一种针对行车拥堵的智能车载音频精准推送方法与流程
本发明涉及车载智能识别与语音交互领域,特别涉及一种针对行车拥堵的智能车载音频精准推送方法。
背景技术:
随着汽车的日益普及,驾车出行已成为最重要的出行方式,我国的机动车保有量约为3.9亿辆,且每年都在以2000万辆递增。随着车辆增速远远超过道路基础设施的修建和改良速度,再加上早晚高峰期超聚集行车数量,以及因社会竞争造成的日益急躁的驾驶陋习,导致交通拥堵情况也变得越来越普遍,越来越严重。以至于贵阳、北京等城市被冠以“堵城”的称号。
高频率的拥堵会带来以下几个方面的危害:
1.驾驶员心情烦躁,容易引起路怒甚至擦碰等纠纷;
2.拥堵停滞容易导致驾驶员瞌睡,导致追尾等交通事故;
3.上班路上拥堵郁闷,影响心情从而影响一天的工作状态;
4.烦闷无聊影响驾驶员身心健康。
现有车辆都是被动式的机器,没有人工智能的交互,使用体验没有情感温度。传统的车载娱乐电子产品如车载中控、流媒体后视镜、dvd娱乐系统都是被动式的,需要驾驶员自己去设置或手动播放音视频内容,操作不便而且增加驾驶时的不安全因素,不能进行主动定向推送,不够智能,内容相对固定,需要用户自己提前下载相应的音视频内容,已不适应目前经济社会发展所需要的车联网新需求,也不符合广大驾车人员对移动互联时代驾车的期许。
因此,有必要针对上述问题提出一种新的解决方案。
技术实现要素:
本发明的主要目的是提出一种针对行车拥堵的智能车载音频精准推送方法,旨在能智能识别行车拥堵状态,主动与驾驶员进行交互,提供定向精准的内容推送,在检测到堵车时能根据大数据智能分析,推送特定的音频内容,从而消磨堵车时光,舒畅驾驶员心情,预防驾驶员因为拥堵停滞引起的瞌睡,提高驾驶安全和驾驶乐趣。
为实现上述目的,本发明提出的一种针对行车拥堵的智能车载音频精准推送方法,包括如下步骤:
1)人脸识别模块通过车内摄像头采集驾驶员的图像,采集图像后运用人脸识别算法进行人脸识别,将识别信息传送给核心处理模块;
2)堵车情景识别模块获取车载gps系统的路况信息,判断当前行程路段是否属于拥堵状态,若属于拥堵状态,则将拥堵状态信息发送给所述核心处理模块;
3)所述核心处理步骤模块根据所述人脸识别模块的识别信息匹配数据库,若匹配识别到为已有人脸id,则将该人脸id传送给定向内容大数据推送模块,所述定向内容大数据推送模块通过和云后台通信连接获取该人脸id喜好的音频内容推送给车载音响系统播放;若没有匹配识别到为已有的人脸id,则所述核心处理模块通过所述语音交互模块与所述驾驶员交流,获取其喜好的音频,储存喜好信息并推送给所述车载音响系统播放。
进一步地,所述车内摄像头角度可调节,且所述车内摄像头与所述驾驶员人脸的夹角小于30°。
进一步地,所述堵车情景识别模块还包括车载obd盒子。
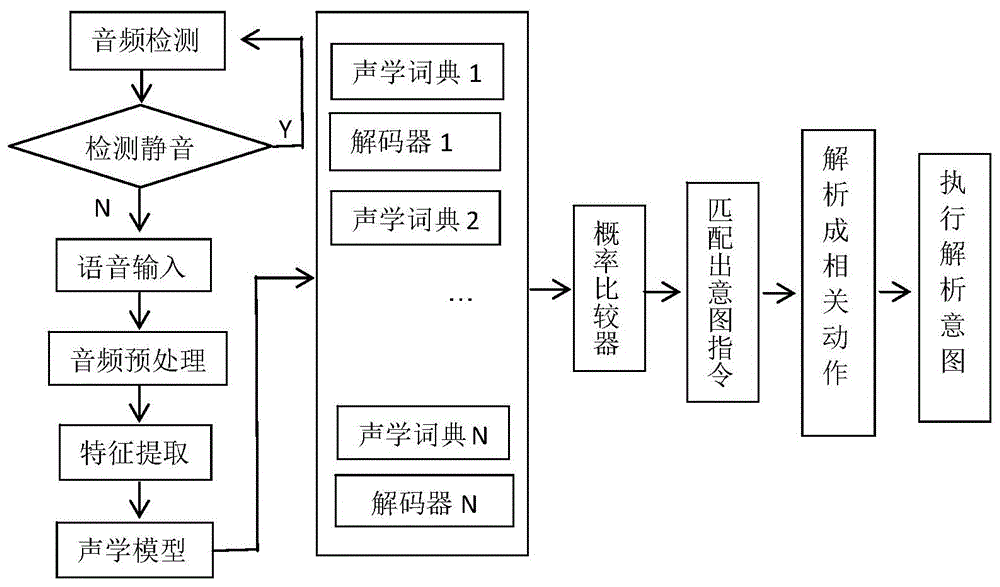
进一步地,所述语音交互模块包括ai语音识别装置,所述ai语音识别装置的识别步骤如下:
s1、音频检测:装置通过语音识别控制单元采集车内的音频数据,得到音频数据序列x(n);
s2、检测静音:对采集到的音频数据做傅里叶变换得到能量场分布图,其变换公式为:
s3、语音输入预处理:音频数据中
将音频数据进行数字滤波,去除背景噪声干扰,滤除方法采用lms自适应滤波方法,已知v(m)为语音输入信号,l(m)为对应的另一路mic采集的背景噪声,y(m)=v(m)-l(m),背景噪声可为音乐声、风雨声等环境噪声,则将噪声滤除得到较为纯净的语音信号。后对语音输入进行加窗处理成一帧一帧的帧数据,每帧的长度为t,帧移动的长度为t,则每帧之间存在着t-t的交替重叠(t>2t),处理好的帧送入步骤s4;
s4、特征提取:识别语音信号中的口音特征,通过对语音信号进行傅里叶变换,利用梅尔倒频谱系数法(mfcc)后由深度神经网络(dnn)来分析和综合运算语音信号所属的口音类型;
s5、声学模型选择:根据上一步骤中获得的所述口音类型,获取所属的声学词典和解码器。
进一步地,步骤s3中所述核心处理步骤模块接收到拥堵状态信息后,通过所述语音交互模块获取所述驾驶员是否需要收听音频的答案;若是,则继续执行;若否,则在一定时间后返回s2。
进一步地,所述人脸识别算法采用lbp算法对人脸区域的纹理特征进行提取,并进行特征分类识别,其包括如下步骤:
b1、人脸区域划分,从人脸图像中划分出重要区域矩形,包括人眼、鼻子、嘴唇和眉毛四大区域矩形,其他的区域归为非重要区域;
b2、分类lbp特征提取,对重要区域采用对纹理信息描述力更强的lbp算子进行纹理特征提取,而对非重要区域采用对纹理信息描述力一般的lbp算子进行纹理特征提取;
b3、pca特征降维,对上步骤b2中提取的lbp纹理特征进行降维;
b4、vm分类识别,对降维后的特征进行纹理分类。
与现有技术相比,本发明的有益效果是:能采集并识别驾驶员的面部图像,通过深度神经网络识别算法识别驾驶人的面部特征,在堵车过程中,当识别到当前路段处于堵车状态,本发明的智能装置能自动与驾驶员进行沟通,询问是否需要收听内容资源;当驾驶员回复肯定时,装置播放对应内容资源,解决上下班高峰期堵车时的无聊。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图示出的结构获得其他的附图。
图1为本发明中堵车情景识别的流程图;
图2为本发明中人脸识别流程图;
图3为本发明中语音识别流程图;
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
本实施例提出的一种针对行车拥堵的智能车载音频精准推送方法,旨在能智能识别行车拥堵状态,主动与驾驶员进行交互,提供定向精准的内容推送,在检测到堵车时能根据大数据智能分析,推送特定的音频内容,从而消磨堵车时光,舒畅驾驶员心情,预防驾驶员因为拥堵停滞引起的瞌睡,提高驾驶安全和驾驶乐趣。
为实现上述目的,本发明提出的一种针对行车拥堵的智能车载音频精准推送方法,包括如下步骤:
1)人脸识别模块通过车内摄像头采集驾驶员的图像,采集图像后运用人脸识别算法进行人脸识别,将识别信息传送给核心处理模块;
2)堵车情景识别模块获取车载gps系统的路况信息,判断当前行程路段是否属于拥堵状态,若属于拥堵状态,则将拥堵状态信息发送给核心处理模块;
3)核心处理步骤模块根据人脸识别模块的识别信息匹配数据库,若匹配识别到为已有人脸id,则将该人脸id传送给定向内容大数据推送模块,定向内容大数据推送模块通过和云后台通信连接获取该人脸id喜好的音频内容推送给车载音响系统播放;若没有匹配识别到为已有的人脸id,则核心处理模块通过语音交互模块与驾驶员交流,获取其喜好的音频,储存喜好信息并推送给车载音响系统播放。
本发明能采集并识别驾驶员的面部图像,通过深度神经网络识别算法识别驾驶人的面部特征,在堵车过程中,当识别到当前路段处于堵车状态,本发明的智能装置能自动与驾驶员进行沟通,询问是否需要收听内容资源;当驾驶员回复肯定时,装置播放对应内容资源,解决上下班高峰期堵车时的无聊。
在本发明一实施例中,车内摄像头角度可调节,且车内摄像头与驾驶员人脸的夹角小于30°。
在本发明一实施例中,堵车情景识别模块还包括车载obd盒子。由于隧道等信号弱地方无法调取gps信息,所以本模块增加车载obd盒子采集车速信息,两者结合判定当前行车速度在所行驶路段是否属于拥堵状态,如果是拥堵状态就启动语音交互定向推送当前驾驶员喜好的音频内容。
堵车情景识别的流程如图1所示。
堵车情景判定步骤为:
第一步,通过obd盒子采集当前行驶测速,只要测到车辆未熄火,车速为0,则通过摄像头识别当前驾驶员面部信息,语音互动定向推送其喜好的音频内容。
第二如果通过obd盒子读取车速不为0,则根据gps定位所行驶路段属于哪一种路段,依据下面表1中不同路段行车拥堵判定国家标准,判定是否堵车,如果判定已经堵车,则通过摄像头识别当前驾驶员面部信息,语音互动定向推送其喜好的音频内容。
在本发明一实施例中,语音交互模块包括ai语音识别装置,语音识别流程如图3所示,ai语音识别装置的识别步骤如下:
s1、音频检测:装置通过语音识别控制单元采集车内的音频数据,得到音频数据序列x(n);
s2、检测静音:对采集到的音频数据做傅里叶变换得到能量场分布图,其变换公式为:
s3、语音输入预处理:音频数据中
将音频数据进行数字滤波,去除背景噪声干扰,滤除方法采用lms自适应滤波方法,已知v(m)为语音输入信号,l(m)为对应的另一路mic采集的背景噪声,y(m)=v(m)-l(m),背景噪声可为音乐声、风雨声等环境噪声,则将噪声滤除得到较为纯净的语音信号。后对语音输入进行加窗处理成一帧一帧的帧数据,如图2所示,每帧的长度为t,帧移动的长度为t,则每帧之间存在着t-t的交替重叠(t>2t),处理好的帧送入步骤s4;
s4、特征提取:识别语音信号中的口音特征,通过对语音信号进行傅里叶变换,利用梅尔倒频谱系数法(mfcc)后由深度神经网络(dnn)来分析和综合运算语音信号所属的口音类型;
s5、声学模型选择:根据上一步骤中获得的口音类型,获取所属的声学词典和解码器。
在本发明一实施例中,步骤s3中核心处理步骤模块接收到拥堵状态信息后,通过语音交互模块获取驾驶员是否需要收听音频的答案;若是,则继续执行;若否,则在一定时间后返回s2。
在本发明一实施例中,人脸识别算法采用lbp算法对人脸区域的纹理特征进行提取,并进行特征分类识别。方法如下:人脸识别模块通过车内摄像头采集驾驶员位置的图像,摄像头可对准人脸上下左右调整角度,校准到摄像头与人脸的夹角小于30°为最佳,采集图像后运用人脸识别算法进行id识别,识别结果如果跟目前数据库人脸id匹配,则根据该人脸id的音频内容喜好进行精准推送。如果识别结果跟目前数据库人脸id不匹配,则建立新的人脸id,询问其想要听的内容进行推送,同时统计其使用喜好,以便下一次精准推送。
人脸识别算法采用lbp算法对人脸区域的纹理特征进行提取,然后进行特征分类识别。算法首先对人脸区域进行分块,区分出重要特征区域和非重要特征区域,然后采用不同模式的lbp算子进行特征提取的策略,最后对特征进行降维和分类识别。主要步骤为:
第一步:人脸区域划分,从人脸图像中划分出重要区域矩形,包括人眼、鼻子、嘴唇和眉毛四大区域矩形,其他的区域归为非重要区域;
第二步:分类lbp特征提取,对重要区域采用对纹理信息描述力更强的lbp算子进行纹理特征提取,而对非重要区域采用对纹理信息描述力一般的lbp算子进行纹理特征提取;
首先计算图像中每个像素与其局部领域点在灰度上的二值关系;其次,对二值关系按一定规则加权形成局部二值模式;最后采用多区域直方图序列作为图像的特征。这种局部纹理特征可由下面t算子进行描述:
t≈t(f(g0-gc),f(g1-gc),λf(gp-1-gc))
将二进制f(gp-gc)乘以相应的权值2p,然后累加求和就可以得到以点gc为中心,r为半径邻域的纹理特征t描述:
t≈t(lbpp,r(xc,yc))
接下来将求解该特征描述的直方图,将其分解成不同的若干个区域,则该图像的直方图定义如下:
hi,j=∑x,yi{h(x,y)=i}i{(x,y)∈rj},
i=0,1,λn-1,j=0,1,λd-1
其中hi,j表示从图像划分的区域rj中属于第i个bin的个数,n为lbp的统计模式特征个数,d为图像划分的区域的个数。
第三步:pca特征降维,对上一步中提取的lbp纹理特征进行降维;
假设此时共有n幅样本人脸图片参与特征提取工作,将图像的lbp模式直方图hi,j看做一向量,并把所有hi,j合并为一矩阵h,那么h就是d×n的矩阵。现在就是要采用pca算法对d×n的矩阵h进行降维,降维后的矩阵称之为
第四步:svm分类识别,对降维后的特征进行纹理分类。
对于特征矩阵h的n类样本分类求解问题,可以把这n类分类划分为多个两类分类问题,每类分类问题可以构建一个最小支持向量机,那么对于n类分类问题需要构建n=n(n-1)/2个最小支持向量机。在构造任意两类样本的最小支持向量机分类器时如p和q类,可以选取将属于第p类的训练样本数据标记为+1,将属于第q类的训练样本数据标记为-1,这样就可以训练出这两类样本数据的最小支持向量机用于人脸分类。当人脸待测样本经过n=n(n-1)/2个这样的两类最小支持向量机分类之后,便可确定其所属人脸样本库的最终类别,即达到人脸分类识别的目的。
人脸识别流程如图2所示,基体步骤如下:
b1、人脸区域划分,从人脸图像中划分出重要区域矩形,包括人眼、鼻子、嘴唇和眉毛四大区域矩形,其他的区域归为非重要区域;
b2、分类lbp特征提取,对重要区域采用对纹理信息描述力更强的lbp算子进行纹理特征提取,而对非重要区域采用对纹理信息描述力一般的lbp算子进行纹理特征提取;
b3、pca特征降维,对上步骤b2中提取的lbp纹理特征进行降维;
b4、vm分类识别,对降维后的特征进行纹理分类。
其中核心处理模块:核心处理模块的作用为其他模块的“大脑”--控制中心,在收到各个模块的信息反馈后进行决策,根据堵车、疲劳、不同交互场景、个性化设置内容等进行定制不同的决策给定向内容大数据推送模块,提供定向的内容大数据推送,针对不同的场景和不同的用户习惯,通过大数据机器学习算法提供多种用户个性化内容,是整个系统的“指挥中心”。
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!