一种物联网深度神经网络分布式判别推论系统及方法与流程
本发明涉及物联网视频图像的智能分析领域,具体涉及一种物联网深度神经网络分布式判别推论系统及方法。
背景技术:
随着图像处理单元gpu在深度学习领域中的使用,深度神经网络的模型研发与市场应用迎来爆发。例如在视频,图像,音频分析处理上,深度神经网络展现的超越人工判别处理的准确率,在人脸识别,车联网驾驶员行为分析,音频转录等领域有着广泛的应用。
随着嵌入式设备处理性能的增长,以及移动网络4g/5g的发展与普及,移动与边缘计算正在物联网领域引领新的应用。然而深度学习模型通常需要大量的计算和处理。如使用嵌入式设备运行深度学习模型,对设备本身的性能要较高,导致硬件成本的提高和计算性能的局限。如嵌入式设备无法完全满足深度学习所需计算。通常的实施方法为通过嵌入式设备进行数据的采集和判别,将判别结果上行传输至中心服务器。进行深度学习的推理。
在物联网领域,由于受到嵌入式处理器算力的限制,往往只能运行经典人工智能算法或简单的神经网络模型。在市场应用及性能上受到局限。针对嵌入式端处理性能不足的问题,一种解决办法是使用云端处理服务器。即,嵌入式设备图像采集,进行适当的预处理后将图像上行传输至中心服务器,中心服务器进行判别。这种解决方案的不足在于,网络传输的延迟导致了应用的局限性,无法应用在实时处理分析。同时,由于图像及视频的数据量会产生大量的网络传输流量,进而产生移动通信的费用,造成算力,延迟,流量上资源不能实现最优平衡与配置。
技术实现要素:
本发明的目的在于提供一种物联网深度神经网络分布式判别推论系统及方法,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:一种物联网深度神经网络分布式判别推论系统,包括视频或图像采集设备、数量至少为一个的智能判别服务器和数量至少为一个嵌入式判别设备组成,其中智能判别服务器运行于云端,即公有云、私有云或托管服务器,智能判别服务器使用至少一个cuda兼容gpu,嵌入式判别设备运行于车联网车载终端,所述嵌入式设备使用arm微处理器,运行linux操作系统,嵌入式判别设备连接视频或图像采集设备并通过无线移动通信网络连接智能判别服务器。
优选地实施方式中,所述智能判别服务器使用tensorflowserving运行于cuda兼容gpu之上,实现“请求-处理”的多路复用机制,所述智能判别服务器的数量为两个以上,所述每个智能判别服务器可使用数量为两个以上的gpu,所述数量为两个以上的智能判别服务器可以组成用于增加处理容量的智能判别集群。
优选地实施方式中,所述嵌入式判别设备连接视频或图像采集设备并通过无线移动通信网络连接智能判别集群。
优选地实施方式中,该物联网深度神经网络分布式判别推论系统还包括深度神经网络模型,所述嵌入式设备上运行tensorflowlite,所述深度神经网络模型在gpu服务器集群中进行大规模训练及优化,模型训练完成后,依据嵌入式设备的处理性能以及上行通信带宽,对模型进行分割,使部分部署于嵌入式设备中的tensorflowlite框架中,部分部署于智能判别服务器中的tensorflowserving框架。
优选地实施方式中,所述嵌入式设备获取图像信息后,进行预处理,与传统方法不同,嵌入式设备对图像和视频数据进行预处理后,并不直接上传,图像数据输入tensorflowlite模型中进行处理。
一种物联网深度神经网络分布式判别推论方法,包括以下步骤:
步骤一:训练过程可在gpu上进行,训练可使用tensorflowserving框架;
步骤二:训练结束后,可在保证测试数据集准确性及鲁棒性的前提下,对模型进行剪枝或压缩;
步骤三:剪枝压缩后,对模型进行整合及格式转换;
步骤四:对模型进行隐藏层分析;
步骤五:按照分割决策器的输出结果,对模型进行分割后的模型进行部署。
优选地,所述步骤四对模型进行隐藏层分析的核心为一个机器学习分类器实现的分割决策器对模型进行隐藏层分析,其隐藏分析步骤如下:
步骤一:对剪枝压缩后,对模型进行整合及格式转换的数据通过预期网络带宽输入神经网络模型和嵌入式判别设备;
步骤二:配置最优化任务的目标函数,即端到端处理延迟由嵌入式端前置层处理延迟、网络带宽延迟与服务器端处理延迟构成。
步骤三:配置最优化任务的约束集,即网络带宽流量上限,例如,可设置流量使用上限为200kbps。
步骤四:执行最优化任务对神经网络模型进行分析获得各层计算量、输入输出特征向量,并结合嵌入式算力与网络带宽,在约束集内进行非线性规划,例如,嵌入式设备的处理性能越强,则可以处理越多分层的神经网络模型,上行通信的数据量则可以越少,最优分割方案在约束条件内实现在最小端到端处理延迟。
步骤五:隐藏层分析输出为神经网络模型的嵌入式端前置层与服务器端后置层的分割分配。
优选地实施方式中,所述步骤五按照分割决策器的输出结果,对模型进行分割的模型进行部署的方法包含如下步骤:
步骤一:将前端模型部署与嵌入式设备中tensorflow、tensorflowlite或tensorflow.js框架中。
步骤二:对接前端模型和预处理以及网络通信。
步骤三:部署后端模型于tensorflowserving框架中,形成云端智能判别器,运行于处理器集群中。
与现有技术相比,本发明的有益效果是:解决嵌入式处理器算力局限与网络传输的延迟与费用的平衡,实现算力,延迟,流量上资源的最优平衡与配置。
附图说明
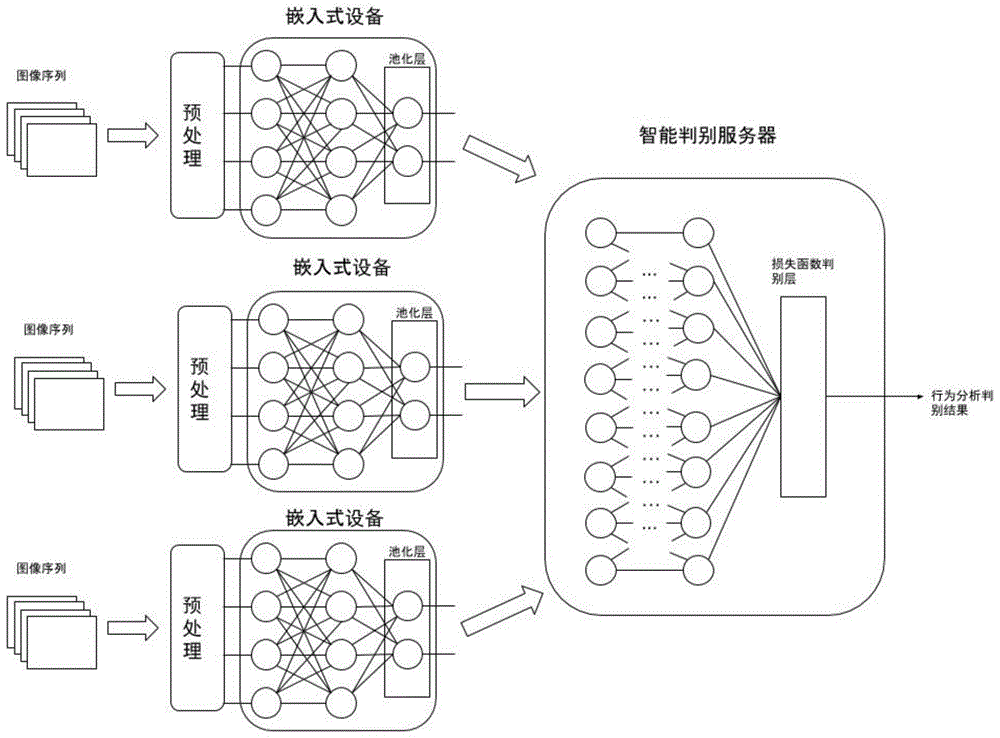
图1是本发明整体系统架构。
图2是本发明实施流程图。
图3是模型分割算法图。
图4是本发明硬件系统拓扑图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅说明书附图,本发明提供一种技术方案:一种物联网深度神经网络分布式判别推论系统,包括视频或图像采集设备、数量至少为一个的智能判别服务器和数量至少为一个嵌入式判别设备组成,其中智能判别服务器运行于云端,即公有云、私有云或托管服务器,智能判别服务器使用至少一个cuda兼容gpu,嵌入式判别设备运行于车联网车载终端,所述嵌入式设备使用arm微处理器,运行linux操作系统,嵌入式判别设备连接视频或图像采集设备并通过无线移动通信网络连接智能判别服务器。
优选地,所述智能判别服务器使用tensorflowserving运行于cuda兼容gpu之上,实现“请求-处理”的多路复用机制,所述智能判别服务器的数量为两个以上,所述每个智能判别服务器可使用数量为两个以上的gpu,所述数量为两个以上的智能判别服务器可以组成用于增加处理容量的智能判别集群。
优选地,所述嵌入式判别设备连接视频或图像采集设备并通过无线移动通信网络连接智能判别集群。
优选地,该物联网深度神经网络分布式判别推论系统还包括深度神经网络模型,所述嵌入式设备上运行tensorflowlite,所述深度神经网络模型在gpu服务器集群中进行大规模训练及优化,模型训练完成后,依据嵌入式设备的处理性能以及上行通信带宽,对模型进行分割,使部分部署于嵌入式设备中的tensorflowlite框架中,部分部署于智能判别服务器中的tensorflowserving框架。
优选地,所述嵌入式设备获取图像信息后,进行预处理,与传统方法不同,嵌入式设备对图像和视频数据进行预处理后,并不直接上传,图像数据输入tensorflowlite模型中进行处理。
一种物联网深度神经网络分布式判别推论方法,包括以下步骤:
步骤一:训练过程可在gpu上进行,训练可使用tensorflowserving框架;
步骤二:训练结束后,可在保证测试数据集准确性及鲁棒性的前提下,对模型进行剪枝或压缩;
步骤三:剪枝压缩后,对模型进行整合及格式转换;
步骤四:对模型进行隐藏层分析;
步骤五:按照分割决策器的输出结果,对模型进行分割后的模型进行部署。
优选地,对模型进行隐藏层分析的核心为一个机器学习分类器实现的分割决策器对模型进行隐藏层分析,其隐藏分析步骤如下:
步骤一:对剪枝压缩后,对模型进行整合及格式转换的数据通过预期网络带宽输入神经网络模型和嵌入式判别设备;
步骤二:配置最优化任务的目标函数,即端到端处理延迟由嵌入式端前置层处理延迟、网络带宽延迟与服务器端处理延迟构成。
步骤三:配置最优化任务的约束集,即网络带宽流量上限,例如,可设置流量使用上限为200kbps。
步骤四:执行最优化任务对神经网络模型进行分析获得各层计算量、输入输出特征向量,并结合嵌入式算力与网络带宽,在约束集内进行非线性规划,例如,嵌入式设备的处理性能越强,则可以处理越多分层的神经网络模型,上行通信的数据量则可以越少,最优分割方案在约束条件内实现在最小端到端处理延迟。
步骤五:隐藏层分析输出为神经网络模型的嵌入式端前置层与服务器端后置层的分割分配。
优选地,按照分割决策器的输出结果,对模型进行分割的模型进行部署的方法包含如下步骤:
步骤一:将前端模型部署与嵌入式设备中tensorflow、tensorflowlite或tensorflow.js框架中。
步骤二:对接前端模型和预处理以及网络通信。
步骤三:部署后端模型于tensorflowserving框架中,形成云端智能判别器,运行于处理器集群中。
本发明系统对深度神经网络的进行分割,并将分割后的神经网络模型在嵌入式端以及云端服务器上分别进行部署。嵌入式端设备与云端服务的数据通信为神经网络隐藏层间的输出输入特征向量,而非原始图像数据或判别后的结果数据。在充分利用嵌入式端的计算资源的基础上,本发明平衡嵌入式处理器算力局限与网络传输的延迟与费用的平衡,实现算力,延迟,流量上资源的最优平衡与配置。本发明中实现所述最优配置的方法为一种深度神经网络的分割决策系统,它使用深度神经网络模型、嵌入式端算力、网络带宽作为分割决策系统的输入数,使用网络流量作为分割决策系统的约束集,实现端到端检测的最低延迟。
本发明所提供的分布式系统由:至少一个智能判别服务器和至少一个嵌入式判别设备组成。
其中智能判别服务器运行于云端,即公有云、私有云或托管服务器。智能判别服务器使用至少一个cuda兼容gpu。嵌入式判别设备运行于车联网车载终端。所述嵌入式设备使用arm微处理器,运行linux操作系统。嵌入式设备连接视频或图像采集设备并通过无线移动通信网络连接智能判别服务器集群。
本系统中智能判别服务器使用tensorflowserving运行于cuda兼容gpu之上,实现“请求-处理”的多路复用机制。每个智能判别服务器可使用多个gpu,多个智能判别服务器可以组成智能判别集群,增加处理容量。
嵌入式设备上运行tensorflowlite,一种轻量级嵌入式端的深度学习框架。与现有嵌入式神经网络系统不同,本方案中嵌入式设备上不运行完整的深度神经网络模型。
如图2,本系统中所使用的深度神经网络模型在gpu服务器集群中进行大规模训练及优化。模型训练完成后,依据嵌入式设备的处理性能以及上行通信带宽,对模型进行分割:部分部署于嵌入式设备中的tensorflowlite框架中,部分部署于智能判别服务器中的tensorflowserving框架。
如图3,模型分割本身为一个非线性组合最优化任务,其核心为一个机器学习分类器实现的分割决策器。最优化任务的输入为神经网络模型、预期移动网络带宽、嵌入式处理器算力。最优化任务的输出(即最优可行解)为神经网络模型的嵌入式端前置层与服务器端后置层的分割分配。最优化任务的目标函数为端到端处理延迟,由嵌入式端前置层处理延迟、网络通信延迟与服务器端处理延迟构成。最优化任务包括一个约束集,即网络带宽流量上限。例如,可设置流量使用上线为200kbps。最优化任务对神经网络模型进行分析获得各层计算量、输入输出特征向量,并结合嵌入式算力与网络带宽,在约束集内进行非线性规划。例如,嵌入式设备的处理性能越强,则可以处理越多分层的神经网络模型,上行通信的数据量则可以越少。最优分割方案在约束条件内实现在最小端到端处理延迟。
所述嵌入式设备获取图像信息后,进行预处理。与传统方法不同,嵌入式设备对图像和视频数据进行预处理后,并不直接上传。图像数据输入tensorflowlite模型中进行处理。模型为分割后前段部分深度神经网络。输出层不使用softmax或sigmoid等损失函数而是池化层结果。池化层对前层数据进行降采样,在神经网络中常常使用,避免过拟合等问题。由于降采样减少数据及参数量,池化层具有数据压缩的效果。
池化层输出的结果为前层数据的特征向量,通过前述分割办法,可以确保该特征向量的数据量小于原始图像数据量。所述嵌入式设备通过无线通信将特征向量及设备id传输至云端智能判别服务器。
云端智能判别服务器在tensorflowserving框架中运行前述分割后的后段部分神经网络,处理结果结合所接受的设备id实现对特定物联网设备采集的视频数据实现行为分析和判别。
由于部分深度神经网络运行与所述嵌入式设备,云端智能判别服务器无需实现全部神经网络的推理。因此,云端智能判别服务器所需计算量小于传统方法中云端服务器的计算量。
相较传统的技术模式使用原始数据作为数据传输,本发明通过构建分布式神经网络推理系统,使用嵌入式神经网络的输出特征向量作为数据传输,这种模式极大的压缩了数据通信所需带宽和流量。
另一方面,相较传统的技术使用云端服务器实现全部计算,本发明中部分处理在嵌入式端进行,减少了服务器的计算压力。
最后,由于通信量的压缩和计算的分步实施,本发明相较传统技术可以实现更小的延迟。
本发明的具体实施方式如下:
整体流程如图2所示,首先,针对具体的应用领域,选择或设计深度神经网络模型进行大规模数据学习训练。
步骤一:训练过程可在高性能gpu集群上进行。训练可使用tensorflow框架
步骤二:训练结束后,可在保证测试数据集准确性及鲁棒性的前提下,对模型进行剪枝或压缩。
步骤三:剪枝压缩后,对模型进行整合及格式转换。
其次,对模型进行隐藏层分析。隐藏层分析如图3所示,核心为一个机器学习分类器实现的分割决策器。
步骤一:对该决策器输入神经网络模型(上述步骤三转化后格式)、预期移动网络带宽、嵌入式处理器算力。
步骤二:配置最优化任务的目标函数即端到端处理延迟,由嵌入式端前置层处理延迟、网络通信延迟与服务器端处理延迟构成。
步骤三:配置最优化任务的约束集,即网络带宽流量上限。例如,可设置流量使用上线为200kbps。
步骤四:执行最优化任务对神经网络模型进行分析获得各层计算量、输入输出特征向量,并结合嵌入式算力与网络带宽,在约束集内进行非线性规划。例如,嵌入式设备的处理性能越强,则可以处理越多分层的神经网络模型,上行通信的数据量则可以越少。最优分割方案在约束条件内实现在最小端到端处理延迟。
步骤五:隐藏层分析输出(即最优可行解)为神经网络模型的嵌入式端前置层与服务器端后置层的分割分配。
再次,按照分割决策器的输出结果,对模型进行分割。
最后,对分割后的模型进行部署。
步骤一:将前端模型部署与嵌入式设备中tensorflow、tensorflowlite或tensorflow.js框架中。
步骤二:对接前端模型和预处理以及网络通信。
步骤三:部署后端模型于tensorflowserving框架中,形成云端智能判别器,运行于处理器集群中。
本设计中,涉及的控制电路,以来控制各组件动作以及相应的控制程序可以理解为现有技术,各部件之间的型号或大小能够相互适配实现本发明的原理即可。尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!