采用无监督聚类得分规整的说话人确认方法与流程
本发明涉及语音信号处理领域,尤其涉及一种采用无监督聚类得分规整的说话人确认方法。
背景技术:
近年来,随着信息科技的飞速发展,人们产生的信息越来越多,获取信息的渠道也越来越多,如何保护个人信息的隐私成为一个关键的问题,利用个人自身的生物特征来进行身份的验证成为了一个值得关注的话题。说话人确认(speakerverification)或者说话人识别(speakerrecognition),也称声纹识别(voiceprintrecognition),是生物特征的一种,它的目的是利用机器根据给定的语音片段来自动地判断一段测试语音与其所声明身份是否一致的过程。由于人类的生理器官天生不同,后天发音方式和习惯也存在差异,这使得每个人的声音具有独特的属性,可以用来鉴别个人的身份。相比于其它生物特征,声纹特征具有便于收集,获取音频成本低廉等优点,有着非常广泛的应用前景。
说话人确认是一个典型的二分类模式识别任务。在说话人确认中,需要计算每段测试语料与其声明说话人之间的模型得分,将得分与设定的判决门限比较作出判决,而这个门限通常是在开发集上确定,对所有测试语音都是同一个数值(auckenthaler,roland,m.carey,andh.lloydthomas.“scorenormalizationfortext-independentspeakerverificationsystems”[j],//digitalsignalprocessing,2000,10(1-3):42-54)。受语料之间信道、语种、时长、性别等因素的影响,不同的说话人模型、测试语音的得分分布往往不同,这种固定一个数值的门限会导致整个系统的性能受到严重的影响。
为了使得不同人、不同测试语音的得分分布趋于一致,从而使得固定的门限能够比较好地区分目标说话人和冒认者,一般采用得分规整的方法来使得说话人得分分布趋于一致。通常有两种规整的途径,一种是规整目标说话人的得分分布,例如零规整(z-norm),另一种是规整冒认者得分分布,例如测试规整(t-norm)。在这二者的基础上,又衍生出了一系列得分规整方法,包括zt-norm(p.kenny,“bayesianspeakerverificationwithheavy–tailedpriors”[c],//keynotepresentation,proc.ofodyssey2010,brno,czechrepublic,june2010)、s-norm(h.aronowitz,d.irony,andd.burshtein,“modelingintraspeakervariabilityforspeakerrecognition”[c],//proc.ofinterspeech,2005:2177-2180)、top-norm(y.zigelandm.wasserblat,“howtodealwithmultiple-targetsinspeakeridentificationsystems?”[c],//proceedingsofthespeakerandlanguagerecognitionworkshop(ieee-odyssey2006),sanjuan,puertorico,june2006)等。目前得分规整已在说话人确认系统中的得到广泛运用,并在高斯混合模型-通用背景模型(gaussianmixturemodels,,universalbackgroundmodel,gmm-ubm)(d.e.sturim,d.a.reynolds,r.b.dunn,andt.f.quatieri.“speakerverificationusingtext-constrainedgaussianmixturemodels”[c],//proc.oficassp2002,may2002:i-677-680)、i-vector(kenny,p,etal.“astudyofinterspeakervariabilityinspeakerverification”[j],//ieeetransactionsonaudiospeech&languageprocessing16.5(2008):980-988)、x-vector(snyder,david,etal.“deepneuralnetwork-basedspeakerembeddingsforend-to-endspeakerverification”[c],//spokenlanguagetechnologyworkshopieee,sandiego,ca,usa,2017:165-1702)等系统中取得显著效果。
得分规整需要挑选一定的冒认语音测试来获得规整所需要的参数。近几年的研究中,如何挑选合适的得分规整所需要的测试语料,从而接近测试集真实的得分分布参数是一关键问题(khemiri,houssemeddine,andd.petrovska-delacretaz.“cohortselectionfortext-dependentspeakerverificationscorenormalization”[c],//internationalconferenceonadvancedtechnologiesforsignal&imageprocessingieee,mar2016,monastir,tunisia,2016:689-692)。由于测试集的得分分布实际上是无法事先获知的,为了尽量缩小由规整集合估计的分布与真实分布之间的偏移,主流的方法是根据给定的数据标签,选择与测试集在语种、性别、信道等各方面因素相匹配的数据并采用随机挑选的方法构造得分规整的集合,如(skorkovska,lucie,z.zajic,andl.muller.“comparisonofscorenormalizationmethodsappliedtomulti-labelclassification”[c],//ieeeinternationalsymposiumonsignalprocessing&informationtechnologyieee,2014)、(swart,albert,andn.brummer.“agenerativemodelforscorenormalizationinspeakerrecognition”[c],//proc.ofinterspeech,august,2017,stockholm,sweden,2017:1477-1481)。在此基础上,论文(d.e.sturimandd.a.reynolds,“speakeradaptivecohortselectionfortnormintext-independentspeakerverification”[c],//proc.oficassp,2005:741–744)对规整集合得分只取最高(top-n)的前若干个得分用于统计分布参数,从理论上而言,也就是只用对目标得分竞争最高的冒认者得分来估计参数,从结果上来看,这种方法优于随机选择的方法。
得分规整总体逻辑思路就是把所有冒认得分(模型和测试语音不是同一个人)规整到一个接近正态的分布上,消除说话内容、语速、时长、信道等因素的影响(r.aisikaer,d.wang,l.li,etal.“scoredomainspeakingratenormalizationforspeakerrecognition”[j],//journaloftsinghuauniversity,2018,58(4):337-341。艾斯卡尔·肉孜,王东,李蓝天,等人,“说话人识别中的分数域语速归一化”[j],//清华大学学报(自然科学版),2018,vol.58issue(4):337-341),从而通过一个合理的门限来获得最好的识别性能。最合理地估计出正态分布的均值和标准差使得得分分布接近测试集得分的分布,是一个关键的研究点。上述论文(d.e.sturimandd.a.reynolds,“speakeradaptivecohortselectionfortnormintext-independentspeakerverification”[c],//proc.oficassp,2005:741–744)选择得分最高的一些冒认得分来估计规整参数,这些数值最大的得分分布不服从高斯分布,因此必然与测试集的分布存在偏差;另外,到底选择多少个最大的得分实际上完全是一个经验值,对实际的性能影响很大。
技术实现要素:
本发明的目的是提供一种采用无监督聚类得分规整的说话人确认方法,可以提高说话人确认的准确率。
本发明的目的是通过以下技术方案实现的:
一种采用无监督聚类得分规整的说话人确认方法,包括:
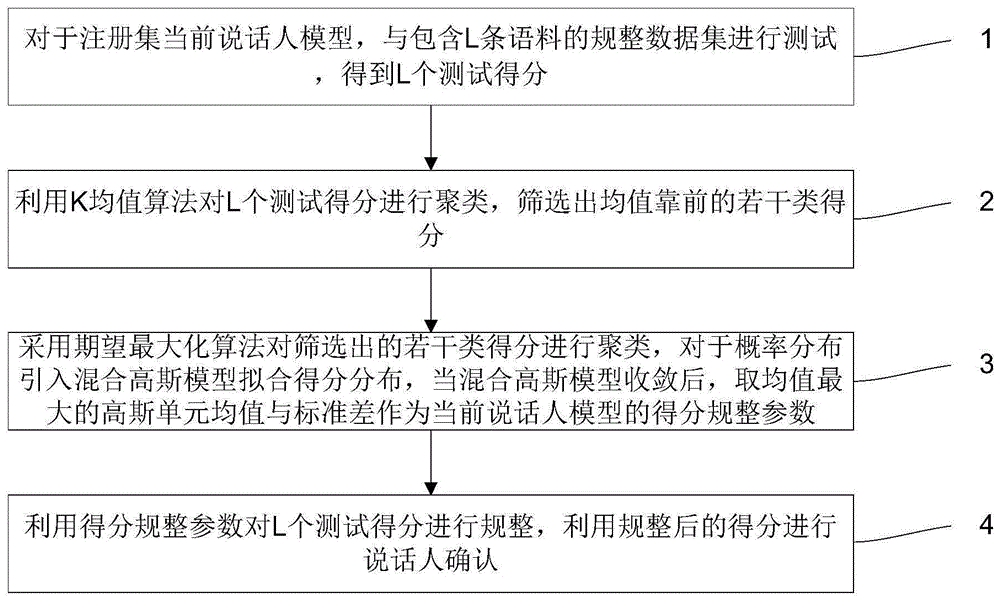
对于注册集当前说话人模型,与包含l条语料的规整数据集进行测试,得到l个测试得分;
利用k均值算法对l个测试得分进行聚类,筛选出均值靠前的若干类得分;
采用期望最大化算法对筛选出的若干类得分进行聚类,对于概率分布引入混合高斯模型拟合得分分布,当混合高斯模型收敛后,取均值最大的高斯单元均值与标准差作为当前说话人模型的得分规整参数;
利用得分规整参数对l个测试得分进行规整,利用规整后的得分进行说话人确认。
由上述本发明提供的技术方案可以看出,针对说话人确认中测试得分分布差异性问题,在传统的采用所有冒认得分的规整参数不够准确的情况下,提出了首先用k均值方法去掉一部分数值比较小的得分,然后对于剩下的得分采用混合高斯模型进行拟合,用均值最大的那个高斯函数的参数来作为规整的参数,从而提升说话人确认准确率。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他附图。
图1为本发明实施例提供的一种采用无监督聚类得分规整的说话人确认方法的流程图;
图2为本发明实施例提供的使用k均值方法进行测试得分清洗的示意图;
图3为本发明实施例提供的gmm得分规整示意图;
图4为本发明实施例提供的估计分布参数与实际分布参数偏差示意图。
具体实施方式
下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明的保护范围。
本发明实施例提供一种采用无监督聚类得分规整的说话人确认方法,可提升说话人确认准确率。
由于注册语料语义信息、环境噪声等方面的差异,不同的说话人模型对于相同的冒认者语料集合会产生不同分布的得分输出,这将造成统一的判决门限与不同说话人模型实际最佳的判决门限存在较大差异,导致系统性能下降。得分规整的目的就是尽量地将不同说话人的冒认者得分规整到一个相同的正态分布上,从而使得统一门限对所有说话人都能够取得好的判决结果,而规整参数将影响最终判决结果的准确率。以典型的z规整算法(z-norm)为例来介绍这一过程。
z-norm利用注册集中的实际说话人模型{e1,e2…em}对规整数据集中大量冒认者语料
上述得分均值μ(em)和标准差σ(em)即为规整参数,利用规整参数对测试得分进行规整:
最终,利用规整得分
上面的流程可以看出,从大量冒认者语料得到的测试得分
如图1所示,为本发明实施例提供的一种采用无监督聚类得分规整的说话人确认方法,其主要包括:
步骤1、对于注册集当前说话人模型,与包含l条语料的规整数据集进行测试,得到l个测试得分。
与之前介绍的方式类似,对于注册集中第m个说话人模型em,与包含l条语料的规整数据集
步骤2、利用k均值算法对l个测试得分进行聚类,筛选出均值靠前的若干类得分。
由于步骤1中的测试可能存在语言、性别等多种信息不匹配的情况,如果这些不匹配测试的得分参与规整参数的计算,会导致规整参数无法反映实际测试中冒认者得分分布,因此本发明利用k均值(kmeans)算法对l个测试得分进行聚类,聚类完成后,可以认为kmeans聚类获得的k个类别的得分代表着不同匹配程度的测试得分类,类中心数值越大的类得分所对应的冒认者测试语料与声明说话人在性别、信道、语种等方面信息匹配程度越高,中心值越低的类匹配程度越低。因此,我们去掉聚类后均值比较小的那些类,仅保留均值靠前的若干类(例如,前k’类,具体数值可以根据实际情况来设定)得分作为筛选后得分,如图2,实际上述操作,就是将数值比较小的得分被清洗掉了。
本发明实施例中,kmeans算法是一种无监督训练的方法,采用kmeans算法对所有得分进行聚类,均值比较小的类别就代表了不匹配的数据,将这些数据进行清洗,从而保证剩下的得分数据与测试集更一致。
步骤3、采用期望最大化算法对筛选出的若干类得分进行聚类,对于概率分布引入混合高斯模型拟合得分分布,当混合高斯模型收敛后,取均值最大的高斯单元均值与标准差作为当前说话人模型的得分规整参数。
如图3所示,利用期望最大化算法(em)聚类后,并引入混合高斯模型(gmm)来拟合数据的分布,可以得到k’个高斯的均值和方差,选择均值最大的那个高斯分量,将其均值
步骤4、利用得分规整参数对l个测试得分进行规整,利用规整后的得分进行说话人确认。
基于本发明实施例上述方案得到的规整参数可结合现有其他规整算法对测试得分进行规整,以前文介绍的z-norm为例,将其测试得分规整公式中的均值μ(em)和标准差σ(em)替换为本发明上述步骤3得到的规则参数(均值
其中,
最后,根据规整后的得分来判决测试语音是否为目标说话人所说。
本发明实施例上述方案,针对说话人确认中测试得分分布差异性问题,在传统的采用所有冒认得分的规整参数不够准确的情况下,提出了首先用k均值方法去掉一部分数值比较小的得分,然后对于剩下的得分采用混合高斯模型进行拟合,用均值最大的那个高斯函数的参数来作为规整的参数,从而提升说话人确认准确率。
本发明提出的方法解决了得分规整集合与测试集不匹配的情况下规整参数的获得问题。由于kmeans和em算法都是无监督聚类的方法,因此可以说是不用开发集就可以获得很好的规整参数。为了验证本发明所提出方法的有效性,设计了如下实验。
(1)实验设置
本发明使用美国国家标准与技术署(nationalinstituteofstandardandtechnology,nist)提供的2016年说话人识别评测比赛(speakerrecognitionevaluation,sre)的测试集作为系统性能评估数据集,测试集中包含广东话与菲律宾塔加路语两种语言。说话人注册语音为时长60s的语料,说话人模型由一段或三段语料注册得到;测试语料时长均匀分布在10~60s,目标说话人测试有37058条,冒认者测试有19494662条。
得分规整所使用的数据集为nistsre2016未标签数据集中的major数据,共计2272条语音,包含广东话与菲律宾塔加路语两种语言,无标签信息。
采用nistsre2016官方计划中的等错误率(equalerrorrate,eer),最小错误代价函数(minimaldetectioncostfunction,min_dcf)和实际的错误代价函数(actualdetectioncostfunction,act_dcf)作为评价指标(“the2016nistspeakerrecognitionevaluationplan(sre16)”[w]),所有这些指标,数值越小说明系统性能越优越。
(2)实验结果
采用因子分析(factoranalysis)的方法首先将每句不定长的语音转换成固定的低维矢量(i-vector),然后采用概率线性判别分析(probabilisticlineardiscriminantanalysis,plda)的方法来获得每句测试语音的得分。在得到plda测试得分之后,采用各种得分规整方法进行得分规整,整个系统采用开源代码kaldi实现(povey,daniel,etal.“thekaldispeechrecognitiontoolkit”,//ieee2011workshoponautomaticspeechrecognitionandunderstanding.no.epfl-conf-192584.ieeesignalprocessingsociety,2011)。
本发明将无得分规整的结果作为基线系统,并构建了不同的得分规整系统进行对比:
系统0:得分不做规整,这是基线(baseline)系统。
系统1-3:使用所有得分进行z-norm、t-norm、s-norm;这些算法是目前广泛采用的得分规整算法。
系统4-6:使用最高的n个得分进行z-norm、t-norm、s-norm。这是论文(matejka,pavel,etal.“analysisofscorenormalizationinmultilingualspeakerrecognition”[c],//proceedingsofinterspeech,stockholm,sweden,2017:1567-1571)所采用的算法。本实验中z-norm中n取150,t-norm中n取100,在这两个参数上本发明系统性能最佳,后面的描述中按此种做法所做的规整将在规整方法前加top,例如topz-norm。
系统7-9:利用本发明提出的方法来计算规则参数并结合z-norm、t-norm、s-norm方法,后面的描述中按此种做法所做的规整将在规整方法前加gmm,例如gmmz-norm。
不同规整系统实验结果如表1所示:
表1不同得分规整系统实验结果
从表1中各项指标可看出,系统9gmms-norm整体性能最佳,eer达到了13.69,而min_dcf和act_dcf达到了0.7167和0.7214,这两项指标较基线分别有7.1%和22.0%的明显提升。
从基本的规整方法来看,s-norm效果要好于z-norm、t-norm,说明s-norm充分结合了二者的优点,实现了性能互补。对比系统1-3、4-6以及系统7-9可知,从选取得分数量策略来看,选取靠前的得分统计规整参数性能更优,这一定程度上是因为靠前的得分集合有更加稳定的均值和标准差。使用基于无监督聚类实际上选取的若干个数值比较大的得分来获得规整参数,相对而言top方法选定固定数量比较大的得分,从实验结果来看,无监督聚类方法明显优越一些。这得益于gmm模型在刻画数据分布时的优势,这也表明利用gmm模型能有效地解决在取固定数量个得分计算规整参数时分布信息丢失的问题。
为了体现由规整参数估计的得分分布参数与真实测试集分布参数的差异,另外给出均值和标准差两个偏差参数:
其中,n为测试集中待规整目标的数量,对于z-norm,n为注册说话人数量,对于t-norm,n为测试语料数量,
从图4可以看出,无论是z-norm还是t-norm,基于聚类的得分规整方法的两种偏差都要明显小于选取固定数量个得分的规整方法。选取所有得分统计规整参数时,由于存在部分数据标签不匹配的测试,这会使得估计的均值远低于真实分布均值,标准差也会因此偏高,而选取最靠前的n个得分统计规整参数时,整体估计的均值往往大于真实分布均值,并且这前n个相邻得分标准差远小于真实分布。本发明提供的规整方案首先剔除了靠后的得分类,可以缩小与真实分布均值上的差距,然后利用gmm软聚类的方法使得保留的每个得分点都参与规整参数的计算,这样可以缩小标准差与真实分布的偏差,因此基于聚类的得分规整可有效的防止得分分布信息的丢失。
总的来说,在由全部得分得到规整参数的传统算法的基础上,本发明提出无监督聚类的方法来获得规整参数,首先剔除了一部分与测试集不匹配的得分,进一步采用期望最大化(em)聚类的方法来获得gmm的估计,最终只选择均值最大的一个高斯来进行规整,从逻辑上来看就是动态地选择与测试数据最匹配的一些得分来获得规整参数,从实验结果来看,这种方法由于全部得分获得规整的方法,也优于只选择最大的topn个得分获得规整参数的方法(系统4-6)。
为了便于理解,下面结合一个示例来进行说明。
对于一段测试语音,对于给定的说话人模型算到原始的测试得分,这种测试得分可以是如上面实验配置部分的i-vector和后端的plda模型计算得分,也可以是其它的模型如支持向量机(supportvectormachine,svm)或者gmm-ubm等算法得到。
有一个开发集,这个开发集一般是没有标签的,也就是不知道每段语音说话人的性别、信道、所用语言信息,当然还有其它的一些信息,比如情绪等。同样,采用上面的模型也可以测试得到一个得分。由于语句很多,后面的无监督聚类算法就是从这大量的得分中估计出一个比价准确的规整参数。
首先,如图2所示,对开发集得分进行数据清洗,也即,筛选出要数值比较大的得分。
然后,如图3所示,采用em算法对清洗剩余的数据进行无监督聚类,采用混合高斯模型来拟合这些数据的分布。
最后,只挑选最大的那个高斯分量的均值和方差作为规整参数,将原始的测试得分和规整参数按照前文介绍的规整公式进行最终得分计算,最终的得分用于判决测试语音是否为目标说话人所说。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例可以通过软件实现,也可以借助软件加必要的通用硬件平台的方式来实现。基于这样的理解,上述实施例的技术方案可以以软件产品的形式体现出来,该软件产品可以存储在一个非易失性存储介质(可以是cd-rom,u盘,移动硬盘等)中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述的方法。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明披露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求书的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!