一种基于SOC的可训练柔性CNN系统设计方法与流程
本发明提供的一种基于soc的可训练柔性cnn系统设计方法,属于嵌入式深度学习领域,适用于嵌入式cnn识别系统。
背景技术:
cnn在机器视觉、图像处理等领域表现出优秀的处理能力。目前,基于cnn的人工智能产品,多以专用处理器为核心,依托云平台、服务器,完成核心的神经网络算法。这种实现方法虽然处理性能高,能够保证产品的实时性;但体积庞大、成本和功耗高、便携性差,不能满足工业、医疗、国防等嵌入式应用领域的需求。
近年来,基于fpga的cnn嵌入式加速实现,逐渐成为新的研究热点。但是,现有方案多局限于神经网络算法的前馈过程加速,存在着系统电路固定、适应性差、无法在线学习等不足。特别是在军事目标识别领域,应用场景复杂多变,目标多元化,系统需要具备在线学习能力,以便及时改善识别准确率。因此,迫切需要设计面向嵌入式环境的可训练柔性cnn系统,本发明专利是针对上述问题的一种有效的系统设计方法。
技术实现要素:
本发明的目的在于针对上述存在的问题和不足,提供一种基于soc的可训练柔性cnn系统设计方法,不仅能够实现在线预测功能,而且具有嵌入式在线学习和结构柔性拓展能力,能适应多种应用场景,非常适合低成本、低功耗的嵌入式应用环境。
为了实现上述目的,本发明采用的技术方案是:一种基于soc的可训练柔性cnn系统设计方法,包括以下几个步骤:
步骤1:利用fpga片上软核或硬核处理器实现学习引擎,利用fpga逻辑设计前馈加速器,并设计外部接口模块,构建基于soc的可训练cnn系统的硬件框架;
步骤2:使cnn系统进入在线学习阶段,通过外部接口设置网络结构参数,并初始化训练样本图像个数;
步骤3:通过外部接口向cnn系统加载一个训练样本图像,同时初始化待加速网络层数和网络权值;
步骤4:在学习引擎的控制下,分时复用前馈加速器,实现图像数据处理的前馈过程加速;
步骤5:学习引擎访问最后一个待加速cnn网络层的运算结果,执行输出层,输出执行结果;
步骤6:学习引擎根据学习规则,以最优化误差损失为目标函数,推算新权值;
步骤7:将步骤6所得新权值作为初始化网络权值,重复步骤3~6,依次学习全部样本;
步骤8:使cnn系统进入预测阶段,将步骤7所得最终网络权值作为初始化网络权值,通过外部接口加载待预测图像,重复步骤4~5,输出执行结果。
进一步地,步骤1中,所述cnn系统的学习引擎、前馈加速器和外部接口均在同一片fpga上实现;所述外部接口和所述学习引擎的输入输出互连,所述前馈加速器和所述学习引擎通过总线互连;所述前馈加速器包括可重构加速单元、数据缓存区、参数配置器、状态监控器和地址生成器,其中参数配置器的输出分别连接地址生成器和可重构加速单元,地址生成器的输出连接数据缓存区,数据缓存区的输出连接可重构加速单元,可重构加速单元的输出分别连接数据缓存区和状态监控器;
所述学习引擎为主控制器,负责各模块的总体控制、样本图像损失误差的分析和新权值的计算;所述外部接口用于与外部通信,接收控制命令,输入样本图像、待预测图像和初始权值,输出处理结果;所述前馈加速器用于实现图像数据处理的前馈过程加速;所述前馈加速器的数据缓存区包括图像缓存、权值缓存和特征图缓存,均为双端口ram。
进一步地,步骤4中,所述图像数据处理的前馈过程加速的具体实现方法如下:
(1)学习引擎将当前待加速cnn网络层的网络权值存储至数据缓存区,并向参数配置器发送当前待加速层cnn网络层的网络参数,配置地址生成器和可重构加速单元;
(2)地址生成器产生相应的图像、权值数据读取地址,向可重构加速单元加载数据流;
(3)可重构加速单元对输入图像数据进行卷积、激活、池化等运算,并将特征图结果保存至数据缓存区,作为下一级待加速cnn网络层的输入;
(4)状态监控器实时监测可重构加速单元的状态信号,等待当前待加速cnn网络层加速计算完毕;
(5)状态检测器向学习引擎发送请求处理下一级信号;
(6)重复(1)~(5),直至所有待加速cnn网络层处理完毕。
进一步地,所述前馈过程加速的具体实现方法采用加速器与数据流分离的设计方法:所述可重构加速单元包含n路运算链,每条运算链通过卷积、激活、池化等算子组合,提取一种特征信息,运算链路数n由参数配置器设置;所述地址生成器根据参数配置器设置的当前待加速层模型参数,生成数据缓存区的读取地址序列,自动向可重构加速单元加载数据流;通过控制加速器链路数与数据流的变化,灵活地适应不同卷积层的加速计算,实现cnn结构的柔性拓展。
与现有技术相比,本发明的有益效果是:系统整体采用包含学习引擎、前馈加速器和外部接口的soc架构,能够实现cnn系统的嵌入式在线学习和预测功能;采用数据流与加速器分离的设计方法,能够实现cnn结构的柔性拓展;通过分时复用前馈加速器,并通过加速器协助训练过程,不仅节约了硬件资源开销,而且降低了系统功耗和体积,在工业、医疗、国防等低成本、低功耗的嵌入式应用领域具有广阔的应用前景。
附图说明
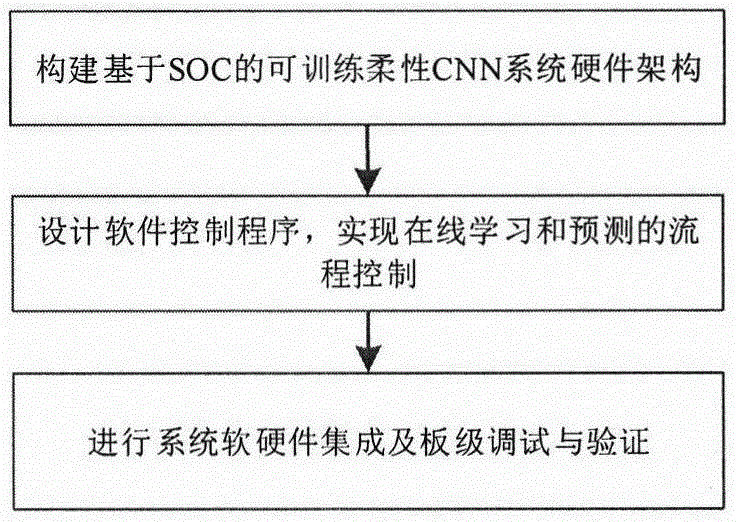
图1为本发明实施实例的可训练柔性cnn系统的设计流程
图2为本发明实施实例的可训练柔性cnn系统的soc系统组成框图
图3为本发明实施实例的串口通信界面交互信息
具体实施方式
下面详细描述本发明的实施例,本实施例是示例性的,仅用于解释本发明,而不能理解为对本发明的限制。基于xilinx公司的zedboard开发板设计和实现本发明实例,参照说明书附图对本发明的一种基于soc的可训练柔性cnn系统设计方法作以下详细说明。
如图1所示,为基于soc的可训练柔性cnn系统的设计流程,包括以下步骤:首先构建基于soc的可训练柔性cnn系统硬件架构;然后设计软件控制程序,实现在线学习和预测的流程控制;最后完成系统软硬件集成,并进行板级调试与验证。
(1)构建基于soc的可训练柔性cnn系统的硬件架构
如图2所示,为本发明实施实例的可训练柔性cnn系统的soc系统硬件架构:采用fpga片上arm硬核实现学习引擎,采用fpga逻辑资源设计前馈加速器,包括可重构加速单元、参数配置器、地址生成器、状态监控器、bram控制器等;采用外部sd卡存储fpga初始化位流、样本集、测试集,采用uart接口实现与pc机的通信;具体构建步骤如下:
①在vivado开发环境下,使用verilog硬件描述语言,设计可重构加速单元、地址生成器、状态监控器、参数配置器等模块,并设计顶层文件,编写仿真代码,进行仿真测试,验证设计的正确性;
②将参数配置器、状态监控器等具有axi接口的模块封装成ip核;
③创建基于zynq硬核处理器核的系统,并修改其配置信息,包括系统时钟频率、存储器类型、外设io引脚等;
④在系统中添加①和②所设计的ip核和其他必要的辅助ip核,并按照图2所示连接各ip核,完成cnn系统硬件架构的构建;然后通过综合报告,分析优化时序、资源利用率;最后经布局布线,生成系统全局配置位流文件system.bit。
(2)设计软件控制程序
在sdk软件开发环境下,以cnn中典型的lenet5模型为例,采用c语言编程,实现可训练柔性cnn系统的在线学习和预测的控制流程,并生成可执行文件mynet.elf;主要包括以下步骤:
s1:学习引擎通过uart接口与外部pc机通信,设置网络结构参数,并初始化训练样本图像个数;
s2:学习引擎从片外存储器ddr中加载一个训练样本图像,并通过axi总线将图像数据传递至图像缓存区imb;
s3:初始化待加速网络层数和网络权值,并初始化可重构加速单元输入通道,使可重构加速单元的初始输入数据dina和dinb分别来自图像缓存区imb和权值缓存区wtb;
s4:学习引擎通过axi总线将待加速层网络权值传递至权值缓存器wtb;并利用当前待加速层的模型参数,包括卷积核的个数n、卷积核的尺寸k、输入特征图的大小f、池化核尺寸p,经过参数配置器,配置可重构加速单元和地址生成器;
s5:地址生成器产生相应的图像、权值数据读取地址addra和addrb,向可重构加速单元加载数据流;
s6:可重构加速单元对输入数据流dina、dinb进行卷积、激活、池化等运算,并将输出结果doutf传送至特征图缓存区fb中,准备进行下一级隐含层加速;
s7:状态监控器实时监测可重构加速单元的状态信号finish,若finish为1,表示当前层加速计算完毕,转s8;否则,继续等待。
s8:将dina输入由图像通道切换至特征图通道,并向学习引擎发送请求处理下一级信号;
s9:学习引擎判断待加速层数是否为0,若为0,表明所有网络层处理完毕,转s10;否则将待加速层数减1,转s4;
s10:学习引擎访问特征图缓存区fb中的特征图结果,执行输出层,并输出执行结果;
s11:学习引擎根据学习规则,以最优化误差损失为目标函数,推算新权值;
s12:学习引擎判断样本个数是否为0,若为0,表明所有样本学习完毕,转s13;否则,将待学习样本个数减1,转s2;
s13:学习引擎将最优网络权值暂存外部存储器ddr中,学习完毕;
s14:进入预测阶段,将s13所得最终网络权值作为初始化网络权值,加载待预测图像,重复s3~s10,输出执行结果。
(3)系统软硬件集成及板级调试与验证
在sdk中,将系统全局配置位流文件system.bit和可执行文件mynet.elf生成系统的启动文件boot.bin文件,并保存至sd卡中。
将sd卡插入开发板卡槽,然后在硬件系统中添加debug核,用于抓取信号,通过调试,验证系统功能的正确性。开发板上电后,系统先将样本集、测试集从sd卡加载到ddr3中,等待用户发出开始训练指令,工作过程中串口通信界面交互信息如图3所示。
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!