一种基于传递依存关系和结构助词的关系抽取方法及装置与流程
本发明涉及命名实体识别、依存句法分析、文本复述及关系抽取领域,具体地说是一种基于传递依存关系和结构助词的关系抽取方法及装置。
背景技术:
关系是描述实体对之间语义联系的三元组,其形式是(a,ɑ,b),其中a、b是实体,ɑ是实体间的语义联系。关系大量存在于自然文本中,例如:句子“a城市是m国的首都”中包含关系(a城市,首都,m国),句子“x国总统b来到m国”中包含关系(x国,总统,b)和(b,来到,m国)。关系抽取是信息抽取领域的重要研究内容,可以建立不同实体间的依赖类型,将非结构化文本转化为结构化或半结构化知识,形成由知识构成的关系网络,用于智能问答、语义搜索、社团发现等智能型服务。
目前,随着“大数据”和“互联网+”的高速发展,不同领域的信息数据呈井喷式增长,关系抽取可以永不停息地理解和筛选信息,源源不断地生成并完善适用的领域知识,突破传统人工阅读、理解、整理等信息加工方式的时空局限性,构建远超人类自身极限的智能设备、工具和体系,引领人工智能发展的前沿,是未来智慧生活的技术保障。
目前,常用的关系抽取方法包括下述三种:
(1)、规则模板法:通过分析句式特点,设计若干模板(正则表达式),使用模板在文本中匹配出关系三元组。这种方法需要构建庞大的模板库,早期由专家手工写出模板,人力耗费极大;近年来开始采用自动化方式生成模板,最常用的是bootstrapping算法,根据最初几个实例从文本中提取种子模板,然后将进一步应用于文本,获得新的实例,重复上述过程,获得更多的模板。bootstrapping算法的基础是多次重复抽样,如果初始实例质量不佳,提取出的种子模板适用面窄,在后继迭代(重复抽样)中容易陷入局部收敛,缺乏扩展性和普适性;此外,在模板扩增的过程中,会产生适用面窄、不正确或彼此冲突(对于同一句话的相同实体,得到彼此矛盾的关系)的新模板,影响关系抽取的准确性。
(2)、依存分析法:对文本进行句法或语法分析,根据关系三元组各个元素在句中的依存关系(如主谓、动宾、动补、定中、介宾等),确定对应的抽取规范。该方法与规则模板法类似,但处理对象是文本的句法或语法分析结果,要综合多条规则进行抽取,而不是使用模板直接匹配。本方法在句法或语法层进行处理,抽取结果能够更准确揭示实体间的语义联系。但是,依存关系种类有限,导致可用的抽取规则数量不多;此外,不同树库(或相同树库的不同版本)的依存关系定义和符号均有差异,更换树库类型或版本后,原有的关系抽取规则会失去效果;上述问题,影响本方法的普适性。
(3)、机器学习法:该方法把关系抽取任务当作分类训练问题。首先,对句子进行词法和句法分析,得到每个实体的平面特征和句法特征;然后,综合平面特征和句法特征,以及语义角色标注特征,生成完整的关系特征;最后,根据关系特征和已标注的特征标签,采用合适的方法(lr、svm、crf等)进行训练,从而得到不同关系的生成模型。按照语料标注的方式,本方法分为有监督学习方法、半监督学习方法、远程监督学习方法。其中,有监督学习方法需要人工标注大量训练语料,非常耗时耗力,而且适用面窄;半监督学习方法根据少量人工标注语料,为其它无标注样本打标签,标注准确性不易保证;远程监督学习方法将知识库中的实体关系映射到未标注文本中,自动构建大量训练数据,但关系存在多义性,实体在知识库和未标注文本中的关系未必相同,容易引入噪声数据。由此可知,使用本方法进行关系抽取,在特征选择、语料标注、样本训练等方面都存在技术挑战。
综上所述,如何处理当前关系抽取中存在的抽取模板和规则依赖树库的依存关系定义和符号存在差异且通用性差、机器学习特征选择困难、人工标注训练语料成本高、自动化标注训练语料准确性低的缺点,从而提高关系抽取的效果是目前现有技术中急需解决的技术问题。
专利号为cn109241538a的专利文献公开了一种基于关键词和动词依存的中文实体关系抽取方法,以大规模非结构化自由文本为目标文本,首先对文本进行分词、抽取关键词,形成文本关键词词库;然后对文本进行分句、分词、词性标注、命名实体识别、依存句法分析处理,结合命名实体词库和关键词词库构建实体语料库;根据中文句子构成特点、句法结构以及词语间的依存关系从动词出发构建实体关系句法规则,再对文本中每个句子进行关系句法规则的匹配;最后输出关系三元组,得到文本关系三元组集合。但是该技术方案不能克服当前关系抽取中存在的抽取模板和规则依赖树库的依存关系定义和符号存在差异且通用性差、人工标注训练语料成本高、自动化标注训练语料准确性低的缺点。
专利号为cn107291687a专利文献公开了一种基于依存语义的中文无监督开放式实体关系抽取方法,该方法包括以下步骤:预处理输入文本:对输入文本进行中文分词、词性标注和依存句法分析;对输入文本进行命名实体识别;从识别出的实体中任意选出两个实体构成候选实体对;寻找候选实体对中的两个实体之间的依存路径;分析依存路径所映射的句法结构是否与依存语义范式集的范式匹配,若是,则根据被匹配的范式从输入文本的剩余部分中抽取出词或短语作为关系词,抽取的关系词与候选实体对构成关系三元组,若否则进行下一组候选实体对的范式匹配;输出关系三元组。但是该技术方案不能克服当前关系抽取中存在的抽取模板和规则依赖树库的依存关系定义和符号存在差异且通用性差、人工标注训练语料成本高、自动化标注训练语料准确性低的缺点。
技术实现要素:
本发明的技术任务是提供一种基于传递依存关系和结构助词的关系抽取方法及装置,来解决如何处理当前关系抽取中存在的抽取模板和规则依赖树库的依存关系定义和符号存在差异且通用性差、机器学习特征选择困难、人工标注训练语料成本高、自动化标注训练语料准确性低的缺点,从而提高关系抽取的效果的问题。
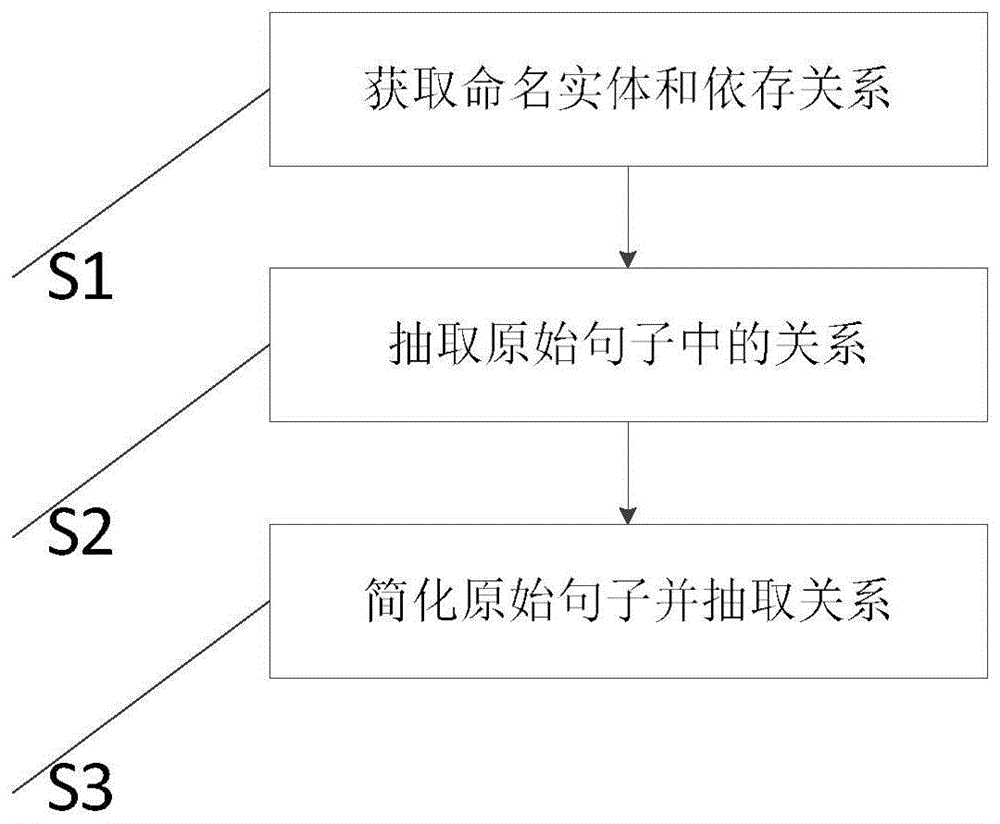
本发明的技术任务是按以下方式实现的,基于传递依存关系和结构助词的关系抽取方法,包括如下步骤:
s1、获取命名实体和依存关系:使用自然语言处理软件处理句子,获取命名实体和不同成分间的依存关系;
s2、抽取原始句子中的关系:根据实体之间的传递依存关系抽取关系三元组;若实体ai以及实体aj均和词汇ɑ存在依存关系,则实体ai和实体aj存在传递依存关系,便可抽取出关系三元组(ai,ɑ,aj);
s3、简化原始句子并抽取关系:根据步骤s2中已经生成的关系三元组(ai,ɑ,aj)调整并简化原始句子,并借助结构助词来抽取除关系三元组(ai,ɑ,aj)以外的关系三元组。
作为优选,所述步骤s1中获取命名实体和依存关系的具体步骤如下:
s101、读取待处理句子;
s102、对待处理句子进行分词;
s103、标注分词词汇的词性;
s104、识别出命名实体a1、a2、…、an;
s105、对句子进行依存句法分析;
s106、返回命名实体和依存关系。
作为优选,所述步骤s2中抽取原始句子中的关系的具体步骤如下:
s201、初始化i=1,j=2;
s202、读取实体ai和实体aj;
s203、判断实体ai及实体aj是否均和词汇ɑ存在依存关系:
①、若是,则下一步执行步骤s204;
②、若否,则跳转至步骤s205;
s204、抽取关系三元组(ai,ɑ,aj);
s205、j=j+1;
s206、判断j是否大于n:
①、若j>n,则跳转至步骤s208;
②、若j≤n,则下一步执行步骤s207;
s207、读取实体aj,下一步跳转至步骤s203;
s208、i=i+1,j=i+1;
s209、判断i是否大于等于n:
①、若i≥n,则下一步执行步骤s210;
②、若i<n,则跳转至步骤s202;
s210、返回所抽取的关系三元组。
作为优选,所述步骤s3中简化原始句子并抽取关系的具体步骤如下:
s301、读取原始句子到sent;
s302、判断所有实体是否均已经和除自身以外的其他实体建立关系:
①、若是,则跳转至步骤s312;
②、若否,则下一步执行步骤s303;
s303、将句子sent简化为simplesent;
s304、初始化简化后抽取的关系个数simplecount=0;
s305、获取simplesent中的命名实体和依存关系;
s306、根据传递依存关系获取simplesent中的新关系;
s307、判断所有实体是否均已经和除自身以外的其他实体建立关系:
①、若是,则跳转至步骤s312;
②、若否,则下一步执行步骤s308;
s308、通过添加结构助词获取simplesent中的新关系;
s309、判断所有实体是否均已经和除自身以外的其他实体建立关系:
①、若是,则跳转至步骤s312;
②、若否,则下一步执行步骤s310;
s310、判断simplecount是否为0:
①、若simplecount=0,则跳转至步骤s312;
②、若simplecount≠0,则下一步执行步骤s311;
s311、设置sent=simplesent;
s312、返回抽取的所有关系三元组。
更优地,所述步骤s303中将句子sent简化为simplesent的具体步骤如下:
s30301、初始化simplesent=sent;
s30302、读取第一个关系三元组(ai,ɑ,aj);
s30303、构造简化子句simplesubsent=ai+ɑ+aj;其中,+表示字符串连接操作;
s30304、将simplesent中包含ai、ɑ和aj的最小子句,替换为simplesubsent;
s30305、判断关系三元组是否读取完毕:
①、若是,则跳转至步骤s30307;
②、若否,则下一步执行步骤s30306;
s30306、读取下一个关系三元组(ai,ɑ,aj),下一步跳转至步骤s30303;
s30307、返回simplesent;
所述步骤s306中根据传递依存关系获取simplesent中的新关系的具体步骤如下:
s30601:读取第一个孤立实体a;
s30602:判断是否存在和词汇ɑ均具有依存关系的实体b和孤立实体a:
①、若存在,则下一步执行步骤s30603;
②、若不存在,则跳转至步骤s30604;
s30603、抽取关系三元组(a,ɑ,b);
s30604、判断孤立实体是否读取完毕:
①、若是,则跳转至步骤s30606;
②、若否,则下一步执行步骤s30605;
s30605、读取下一个孤立实体a,则跳转至步骤s30602;
s30606、返回所抽取的关系三元组。
更优地,所述步骤s308中通过添加结构助词获取simplesent中的新关系的具体步骤如下:
s30801、读取第一个孤立实体a;其中,孤立实体是指没有和其它任何实体建立关系的实体;
s30802、在孤立实体a的前面寻找关系三元组,具体步骤如下:
s3080201、在simplesent中,找到孤立实体a前面的第一个实体apre;
s3080202、在实体apre和孤立实体a之间词汇的空隙,添加结构助词,得到句子preauxsimplesent;
s3080203、对preauxsimplesent进行依存句法分析;
s3080204、判断实体apre和孤立实体a是否均与词汇β产生依存关系:
①、若是,则下一步执行步骤s3080205;
②、若否,则跳转至步骤s3080207;
s3080205、抽取关系三元组(apre,β,a);
s3080206、simplecount=simplecount+1;
s3080207、返回simplecount;
s30803、在孤立实体a的后面寻找关系三元组,具体步骤如下:
s3080301、在simplesent中,找到孤立实体a后面的第一个实体aaft;
s3080302、在孤立实体a和实体aaft之间词汇的空隙,添加结构助词,得到句子aftauxsimplesent;
s3080303、对aftauxsimplesent进行依存句法分析;
s3080304、判断孤立实体a和实体aaft是否均与词汇β产生依存关系:
①、若是,则下一步执行步骤s3080305;
②、若否,则跳转至步骤s3080307;
s3080305、抽取关系三元组(a,β,aaft);
s3080306、simplecount=simplecount+1;
s3080307、返回simplecount;
s30804、判断孤立实体是否读取完毕:
①、若是,则跳转至步骤s30806;
②、若否,则下一步执行步骤s30805;
s30805、读取下一个孤立实体a,下一步跳转至步骤s30802;
s30806、返回simplecount。
一种基于传递依存关系和结构助词的关系抽取装置,该装置包括,
命名实体和依存关系获取单元,用于获取句子中的命名实体和依存关系;
原始句子关系三元组抽取单元,用于直接获取原始句子中存在的语义三元组;
原始句子简化和关系三元组抽取单元,用于根据已生成的关系三元组调整并简化原始句子,并结合结构助词抽取除已生成关系三元组以外的关系三元组。
作为优选,所述命名实体和依存关系获取单元包括,
句子读取子单元,用于读取待处理句子;
分词子单元,用于将待处理句子分隔为若干词汇;
词性标注子单元,用于标注待处理句子中各个词汇的词性;
命名实体识别子单元,用于获取待处理句子中的命名实体;
依存句法分析子单元,用于获取待处理句子中词汇间的语义关系。
作为优选,所述原始句子关系三元组抽取单元包括,
实体对读取子单元,用于读取原始句子中的任意两个实体;
传递依存关系检测子单元,用于检测是否存在和两个实体具有依存关系的词汇;
关系三元组构建子单元,用于根据两个实体以及与两个实体存在依存关系的词汇构建出关系三元组。
作为优选,所述原始句子简化和关系三元组抽取单元包括,
孤立实体检测子单元,用于检测是否存在尚未和除自身以外的实体建立关系的实体;
句子简化子单元,用于根据关系三元组简化句子;句子简化子单元包括,
关系三元组读取模块,用于读取关系三元组;
简化子句构造模块,用于根据关系三元组生成简化后长度最短的子句;
最小子句替换模块,用于使用简化子句替换原句中包含关系三元组的最小子句;
命名实体识别子单元,用于获取待处理句子中的命名实体;
依存句法分析子单元,用于获取待处理句子中词汇间的语义关系;
孤立实体关系直接匹配子单元,用于根据传递依存关系,在简化后的句子中直接获取孤立实体和除自身以外的实体的关系;孤立实体关系直接匹配子单元包括,
直接孤立实体读取模块,用于读取孤立实体;
孤立实体传递依存关系检测模块,用于检测是否存在和孤立实体具有传递依存关系的其它实体;
孤立实体关系三元组构建模块,用于根据孤立实体和其它实体间的传递依存关系构建出关系三元组;
孤立实体关系间接匹配子单元,用于在简化后的句子中添加结构助词,并根据传递依存关系获取孤立实体和除自身以外的实体的关系;孤立实体关系间接匹配子单元包括,
间接孤立实体读取模块,用于读取孤立实体;
孤立实体前向匹配模块,用于在孤立实体的前面添加结构助词,并根据传递依存关系获取孤立实体和除自身以外的实体的关系;
孤立实体后向匹配模块,用于在孤立实体的后面添加结构助词,并根据传递依存关系获取孤立实体和除自身以外的实体的关系。
本发明的基于传递依存关系和结构助词的关系抽取方法及装置具有以下优点:
(一)、本发明解决当前关系抽取中存在的抽取模板和规则依赖树库的依存关系定义和符号存在差异且通用性差、机器学习特征选择困难、人工标注训练语料成本高、自动化标注训练语料准确性低等问题,从而提高关系抽取的效果;
(二)、本发明的理论基础是实体之间存在传递依存关系,因此可以得到描述两个实体之间语义关系的三元组,操作简单且速度很快,所得关系具有较高的语义正确性;
(三)、本发明抽取关系三元组时不需要借助模板和规则,解决了由于树库依存关系定义和符号差异所带来的应用受限问题;如果实体间的传递依存关系隐藏未现,通过借助已生成关系三元组简化句子以及在实体间添加结构助词,可以挖掘出隐藏的传递依存关系,从而解决实体无法关联的问题。
附图说明
下面结合附图对本发明进一步说明。
附图1为本发明的基于传递依存关系和结构助词的关系抽取方法的流程框图;
附图2为步骤s1获取命名实体和依存关系的流程框图;
附图3为示例句子在ltp平台上的处理结果的示意图;
附图4为步骤s2抽取原始句子中的关系的流程框图;
附图5为步骤s3简化原始句子并抽取关系的流程框图;
附图6为步骤s303将句子sent简化为simplesent的流程框图;
附图7为简化后句子在ltp平台上的处理结果的示意图;
附图8为步骤s306根据传递依存关系获取simplesent中的新关系的流程框图;
附图9为步骤s308通过添加结构助词获取simplesent中的新关系的流程框图;
附图10为步骤s30802在孤立实体a的前面寻找关系三元组的流程框图;
附图11为步骤s30803在孤立实体a的后面寻找关系三元组的流程框图;
附图12为添加结构助词句子在ltp平台上的处理结果的示意图;
附图13为本发明的基于传递依存关系和结构助词的关系抽取装置的结构框图;
附图14为命名实体和依存关系获取单元m1的结构框图;
附图15为原始句子关系三元组抽取单元m2的结构框图;
附图16为原始句子简化和关系三元组抽取单元m3的结构框图;
附图17为句子简化子单元m302的结构框图;
附图18为孤立实体关系直接匹配子单元m305的结构框图;
附图19为孤立实体关系间接匹配子单元m306的结构框图。
具体实施方式
参照说明书附图和具体实施例对本发明的基于传递依存关系和结构助词的关系抽取方法及装置作以下详细地说明。
实施例1:
如附图1所示,本发明的基于传递依存关系和结构助词的关系抽取方法,包括如下步骤:
s1、获取命名实体和依存关系:使用自然语言处理软件处理句子,获取命名实体和不同成分间的依存关系;如附图2所示,具体步骤如下:
s101、读取待处理句子;
s102、对待处理句子进行分词;
s103、标注分词词汇的词性;
s104、识别出命名实体a1、a2、…、an;
s105、对句子进行依存句法分析;
s106、返回命名实体和依存关系。
举例:以句子“x国第一任h人种总统b来到历史悠久的g国,和g国现任c总理讨论某某问题。”为例,上述流程的执行情况如下:
c101:读取句子;
c102:得到分词词汇,分别是:x国第一任h人种总统b来到历史悠久的g国,和g国现任c总理讨论某某问题。;
c103:得到每个分词词汇的词性,分别是:ns、m、q、n、n、nh、v、n、a、u、ns、wp、p、ns、b、nh、n、v、v、n、wp;
c104:获取命名实体,分别是:x国、b、g国、g国、c;
c105:获取依存关系,分别是:att(x国总统)att(第一任)att(任总统)att(h人种总统)att(总统b)sbv(b来到)hed(来到root)sbv(历史悠久)att(悠久g国)rad(的悠久)vob(g国来到)wp(,来到)adv(和讨论)att(g国c)att(现任c)att(c总理)pob(总理和)coo(讨论来到)att(某某问题)vob(问题讨论)wp(。来到),在每个关系对r(ab)中,r是关系名称,b、a分别是关系弧的起点和终点;
c106:结束并返回命名实体和依存关系。
在哈工大的自然语言处理平台ltp中进行处理,得到如附图3所示的结果。不同分词词汇采用空格隔开;在分词词汇的下方标记词性,并采用不同颜色的矩形框标记命名实体类型(如果存在的话);在分词词汇的上方采用有向弧标记依存关系,并在有向弧上标记出依存关系的名称。
s2、抽取原始句子中的关系:根据实体之间的传递依存关系抽取关系三元组;若实体ai以及实体aj均和词汇ɑ存在依存关系,则实体ai和实体aj存在传递依存关系,便可抽取出关系三元组(ai,ɑ,aj);如附图4所示,具体步骤如下:
s201、初始化i=1,j=2;
s202、读取实体ai和实体aj;
s203、判断实体ai及实体aj是否均和词汇ɑ存在依存关系:
①、若是,则下一步执行步骤s204;
②、若否,则跳转至步骤s205;
s204、抽取关系三元组(ai,ɑ,aj);
s205、j=j+1;
s206、判断j是否大于n:
①、若j>n,则跳转至步骤s208;
②、若j≤n,则下一步执行步骤s207;
s207、读取实体aj,下一步跳转至步骤s203;
s208、i=i+1,j=i+1;
s209、判断i是否大于等于n:
①、若i≥n,则下一步执行步骤s210;
②、若i<n,则跳转至步骤s202;
s210、返回所抽取的关系三元组。
举例:按照上述方法处理附图3所示依存关系,结果如下:
c201:根据att(x国总统)和att(总统b),得到关系三元组(x国,总统,b);
c202:根据sbv(b来到)和vob(g国来到),得到关系三元组(b,来到,g国)。
s3、简化原始句子并抽取关系:根据步骤s2中已经生成的关系三元组(ai,ɑ,aj)调整并简化原始句子,并借助结构助词来抽取除关系三元组(ai,ɑ,aj)以外的关系三元组;如附图5所示,具体步骤如下:
s301、读取原始句子到sent;
s302、判断所有实体是否均已经和除自身以外的其他实体建立关系:
①、若是,则跳转至步骤s312;
②、若否,则下一步执行步骤s303;
s303、将句子sent简化为simplesent,如附图6所示,具体步骤如下:
s30301、初始化simplesent=sent;
s30302、读取第一个关系三元组(ai,ɑ,aj);
s30303、构造简化子句simplesubsent=ai+ɑ+aj;其中,+表示字符串连接操作;
s30304、将simplesent中包含ai、ɑ和aj的最小子句,替换为simplesubsent;
s30305、判断关系三元组是否读取完毕:
①、若是,则跳转至步骤s30307;
②、若否,则下一步执行步骤s30306;
s30306、读取下一个关系三元组(ai,ɑ,aj),下一步跳转至步骤s30303;
s30307、返回simplesent;
举例:按照上述方法处理句子“x国第一任h人种总统b来到历史悠久的g国,和g国现任c总理讨论某某问题。”,结果如下:
c30301:关系(x国,总统,b)构成的简化子句是“x国总统b”,它所在的子句是“x国第一任h人种总统b”,使用简化子句替换该子句;
c30302:关系(b,来到,g国)构成的简化子句是“b来到g国”,它所在的子句是“b来到历史悠久的g国”,使用简化子句替换该子句。
经过上述处理后,原始句子被转换为“x国总统b来到g国,和g国现任c总理讨论某某问题。”
s304、初始化简化后抽取的关系个数simplecount=0;
s305、获取simplesent中的命名实体和依存关系;
举例:按照步骤s304、s305处理简化后句子“x国总统b来到g国,和g国现任c总理讨论某某问题。”,结果如附图7所示。
s306、根据传递依存关系获取simplesent中的新关系,通过实验发现,对句子进行简化后,再进行依存句法分析,可能会使某些孤立实体(没有和其它任何实体建立关系的实体)和其它实体产生传递依存关系,从而建立关联。如附图8所示,具体步骤如下:
s30601:读取第一个孤立实体a;
s30602:判断是否存在和词汇ɑ均具有依存关系的实体b和孤立实体a:
①、若存在,则下一步执行步骤s30603;
②、若不存在,则跳转至步骤s30604;
s30603、抽取关系三元组(a,ɑ,b);
s30604、判断孤立实体是否读取完毕:
①、若是,则跳转至步骤s30606;
②、若否,则下一步执行步骤s30605;
s30605、读取下一个孤立实体a,则跳转至步骤s30602;
s30606、返回所抽取的关系三元组。
举例:以附图7为例,孤立实体是“g国”和“c”,不存在和它们及其它实体均有依存关系的词汇,因此执行步骤s30601到s30606后,无法生成新的关系。
s307、判断所有实体是否均已经和除自身以外的其他实体建立关系:
①、若是,则跳转至步骤s312;
②、若否,则下一步执行步骤s308;
s308、通过添加结构助词获取simplesent中的新关系,通过实验发现,在孤立实体附近添加结构助词(如“的”)后,进行依存句法分析,可能会使某些孤立实体和其它实体产生传递依存关系,从而建立关联。如附图9所示,具体步骤如下:
s30801、读取第一个孤立实体a;
s30802、在孤立实体a的前面寻找关系三元组,如附图10所示,具体步骤如下:
s3080201、在simplesent中,找到孤立实体a前面的第一个实体apre;
s3080202、在实体apre和孤立实体a之间词汇的空隙,添加结构助词,得到句子preauxsimplesent;
s3080203、对preauxsimplesent进行依存句法分析;
s3080204、判断实体apre和孤立实体a是否均与词汇β产生依存关系:
①、若是,则下一步执行步骤s3080205;
②、若否,则跳转至步骤s3080207;
s3080205、抽取关系三元组(apre,β,a);
s3080206、simplecount=simplecount+1;
s3080207、返回simplecount;
s30803、在孤立实体a的后面寻找关系三元组,如附图11所示,具体步骤如下:
s3080301、在simplesent中,找到孤立实体a后面的第一个实体aaft;
s3080302、在孤立实体a和实体aaft之间词汇的空隙,添加结构助词,得到句子aftauxsimplesent;
s3080303、对aftauxsimplesent进行依存句法分析;
s3080304、判断孤立实体a和实体aaft是否均与词汇β产生依存关系:
①、若是,则下一步执行步骤s3080305;
②、若否,则跳转至步骤s3080307;
s3080305、抽取关系三元组(a,β,aaft);
s3080306、simplecount=simplecount+1;
s3080307、返回simplecount;
举例:对附图7中的句子来说,第1个孤立实体是“g国”,在其后面添加结构助词“的”,然后进行处理,结果如附图12所示;可以看出,实体“g国”和“c”均与词汇“总理”存在依存关系,根据依存关系传递性,可以抽取出关系三元组(g国,总理,c);而且,由于添加结构助词并不会影响句子的实际含义,所以原先得到的关系三元组(x国,总统,b)、(b,来到,g国)在处理结果中依然存在,即添加结构助词不会影响原有的关系三元组。
s30804、判断孤立实体是否读取完毕:
①、若是,则跳转至步骤s30806;
②、若否,则下一步执行步骤s30805;
s30805、读取下一个孤立实体a,下一步跳转至步骤s30802;
s30806、返回simplecount。
s309、判断所有实体是否均已经和除自身以外的其他实体建立关系:
①、若是,则跳转至步骤s312;
②、若否,则下一步执行步骤s310;
s310、判断simplecount是否为0:
①、若simplecount=0,则跳转至步骤s312;
②、若simplecount≠0,则下一步执行步骤s311;
s311、设置sent=simplesent;
s312、返回抽取的所有关系三元组。
实施例2:
如附图13所示,本发明的基于传递依存关系和结构助词的关系抽取装置,该装置包括,
命名实体和依存关系获取单元m1,用于获取句子中的命名实体和依存关系;如附图14所示,命名实体和依存关系获取单元m1包括,
句子读取子单元m101,用于读取待处理句子;
分词子单元m102,用于将待处理句子分隔为若干词汇;
词性标注子单元m103,用于标注待处理句子中各个词汇的词性;
命名实体识别子单元m104,用于获取待处理句子中的命名实体;
依存句法分析子单元m105,用于获取待处理句子中词汇间的语义关系。
原始句子关系三元组抽取单元m2,用于直接获取原始句子中存在的语义三元组;如附图15所示,原始句子关系三元组抽取单元m2包括,
实体对读取子单元m201,用于读取原始句子中的任意两个实体;
传递依存关系检测子单元m202,用于检测是否存在和两个实体具有依存关系的词汇;
关系三元组构建子单元m203,用于根据两个实体以及与两个实体存在依存关系的词汇构建出关系三元组。
原始句子简化和关系三元组抽取单元m3,用于根据已生成的关系三元组调整并简化原始句子,并结合结构助词抽取除已生成关系三元组以外的关系三元组。如附图16所示,原始句子简化和关系三元组抽取单元m3包括,
孤立实体检测子单元m301,用于检测是否存在尚未和除自身以外的实体建立关系的实体;
句子简化子单元m302,用于根据关系三元组简化句子;如附图17所示,句子简化子单元m302包括,
关系三元组读取模块m30201,用于读取关系三元组;
简化子句构造模块m30202,用于根据关系三元组生成简化后长度最短的子句;
最小子句替换模块m30203,用于使用简化子句替换原句中包含关系三元组的最小子句;
命名实体识别子单元m303,用于获取待处理句子中的命名实体;
依存句法分析子单元m304,用于获取待处理句子中词汇间的语义关系;
孤立实体关系直接匹配子单元m305,用于根据传递依存关系,在简化后的句子中直接获取孤立实体和除自身以外的实体的关系;如附图18所示,孤立实体关系直接匹配子单元m305包括,
直接孤立实体读取模块m30501,用于读取孤立实体;
孤立实体传递依存关系检测模块m30502,用于检测是否存在和孤立实体具有传递依存关系的其它实体;
孤立实体关系三元组构建模块m30503,用于根据孤立实体和其它实体间的传递依存关系构建出关系三元组;
孤立实体关系间接匹配子单元m306,用于在简化后的句子中添加结构助词,并根据传递依存关系获取孤立实体和除自身以外的实体的关系;如附图19所示,孤立实体关系间接匹配子单元m306包括,
间接孤立实体读取模块m30601,用于读取孤立实体;
孤立实体前向匹配模块m30602,用于在孤立实体的前面添加结构助词,并根据传递依存关系获取孤立实体和除自身以外的实体的关系;
孤立实体后向匹配模块m30603,用于在孤立实体的后面添加结构助词,并根据传递依存关系获取孤立实体和除自身以外的实体的关系。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 还没有人留言评论。精彩留言会获得点赞!