一种基于自动编码器的突发事件检测与预测方法与流程
本发明涉及文本检测与预测领域,尤其涉及一种基于自动编码器的突发事件检测与预测方法。
背景技术:
目前在相关技术中,突发事件的文本表示技术主要是自动编码器(autoencoder)。在深度学习中,自动编码器用于训练阶段,对输入的数据进行特征转换,即将数据编码成另一种形式,然后在此基础上进行一系列学习。自动编码器的本质是利用隐藏层的网络节点重构出输入层的神经元,即使神经网络的输出尽可能地与网络的输入信息相似,在训练的过程中,使用反向传播的方法不断优化损失函数以获得更小的损失值。由于隐藏层中神经元之间的竞争,每个神经元变为专门识别特定的数据模式,所以就整体而言,自动编码器可以学习到有意义的文本表示。在图像数据集表示领域,自动编码器已经得到了广泛的应用并得到了比较好的效果。但是,由于文本十分复杂,例如:高维度,稀疏性和幂律词分布等,传统的自动编码器可能更倾向于学习文本的简单表示,它们在文本数据集上的表现尚未得到广泛研究。
突发事件的检测技术主要是single-pass聚类技术。single-pass聚类算法的主要思想是依次来输入文本以确定当前文本与现有聚类结果之间的匹配程度。如果当前文本与现有结果匹配,则将当前文本归于其中,否则将创建新的簇集。然而,在single-pass算法中,输入模型的文本的顺序将直接影响到聚类的最终效果,而且,传统的单一阈值若设置过高会造成聚类结果的粒度太小进而降低聚类结果的召回率,若阈值设置过高会造成聚类结果的粒度太大进而降低聚类结果的准确率。
突发事件的预测技术主要是基于话题热度值的增长率的预测方法。利用话题热度值随时间窗变化的增长率来预测热点事件和突发事件,指定话题热度阈值fthre、一阶导数阈值dthre1和二阶导数阈值dthre2,当话题热度值大于阈值fthre时,首先计算该主题热度的一阶导数,若该主题的一阶导数大于dthre1,且该主题的二阶导数不小于dthre2,则认为该话题是热点事件,否则该话题不属于热点事件。但该方法存在明显缺陷,因为话题的热度值是基于时间窗来计算的,所以话题的热度值不是连续的,并且在实际情况中,由于网络中突发事件的突发性和复杂性,话题的热度值是上下波动的,话题热度值是随时间窗的变化而起伏波动的,而在理想的基于增长率的预测方法中,默认主题热度值的一阶增长率只有一个最高点。因此,该方法对实际应用中的热点事件和突发事件的预测效果并不理想。
技术实现要素:
本发明提供了一种基于自动编码器的突发事件检测与预测方法,本发明能够有效克服将新闻文档转化为向量后,文档的向量维度较高,且具有稀疏性的问题,同时更适应实际中新闻文本数量随时间变化而有所改变的情况,详见下文描述:
一种基于自动编码器的突发事件检测与预测方法,所述方法包括以下步骤:
对数据文本进行中文分词与停用处理;将处理后的数据文本用文本向量表示,并对文本向量进行降维操作;
计算当前文本与每个主题之间的相似度,并将文本与所有主题间的相似度从小到大进行排序,取相似度最大的值与阈值进行比较判断当前文本所属主题或重新建立新主题;
计算话题热度值,将属于某一话题的新闻文本的第一次出现的时间窗与预测该话题成为热点话题的时间窗的差值小于指定阈值的事件归类到突发事件中。
其中,所述计算话题热度值具体为:基于rd的能量衰减计算话题热度值。
进一步地,所述方法还包括:
基于增长率预测突发事件,在判断某一主题是否为突发事件时,将该话题成为热点事件的时间窗与第一次出现属于该话题的新闻文本的时间窗进行对比。
其中,所述对文本向量进行降维操作具体为:
在隐藏层加入阈值r,当隐藏层中的失败节点的能量值的绝对值大于给定的阈值r时,则将该节点看作是对自编码网络的学习有作用的;
当失败神经元的激活值小于给定阈值r时,将失败神经元的激活值加到成功神经元上,并将失败神经元的值置为零。
进一步地,所述基于增长率预测突发事件具体为:
定义主题热度值的增长率曲线:
dt=g[f(yt)],f(yt)∈[f(ya),f(yb)]
其中,a代表主题热度曲线处于增长阶段时的最大增长率的时间点,b表示主题热度曲线由增长趋于平稳的时间点,f(ya)和f(yb)分别表示该话题在a点和b点的话题热度值;
同时,针对由于时间窗造成的话题热度值的增长率的波动问题,采用下式对增长率进行平滑处理;
其中,dt代表主题在时间窗t上的实际增长率,δi表示在对应的时间窗t处的话题热度值增长率所对应的平滑因子。
其中,所述将属于某一话题的新闻文本的第一次出现的时间窗与预测该话题成为热点话题的时间窗的差值小于指定阈值的事件归类到突发事件中具体为:
设置两个阈值t1和t2,如果存在某一主题使得其与文本间的相似度大于t1,则认为当前文本属于这一主题并更新主题中心向量;若小于t2,则认为没有与当前文本相对应的主题,同时创建一个新的主题;若小于t1但大于t2,则认为当前文本仍有可能属于当前主题,比较并排序当前文本与这一主题中的所有新闻文本的相似度,若其最大值大于t1,则认为当前文本属于这一主题,并将该文本归入这一主题,同时更新主题中心。
本发明提供的技术方案的有益效果是:
本发明使用在训练过程中模型损失值评估kaer对文本向量降维的效果,并与kate进行比较。实验结果如图2所示,可以看出kaer比kate的实验效果更好。在经过训练之后,kaer的损失值从开始的0.599下降到0.141,而kate的损失值从开始的0.624下降到0.157,。就输入向量的重构性而言,与kate相比,kaer能够更好地重构出模型的输入数据。
在突发事件的检测上,本发明采用改进的single-pass方法分别对降维后的向量进行聚类操作,并使用准确率,召回率以及f值进行评估。实验结果表明,就聚类结果而言,降维后的文本向量的准确率和召回率明显高于降维前的结果,说明改进的自动编码器在通过对文本向量进行降维的同时,也可以较好的学习文本特征。
本发明采用改进的基于rd的能量衰减方案计算话题热度值,并对比基于rd的能量衰减方案与改进的基于rd的能量衰减方案,同一主题的热度值随着时间窗变化的曲线分别如图3和图4所示。可以看出,在改进的基于rd的能量衰减方案中,营养衰减因子随当前所在的时间窗中新闻文本的数量而动态变化,因此得以充分考虑了不同时间窗下,新闻文本数量有明显区别的因素,该话题的话题热度曲线较为平滑,更加符合话题热度值在实际中的变化情况。
本发明采用改进的基于增长率的热点事件和突发事件预测方法,在判断某一主题是否为突发事件时,将该话题成为热点事件的时间窗与第一次出现属于该话题的新闻文本的时间窗进行对比,预测结果表明,改进的基于增长率的预测方法能够更好地预测热点事件和突发事件。
附图说明
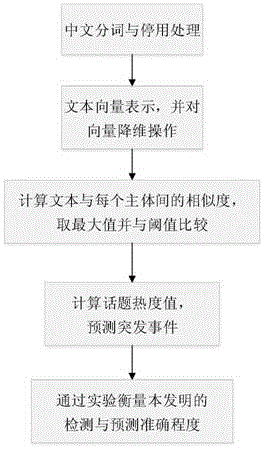
图1为一种基于自动编码器的突发事件检测与预测方法的流程图;
图2为kate(k-竞争自动编码器,k-competitiveautoencoder)和kaer(改进的k竞争自动编码器模型,k-competitiveautoencoderwithr-threshold)损失值对比示意图;
图3为基于rd(递归衰减,recursivedecay)的能量衰减方案下的话题热度曲线示意图;
图4为基于改进的rd的能量衰减方案下的话题热度曲线示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面对本发明实施方式作进一步地详细描述。
实施例1
为了解决背景技术中存在的问题,本发明实施例提出了一种基于自动编码器的突发事件检测与预测方法,参见图1,该方法包括以下步骤:
101:对数据文本进行中文分词与停用处理;
102:将处理后的数据文本用文本向量表示,并对文本向量进行降维操作;
103:计算当前文本与每个主题之间的相似度,并将文本与所有主题间的相似度从小到大进行排序,取相似度最大的值与阈值进行比较判断当前文本所属主题或重新建立新主题;
104:计算话题热度值,将属于某一话题的新闻文本的第一次出现的时间窗与预测该话题成为热点话题的时间窗的差值小于指定阈值的事件归类到突发事件中;
105:通过损失函数、召回率、准确率及f值衡量本发明提出的突发事件检测与预测方法的技术性问题的准确度。
在一个实施例中,步骤101对数据文本进行了中文分词及停用处理,具体步骤如下:
根据中文分词的特点,本发明实施例采用结巴分词进行分词处理,并对分好的词进行词性标记,并在词性标记后采用停用词库过滤掉数据中的停用词。
在一个实施例中,步骤102在步骤101的基础上进行文本向量表示及降维操作,具体步骤如下:
对于已经分好词的新闻文本,逐行读入文本内容,并判断词典中是否包含当前单词,若包含,则将该单词在当前文本中的出现次数自增一次;若不包含,则认为当前单词的重要性较低,直接过滤掉该单词,如此循环直到读完文本中的所有单词。最终,每个新闻文本都表示为由单词在词典中所对应的序号与该单词在当前文本中的出现次数所组成的向量。降维操作采用改进的k竞争自动编码器模型(k-competitiveautoencoderwithr-threshold,kaer)。
在一个实施例中,步骤103对预处理后的新闻文本计算主题相似度,取最大值并与阈值比较,具体步骤如下:
先通过语料库创建词典,然后把文本中的单词与词典进行匹配,并统计匹配的单词的相似度之和,最后采用统计的结果作为两个文本间的相关程度。通过计算主题与新闻文本之间的余弦相似度作为相似度并从小到大进行排序,取最大值。
判断所获取的相似度最大值是否大于指定阈值,若小于指定阈值,则认为当前文本不属于任意一个当前主题,此时需要重新建立一个新的主题,并将当前文本分类到所创建的主题中;反之,则将当前文本分类到此主题中并更新主题的中心向量。
在一个实施例中,步骤104计算话题热度值,预测突发事件,具体步骤如下:
使用改进的基于rd的能量衰减方案(recursivedecaywithdynamictimesolt)计算话题热度值,并使用改进的基于增长率的预测方法预测突发事件,在判断某一主题是否为突发事件时,将该话题成为热点事件的时间窗与第一次出现属于该话题的新闻文本的时间窗进行对比。
在一个实施例中,步骤105中使用损失函数、召回率、准确率及f值衡量本方法的准确程度,具体步骤如下:
通过损失函数计算得到由于压缩而造成的信息的损失程度,统计检测与预测结果与实际结果,计算得到召回率、准确率及f值,衡量本发明的准确程度。
综上所述,本发明实施例能够有效克服将新闻文档转化为向量后,文档的向量维度较高,且具有稀疏性的问题,同时更适应实际中新闻文本数量随时间变化而有所改变的情况。
实施例2
下面结合具体的计算公式对实施例1中的方案进行进一步地介绍,详见下文描述:
201:突发事件的分析过程中,首先进行文本的分词与停用处理,在此过程中用到了结巴分词;
在分词模式方面,结巴分词采用精确模式,此模式用于海量数据中的文本切分,在这一模式下,每个句子被尽可能正确地切分成单词。
202:对于分好的词进行词性标记,在词性标记后采用停用词库过滤掉数据中的停用词;
其中,分好的词例如:名词、动词、形容词等。
203:基于词典的方法来实现新闻文本的向量表示;
在构建词典之后,对词典中的单词进行排序并对每个单词进行编号。在统计单词在当前新闻文本中的出现次数后,使用对数函数标准化文本向量,文本向量的表示如公式(1)所示。
其中,xi表示新闻文本的向量形式,v表示词典,ni表示单词i在当前新闻文本中的出现数量。
204:使用改进的k竞争自动编码器模型(k-competitiveautoencoderwithr-threshold,kaer)实现文本的降维操作;
其中,文本向量具有高维度、稀疏性的特点,本发明实施例使用改进的kaer实现文本的降维操作。通过在隐藏层加入阈值r的方法,当隐藏层中的失败节点的能量值的绝对值大于给定的阈值r时,则将该节点看作是对自编码网络的学习有作用的,对其不予处理;而当失败神经元的激活值小于给定阈值r时,将失败神经元的激活值加到成功神经元上,并将失败神经元的值置为零。本发明实施例中的阈值r的取值为0.1。
205:新闻文本与主题之间的相似度采用余弦相似度进行计算,余弦相似度的计算方法,如公式(2)所示。
其中,d1和d2分别表示新闻文本基于词典的向量表示形式。
206:新闻文本的话题检测采用改进的single-pass算法,然后根据每个主题下的新闻文本的数量对聚类结果进行排序,通过手动标记的方法评估聚类的结果。
在改进的single-pass聚类方法中,设置两个阈值t1和t2,如果存在某一主题使得其与文本间的相似度大于t1,则认为当前文本属于这一主题并更新主题中心向量;若小于t2,则认为没有与当前文本相对应的主题,同时创建一个新的主题;若小于t1但大于t2,则认为当前文本仍有可能属于当前主题,比较并排序当前文本与这一主题中的所有新闻文本的相似度,若其最大值大于t1,则认为当前文本属于这一主题,并将该文本归入这一主题,同时更新主题中心。
207:计算热度值中,用能量值表示话题的发展状态,并用能量值的变化预测该话题可能的生命周期;
其中,对于在第t个时间窗内的任意主题v,令xt表示该主题与指定时间内所有属于这一主题的文本之间的相似度之和。在t时刻,话题的能量值如公式(3)所示。
yt=g(x1,...,xt,α,β)(3)
其中,xi代表第i个时间窗内某一指定主题与属于该主题的新闻文本之间的相似度之和,α和β为生命周期模型中的两个参数,0≤α≤1,0≤β≤1,α表示营养转换因子,α决定了xi能贡献给话题的营养值的比例,β表示营养衰减因子,β决定了该主题在每个时间窗内的能量随时间发展而逐渐降低的情况。
在实际的新闻发布场景中,新闻的数量受到时间因素的影响,一方面,在工作日内发布的新闻数量明显高于周末所发布的新闻数量,另一方面,在特殊事件中所发布的新闻数量明显高于平常所发布的新闻数量,比如世界杯或某地区发生灾难事件的时间段内,由于话题的能量值与属于该话题的新闻文本数量直接相关,而在基于rd的能量衰减方案中,并未考虑到现实情况中时间因素对话题热度的影响,本发明提出动态的营养衰减因子,充分考虑时间区间对话题热度的影响,如公式(4)所示:
βi=β*log(1.0+ni/avg)(4)
其中,ni表示在第i个时间窗内的新闻文本数量,avg表示在一个时间窗内新闻网站发布的新闻文本的平均数量,βi表示在第i个时间片的营养衰减因子,β表示基于rd的能量衰减方案中所计算的营养衰减因子。
其中,定义能量函数f(yt)用来计算话题的热度,该能量函数的自变量为话题的能量值,能量函数需满足以下条件,如公式(5)所示:
其中,yt代表主题在t时刻的能量值大小,f(yt)用于对主题能量进行归一化处理。能量函数的计算方法如公式(6)所示。
f(r·yt)=sr>0,s<1(6)
其中,yt表示话题在t时刻的能量值,上述公式可以解释为当属于一个话题的文本所占的百分比例为r时,能量函数返回的话题热度值为s。
208:采用改进的基于增长率的预测方法(improvedmethodofforecastingbasedonrate),定义主题热度值的增长率曲线如公式(7)所示。
dt=g[f(yt)],f(yt)∈[f(ya),f(yb)](7)
其中,a代表主题热度曲线处于增长阶段时的最大增长率的时间点,b表示主题热度曲线由增长趋于平稳的时间点,f(ya)和f(yb)分别表示该话题在a点和b点的话题热度值。
同时,针对由于时间窗造成的话题热度值的增长率的波动问题,采用公式(8)对增长率进行平滑处理。
其中,dt代表主题在时间窗t上的实际增长率,δ是一组经验值,取值为[32,24,16,8,4],δi表示在对应的时间窗t处的话题热度值增长率所对应的平滑因子。
209:通过损失函数计算得到由于压缩而造成的信息的损失程度,通过统计计算检测与预测结果与实际结果,得到召回率、准确率及f值,衡量本方法的准确程度。
综上所述,本发明实施例设计的一种基于自动编码器的突发事件检测与预测方法,利用自动编码器模型的隐藏层中神经元来表示降维后的文本向量,并且利用改进的能量衰减方案(公式4),使其更适应实际中新闻文本数量随时间变化而有所改变的情况,能够利用网络中已有的新闻信息来提前预测热点事件以及突发事件,可以提供充足的预处理时间以更好地维护社会稳定。
实施例3
下面结合图2-图4对实施例1和2中的方案进行可行性验证,详见下文描述:
为了评估kaer捕获的单词表示在语义上是否有意义,实验验证在向量空间模型[1]中相似或相关的单词是否彼此接近。对于给定主题的单词,获取其在词典中对应的序号,根据得到的序号获取该单词在模型中对应的权重,进而根据权重相近的向量找到与该指定单词相似或相关的单词。就单词的相似性而言,与kate相比,kaer可以学习到相似性更高的单词。
为了评估kaer重构的文本向量与输入向量之间的差值,实验比较在训练过程中模型损失值的变化情况。在给定输入向量xi的情况下,模型的输出向量
其中,v为文本向量的个数,
同时,本发明实施例使用召回率(recall)、准确率(precision)以及f值(f-measure)作为检测评分的评价标准,准确率可以理解为正确预测的样本数量占预测的所有样本数量的比例,主要用来衡量算法的准确性,如公式(10)所示。召回率可以理解为预测的相关文本数量与语料库中相关文本数量的比率,如公式(11)所示。f值可以理解为正确率和召回率的倒数平均数,如公式(12)所示。
其中,m表示聚类算法正确检测出的某一主题中的文本数,n表示在该主题中聚类算法实际上应检测到的属于该主题的文本数。
其中,m表示聚类算法正确检测出的某一主题中的文本数,t表示在指定的文本集中聚类算法实际应检查出的属于该主题的文本数。
其中,p表示准确率,r表示召回率。
实验结果表明就聚类结果而言,降维后的文本向量的准确率和召回率明显高于文本降维前的结果,说明改进的自动编码器在通过对文本向量进行降维以提高算法效率的同时,较好地学习到了文本特征。例如,小米上市的话题,由于在短时间内,上市问题引起广泛关注,因此该话题的准确率和召回率都偏高;长江2018年第1号洪水的话题,由于在该时间段内,国内多个地区的下雨量都较大,造成“暴雨”、“洪水”、“伤亡”等词出现频繁,而降低了地区关键词的比重,因此聚类结果的准确率较低,由于模型将相似结果都视为同一话题,因此召回率较高。
对于改进的增长率的预测方法评估,综合实验结果及分析可知,当事件的出现时间以及随之发展的时间都在选择的数据集的时间范围内时,可以根据事件的发展状况判断其是否为热点事件或突发事件,而当在选择的数据集的时间之前,该事件已经发展成为了热点事件,在这种情况下,模型对于这类事件的突发情况预测并不十分理想。综上所述,改进的基于增长率的预测方法能够较好地预测热点事件和突发事件。
在图2中,kaer比kate的实验效果更好。在kaer中,在经过训练之后,损失值从开始的0.599下降到0.141;而在kate中,损失值由开始的0.624下降到0.157。因此,就输入向量的重构性而言,与kate相比,kaer能够更好地重构出模型的输入数据。
在图3中,在基于rd的能量衰减方案下,经过训练,营养衰减因子的取值为0.0024,由于营养衰减因子是一个固定值,未考虑到不同时间段内的新闻文本数量有明显的区别的因素,因此,该话题的话题热度值曲线变化较为突兀,曲线中的锯齿较多,不利于接下来的基于话题热度曲线的增长率的预测方法。
在图4中,在改进的基于rd的能量衰减方案中,营养衰减因子随当前所在的时间窗中新闻文本的数量而动态变化,因此得以充分考虑了不同时间窗下,新闻文本数量有明显区别的因素,该话题的话题热度曲线较为平滑,也因此更加符合话题热度值在实际中的变化情况。
本领域技术人员可以理解附图只是一个优选实施例的示意图,上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!