一种基于注意力决策的图像视觉问答模型、方法和系统与流程
本发明属于开放式图像视觉问答领域,更具体地,涉及一种基于注意力决策的图像视觉问答模型、方法和系统。
背景技术:
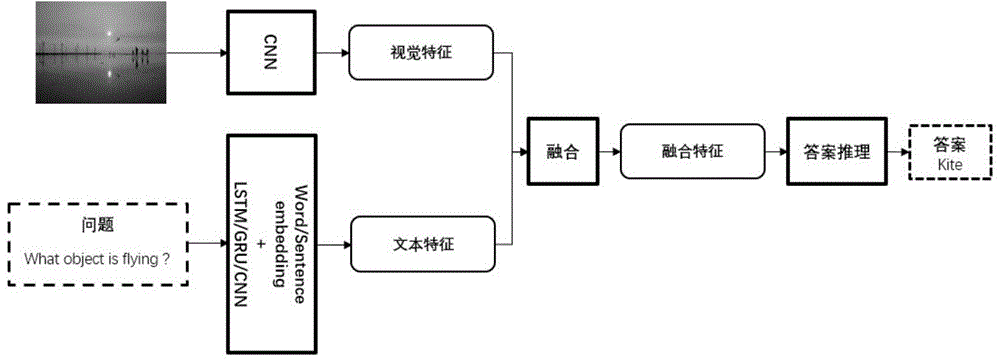
深度学习的发展推动了许多高层次的人工智能任务的研究,例如,视觉问答(visualquestionanswering,vqa)。图像视觉问答是输入一张视觉图像和一个与图像内容相关的开放式自然语言问题,智能系统通过识别理解图像与问题来自行输出自然语言答案。视觉问答可以进行自动量化评估,可以有效跟踪任务的发展。因为关于图片的问题往往倾向于寻找特定的视觉信息,因此对于许多问题,答案仅仅包含一到三个单词,可以通过正确回答问题的数量评估视觉问答算法。图1给出了大多数基于深度学习的视觉问答模型,它主要包括以下四个模块:(1)视觉信息提取模块:一般使用深度卷积神经网络cnn,代表的模型有alexnet,vggnet,googlenet和resnet等;(2)问题分析模块:一般使用深度循环神经网络rnn、长短期记忆网络、门控循环单元和卷积神经网络;(3)多模态信息融合模块:常用的方法有按位加,按位乘,链接和双线性池化等;(4)答案推理模块:一般使用多层感知机。
视觉问答任务中要根据问题在图像中的相关区域找到对应的答案,因此问题引导的图像注意力机制(attentionmechanism)是解决视觉问答任务的重要方法。注意力机制的主要目标是通过使用局部图像特征,并允许模型对不同区域的特征赋予不同的重要性来解决问题。
现有技术都采用的“软注意力”(softattention)方法,为图像中的每一个区域分配一个权重。但是图像中有一些区域和问题无关,这些区域的权重应该被设置为零,而“软注意力”方法分配的权重很难收敛到零。因此会引入一些与问题无关的噪声信息,影响最后答案的决策。另一方面,一些方法为了基于对象语义推理答案,会使用预训练的图像目标检测方法检测图像中的对象,并获得这些对象的特征向量。然后使用软注意力机制为每一个对象分配一个注意力权重。但是这种多阶段处理方法不能端到端训练(endtoendtrain),导致对象特征不具有问题针对性。
技术实现要素:
针对现有技术的缺陷,本发明的目的在于解决现有技术与问题无关的视觉特征影响答案推理、学习到的对象特征不具有问题针对性的技术问题。
为实现上述目的,第一方面,本发明实施例提供了一种基于注意力决策的图像视觉问答模型,所述模型包括:
视觉信息提取模块,用于提取图像i的全局图像特征g和空间图像特征v,全局图像特征g发送给信息融合模块,空间图像特征v发送给特征抽取池化模块;
问题分析模块,用于提取问题q的问题特征向量q,并发送给信息融合模块;
信息融合模块,用于在k=1时,接收并融合来自视觉信息提取模块的全局图像特征g和来自问题分析模块的问题特征向量q,得到融合特征向量uk;或者,在k=2,…,k时,接收并融合特征向量uk-1和来自特征抽取池化模块的图像特征向量
注意力决策模块,用于接收来自信息融合模块的融合特征向量uk,决策出注意力框lk,并发送给特征抽取池化模块;
特征抽取池化模块,用于接收来自视觉信息提取模块的空间图像特征v和来自注意力决策模块的注意力框lk,得到图像特征向量
答案推理模块,用于接收来自信息融合模块的融合特征向量uk,推理出问题q的答案。
具体地,所述融合特征向量uk通过以下方式获得:
其中,fc1、fc2和fc3为全连接神经网络,运算符[,]表示连接两个向量。
具体地,所述决策出注意力框lk,具体如下:
hagent,k+1=rnn(hagent,k,uk)
x′=fc4(hagent,k+1)
y′=fc5(hagent,k+1)
a′=fc6(hagent,k+1)
b′=fc7(hagent,k+1)
其中,hagent,k为第k次决策时内部历史状态,hagent,0为零向量,rnn为循环神经网络,fc4、fc5、fc6和fc7为全连接神经网络,
具体地,在空间图像特征v中,以(x,y)为中心,选择长为a宽为b的矩形区域的特征,再对其进行池化操作,得到一维图像特征向量
具体地,利用强化学习的方法学习自适应的注意力决策过程。
第二方面,本发明实施例提供了一种基于注意力决策的图像视觉问答方法,该方法包括以下步骤:
s1.使用p个训练样本训练如第一方面所述的基于注意力决策的图像视觉问答模型,比较训练样本的推理答案与该训练样本的标签是否相同,若相同,则该训练样本每次注意得到的分数均为1,否则,均为0;
s2.基于rij构建损失函数l,以损失函数l为目标函数,优化网络参数,得到训练后的基于注意力决策的图像视觉问答模型,rij为第j个样本第i次注意得到的分数,j=1,…,p,i=1,…,k;
s3.将待测图像i和问题q输入训练好的基于注意力决策的图像视觉问答模型,得到最终答案。
具体地,利用批量随机梯度下降优化。
具体地,所述损失函数l的计算公式如下:
其中,log(πθ(x,y,a,b))表示计算状态为hagent,i+1、决策为(x,y,a,b)时的损失。
第三方面,本发明实施例提供了一种基于注意力决策的图像视觉问答系统,该系统采用上述第二方面所述的基于注意力决策的图像视觉问答方法。
第四方面,本发明实施例提供了一种计算机可读存储介质,该计算机可读存储介质上存储有计算机程序,该计算机程序被处理器执行时实现上述第二方面所述的基于注意力决策的图像视觉问答方法。
总体而言,通过本发明所构思的以上技术方案与现有技术相比,具有以下有益效果:
1.本发明利用强化学习,学习特征选择的决策过程,可以自适应的选择与问题相关的视觉特征。将图像上的注意力变化调整过程看作一个序列化决策过程,也就是连续的选择图像区域特征,然后融合这些特征,推出答案。可以端到端的训练,让学习到的特征更加具有问题针对性。
2.本发明每次选择图像上一个与问题相关的区域,记录这个区域的信息,忽略与问题无关的信息,可以有效的排除干扰信息。
附图说明
图1为现有技术中的基于深度学习的视觉问答模型结构示意图;
图2为本发明实施例提供的一种基于强化学习的图像视觉问答模型结构示意图;
图3为本发明实施例提供的特征抽取池化过程示意图;
图4为本发明实施例提供的一种基于强化学习的图像视觉问答方法流程图;
图5为本发明实施例提供的注意力决策过程示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
如图2所示,一种基于注意力决策的图像视觉问答模型,所述模型包括:
视觉信息提取模块,用于提取图像i的全局图像特征g和空间图像特征v,全局图像特征g发送给信息融合模块,空间图像特征v发送给特征抽取池化模块;
问题分析模块,用于提取问题q的问题特征向量q,并发送给信息融合模块;
信息融合模块,用于在k=1时,接收并融合来自视觉信息提取模块的全局图像特征g和来自问题分析模块的问题特征向量q,得到融合特征向量uk;或者,在k=2,…,k时,接收并融合特征向量uk-1和来自特征抽取池化模块的图像特征向量
注意力决策模块,用于接收来自信息融合模块的融合特征向量uk,决策出注意力框,并发送给特征抽取池化模块;
特征抽取池化模块,用于接收来自视觉信息提取模块的空间图像特征v和来自注意力决策模块的注意力框,得到图像特征向量
答案推理模块,用于接收来自信息融合模块的融合特征向量uk,推理出问题q的答案。
1.视觉信息提取模块
本发明中,视觉信息提取模块采用卷积神经网络提取图像i的全局图像特征g和空间图像特征v。
对输入图像进行预处理,将输入图像i统一为具有3个通道,大小为244*244的图像i′。
卷积神经网络特征层数越深越具有类别鉴别能力,并且卷积层输出的特征向量保留了空间分布信息。因此,提取卷积神经网络最后一个卷积层的特征图vd×m×n和最后一个全连接层的特征g作为图像特征。
g=cnnfc(i′)
vd×m×n=cnnconv(i′)
其中,d表示卷积核的个数,m×n表示图像特征图空间尺寸。本发明实施例优选vgg16,m=n=14,d=2048。
2.问题分析模块
本发明中,问题分析模块采用glove词嵌入和门控循环单元网络,提取问题q的问题特征向量q。
首先将问题中的每一个单词进行one-hot编码成ci,如果长度大于n,则删除超出的部分,长度不足,使用空(null)填充到指定的长度。本发明实施例优选n=14。
q′={c1,c2,c3,…,cn}
使用预训练的glove300词向量,将每个单词的one-hot编码转化为300维的词向量得到qwe。
qwe=we(q)={w1,w2,…,wn}∈rn×300
其中,we表示将单词转化为词向量的函数,wi是每个词对应的词向量。
将wi按照先后顺序输入到门控循环单元网络(gatedrecurrentunit,gru)中,得到问题编码向量q。
q=gru(qwe)
3.信息融合模块
本发明中,信息融合模块由全连接神经网络fc1、fc2和fc3组成,它们的激活函数是relu函数,但是权重参数有区别。全连接层的作用是对数据进行非线性映射,提取抽象特征。此处,k=1,fc1处理全局图像特征g,fc2处理问题特征向量q;k>1,fc1处理图像特征向量,fc2处理融合特征向量;fc3将两个输入特征融合得到融合特征。
其中,运算符[,]表示连接两个向量。
4.注意力决策模块
本发明中,注意力决策模块采用循环神经网络rnn、fc4、fc5、fc6和fc7,决策出注意力框位置(x,y)和长宽(a,b)。hagent,0为零向量。
hagent,k+1=rnn(hagent,k,uk)
其中,hagent,k为当前内部历史状态。
x′=fc4(hagent,k+1)
y′=fc5(hagent,k+1)
a′=fc6(hagent,k+1)
b′=fc7(hagent,k+1)
其中,fc4、fc5、fc6和fc7激活函数是双曲正切激活函数(tanh),但是权重参数有区别。
x=x′+φ1
y=y′+φ2
a=a′+φ3
b=b′+φ4
φ1、φ2、φ3和φ4为均满足均值为0,方差为1的正态分布的随机数。为决策的结果添加随机噪声,增加模型的搜索能力,有助于搜索到最优解。-1≤x≤1,-1≤y≤1,0≤a≤1,0≤b≤1。
5.特征抽取池化模块
本发明中,特征抽取池化模块根据融合特征向量uk从空间图像特征v中选择图像特征向量
v2048×a×b=selector(v2048×m×n,x,y,a,b)
其中,ap(averagepooling)表示均值池化操作。
6.答案推理模块
本发明中,答案推理模块采用mlp(multi-layerperceptron,multi-layerperceptron)推理出问题q的答案。
推理过程如下:
h=fc9(fc8(u3))
其中,h是候选答案分数向量,i是候选答案的索引,hi是向量h中第i个分数,
利用强化学习的方法学习自适应的注意力决策过程。首先环境给出了当前用于推理答案的融合特征。智能体根据当前的融合特征,判断还需要补充哪些视觉信息,也就是给出下一步需要到哪个位置获取视觉信息。环境在得到位置之后,根据位置在空间特征中抽取出对应位置的视觉信息,将其与当前的融合信息再次融合得到融合特征,再次将其给智能体。迭代数次后,将使用最后的融合特征推理答案。如果答案正确,则给予这次决策1的奖励,否则奖励为0。智能体根据奖励的情况,改变注意力决策的策略。
环境(enviroment):空间图像特征、特征抽取池化模块和信息融合模块。
智能体(agent):注意力决策模块。
状态(state):融合特征。
动作(action):注意力框的位置(x,y)以及长a、宽b。
策略(policy):从当前融合特征到注意力框的位置(x,y)以及长a、宽b的映射过程。决策函数πθ为计算注意力的过程,θ是函数的参数。
奖赏(reward):奖励函数
关于图像的问题,一般需要多次调整注意位置才能精确的找到回答问题的一系列信息。这个过程可以看作一个序列化决策过程,也就是连续的选择图像区域特征,然后融合这些特征,推出答案。本发明使用强化学习方法,学习图像上注意力位置决策过程。每次选择图像上一个与问题相关的区域,记录这个区域的信息。
如图4所示,一种基于注意力决策的图像视觉问答方法,该方法包括以下步骤:
s1.使用p个训练样本训练基于注意力决策的图像视觉问答模型,每个样本训练经历k次注意力决策得到推理答案,比较推理答案与该训练样本的标签是否相同,若相同,则k次注意得到的分数均为1,否则,均为0;
s2.以损失函数l为目标函数,利用批量随机梯度下降优化方式优化网络参数,得到训练后的基于强化学习的图像视觉问答模型;
其中,log(πθ(x,y,a,b))表示计算状态为hagent,i+1、决策为(x,y,a,b)时的损失,rij为第j个样本第i次注意得到的分数。
s3.将待测图像i和问题q输入训练好的基于强化学习的图像视觉问答模型,得到最终答案。
训练样本的标签代表真实答案。如果位置框选中的信息与问题无关,那么得到的答案必然是错误的,因此,得到的奖励少,下一次选中该位置的概率减小,因此,在此机制之下,与问题无关的信息会更少参与计算。
如图5所示,输入的图像i是一个打棒球的运动员的场景,输入的问题q是“whatistheplayer’snumber?”。回答问题时,注意力的变化过程。针对“whatistheplayer’snumber?”,模型首先定位到运动员,然后定位到运动员的球衣号码,最后给出答案“22”。
以上,仅为本申请较佳的具体实施方式,但本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应该以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!