一种面向光场图像的深度估计方法与流程
本发明涉及计算机视觉与数字图像处理技术领域,尤其是一种面向光场图像的深度估计方法。
背景技术:
20世纪上半叶,a.gershun等人已经提出了光场概念,用以描述光在三维空间中的辐射特性,然而,光场成像技术相对滞后于理论概念的发展。陆续出现的光场成像设备主要有相机阵列、光场传感器、微透镜阵列等。r.ng等人于2005年设计的手持式光场相机,成为微透镜阵列光场采集设备的代表,直接推动了光场相机(如lytro、raytrix等)快速进入民用市场,同时也在学术界掀起了光场成像的应用研究热潮。
基于图像分析方法获取场景深度信息(物体与成像系统的距离)是计算机视觉领域的一个重要问题,在机器人导航、三维重建、摄影测量等方面有着广泛应用。与传统相机相比,基于微透镜阵列的光场相机能够同时记录光线的位置和方向,由一次曝光采集的光场数据既可以计算得到多视角的子孔径图像又可以生成焦点堆栈图像,为深度估计提供了便利条件。近年来,基于光场成像的深度估计成为cvpr、iccv等计算机视觉顶级会议讨论的话题之一,不少学者开展了该问题的研究:尹晓艮等人直接使用halcon软件的聚焦深度函数进行对焦点堆栈图像进行深度获取,并应用于3d重建。lin等人对编码焦点堆栈进行了系统研究,并利用稀疏编码技术从焦点堆栈中恢复全聚焦图像和全分辨率深度数据。wanner等人提出全局一致性深度标记算法,在全变分框架下,利用epi图像梯度的结构张量求解纹理斜率,并使用最小化能量函数进行全局约束,实现深度信息的估计。suzuki等人就视差范围受限问题,提出在结构张量分析之前先对epi图像进行裁剪,对不同裁剪系数的结构张量分析结果综合生成最终视差图。
中国专利cn104899870a,公布日2015.09.09,申请号201510251234.8,基于光场数据分布的深度估计方法。利用焦点堆栈图像,分别提取同一个宏像素的强度范围,进而选出最小强度范围对应的重聚焦光场图像,以该重聚焦光场图像的焦距作为该宏像素的场景深度。该发明利用lytro等光场相机采集的场景纹理及空间信息,获得细节丰富,特征清晰,准确性、一致性高的场景深度估计。中国专利cn104966289a,公布日2015.10.07,申请号201510324490.5,一种基于4d光场的深度估计方法。该发明重点解决了初始深度值的可靠性问题、深度过平滑问题、深度值融合问题。中国专利cn105551050a,公布日2016.05.04,申请号201511019609.4,一种基于光场的图像深度估计方法。该发明检测显著特征点并将显著特征点匹配作为深度优化的强约束条件,避免了插值过程引起的视点混淆,提升了深度估计准确性。中国专利cn106651943a,公布日2017.05.10,申请号201611262452.2,一种基于遮挡几何互补模型的光场相机深度估计方法。该发明利用相对的两个视角中,所看到遮挡区域具有互补关系的性质,实现较好的遮挡结果和准确深度图。
当前,对光场相机这类新型成像设备的认识以及基于光场成像的深度估计方法的研究均处于新兴探索阶段。现有基于光场的深度估计方法较少关注深度估计对噪声和遮挡的鲁棒性,而这对复杂场景的深度估计是至关重要的。
技术实现要素:
本发明所要解决的技术问题在于,提供一种面向光场图像的深度估计方法,能够由光场数据得到准确的深度估计结果,并且对存在噪声和遮挡的复杂场景具有较高鲁棒性。
为解决上述技术问题,本发明提供一种面向光场图像的深度估计方法,包括如下步骤:
(1)根据光场相机参数信息,将光场原始图像解码为4d光场数据,并提取中心子孔径图像
(2)由步骤(1)得到的4d光场数据,以视差δd为步长,计算生成焦点堆栈图像序列
(3)对中心子孔径图像
(4)对中心子孔径图像
(5)对中心子孔径图像
(6)对中心子孔径图像
(7)对中心子孔径图像
(8)对中心子孔径图像
优选的,步骤(1)中,4d光场记为l:(i,j,k,l)→l(i,j,k,l),其中,(i,j)表示微透镜图像的像素索引坐标,(k,l)表示微透镜中心的索引坐标,l(i,j,k,l)表示通过像素和微透镜中心的光线的辐射强度;提取中心子孔径图像的方法是抽取每个微透镜图像的中心像素,按微透镜位置索引排列得到二维图像,即
优选的,步骤(2)中,生成焦点堆栈图像序列具体为:基于光场数字重聚焦技术,即把光场重新投影积分到新的像平面上,等效于所有子孔径图像的平移和叠加,计算公式如下:
其中,k'、l'分别表示重聚焦图像像素在水平、垂直方向的坐标;ni、nj分别表示微透镜所覆盖子图像在行列方向上的像素数;nk、nl分别表示微透镜阵列在水平、垂直方向上的微透镜个数;interpn()表示常见的插值函数,返回在指定位置的插值,第1个参数是一个二维矩阵,第2参数是插入位置的水平坐标,第3个参数是插入位置的垂直坐标;β是比例因子;当k'∈[1:1:nk],l'∈[1:1:nl]取遍集合中每个整数值时,得到重聚焦图像
优选的,步骤(4)中,检测聚焦曲线的局部对称性时,局部范围是指取一个窗口w,窗口大小w设定为
这里,ρ()是常用距离函数,定义为:
优选的,步骤(5)中,由4d光场数据生成水平方向和垂直方向epi图像的过程可以看作如下映射:
优选的,步骤(6)中,在
(61)在角度区间[1°,179°]上,等步长生成n个元素的角度序列
(62)在
(63)计算步骤(62)所得直线的灰度一致度cp(θm),计算方法是:
其中,|sp(θm)|表示集合sp(θm)的基数,即集合中元素的个数;
(64)对于
采用与(61)~(64)类似的步骤,可以在epi图像
优选的,步骤(7)中,由中心子孔径图像
(71)对于
(72)在中心子孔径图像
(73)计算集合cv中的所有像素的均值,作为聚焦曲线片段上横坐标为视差f时的纵坐标值。
优选的,步骤(8)中,计算
同理,可计算匹配度
优选的,以步骤(8)得到的视差图d为优化的基础,根据聚焦曲线的匹配度建立数据项约束edata(d),以视差连续性为指导增加平滑项约束esmooth(d),由此构建能量函数e(d)=edata(d)+esmooth(d),采用迭代优化技术求解使能量函数取得最小的视差图
优选的,数据项约束的定义为:
平滑项约束的定义为:
其中,n表示中心子孔径图像或视差图上所有相邻位置构成的集合,{p,q}表示一对相邻位置,λ、λ2、σ表示控制因子。
本发明的有益效果为:(1)本发明针对光场图像提出了一种深度估计方法,该方法使聚焦和视差两种方式估计的视差结果相互补充,提高了深度估计的准确性;(2)本发明的聚焦方式深度估计基于光场的数字重聚焦,重聚焦过程是积分过程,降低了噪声对的影响;另外,视差方式深度估计以水平方向和垂直方向的视差估计的均值作为结果,提高了对噪声的鲁棒性;(3)本发明结合中心子孔径图像和视差图生成聚焦曲线片段,并用该片段与聚焦曲线的匹配度作为视差值取舍的依据,提高了深度估计对遮挡的鲁棒性。
附图说明
图1为本发明的方法流程示意图。
图2为本发明中的中心子孔径图像示例示意图。
图3为本发明中的聚焦于鹦鹉的重聚焦图像示例示意图。
图4为本发明中的聚焦于建筑物的重聚焦图像示例示意图。
图5为本发明中的聚焦曲线示例示意图。
图6为本发明中的epi图像示例示意图。
图7为本发明中放大的epi图像示例示意图。
图8为本发明中在epi图像上选择像素的示意图。
图9为本发明与现有方法的深度估计结果对比示例示意图。
具体实施方式
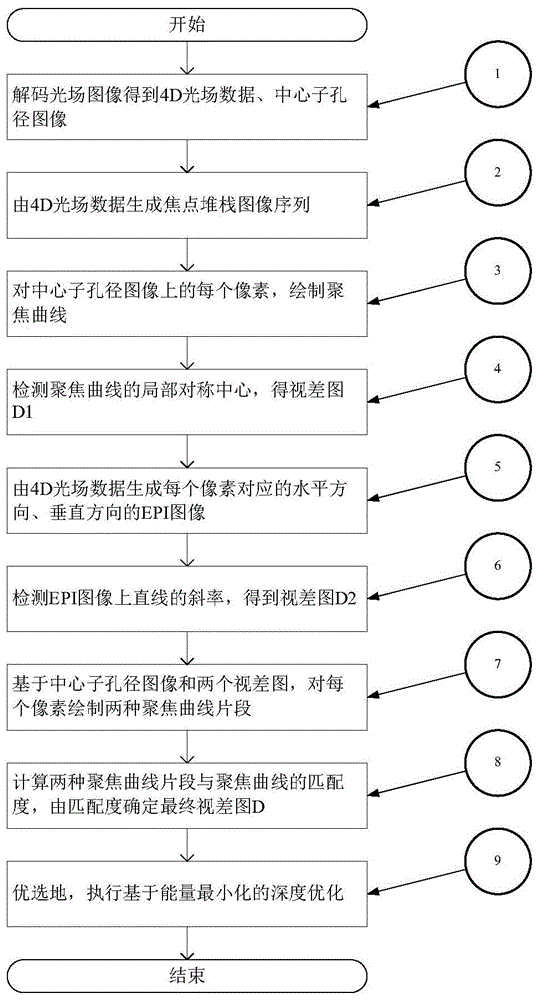
如图1所示,一种面向光场图像的深度估计方法,包括如下步骤:
步骤1,解码光场图像得到4d光场数据、中心子孔径图像。即:根据光场相机参数信息,将光场原始图像解码为4d光场数据,并提取中心子孔径图像
如步骤1所述,光场相机(如lytro等)所采集的原始图像通常是12位bayer格式图像,而在光场分析和处理中通常采用2pp(twoplaneparameterization)形式表示的4d光场,因此,需要根据光场相机提供的参数或进一步标定修正的参数,将原始图像解码为4d光场数据。4d光场通常记为l:(i,j,k,l)→l(i,j,k,l),其中,(i,j)表示微透镜所覆盖子图像的像素索引坐标,(k,l)表示微透镜中心的索引坐标,l(i,j,k,l)表示通过像素和微透镜中心的光线的辐射强度。提取中心子孔径图像的方法是抽取每个微透镜图像的中心像素,按微透镜位置索引排列得到二维图像,即
步骤2,由4d光场数据生成焦点堆栈图像序列。具体地,由步骤1得到的4d光场数据,以视差δd为步长,计算生成焦点堆栈图像序列
步骤2所述的生成焦点堆栈图像序列的方法基于光场数字重聚焦技术,即把光场重新投影积分到新的像平面上,等效于所有子孔径图像的平移和叠加。计算公式如下:
其中,k'、l'分别表示重聚焦图像像素在水平、垂直方向的坐标;ni、nj分别表示微透镜覆盖的子图像(微透镜图像)在行列方向上的像素数;nk、nl分别表示微透镜阵列水平、垂直方向上的微透镜个数;interpn()是常见的插值函数,返回在指定位置的插值,第1个参数是一个二维矩阵,第2参数是插入位置的水平坐标,第3个参数是插入位置的垂直坐标;β是比例因子。
当k'∈[1:1:nk],l'∈[1:1:nl]取遍集合中每个整数值时,得到重聚焦图像
步骤3,对中心子孔径图像上的每个像素,绘制聚焦曲线。具体地,对中心子孔径图像
步骤4,检测聚焦曲线的局部对称中心,得视差图d1。具体地,对中心子孔径图像
步骤4所述的检测聚焦曲线的局部对称性时,局部范围是指取一个窗口w,窗口大小|w|通常设定为
这里,ρ()是常用距离函数,定义为:
步骤5,由4d光场数据生成每个像素对应的水平方向、垂直方向的epi图像。具体地,对中心子孔径图像
步骤5所述的由4d光场数据生成水平方向和垂直方向epi图像的过程可以看作如下映射:
步骤6,检测epi图像上直线的斜率,得到视差图d2。具体地,对中心子孔径图像
步骤6所述的在
(601)在角度区间[1°,179°]上,等步长生成n个元素的角度序列
(602)在
(603)计算步骤(602)所得直线的灰度一致度cp(θm),计算方法是:
其中,|sp(θm)|表示集合sp(θm)的基数,即集合中元素的个数。
(604)对于
采用与(601)~(604)类似的步骤,可以在epi图像
如图7是一幅epi图像的放大示意图,每个格子表示一个像素;图8给出在epi图像上选择像素集合的示例,根据假定斜率的直线所通过的像素,选择像素集合。
步骤7,基于中心子孔径图像和两个视差图,对每个像素绘制两种聚焦曲线片段。具体地,对中心子孔径图像
步骤7所述的由中心子孔径图像
(701)对于
(702)在中心子孔径图像
(703)计算集合cv中的所有像素的均值,作为聚焦曲线片段上横坐标为视差f时的纵坐标值。
由中心子孔径图像
步骤8,计算两种聚焦曲线片段与聚焦曲线的匹配度,由匹配度确定最终视差图d。具体地,对中心子孔径图像
步骤8所述的计算
同理,可计算匹配度
在上述的基于光场图像的深度估计方法中,优选地,进一步还包括对以上步骤得到的结果进行优化的步骤9。
步骤9,优选地,执行基于能量最小化的深度优化。具体地,以步骤8得到的视差图d为优化的基础,根据聚焦曲线的匹配度建立数据项约束edata(d),以视差连续性为指导增加平滑项约束esmooth(d),由此构建能量函数e(d)=edata(d)+esmooth(d),采用迭代优化技术求解使能量函数取得最小的视差图
步骤9所述的数据项约束的定义为:
平滑项约束的定义为:
其中,n表示中心子孔径图像或视差图上所有相邻位置构成的集合,{p,q}表示一对相邻位置,λ、λ2、σ表示控制因子。
本实施例中,采用图割法优化该能量函数,得到优化的视差图。
本实施例中两种典型的光场图像深度估计方法与本发明进行对比分析,一种是tao方法:tao于2013年提出,发表于cvpr;一种是jeon方法:jeon于2015年提出,发表于cvpr。
本实施例使用mousnier等提供的lytro光场数据集测试发明对真实场景光场数据的性能。该数据集包括30组lytro摄像数据,其中,25组是各地的室内外场景,3组包含运动模糊,1组包含长时间曝光,1组平面摄影。图9给出了其中5组典型场景的深度估计结果,第一列是场景的中心子孔径图像,第二至四列分别是本发明的结果、tao方法的结果、jeon方法的结果;上面两行展示两组室内场景、中间一行是局部细节场景、下面两行是典型室外场景。
从本实施例的分析可以明显看出,本发明不论对室外噪声场景还是对复杂遮挡的细节场景,均能较好估计深度信息。
- 还没有人留言评论。精彩留言会获得点赞!