一种基于改进的选择机制和LSTM变体的文本摘要模型及自动文本摘要方法与流程
本发明涉及人工智能与自然语言处理的技术领域,具体涉及一种基于改进的选择机制和lstm变体的文本摘要模型及文本摘要方法。
背景技术:
随着互联网的迅速发展,互联网中的文本数据如新闻、博客、邮件充斥着我们的生活,这些文本数据中往往存在冗余无用的信息。在这个信息爆炸的互联网大数据时代,如何从大量文本数据中检索出有用的信息是一项非常具有挑战性的任务。通过简短的摘要,我们可以高效地检索文本内容,挖掘文本信息。文章的标题可以是哗众取宠、名不副实的,但是文章的摘要一定是符合文章中心思想以及内容的。人工为每篇文章、新闻、博客、邮件撰写摘要,将耗费大量的人力、物力资源。
随着计算机技术和人工智能的发展,自然语言处理领域中的自动文本摘要技术可以高效的完成大量文本摘要工作。自动文本摘要技术分为抽取式文本摘要技术和生成式文本摘要技术,生成式文本摘要技术相比抽取式文本摘要技术有更强的概括能力。本发明就是一种生成式文本摘要技术。然而传统的生成式文本摘要技术仍然存在以下两个问题:1)如何判断原文本中的重要语句和关键词?2)如何提高生成摘要的可读性?
本发明在传统基于注意力机制的编码器-解码器模型上,针对原文本表示问题,基于信息论中信息熵和信息增益的思想设计一种可以提炼原文本概要信息的改进的选择机制,解决如何判断原文本中关键信息的问题;针对解码器的解码过程,基于拷贝的思想设计一种可以拷贝信息的lstm变体作为循环神经网络的循环单元,解决生成摘要中的重复问题从而提高生成摘要的可读性。
技术实现要素:
发明目的:本发明所要解决的技术问题是使用生成式文本摘要技术实现自动文本摘要,针对传统生成式文本摘要技术提炼原文本概要信息困难的问题,提出一种基于信息论中信息熵和信息增益的思想的选择机制对编码后的信息进行提炼;针对生成摘要存在重复单词的问题,提出一种基于拷贝思想的lstm变体作为解码器端循环神经神经网络的循环单元。
技术方案:为实现上述目的,本发明采用的技术方案为:
一种基于改进的选择机制和lstm变体的文本摘要模型,包括编码器、选择器和解码器,所述文本摘要模型的输入样本数据格式为:原文本-摘要;
编码器对输入的样本数据中的原文本序列x=(x0,x1,x2,...,xn)进行编码,得到编码后对应的隐藏状态序列
选择器对隐藏状态序列he进行选择,得到筛选后对应的概要状态序列
步骤a,通过下式计算得到原文本表示s:
步骤b,通过下式计算元素
其中tanh(·)为激活函数,wg和ug为权重矩阵,vg为权重向量,bg为偏置向量;
步骤c,根据步骤b得到的信息增益igi通过下式对元素
步骤d,将
解码器包括词嵌入层和循环神经网络层,循环神经网络层使用lstm变体网络作为循环单元;词嵌入层将样本中真实摘要序列y*中的每一个元素
根据嵌入层输出的wt和lstm变体上一时间步输出的隐藏状态
其中,wc、wo、wc为权重矩阵,bc、bo、bc为偏置向量;
计算候选拷贝信息
更新拷贝细胞状态
计算得到lstm变体输出的隐藏状态
解码器根据
一种基于改进的选择机制和lstm变体的文本摘要方法,包括步骤:
步骤s1,数据预测处理:将采集到的样本数据进行预处理,形成训练样本集,训练样本集中的每个样本格式为:原文本-摘要;
步骤s2,文本摘要模型训练:利用训练样本集使用交叉熵训练算法训练文本摘要模型,所述文本摘要模型为权利要求1所述的文本摘要模型;训练的具体步骤包括:
步骤s21,编码阶段:使用文本摘要模型中的编码器对样本中的原文本序列x=(x0,x1,x2,...,xn)进行编码,得到编码后对应的隐藏状态序列
步骤s22,选择阶段:使用文本摘要模型中的选择器对步骤s21得到的隐藏状态序列进行选择,得到筛选后对应的概要状态序列
步骤s23,解码阶段:使用文本摘要模型中的解码器将样本中的摘要序列
步骤s24,反向传播更新模型参数:计算步骤s23中得到的生成摘要序列y=(y0,y1,y2,...,yn)与参考摘要序列
步骤s3,对新输入的原文本,利用训练好的文本摘要模型使用集束搜索算法生成摘要。
进一步的,所述步骤s21编码阶段在时间步t时刻执行以下步骤:
步骤s211,将xt输入到编码器的词嵌入层,得到对应的词嵌入向量wt;
步骤s212,将步骤s211得到的词嵌入向量wt和上一时间步编码器输出的隐藏状态
步骤s213,将步骤s212得到的正向隐藏状态
进一步的,所述编码器的双向循环网络层使用长短期记忆单元作为循环单元。
进一步的,所述解码阶段的具体步骤包括:
步骤s231,通过下式初始化解码器中循环神经网络层lstm变体网络的待拷贝细胞状态
其中
步骤s232,初始化解码器中循环神经网络层lstm变体网络的拷贝细胞状态
步骤s233,针对样本中真实摘要序列y*中的每一个元素
步骤s2331,将
步骤s2332,将步骤s2331得到的词嵌入向量wt和上一时间步解码器输出的隐藏状态
步骤s2333,针对选择器输出的概要状态序列
其中,tanh(·)为激活函数,wa和ua为权重矩阵,va为权重向量,ba为偏置向量;
步骤s2334,根据步骤s2333得到的注意力得分,通过下式计算概要状态序列
步骤s2335,根据步骤s2334得到的注意力分布,通过下式计算上下文向量ct:
步骤s2336,根据步骤s2335得到的上下文向量,通过下式计算对应的词汇表分布pvocab,t:
其中,softmax(·)为归一化指数函数,wh和wh为权重矩阵,bz和bh为偏置向量;
步骤s2337,根据步骤s2336得到的词汇表分布pvocab,t通过指针-生成网络计算得到虚拟词汇表分布
步骤s2338,根据步骤s2337得到的虚拟词汇表分布
进一步的,所述步骤s2337中指针-生成网络计算得到虚拟词汇表分布
步骤s23371,通过下式计算生成概率pgen,t:
其中,wg、ug和vg是权重矩阵,bg是偏置向量,其参数都通过网络学习得到;
步骤s23372,通过下式构造虚拟词汇表vvir:
vvir=v∪χ∪<unk>
步骤s23373,通过下式计算生成词汇表分布pg(yt):
步骤s23374,通过下式计算拷贝词汇表分布pc(yt):
步骤s23375,通过下式计算虚拟词汇表分布
进一步的,所述步骤s3中对新输入的原文本生成摘要的具体步骤包括:
步骤s31,对新输入的原文本进行数据预处理为文本摘要模型接受的输入序列x=(x0,x1,x2,…,xn);
步骤s32,编码阶段:使用文本摘要模型中的编码器对样本中的原文本序列x进行编码,得到编码后对应的隐藏状态序列
步骤s33,选择阶段:使用文本摘要模型中的选择器对步骤s32得到的隐藏状态序列进行选择,得到筛选后对应的概要状态序列
步骤s34,解码阶段:使用文本摘要模型中的解码器对步骤s33中得到的概要状态序列
步骤s35,文本摘要模型输出生成摘要y并结束。
本发明相比现有技术,具有以下有益效果:
本发明在基于注意力机制的编码器-解码器模型基础上,提出基于信息论中信息熵和信息增益的思想而改进的选择机制和基于拷贝思想的lstm变体。一方面,改进的选择机制可以判断原文本中的关键信息,并将概要信息提炼出来,提高了自动文本摘要的概括能力;另一方面,以lstm变体作为解码器端循环神经网络的循环单元可以优化解码过程,提高解码效率,减少生成摘要中的重复问题从而提高生成摘要的可读性。
附图说明
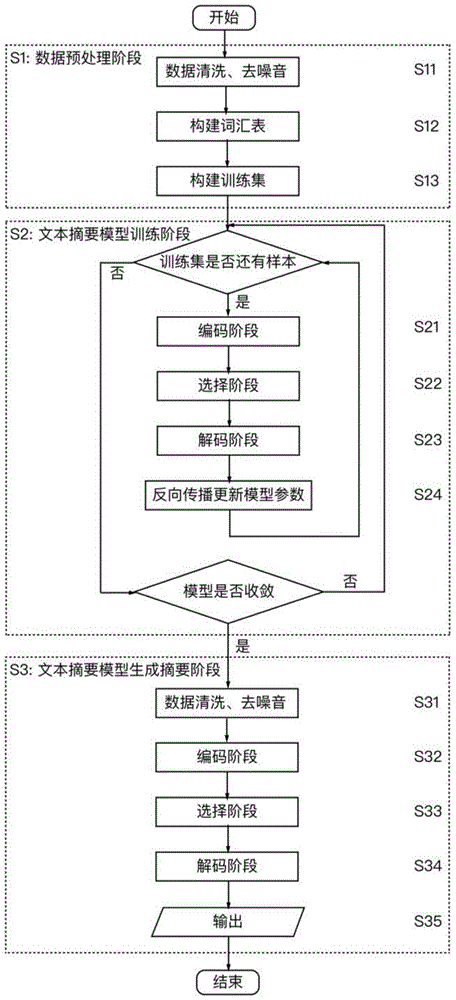
图1是本发明的一种基于改进的选择机制和lstm变体的文本摘要方法的流程图;
图2是本发明的一种基于改进的选择机制和lstm变体的文本摘要模型的结构示意图;
图3是本发明编码器与选择器的结构示意图;
图4是本发明解码器中lstm变体的结构示意图;
图5是本发明的文本摘要模型解码器训练阶段的流程图;
图6是本发明的文本摘要模型解码器生成摘要阶段的流程图。
具体实施方式
下面结合附图和具体实施例,进一步阐明本发明,应理解这些实例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
参照下面的描述和附图,将清楚本发明的实施例的这些和其他方面。在这些描述和附图中,具体公开了本发明的实施例中的一些特定实施方式,来表示实施本发明的实施例的原理的一些方式,但是应当理解,本发明的实施例的范围不受此限制。相反,本发明的实施例包括落入所附加权利要求书的精神和内涵范围内的所有变化、修改和等同物。
以下结合附图描述根据本发明实施例的一种基于改进的选择机制和lstm变体的文本摘要模型及文本摘要方法。
如图2所示为基于改进的选择机制和lstm变体的文本摘要模型结构图,包括编码器、选择器、解码器;其中,编码器对输入的样本数据中的原文本序列x=(x0,x1,x2,...,xn)进行编码,得到编码后对应的隐藏状态序列
选择器对隐藏状态序列he进行选择,得到筛选后对应的概要状态序列
步骤a,通过下式计算得到原文本表示s:
步骤b,通过下式计算元素
其中tanh(·)为激活函数,wg和ug为权重矩阵,vg为权重向量,bg为偏置向量;
步骤c,根据步骤b得到的信息增益igi通过下式对元素
步骤d,将
解码器包括词嵌入层和循环神经网络层,循环神经网络层使用lstm变体网络作为循环单元;词嵌入层将样本中真实摘要序列y*中的每一个元素
根据嵌入层输出的wt和lstm变体上一时间步输出的隐藏状态
其中,wc、wo、wc为权重矩阵,bc、bo、bc为偏置向量;
计算候选拷贝信息
更新拷贝细胞状态
计算得到lstm变体输出的隐藏状态
解码器根据
如图1所示,本发明提出一种基于改进的选择机制和lstm变体的文本摘要方法,包括如下步骤:
步骤s1,数据集预处理阶段:将数据集进行预处理,形成用于训练文本摘要模型的训练集。
步骤s2,文本摘要模型训练阶段:利用训练集使用交叉熵训练算法训练模型,得到文本摘要模型。
步骤s3,文本摘要模型生成摘要阶段:对新输入的原文本,利用训练好的文本摘要模型使用集束搜索算法生成摘要。
具体的,步骤s1具体包括以下步骤:
步骤s11,数据清洗、去噪音;
步骤s12,构建词汇表:遍历原文本和摘要并统计每个单词在整个语料中出现的词频,将单词按词频排序并保留前5万个单词构建词汇表,每一行格式如下:
id单词词频
其中,id、单词、词频用空格隔开,id从0开始。词汇表中默认<sos>是id为0的单词表示序列的开始,<eos>是id为1的单词表示序列的结束。
步骤s13,构建训练集:将原文本和摘要中的单词用词汇表中的id替代,并将不在单词表中的单词去除。每一行为一个原文本和摘要样本构建训练集,每一行格式如下:
原文本摘要
其中,原文本和摘要用tab隔开。
进一步的,对于英文语料数据集,步骤s11具体包括以下步骤:
步骤s111,将英文字母全部小写;
步骤s112,所有的符号统一转换为英文符号。
进一步的,对于中文语料数据集,步骤s11具体包括以下步骤:
步骤s113,将原文本和摘要进行分词,用逗号隔开每个单词;
步骤s114,所有的符号统一转换为中文符号。
具体的,针对训练集中的每一个原文本-摘要样本,所述步骤s2具体包括以下步骤:
步骤s21,编码阶段:使用文本摘要模型中的编码器对样本中的原文本序列x=(x0,x1,x2,...,xn)进行编码,得到编码后对应的隐藏状态序列
步骤s22,选择阶段:使用文本摘要模型中的选择器对步骤s21得到的隐藏状态序列进行选择,得到筛选后对应的概要状态序列
步骤s23,解码阶段:使用文本摘要模型中的解码器将样本中的摘要序列
步骤s24,反向传播更新模型参数阶段:计算步骤s23中得到的生成摘要序列y=(y0,y1,y2,...,yn)与参考摘要序列
请参考图3,针对原文本输入序列中的每一个单词元素xt,所述步骤s21编码阶段对应时间步t时刻具体包括以下步骤:
步骤s211,将xt输入到编码器的词嵌入层(embedding)得到对应的词嵌入向量wt;
步骤s212,将步骤s211得到的词嵌入向量wt和上一时间步编码器输出的隐藏状态
步骤s213,将步骤s212得到的正向隐藏状态
如图3所示,针对步骤s21得到的隐藏状态序列中的每个元素
步骤s211,通过下式计算得到原文本表示s:
步骤s212,通过下式计算元素
其中tanh(·)为激活函数,wg和ug为权重矩阵,vg为权重向量,bg为偏置向量,其参数都是通过网络学习得到;
步骤s213,根据步骤s212得到的信息增益igi通过下式对元素
步骤s214,将
如图5所示,步骤s23具体包括以下步骤:
步骤s231,通过下式初始化解码器中循环神经网络层lstm变体网络的待拷贝细胞状态
其中
步骤s232,初始化解码器中循环神经网络层lstm变体网络的拷贝细胞状态
步骤s233,针对样本中真实摘要序列y*中的每一个元素
步骤s2331,将
步骤s2332,将步骤s2331得到的词嵌入向量wt和上一时间步解码器输出的隐藏状态
步骤s2333,针对选择器输出的概要状态序列
其中tanh(·)为激活函数,wa和ua为权重矩阵,va为权重向量,ba为偏置向量,其参数都是通过网络学习得到;
步骤s2334,根据步骤s2333得到的注意力得分,通过下式计算概要状态序列
步骤s2335,根据步骤s2334得到的注意力分布,通过下式计算上下文向量ct:
步骤s2336,根据步骤s2335得到的上下文向量,通过下式计算对应的词汇表分布pvocab,t:
其中softmax(·)为归一化指数函数,wh和wh为权重矩阵,bz和bh为偏置向量,其参数都是通过网络学习得到;
步骤s2337,根据步骤s2336得到的词汇表分布pvocab,t通过指针-生成网络计算得到虚拟词汇表分布
步骤s2338,根据步骤s2337得到的虚拟词汇表分布
如图4所示,步骤s2332具体包括以下步骤:
步骤s23321,根据嵌入层输出的wt和lstm变体上一时间步输出的隐藏状态
其中wf和bf分别为权重矩阵和偏置向量,其参数都是通过网络学习得到;
步骤s23322,根据embedding层输出的wt和lstm变体上一时间步输出的隐藏状态
其中wc和bc分别为权重矩阵和偏置向量,其参数都是通过网络学习得到;
步骤s23323,根据embedding层输出的wt和lstm变体上一时间步输出的隐藏状态
其中wo和bo分别为权重矩阵和偏置向量,其参数都是通过网络学习得到;
步骤s23324,通过下式计算候选拷贝信息
其中wc和bc分别为权重矩阵和偏置向量,其参数都是通过网络学习得到;
步骤s23324,通过下式更新拷贝细胞状态
步骤s23325,通过下式更新待拷贝细胞状态
步骤s23326,通过下式计算得到lstm变体输出的隐藏状态
进一步的,步骤s2337具体包括以下步骤:
步骤s23371,通过下式计算生成概率pgen,t:
其中wg、ug和vg是权重矩阵,bg是偏置向量,其参数都通过网络学习得到;
步骤s23372,通过下式构造虚拟词汇表vvir:
vvir=v∪χ∪<unk>
步骤s23373,通过下式计算生成词汇表分布pg(yt):
步骤s23374,通过下式计算拷贝词汇表分布pc(yt):
步骤s23375,通过下式计算虚拟词汇表分布
如图6所示,针对新输入的原文本,步骤s3具体包括以下步骤:
步骤s31,对新输入的原文本进行数据预处理为文本摘要模型接受的输入序列x=(x0,x1,x2,…,xn);
步骤s32,编码阶段:使用文本摘要模型中的编码器对样本中的原文本序列x进行编码,得到编码后对应的隐藏状态序列
步骤s33,选择阶段:使用文本摘要模型中的选择器对步骤s32得到的隐藏状态序列进行选择,得到筛选后对应的概要状态序列
步骤s34,解码阶段:使用文本摘要模型中的解码器对步骤s33中得到的概要状态序列
步骤s35,文本摘要模型输出生成摘要y并结束。
进一步的,步骤s31具体包括以下步骤:
步骤s311,数据清洗、去噪音,同步骤s11;
步骤s312,将步骤s311处理后的原文本序列中的单词用步骤s12得到的词汇表中的id替换得到文本摘要模型接受的输入序列x=(x0,x1,x2,...,xn)。
请参考图6,进一步的,步骤s34具体包括以下步骤:
步骤s341,通过下式初始化解码器中循环神经网络层lstm变体网络的待拷贝细胞状态
其中
步骤s342,初始化解码器中循环神经网络层lstm变体网络的拷贝细胞状态
步骤s343,以y0=<sos>作为解码器的第一个输入,预测得到对应的下一个摘要词直到<eos>或达到生成摘要的最大长度,最终得到生成摘要序列y=(y0,y1,y2,...,ym)。
进一步的,步骤s343中根据yt-1预测yt的过程同步骤s233。
终上所述,本发明在基于注意力机制的编码器-解码器模型基础上,提出基于信息论中信息熵和信息增益的思想而改进的选择机制和基于拷贝思想的lstm变体,为生成式文本摘要技术提供了一种新的方式。
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!