一种随机森林的边缘计算终端安全等级评估方法与流程
本发明涉及边缘计算终端安全等级评估方法,特别是涉及一种随机森林的边缘计算终端安全等级评估方法。
背景技术:
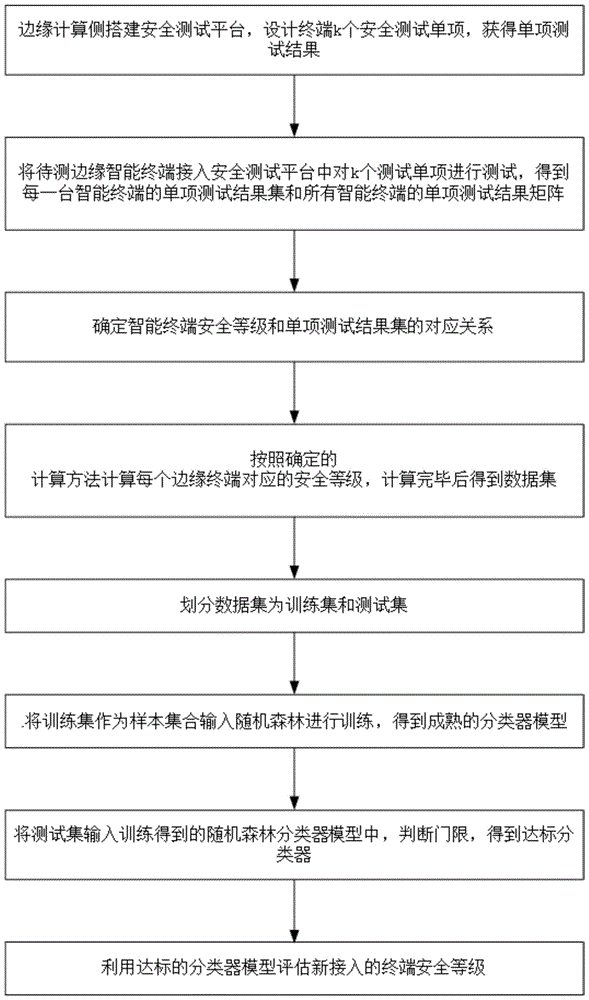
:随着万物互联的飞速发展及广泛应用,智能终端将成为万物互联关键节点,并产生海量实时数据。根据idc统计数据,到2020年将有超过500亿个终端和设备接入网络,其中超过50%的数据需要在网络边缘侧分析、处理与存储。大量边缘设备产生的海量数据需要更敏捷的连接、更有效的数据处理,同时要有更好的数据保护。面对大量异构终端接入物联网,边缘计算侧也面临着更大的数据安全威胁和隐患,存在一些不受信任的终端及移动边缘应用开发者的非法接入问题。因此,需要对边缘计算终端的数据安全需求按等级划分,在终端、边缘节点、边缘计算服务之间建立新的安全接入机制,以保证数据的机密性、完整性、用户信息隐私性。这种背景下,对于边缘计算终端的安全性能进行测评,首先在边缘计算侧对终端安全进行单项测评,根据各测试单项的测试结果科学计算,进行终端安全等级的划分,实现不同安全级别需求的安全使用,达到智能终端安全有效。边缘侧的计算资源支持,使得其可以采用较为复杂的计算方法进行终端安全性能评估,实现终端安全等级的客观、有效和精确划分,本专利提出将终端和数据安全需求按等级划分,根据面临的安全风险、系统复杂度等,通过量化的客观标准进行边缘计算侧终端安全等级的评测。随机森林(randomforest)是2001年由leobreiman提出的机器学习算法,主要应用于回归和分类。它的基本思想是利用自助法(bootstrap)重采样技术和节点随机分裂技术构建多棵决策树,从原始训练样本集n中有放回地重复随机抽取k个样本生成新的训练样本集合,然后根据自助样本集生成k个分类树组成随机森林,通过分类树投票得到新数据的分类结果。基于边缘计算能力的支撑,在随机森林算法下实现智能终端的数据安全需求按等级划分,对于实现边缘计算系统安全性能的最大优化具有重大意义。技术实现要素:本发明的目的在于克服现有技术的不足,提供一种随机森林的边缘计算终端安全等级评估方法,根据智能终端各单项安全性能的测试得到测试结果,并采用随机森林算法进行智能终端的安全等级划分,提高了安全等级划分的准确性。本发明的目的是通过以下技术方案来实现的:一种随机森林的边缘计算侧终端安全等级评估方法,包括以下步骤:s1.在边缘计算侧搭建安全测试平台,设定终端的k个测试单项,每个测试单项的测试结果为0或1,其中0表示不通过,1表示通过;s2.在边缘侧的安全测试平台上,按照k个测试单项对m+n台智能终端进行测试,得到每一台智能终端的安全性能单项测试结果集,其中第i台智能终端的安全性能单项测试结果集为:xi=[xi1,xi2,...,xik],i=1,2,...,m+n;其中,xij为第i台智能终端的第j个测试单项得分,j=1,2,...,k;将所有智能终端的单项测试结果用(m+n)*k维矩阵x表示:s3.确定智能终端安全等级和单项测试结果集的对应关系;s4.按照步骤s3中的对应关系,计算每个xi=[xi1,xi2,...,xik]对应的安全等级yi,计算完毕后得到数据集d={(x1,y1),(x2,y2),...,(xm+n,ym+n)};s5.划分数据集d,取数据集d的前m项为训练集t,后n项为测试集s:训练集t={(x1,y1),(x2,y2),...,(xm,ym)},占数据集的比例为测试集s={(xm+1,ym+1),(xm+2,ym+2),...,(xm+n,ym+n)},占数据集的比例为优选地,训练集t和测试集s的大小可以调整,数据集越大,训练集数据越多,训练效果越好,对测试集的分类越准确;s6.将训练集t={(x1,y1),(x2,y2),...,(xm,ym)}作为样本集合,输入随机森林分类器模型中进行训练,得到成熟的分类器模型;s7.训练完成后,将测试集s={(xm+1,ym+1),(xm+2,ym+2),...,(xm+n,ym+n)}输入训练得到的随机森林分类器模型中,得到测试结果与步骤s4安全等级对比得到达标分类器;s8.将新接入的待测边缘计算侧智能终端接入安全测试平台得到测试结果,输入达标的分类器模型中进行评估,得到对应的安全等级。进一步地,所述步骤s3包括以下子步骤:s31.将智能终端的安全等级划分为y类;s32.令第i台智能终端的测试单项总得分0≤sumi≤k;s33.以为间隔确定安全等级划分范围,当时,第i台智能终端的安全等级为0,时安全等级为1,时安全等级为2,以此类推,时安全等级为t,t=1,2,...,y-1;sumi越大表示智能终端的安全性能越好。进一步地,所述步骤s6包括以下子步骤:s61.选择随机森林算法构建随机森林分类器模型,它属于bagging类型,通过组合多个弱分类器,最终结果通过投票或取均值,使得整体模型的结果具有较高的精确度和泛化性能;s62.将训练集t={(x1,y1),(x2,y2),...,(xm,ym)}划分为少数类样本集tmin和多数类样本集tmax,其中,并且tmin∩tmax={t};s63.从原始样本集中随机的抽取三分之二个样本点,得到训练集t′,观察t′的少数类数据集tmin′,多数类数据集tmax′;s64.计算值,给出条件且s65.如果训练集t′满足s64中的条件,则保存抽取得到的训练集,若训练集t′不满足s64中的条件,则舍弃抽取得到训练集;s66.重复步骤s63~s65,直至得到ntree个满足条件的训练集,其中,ntree为拟构造决策树数量,最终得到的ntree个训练集为其中i=1,2,...,ntree;s67.在i=1,2,...,ntree时,利用训练集ti,训练一个cart决策树hi,依据gini指标选取最优特征。其中,所述步骤s62包括以下子步骤:s621.统计训练集t={(x1,y1),(x2,y2),...,(xm,ym)}中各个安全等级的样本数目;s622.对于每一个安全等级,若其对应的样本数目大于预设阈值h,则将该安全等级的所有样本加入多数类样本集tmax;若其对应的样本数目小于或等于预设阈值h,将该安全等级的所有样本加入少数类样本集tmin。其中,所述步骤s67包括以下子步骤:s671.对于训练集ti,计算基尼指数gini,gini指数越小表示集合中被选中的样本被分错的概率越小,也就是说集合的纯度越高,反之,集合越不纯;其中pk表示分类结果中第k个类别出现的频率;s672.对于含有n个样本的训练集ti,根据属性a的第i个属性值,将数据集ti划分成两部分,计算出gain_gini,其中n1、n2为样本子集ti1、ti2的样本个数;s673.对于属性a,分别计算任意属性值将数据集划分成两部分之后的gain_gini,选取其中的最小值,作为属性a得到的最优二分方案:s674.对于样本集ti,计算所有属性的最优二分方案,选取其中的最小值,作为样本集ti的最优二分方案:进一步地,所述步骤s7包括以下子步骤:s71.测试集s={(xm+1,ym+1),(xm+2,ym+2),...,(xm+n,ym+n)}为待测样本;s72.对于i=1,2,...,ntree,决策树初始投票权重为1,令ri=timax′/timin′;更新每棵决策树的投票权重为s73.对于j=m+1,m+2,...,m+n,i=1,2,...,ntree,输入待测样本xj,由s66的决策树hi输出hi(xj),预测的最终类别为即为测试样本xj对应的安全等级;s74.设定判决分类器误差门限值θ,0≤θ≤1。如果m+1≤j≤m+n,则分类器满足预设门限值,为达标分类器,若不满足则返回步骤s5重新训练,其中进一步地,所述步骤s8包括以下子步骤:s81.将新接入的待测边缘计算侧智能终端接入安全测试平台得到k项测试单项测试结果x=[x1,x2,...,xk];s82.将测试结果输入达标的分类器模型中,i=1,2,...,ntree。f(x)即为对应安全等级。本发明的有益效果是:(1)本发明根据边缘计算智能终端各单项安全性能的测试,采用随机森林分类算法实现对智能终端安全等级的客观准确划分,实现边缘计算系统安全性能的最大优化;(2)本发明利用随机森林算法构建分类模型,随机性的引入,使得随机森林不容易过拟合,有很好的抗噪声能力,训练速度快,可以得到变量等级分类结果,获得较为准确的量化客观标准;(3)本发明对不同的边缘智能终端设备进行安全测试,并以每台终端测试结果数据集为反馈,以实现分类器的训练和安全等级的划分,提高了安全等级划分结果的可信度。附图说明图1为本发明的方法流程图;图2为实施例中一种随机森林的边缘计算终端安全等级评估方法的流程图。具体实施方式下面结合附图进一步详细描述本发明的技术方案,但本发明的保护范围不局限于以下所述。如图1所示,一种随机森林的边缘计算侧终端安全等级评估方法,包括以下步骤:s1.在边缘计算侧搭建安全测试平台,设定终端的k个测试单项,每个测试单项的测试结果为0或1,其中0表示不通过,1表示通过;s2.在边缘侧的安全测试平台上,按照k个测试单项对m+n台智能终端进行测试,得到每一台智能终端的安全性能单项测试结果集,其中第i台智能终端的安全性能单项测试结果集为:xi=[xi1,xi2,...,xik],i=1,2,...,m+n;其中,xij为第i台智能终端的第j个测试单项得分,j=1,2,...,k;将所有智能终端的单项测试结果用(m+n)*k维矩阵x表示:s3.确定智能终端安全等级和单项测试结果集的对应关系;s4.按照步骤s3中的对应关系,计算每个xi=[xi1,xi2,...,xik]对应的安全等级yi,计算完毕后得到数据集d={(x1,y1),(x2,y2),...,(xm+n,ym+n)};s5.划分数据集d,取数据集d的前m项为训练集t,后n项为测试集s:训练集t={(x1,y1),(x2,y2),...,(xm,ym)},占数据集的比例为测试集s={(xm+1,ym+1),(xm+2,ym+2),...,(xm+n,ym+n)},占数据集的比例为在本申请的实施例中,训练集t和测试集s的大小可以调整,数据集越大,训练集数据越多,训练效果越好,对测试集的分类越准确;s6.将训练集t={(x1,y1),(x2,y2),...,(xm,ym)}作为样本集合,输入随机森林分类器模型中进行训练,得到成熟的分类器模型;s7.训练完成后,将测试集s={(xm+1,ym+1),(xm+2,ym+2),...,(xm+n,ym+n)}输入训练得到的随机森林分类器模型中,得到测试结果与步骤s4安全等级对比得到达标分类器;s8.将新接入的待测边缘计算侧智能终端接入安全测试平台得到测试结果,输入达标的分类器模型中进行评估,得到对应的安全等级。进一步地,所述步骤s3包括以下子步骤:s31.将智能终端的安全等级划分为y类;s32.令第i台智能终端的测试单项总得分0≤sumi≤k;s33.以为间隔确定安全等级划分范围,当时,第i台智能终端的安全等级为0,时安全等级为1,时安全等级为2,以此类推,时安全等级为t,t=1,2,...,y-1;sumi越大表示智能终端的安全性能越好。进一步地,所述步骤s6包括以下子步骤:s61.选择随机森林算法构建随机森林分类器模型,它属于bagging类型,通过组合多个弱分类器,最终结果通过投票或取均值,使得整体模型的结果具有较高的精确度和泛化性能;s62.将训练集t={(x1,y1),(x2,y2),...,(xm,ym)}划分为少数类样本集tmin和多数类样本集tmax,其中,并且tmin∩tmax={t};s63.从原始样本集中随机的抽取三分之二个样本点,得到训练集t′,观察t′的少数类数据集tmin′,多数类数据集tmax′;s64.计算值,给出条件且s65.如果训练集t′满足s64中的条件,则保存抽取得到的训练集,若训练集t′不满足s64中的条件,则舍弃抽取得到训练集;s66.重复步骤s63~s65,直至得到ntree个满足条件的训练集,其中,ntree为拟构造决策树数量,最终得到的ntree个训练集为其中i=1,2,...,ntree;s67.在i=1,2,...,ntree时,利用训练集ti,训练一个cart决策树hi,依据gini指标选取最优特征。其中,所述步骤s62包括以下子步骤:s621.统计训练集t={(x1,y1),(x2,y2),...,(xm,ym)}中各个安全等级的样本数目;s622.对于每一个安全等级,若其对应的样本数目大于预设阈值h,则将该安全等级的所有样本加入多数类样本集tmax;若其对应的样本数目小于或等于预设阈值h,将该安全等级的所有样本加入少数类样本集tmin。其中,所述步骤s66包括以下子步骤:s671.对于训练集ti,计算基尼指数gini,gini指数越小表示集合中被选中的样本被分错的概率越小,也就是说集合的纯度越高,反之,集合越不纯;其中pk表示分类结果中第k个类别出现的频率;s672.对于含有n个样本的训练集ti,根据属性a的第i个属性值,将数据集ti划分成两部分,计算出gain_gini,其中n1、n2为样本子集ti1、ti2的样本个数;s673.对于属性a,分别计算任意属性值将数据集划分成两部分之后的gain_gini,选取其中的最小值,作为属性a得到的最优二分方案:s674.对于样本集ti,计算所有属性的最优二分方案,选取其中的最小值,作为样本集ti的最优二分方案:进一步地,所述步骤s7包括以下子步骤:s71.测试集s={(xm+1,ym+1),(xm+2,ym+2),...,(xm+n,ym+n)}为待测样本;s72.对于i=1,2,...,ntree,决策树初始投票权重为1,令ri=timax′/timin′;更新每棵决策树的投票权重为s73.对于j=m+1,m+2,...,m+n,i=1,2,...,ntree,输入待测样本xj,由s66的决策树hi输出hi(xj),预测的最终类别为即为测试样本xj对应的安全等级;s74.设定判决分类器误差门限值θ,0≤θ≤1。如果m+1≤j≤m+n,则分类器满足预设门限值,为达标分类器,若不满足则返回步骤s5重新训练,其中进一步地,所述步骤s8包括以下子步骤:s81.将新接入的待测边缘计算侧智能终端接入安全测试平台得到k项测试单项测试结果x=[x1,x2,...,xk];s82.将测试结果输入达标的分类器模型中,i=1,2,...,ntree。f(x)即为对应安全等级。如图2所示,在本申请的实施例中,利用训练的随机森林,输入待测边缘终端得到边缘计算终端安全等级的过程如下:1.在边缘计算侧,先将10台边缘智能终端接入安全测试平台,设计终端测试单项为22项,得到每台边缘智能终端的单项测试结果为xi=[x1,x2,...,x22],i=1,2,...,10,所有边缘智能终端的单项测试结果集为10*22维矩阵x,其中xij=0或xij=1。2.确定边缘终端安全等级和单项测试结果集的对应关系。1)本次评估将边缘智能终端的安全等级分为0,1,2,3四类;2)令第i台智能终端的测试单项总得分0≤sumi≤22;3)根据sum值确定安全等级划分,当0≤sum≤5时对应安全等级为0,6≤sum≤10时安全等级为1,11≤sum≤15时安全等级为2,16≤sum≤22时安全等级为3,安全等级越高代表终端的安全性能越好。安全等级对应关系下表所示:总分sum0~56~1011~1516~22安全级别yi0123安全程度很差差一般安全3.计算每个xi=[x1,x2,...,x22]的安全等级yi,计算完毕后得到数据集:d={(x1,y1),(x2,y2),...,(x10,y10)}。4.由于数据集不够大,因此采用了蒙特卡洛算法将数据集d按比例进行扩充。5.将数据集d划分为训练集t={(x1,y1),(x2,y2),...,(xm,ym)}和测试集s={(xm+1,ym+1),(xm+2,ym+2),...,(xm+n,ym+n)},测试集作为待测样本。6.从原始样本集中随机的抽取三分之二个样本点,得到训练集t′。观察t′的少数类数据集tmin′,多数类数据集tmax′。7.计算值:如果训练集t′满足且则重复进行步骤6,重复ntree次,ntree为拟构造决策树数量。得到随机采样后的训练集ti,i=1,2,...,ntree。8.对i=1,2,...,ntree,使用训练集ti生成一颗不剪枝的树hi。从22个特征中随机选择m个特征,在每个节点上从m个特征依据gini指标选取最优特征,分裂直到树生长到最大。9.对于i=1,2,...,ntree,决策树初始投票权重为1,令ri=timax′/timin′,更新每棵决策树的投票权重为10.对于j=m+1,m+2,...,m+n,i=1,2,...,ntree,输入待测样本xj,由决策树hi输出hi(xj),预测的测试样本类别为即为测试样本对应的安全等级。11.设定判决分类器误差门限值θ=0.98。m+1≤j≤m+n,分类器满足预设门限值,为达标分类器。12.将新接入的待测边缘计算侧智能终端接入安全测试平台得到22项测试单项测试结果x=[x1,x2,...,x22]。13.将测试结果x=[x1,x2,...,x22]输入达标的分类器模型中,i=1,2,...,ntree。f(x)即为待测边缘计算侧智能终端对应安全等级。在本申请的实施例中,步骤s6除采用机器学习随机森林算法构建分类模型外,还可以采用k-近邻算法、朴素贝叶斯算法、svm算法和决策树算法,或者卷积神经网络算法、前馈神经网络算法和径向基神经网络算法构建相应神经网络,并利用训练集对神经网络训练,得到相应的成熟模型。综上,本发明基于机器学习算法等级分类模型提出一种随机森林的边缘计算终端安全等级评估方法,根据边缘计算智能终端各单项安全性能的测试,采用随机森林分类算法实现对智能终端安全等级的客观准确划分,实现边缘计算系统安全性能的最大优化;利用随机森林算法构建分类模型,随机性的引入,使得随机森林不容易过拟合,有很好的抗噪声能力,训练速度快,可以得到变量等级分类结果,获得较为准确的量化客观标准;对不同的边缘智能终端设备进行安全测试,并以每台终端测试结果数据集为反馈,以实现分类器的训练和安全等级的划分,提高了安全等级划分结果的可信度;同时,本发明对获得训练集的重抽样过程进行了改进,通过增加约束条件对抽样结果进行筛选,能够保证获得的随机训练集能更好的代表原始训练集;并且对于组合决策树形成森林的过程,本发明通过变更决策树的投票权重,能够有效减小随机森林算法本身的缺陷,特别对于数据分布不平衡的场景处理效果有着明显的提高,数据量少的处理效果接较好。以上所述是本发明的优选实施方式,应当理解本发明并非局限于本文所披露的形式,不应该看作是对其他实施例的排除,而可用于其他组合、修改和环境,并能够在本文所述构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离本发明的精神和范围,则都应在本发明所附权利要求的保护范围内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1