一种基于文本纠错与神经网络的中文问句分类方法与流程
本发明属于智能信息处理和计算机技术领域,尤其涉及一种中文问句分类方法。
背景技术:
随着互联网时代科技迅速发展,大量数据涌入,通过搜索引擎搜索关键字词需要对返回的结果进行手动筛选,对用户来说耗时耗力。而通过问答系统能迅速的获取用户的意图,可以在成百上千的候选答案中返回给用户最准确的答案。
中文问句分类是问答系统的首要步骤,并且是问答系统实现精准回答的关键技术之一,通过对中文问句的分类,问答系统能够有效缩小答案的范围并且决定问句处理的方式,使得问答系统的答案更加准确可靠。
目前对于中文问句分类方法的研究,主要有三种:一种是基于规则匹配、特征提取的方法,另一种是基于传统机器学习的方法,最后一种是基于深度学习的方法。其中,基于规则匹配、特征提取的方法针对不同中文问句的特征定义一套规则,通过分析中文问句与规则的匹配程度来实现对中文问句的分类,这种方法对于某一特定领域具有较好的准确度,但不同领域的中文问句千变万化,很难对于不同领域的中文问句提出一套通用的规则,因此,利用规则匹配,特征提取的方法具有很大的局限性。而基于机器学习的中文问句分类方法有许多种,常用的有包括朴素贝叶斯分类,支持向量机分类等等,但仍然需要主动提取特征,对于中文问句分类仍然具有一定的主观性。基于深度学习的中文问句分类方法也有许多种包括基于卷积神经网络分类、基于长短期记忆分类、基于双向门控循环单元分类等等,基于深度学习方法的中文问句分类相较于基于规则匹配、特征提取方法以及传统机器学习方法,准确率有了较大的提升。目前的研究与应用证明基于循环神经网络如长短期记忆、双向门控循环单元等更能够学习中文问句的上下语义信息,而基于卷积神经网络更能够学习句子中的局部特征,提取句子中的关键信息,但中文问句的分类种类繁多,单一分类方法的分类效果在实践中仍然不能完全满足要求,并且目前的研究很少有能充分利用循环神经网络与卷积神经网络的优势。
此外,目前大多数利用深度学习神经网络进行中文问句分类的方法,几乎没有考虑输入问句存在语病、多字、别字等情况,都一并作为模型的输入进行预测或训练,这样会导致训练的模型针对类似问句存在较大的偏差,导致预测错误。
技术实现要素:
本发明的目的是针对上述现有技术的不足,提供一种基于文本纠错与神经网络的中文问句分类方法,能够对中文问句进行比较准确的多标签分类。
本发明的目的可以通过如下技术方案实现:
一种基于文本纠错与神经网络的中文问句分类方法,所述方法包括以下步骤:
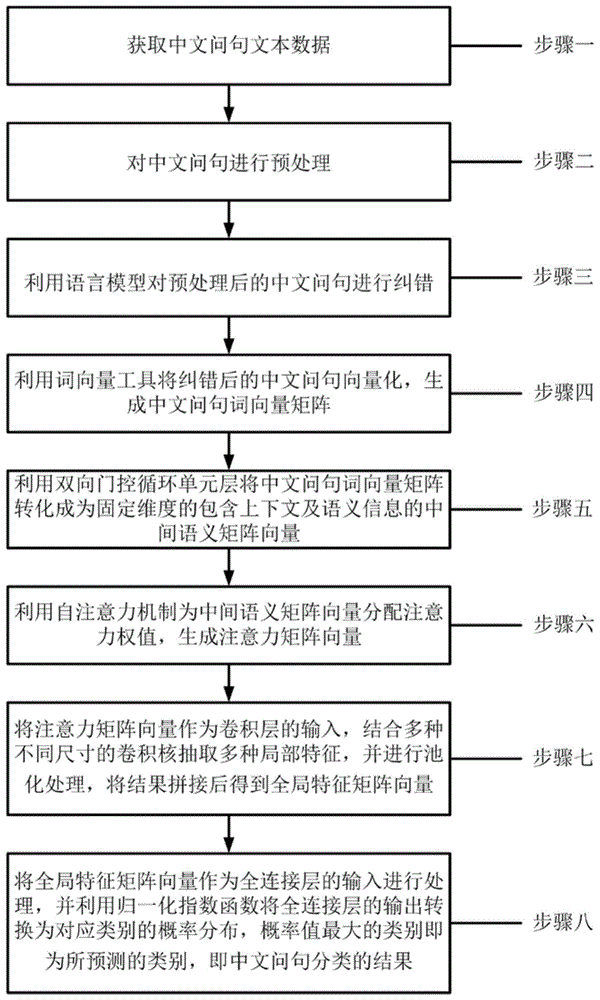
步骤一:获取中文问句文本数据;
步骤二:对中文问句进行预处理;
步骤三:利用语言模型对预处理后的中文问句进行纠错;
步骤四:利用词向量工具将纠错后的中文问句向量化,生成中文问句词向量矩阵;
步骤五:利用双向门控循环单元层将中文问句词向量矩阵转化成为固定维度的包含上下文及语义信息的中间语义矩阵向量;
步骤六:利用自注意力机制为中间语义矩阵向量分配注意力权值,生成注意力矩阵向量;
步骤七:将注意力矩阵向量作为卷积层的输入,结合多种不同尺寸的卷积核抽取多种局部特征,并进行池化处理,将结果拼接后得到全局特征矩阵向量;
步骤八:将全局特征矩阵向量作为全连接层的输入进行处理,并利用归一化指数函数将全连接层的输出转换为对应类别的概率分布,概率值最大的类别即为所预测的类别,即中文问句分类的结果。
本发明有益效果如下:
本发明方法对中文问句分类的研究有重要作用。本发明采用了基于文本纠错以及神经网络的方法针对中文问句分类进行了研究。
相比较于其他中文问句分类方法,本发明将输入的问句在利用中文问句分类模型分类前进行文本纠错,在一定程度上解决因输入中文问句错误而导致的中文问句分类错误。
在纠错之后,本发明将正确的中文问句通过双向门控循环单元层,将中文问句词向量矩阵转为包含上下文语义信息的中间语义矩阵向量,并利用自注意力机制有效加强中文问句中的关键词语的作用,接着利用卷积神经网络以及池化操作抽取注意力矩阵向量的局部特征,最后通过全连接层以及归一化指数函数输出中文问句分类结果。通过结合双向门控循环单元网络模型、自注意力模型以及卷积神经网络模型,能够充分发挥不同模型的优势,从而使分类更加准确。
上述说明仅仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更加明显易懂,以下特举本发明的具体实施方式。
说明书附图
图1是本发明实施例的一种基于文本纠错与神经网络的中文问句分类方法的流程图。
图2是本发明实施例的中文问句分类模型结构图。
具体实施方式
下面将结合附图和实施例对本发明做进一步阐述和说明,但本发明的实施方式不限于此。
实施例:
本实施例提供了一种基于文本纠错以及神经网络的中文问句分类方法,所述方法包括以下步骤:
步骤一:获取中文问句文本数据;
步骤二:对中文问句进行预处理;
步骤三:利用语言模型对预处理后的中文问句进行纠错;
步骤四:利用词向量工具将纠错后的中文问句向量化,生成中文问句词向量矩阵;
步骤五:利用双向门控循环单元层将中文问句词向量矩阵转化成为固定维度的包含上下文及语义信息的中间语义矩阵向量;
步骤六:利用自注意力机制为中间语义矩阵向量分配注意力权值,生成注意力矩阵向量;
步骤七:将注意力矩阵向量作为卷积层的输入,结合多种不同尺寸的卷积核抽取多种局部特征,并进行池化处理,将结果拼接后得到全局特征矩阵向量;
步骤八:将全局特征矩阵向量作为全连接层的输入进行处理,并利用归一化指数函数将全连接层的输出转换为对应类别的概率分布,概率值最大的类别即为所预测的类别,即中文问句分类的结果。
所述步骤一获取中文问句文本数据可以是用户在搜索引擎中输入的搜索问句也可以是在问答系统中输入的问句,或者是用户直接输入的文本类型的中文问句,此处不作限制。
所述步骤二对中文问句进行预处理,其具体步骤为:
2.1)去除中文问句中的特殊字符以及符号标点,仅保留文字;
2.2)对步骤2.1)得到的结果进行分词处理。
所述步骤2.2)具体为根据领域词典,使用分词程序对输入的问句进行分词,得到分词结果序列w1,w2,…,wn-1,wn,其中n为该中文问句中词语的数量,wi为中文问句中的一个词语,每一个wi都是所述领域词典中的词语。
所述步骤三利用语言模型对中文问句文本数据进行纠错:
其中,语言模型,可以是n元语言模型,最大熵模型,神经网络模型等等。
可以理解的是,利用语言模型,可以对输入中文问句中的错误进行一定程度上的修正。
所述步骤四利用词向量工具并利用预先训练的词向量模型将纠错后的中文问句向量化,得到一个二维矩阵向量,即中文问句的词向量矩阵s1,s2,…,sn-1,sn。其中,si∈rd,si是中文问句中每一个词的词向量,d是词向量的维度大小,n是该中文问句的长度,整个中文问句矩阵向量的维度大小为d×n,词向量工具为谷歌词向量工具,。
所述步骤五中利用双向门控循环单元层将中文问句词向量矩阵转化为成为指定维度的中间语义矩阵向量,其具体步骤为:
5.1)将中文问句的词向量序列s1,s2,…,sn-1,sn作为双向门控循环单元层的输入。其中,双向门控循环单元层由多个门控循环单元组成,每一个词的词向量都对应着一个门控循环单元,门控循环单元层按照中文问句中词语的顺序依次输入单个词向量。对于中文问句的输入序列特征表达都采用有向门控循环单元,即包括正向门控循环单元与反向门控循环单元,反向门控循环单元与正向门控循环单元的网络结构相同,只是输入序列的顺序相反。因此,输入的中文问句词向量矩阵将同时输入进正向门控循环单元与反向门控循环单元,即双向门控循环单元;
5.2)每个门控循环单元都会输出指定维度的向量值,将每一个门控循环单元的输出进行拼接生成包含上下语义信息的中间语义矩阵向量h1,h2,…,hn-1,hn,其中hi∈rk,k是指定的维度大小。
所述步骤5.2)每一个门控循环单元输出指定维度的向量值的过程为:
5.2.1)门控循环单元涉及到4部分的计算,令rt,zt,
5.2.2)计算重置向量rt,其公式为:
rt=σ(wrst+urht-1+br)
其中,wr以及ur两个变量是权值参数,ht-1是上一个时刻门控循环单元的输出,st为当前时刻输入的词向量,br是偏置参数,σ为激活函数;
5.2.3)计算更新向量zt,其公式为:
zt=σ(wzst+uzht-1+bz)
其中,wz以及uz两个变量是权值参数,ht-1是上一时刻门控循环单元的输出,st为当前时刻输入的词向量,bz是偏置参数,σ为激活函数;
5.2.4)计算候选记忆单元
其中,w以及u两个变量是权值参数,b是偏置参数,ht-1是上一时刻门控循环单元的输出,st为当前时刻输入的词向量,rt为步骤5.2.2)所计算的重置向量,tanh为正切函数;
5.2.5)计算当前时刻输出ht,其公式为:
其中,ht-1是是上一时刻门控循环单元的输出,zt是步骤5.2.3)计算的更新向量,
所述步骤六中利用自注意力机制为中间语义矩阵向量分配注意力权值的具体步骤为:
6.1)计算注意力值aij,其公式为:
aij=softmax(wa2tanh(wa1ht))
其中,wa2与wa1为权值参数,ht为当前时刻门控循环单元的输出;
6.2)计算当前时刻注意力向量ct,其公式为:
其中,ct为当前时刻自注意力机制的输出,th是时序总长度,t是当前时刻,aij是当前时刻的注意力权值大小;
6.3)将不同时刻的注意力向量进行拼接,得到注意力矩阵向量c1,c2,…,
所述步骤七中利用卷积神经网络作为可训练的特征提取网络从指定维数k,指定时序长度th的注意力中间语义向量提取多个特征,其具体步骤为:
7.1)将注意力矩阵向量c1,c2,…,
7.2)卷积神经网络层使用不同长度的卷积核进行计算;
7.3)对卷积结果进行最大池化抽取局部特征;
7.4)对多个池化后的结果进行拼接,得到全局特征向量作为卷积神经网络层的输出。
所述步骤7.1)注意力矩阵向量c1,c2,…,
所述步骤7.2)使用不同卷积核提取输入特征,其具体步骤为:
7.2.1)设置有n种不同卷积核尺寸,n≥2,其中卷积核长度不变,为注意力向量的维数k,而宽度m可以变化,1≤m≤th;
7.2.2)不同卷积核同时对输入进行卷积计算,卷积核的计算公式为:
ti=f(wci:i+m-1+b)
其中w是权值信息,m是卷积核的宽度,b是偏置参数,ci:i+m-1是多个时刻注意力向量的拼接,其公式为:
其中ci为时刻i的注意力向量;
所述步骤7.3)对卷积结果进行最大池化抽取局部特征,其公式为:
其中,max为求出ti中的最大值;
所述步骤7.4)对多个池化后的结果进行拼接,得到全局特征向量作为卷积神经网络层的输出,其公式为:
其中n为不同卷积核的数量,t为卷积神经网络层的输出。
所述步骤八通过全连接层以及归一化指数函数计算中文问句分类结果,其具体步骤为:
8.1)将步骤7.4)计算得到的全局特征向量作为全连接层的输入,计算全连接层的输出向量;
8.2)计算归一化指数函数得到模型的所有类别的概率分布;
8.3)取输出最大值的所在索引作为该中文问句的类别。
所述步骤8.1)计算全连接层的输出向量,其公式为:
f=σ(wft+bf)
其中,wf是权值参数,bf是偏置参数,σ为激活函数,t为步骤七得到的全局特征向量。
所述步骤8.2)计算归一化指数函数得到模型的输出,其公式为:
其中,fj为全连接层输出向量的第j维,oi为第i种分类结果的概率。
本领域技术人员应该理解,本领域技术人员结合现有技术以及上述实施例可以实现所述变化例,在此不予赘述。这样的变化例并不影响本发明的实质内容,在此不予赘述。
以上对本发明的较佳实施例进行了描述。需要理解的是,本发明还可有其他多种实施,在不背离本发明精神及其实质的情况下,本领域技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!