标句式中存在人物实体词残缺时,根据所述目标句式中已有的人物实体词及人物关系词,在所述书页文本信息中查找关联目标语句;当判定所述目标句式中存在人物关系词残缺时,根据所述目标句式中已有的人物实体词对,在所述书页文本信息中查找关联目标语句;具体的,关联目标语句是指与目标句式中已有的人物实体词或人物关系词相关的的语句。
抽取子模块620,用于将所述查找到的关联目标语句输入所述训练好的人物关系抽取模型进行人物关系抽取,获得若干组人物实体词对及其对应的人物关系词。
较佳的,所述查找子模块610包括:
同义词获取单元611,用于获取所述目标句式中已有的人物实体词的同义实体词;还用于获取所述目标句式中已有的人物关系词的同义关系词;具体的,由于同一个人物,可能有不同的人物实体词表示,因此,在获取到目标句式中的人物实体词后,还需要获取与该人物实体词语义相同的其它实体词,也就是同义实体词。比如,目标句式中的人物实体词为“张小兰”,由于在书中描写时,有的地方可能为显得更亲切而称呼为“小兰”,将姓氏去掉了,而实际上小兰和张小兰是同一个人,“小兰”便是“张小兰”的同义实体词。同样的,同一种人物关系也可能存在不同的表达方式,因此还需要根据人物关系词的同义关系词,比如“朋友关系”,也可称为“好友关系”。
关联查找单元612,用于在所述书页文本信息中,查找与所述目标句式中的人物实体词、所述同义实体词、所述目标句式中已有的人物关系词、或所述同义关系词之中任意一个关键词相关的语句作为关联目标语句。
较佳的,在上述任一实施例基础上,所述提取生成模块200包括:
识别转换子模块210,用于识别所述语音信息,将所述语音信息转换为对应的文字信息;便于所述人物关系抽取模块600将所述转换后的文字信息输入到所述人物关系抽取模型进行人物关系抽取,输出抽取出的人物实体词和/或人物关系词;
目标句式生成子模块220,用于根据抽取出的人物实体词和/或人物关系词,生成对应的目标句式。
本实施例在上述任一实施例基础上,对提取生成模块200进行了详细阐述,具体的,在语音采集模块100采集到用户语音信息后,识别转换子模块210对该语音信息进行识别处理,从而将该语音信息转换为对应的文字信息,然后人物关系抽取模块600从该文字信息中抽取出该文字信息中包含的人物实体词、人物关系词(可能没有),然后,目标句式生成子模块220再根据抽取出来的人物实体词、人物关系词来生成对应的目标句式。其中,人物关系抽取模块600采用的人物关系抽取模型是通过神经网络技术构建的,已经经过了训练学习,人物关系抽取效率高,抽取的准确率也比较高。
本发明装置的另一实施例,在上述任一实施例的基础上,所述人物关系补全装置还包括:
目标内容获取模块,用于当所述目标句式与所述书页文本信息包含的人物实体词对及对应的人物关系词匹配不成功时,根据所述书页文本信息获取所述书页文本信息对应的目标文章或者目标书本;并获取所述目标文章或者目标书本包含的文字信息;
所述人物关系抽取模块,还用于通过所述人物关系抽取模块抽取所述目标文章或者目标书本包含的文字信息中的人物关系;获得所述目标文章或目标书本包含的人物实体词对及对应的人物关系词;
所述补全模块,还用于根据所述目标文章或者目标书本包含的人物实体词对及对应的人物关系词,补全所述目标句式中残缺的人物实体词或人物关系词;从而便于所述反馈模块根据补全后的目标句式,给所述用户以相应反馈。
较佳的,在上述实施例的基础上,所述人物关系补全装置还包括:
图谱构建模块,用于根据所述人物关系抽取模型对所述书页文本信息的抽取结果,构建人物关系图谱;或根据所述人物关系抽取模型对所述目标文章或目标书本的抽取结果,构建人物关系图谱;
显示模块,用于向所述用户展示所述人物关系图谱。
本发明的人物关系补全方法实施例与本发明的人物关系补全装置实施例对应,本发明的人物关系补全方法实施例的技术细节同样适用于本发明的人物关系补全装置实施例,为减少重复,不再赘述。
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!