一种新闻话题检测方法与流程
本发明属于文本信息处理
技术领域:
,具体涉及一种新闻话题检测方法。
背景技术:
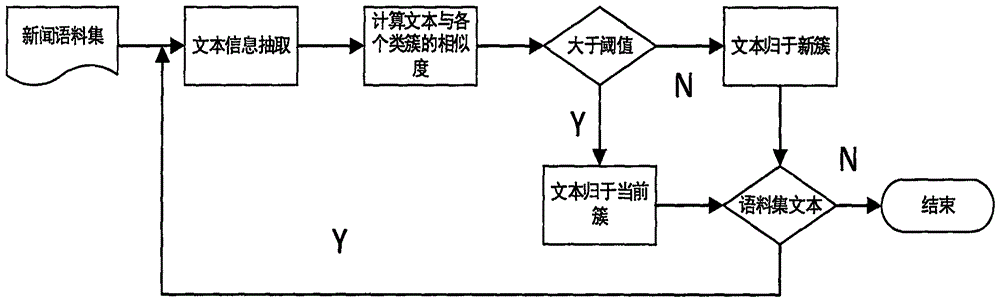
:互联网的高速发展使得新闻事件无时无刻不在保持着高速、大量的更新。而门户网站更是为了能够更加快速的传递国内外的重要新闻报道消息,通过各自的网络媒体实时地向用户推送相关消息。借助于互联网,用户可以畅通无阻的接收到来自世界各地的新闻报道,之前信息匮乏的年代一去不复返。根据中国互联网络信息中心发布的《第39次中国互联网络发展状况统计报告》显示,中国网民规模于2016年底已经达到7.31亿,去年网民总共的增加数多达4299万人,互联网的普及也使得2016年的网络普及率上升到了53.2%,根据2015年的数据显示,相比2015年,普及率上升了2.9个百分点。而互联网移动设备的普及,如手机、平板电脑等产品,使得用户在闲暇时间能通过设备获得大量的新闻信息,然而在获得海量新闻报道的同时,用户也在海量的新闻报道中不知所措。尤其是当需要获得特定话题下的相关信息的时候,会出现无法准确快速的获得自己想要的内容,造成用户在面对海量新闻报道时感到茫然与困惑。综上所述,在信息爆炸的今天,新闻报道文本作为记载和传递信息的载体,通过对新闻报道文本的研究,将文本中所包括的信息抽取并总结,帮助用户能够对整个事件有更加清晰、全面的认识。因此准确的有效的文本信息检测与跟踪,可以让用户耗费更少的时间来准确把握当前发生重大事件的走向。而在21世纪,微博、新闻报道站点、个人站点的火速增长,能够迅速、准确的获得当前重大事件的进展情况以及信息流向,对国家和企业来说,有重要意义。随着各个领域的信息化快速发展,新闻话题检测在各个领域均成为了重点的研究方向。在过去,新闻报道信息都是通过人工的手段来进行识别、收集和汇总。这个过程不仅费时费力,而且有时候并没有对事件进行全面的了解,会片面的将旧话题的事件整理到新话题中去,从而导致了一些负面的影响。而在互联网爆炸的今天,人工的速度已然无法满足信息的增长速度。实时的监测新闻报道,能够同时检测多个新闻来源,通过汇总多个新闻来源的新闻报道,根据建立的话题模型,动态的分类新闻报道,将结果推送给订阅该话题的用户,而在这个过程中,如何准确、及时的分类相关报道,成为了研究的重要方向。而因为受到互联网网络信息特性的制约,如:海量无序性,信息表达不规范等问题,都是对新闻报道的信息进行有效抽取和识别过程中所面对的严峻问题。因此,如何对新闻报道中的信息进行抽取,如何能够准确地自动检测新闻报道话题,使得话题能够自动更新并动态演化都是研究过程中亟待解决的问题。技术实现要素:针对上述现有技术中存在的问题,本发明的目的在于提供一种可避免出现上述技术缺陷的新闻话题检测方法。为了实现上述发明目的,本发明提供的技术方案如下:一种新闻话题检测方法,包括:对文本信息进行关键词抽取、计算新闻报道与话题类簇之间的相似度。进一步地,所述新闻话题检测方法包括:步骤1)对新闻语料集进行预处理,对文本信息进行关键词抽取;步骤2)采用抽取出的关键词集,通过聚类的方法,计算新闻报道与话题类簇之间的相似度,得到关键词类簇,选出具有代表性的关键词作为报道事件的关键词。进一步地,步骤1)包括:采用tfidf和textrank两个模型相结合的方法来进行关键词抽取;分别取权值最高的前十个关键词作为个体提取的关键词集,经过加权平均并归一化后,再挑选出权值前十的关键词得到构建模型中的关键词集合;将获得的关键词集进行归一化。进一步地,关键词抽取的方法具体为:对新闻报道进行预处理,将报道转换为词的格式,然后使用tfidf算法和textrank算法,设定加权公式,取得关键词的权重,获得每篇报道的关键词集合,完成新闻报道关键词的抽取。进一步地,加权平均公式如下:wij=(1{ci∈tfj}αti+(1{ci∈trj})βri;wij表示第j个文本中的i个词的权重,ci表示第i个词是否在tfidf所计算的关键词集中,tfj表示第j个文本经过tfidf计算后得到的关键词集,ti表示在第j个文本的tfidf关键词集中,词ci的权重大小;trj表示第j个文本经过textrank计算后得到的关键词集,ri表示在第j个文本的textrank关键词集中词ci的权重大小。进一步地,归一化公式为:其中wij为加权后的关键词的权重,dj表示第j个报道,表示第j个文本所有关键词的权重的和,w′ij为归一化后该关键词的权重。进一步地,对关键词的抽取包括对新闻报道进行时间抽取的步骤,新闻报道中的时间包括绝对时间和相对时间;绝对时间具有时间单位和时间值,能够直接获得时间的准确时间,用如下公式来定义绝对时间:at={year:,m:,d:};用一个三元组来表示相对时间,如下:et=(at,p,count);其中,at表示该报道的绝对时间,若句子中没有绝对时间,则采用报道的时间作为绝对时间;p为偏移量,正值则表示是绝对时间以后的时间,负值表示绝对时间以前的时间;count为偏移的数值。进一步地,步骤2)包括:将新闻报道转换为基于权重的特征向量,采用改进的相似度计算方法来计算新闻报道与话题类簇之间的相似度的公式如下:sim(m,n)=α×sim(m,n)-0.01-β(time1-time2);其中,sim(m,n)表示当前新闻报道m与话题类簇n之间的相似度;(time1-time2)为当前新闻报道m中事件发生的时间time1与话题类簇n中种子事件发生的时间time2之间相隔的天数;α、β为调整因子;0.01为经验值;采用夹角余弦来计算新闻报道w与类簇m的相似度的计算公式如下:sim(w,m)=max(sim(w,mi)),i=1,2,...,l;其中,w代表新闻报道,m代表话题类簇,l代表类簇m中的事件向量个数。进一步地,所述聚类的方法采用单通道聚类法。进一步地,所述新闻话题检测方法包括:步骤(1)对新闻语料集进行预处理,对文本信息进行关键词抽取;步骤(2)根据时间-事件模型的格式,对报道内容进行向量表示;步骤(3)对新文档进行相似度计算;步骤(4)若相似度大于阈值,则将对象分配到该类簇中;否则,创造出一个新的类簇,将该对象加入到新的类簇中;步骤(5)重复执行步骤(2)-步骤(4)直到数据流结束,过程结束。本发明提供的新闻话题检测方法,提出了改进的相似度计算方法,从事件的时间以及关键词的角度出发,采用抽取出的关键词集,通过聚类的方法,根据时间的长短,针对不同的新闻报道,动态地调整新闻报道与话题的相似度,得到关键词类簇,选出具有代表性的关键词作为报道事件的关键词,用来完成新闻话题的检测,能够对新闻报道中的信息进行准确抽取,能够准确地自动检测新闻报道话题,使得话题能够自动更新并动态演化,检测效果好,可以很好地满足实际应用的需要。附图说明图1为本发明方法的具体流程图。具体实施方式为了使本发明的目的、技术方案及优点更加清楚明白,下面结合附图和具体实施例对本发明做进一步说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。一种新闻话题检测方法,包括:步骤1)对新闻语料集进行预处理,对文本信息进行关键词抽取;步骤2)采用抽取出的关键词集,通过聚类的方法,根据时间的长短,针对不同的新闻报道,计算新闻报道与话题类簇之间的相似度,动态地调整新闻报道与话题类簇的相似度,得到关键词类簇,选出具有代表性的关键词作为报道事件的关键词,用来完成新闻报道的检测。步骤1)包括:采用tfidf和textrank两个模型相结合的方法来进行关键词抽取。基本思想是对新闻报道进行预处理,将报道转换为词的格式,然后使用tfidf算法和textrank算法,设定加权公式,取得关键词的权重,获得每篇报道的关键词集合,完成新闻报道关键词的抽取。通过tfidf和textrank,提取报道集中所有报道的关键词,并分别取权值最高的前十个关键词作为个体提取的关键词集,经过加权平均并归一化后,再挑选出权值前十的关键词得到构建模型中的关键词集合。加权平均公式如下:wij=(1{ci∈tfj}αti+(1{ci∈trj})βri(1)wij表示第j个文本中的i个词的权重,ci表示第i个词是否在tfidf所计算的关键词集中,tfj表示第j个文本经过tfidf计算后得到的关键词集,ti表示在第j个文本的tfidf关键词集中,词ci的权重大小。trj表示第j个文本经过textrank计算后得到的关键词集,ri表示在第j个文本的textrank关键词集中词ci的权重大小。α、β表示各自所占的权重,本实施例将α、β均设置为0.5。i和j均为整数。经过合并后,再将获得的关键词集进行归一化,归一化公式为:其中wij为加权后的关键词的权重,dj表示第j个报道,表示第j个文本所有关键词的权重的和。w′ij为归一化后该关键词的权重。新闻报道中时间表示一般包括两种类型,即可标注类型和不可标注的类型。其中可标注类型表示的是,通过文本的表达,可以直接获得事件时间,或者通过时间关系推导可以获得事件的时间的类型,而不可标注类型即虽然表达的内容与时间相关,但是,并不能通过文本的表达来获取事件的时间。表1所示的是二者不同的文本表达样例:表1时间类型对比而新闻报道六要素(谁、何时、何地、何事、为何、过程如何)里包含着时间特性,并且书写极为规范,基本不存在不可标注的时间类型,因此只考虑可标注的时间类型。但是,仅仅考虑报道发布的时间作为事件发生的时间是不对的,因为新闻报道可能会出现报道发布的时间并不是事件发生的准确时间。因此,我们需要对新闻报道进行时间抽取,对于时间的抽取,我们一般采用先通过抽取的关键词确定需要抽取时间的关键句,然后再抽取时间。在新闻报道中,时间分为绝对时间以及相对时间,表2是绝对时间和相对时间的样例:表2可标注时间的表达方式从表2可以看出,绝对时间具有时间单位和时间值,能够直接获得时间的准确时间,本发明用如下公式来定义绝对时间:at={year:,m:,d:}(3);而相对时间的特性,从表3.2可以看出,若只有单独的相对时间的描述,是不能决定时间的,只能根据新闻报道自身的时间,以及关键句中的语境来确定。通过句子的描述,可以建立一个报道时间和相对时间的推理关系,通过推理,这样就可以利用相对时间获得该时间的绝对时间。本实施例用一个三元组来表示相对时间,如下:et=(at,p,count)(4)其中,at表示该报道的绝对时间,一般为句子中的绝对时间,若句子中没有绝对时间,则采用报道的时间作为绝对时间。p为偏移量,正值则表示是绝对时间以后的时间,负值表示绝对时间以前的时间。count为偏移的数值。表3所示为在本实验中出现的偏移时间的一些例子。表3时间偏移现象报道的时间:相对时间2015-01-01:昨天,国务院批转财政部《权责发生制政府综合财务报告制度改革方案》2015-01-01:2013年4月29日,她因病到宣武医院就诊,被诊断为...2015-01-23:据外媒23日报道,沙特国王逝世2015-4-25:这一项调查是在本月7、8日,通过网络对全国20-59岁的6万9989人实施2015-4-26:距离尼泊尔8.1级地震已经过去逾30小时,强烈的余震仍不断根据对新闻语料的研究发现,新闻中时间的表达十分规范,格式基本为“某年某月某日”或“某月某日”或“某日”,因此本实施例采取正则表达式来抽取时间。本实施例采取的是通过事件抽取的结果,将关键词权重第一的句子作为时间获取的句子,并通过正则表达式对事件进行时间抽取,若该句子中不存在相对时间,则将绝对时间当作事件的时间。若存在相对时间,则通过规则来判断具体的时间。本实施例遵循话题检测与追踪任务中对时间表达给出的标注规范,采用统一的纯数字时间来表示对事件时间的描述,如“2001年1月25日”,我们用“20010125”来表示事件时间。抽取效果如表4所示:表4时间抽取结果通过抽取的结果可以看出,报道中的时间均能正确的抽取,如,在2015年1月1日报道中抽取的句子的描述里出现的“2013年4月29日,她因病到宣武医院...”被成功的识别为20130429,其余结果也均识别正确,证明该算法对于新闻报道中的时间抽取是可行的。步骤2)包括:将新闻报道转换为基于权重的特征向量,采用夹角余弦来计算新闻报道w与类簇m的相似度sim(w,m),假设类簇中有l个事件向量,则相似度的计算方法如下:sim(w,m)=max(sim(w,mi)),i=1,2,...,l(5)其中,报道之间的相似度sim(w,mi)采用夹角余弦算法来计算。麻省理工大学的学者们通过研究发现随着时间的推移,新闻报道与某话题种子事件的时间间隔越长,那么当前新闻报道属于该话题的概率会越小。在一般聚类算法中,新闻报道与话题的相似度高出一定阈值,我们就判断当前报道属于该话题,将其划分到该话题内。但是这就忽略了时间对新闻报道的影响,所以我们提出了改进的相似度计算方法,通过将时间距离差作为报道与话题相似度计算的一部分,根据时间动态的调整相似度,使得离话题种子事件的时间间隔越远的话题需要更高的相似度才能加入到该话题中去。采用改进的相似度计算方法来计算新闻报道与话题类簇之间的相似度的公式如下:sim(m,n)=α×sim(m,n)-0.01-β(time1-time2)(6)其中,sim(m,n)表示当前新闻报道m与话题类簇n之间的相似度,为当前新闻报道与话题类簇里所有新闻报道的相似度的最大值;(time1-time2)为当前新闻报道m中事件发生的时间time1与话题类簇n中种子事件发生的时间time2之间相隔的天数;α、β为调整因子;0.01为经验值。本实施例选用夹角余弦与时间距离加权的算法作为计算新闻报道事件之间相似度的方法,用单通道聚类法进行聚类,获得关键词类簇,获取具有代表性的关键词来表示该类簇代表的话题。基于时间和夹角余弦的聚类方法对新闻报道话题检测具有较好的检测能力。单通道聚类法是流式数据聚类的经典方法,对于给定的数据流,按照一定的顺序处理数据。处理过程中,根据当前数据与已知话题的相似度,与阈值进行对比,来决定加入一个旧的话题还是增加一个新话题。参照图1所示,本发明的方法具体流程包括:步骤(1)对新闻语料集进行预处理,对文本信息进行关键词抽取;步骤(2)根据时间-事件模型的格式,对报道内容进行向量表示;步骤(3)对新文档进行相似度计算;步骤(4)若相似度大于阈值,则将对象分配到该类簇中;否则,创造出一个新的类簇,将该对象加入到新的类簇中;步骤(5)重复执行步骤(2)-步骤(4)直到数据流结束,过程结束。为了验证本发明的方法相对于现有技术的优势和优越性,进行了大量实验:采用从腾讯国内和国际新闻报道栏目爬取得到的总计2000多篇报道,抽取新闻报道中的文本信息并构建时间-事件话题模型,本实验从时间-事件话题模型中挑选240篇作为实验语料,采用漏检率、误检率作为评测标准。单次聚类算法中,阈值μ为是否将文本聚类到某一簇里的判定条件。本发明将时间与阈值相结合,根据μ对实验的重要影响,设置不同的μ值进行六组实验,结果如表5所示:表5阈值μ的数值对实验的影响由表5所示,当阈值μ取0.005正确率达到最优值,增大或者减小μ值均会导致聚类效果变差,这是因为相似度距离作为判断当前文件是否属于某个簇的条件,如果阈值过大,会生成过多的新簇,导致描述同一事件或者话题的报道无法聚为一个簇,如果阈值过小,会使得即使不相关的报道仍然被分到了同一个簇里面,无法正确、准确的描述当前话题,导致误检率上升。取阈值μ为0.005,抽取240条语料进行聚类,得到8个正确分类的类簇,挑选类簇中具有代表性的几个关键词来描述该话题,检测结果如下:表6实验结果选取k-means聚类和lda算法与本发明方法进行对比,其中lda采用网上开源的jgibblda模型并且仅用于主题抽取来与本发明方法进行对比。实验选取相同的语料做实验。k-means聚类结果(簇类个数为8)如下:表7k-meanss实验结果由结果可以看出,k-means虽然设置了跟本发明的方法正确识别的簇的个数一样的类簇个数,但是个别话题仍无法正常识别,例如“反法西斯胜利70周年”、“抗日战争胜利70周年”,二者都属于同一个话题“反法西斯胜利70周年”,也就是说“抗日战争胜利70周年”这一主题并未被正确识别出来,说明k-means在子话题的识别上不如本发明提出的方法更有优势。lda作为统计话题模型,广泛用使用在文本话题抽取中。我们选取共计1000篇作为一个文档,里面包含不同的话题,在实验中,alpha数值为5,beta数值为0.1,主题数目设置为8个。其中识别出的部分结果如下:表8lda实验结果从表8中结果可知,lda存在主题重复识别的问题,“伊斯兰恐怖组织”作为重复话题被lda模型检测出来,虽然通过调整lda模型,可能会获得更好的结果,但是需要耗费更多的实验来进行参数修正,因此,本发明提出的方法要优于lda方法。lda方法只是为了表明在主题抽取方面本发明提出的方法较优,并不用于最后结果对比,本发明采用层次聚类方法和改进的k-means方法作为对比方法。表9实验结果对比由实验结果可知,本发明的方法优于k-means聚类、在主题检测方面要优于lda这两个对比方法,经过分析有以下几点:(1)k-means聚类算法需要事先设定簇点,根据个数和位置的不同,会有不同的分类结果。因此需要大量的时间确定聚类中心。而且,初值的设定也可能会对话题中的子话题识别造成一定负面影响。而基于改进的相似度计算方法的单遍聚类法,根据时间顺序将新闻语料依次输入进行聚类,不仅可以自动分类,当新闻顺序不变时,聚类出的结果也不会有改变。(2)lda识别的类簇中的topwords中,有的太过模糊而导致很难识别突发事件。而且,相同话题有可能会被分到不同的主题下。虽然通过重新设置话题个数,lda会根据话题个数产生新的分布,但是,如果想要提高lda的识别效果,需要耗费更多的时间用来处理。而话题模型中的关键词抽取是利用tfidf和textrank算法加权而算出的,通过算法的权重加权,提升了关键词抽取的精度,为后续话题检测实验做了良好的铺垫。(3)层次聚类方法中,需要人为设定合并和分解的终止条件,会导致结果的不确定性,本实验不需要人为设定终止条件。本发明提供的新闻话题检测方法,提出了改进的相似度计算方法,从事件的时间以及关键词的角度出发,采用抽取出的关键词集,通过聚类的方法,根据时间的长短,针对不同的新闻报道,动态地调整新闻报道与话题的相似度,得到关键词类簇,选出具有代表性的关键词作为报道事件的关键词,用来完成新闻话题的检测,能够对新闻报道中的信息进行准确抽取,能够准确地自动检测新闻报道话题,使得话题能够自动更新并动态演化,检测效果好,可以很好地满足实际应用的需要。以上所述实施例仅表达了本发明的实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1