一种基于差分隐私保护的兴趣点推荐算法的制作方法
本发明属于兴趣点推荐算法技术领域,特别涉及一种基于差分隐私保护的兴趣点推荐算法。
背景技术:
目前,基于位置的社交网络(lbsn,location-basedsocialnetworks)应用非常广泛,典型的lbsn有美团、街旁、大众点评网等。这些社交网站为用户提供兴趣点(poi,pointofinterests)的签到、评论以及分享功能,这些功能积累的大量数据可作为兴趣点推荐的基础数据。兴趣点推荐服务是基于用户和地理位置的社交网络中的一种服务类型,主要是向用户推荐满足自身偏好并且从未去过的位置。在互联网的快速发展中,兴趣点推荐服务可以让用户更加方便的在网络上与朋友分享信息、推荐信息,但与此同时也存在弊端,用户需要暴露隐私信息来进行推荐,因此会带来隐私泄露的风险,例如观察用户每天的出行路线,可以大致推测出用户的家庭住址以及公司地址;将用户的历史访问兴趣点进行分类统计,能够大致得出用户的个人喜好以及经济情况,所以用户可能会因为隐私问题不愿意接受这样的推荐服务。在传统的兴趣点推荐服务中加入差分隐私保护机制,就可以很好地解决这个问题。
国内外大量的学者对兴趣点推荐系统进行了深入地研究。park等人根据用户对餐厅属性的偏好,采用贝叶斯分析方法构建数学模型,将用户可能感兴趣的餐厅反馈给用户。nunes等人提出了一种基于位置信息的推荐方法,利用位置感知和高斯模型进行推荐。jia-dongzhang等人提出了兴趣点推荐系统需要考虑的几点因素:地理位置、好友信息、用户偏好以及时空关系,详细地列举了影响兴趣点推荐的几个方面。曹玖新、董羿等人对社交网络图和签到轨迹图进行综合考虑,将这两个图结合起来,计算每条路径的关联度,为用户推荐兴趣点。jehg,widomj等人运用pagerank算法,提出了两种改进的位置推荐算法:基于好友关系的标签涂色算法和基于位置-好友关系的标签涂色算法。yang等人提出了一种结合空间和时间因素的兴趣点推荐方法。
上述算法虽然能从不同角度满足兴趣点推荐系统的要求,但是并没有考虑到用户的隐私泄漏问题。
现有的位置隐私保护方法大多都是通过地理位置信息模糊化的方法达到隐私保护的效果。当用户向系统发送一个当前地理位置的信息时,尽管发送的实时地理位置是模糊的,但是其签到所在的兴趣点是精确存在的。攻击者仍然可以通过获取该兴趣点的相关信息获得用户的实时地理位置,所以对于当前位置隐私保护的程度是远远不够的。
技术实现要素:
本发明的目的是提供一种基于差分隐私保护的兴趣点推荐算法,在传统的推荐算法中加入差分隐私算法,在保证兴趣点推荐效果的同时,能够保护用户的隐私信息;本发明采用树的结构来表示位置数据,对位置记录进行加噪处理时,加噪扰动的对象是整个节点,而不是单独的位置记录,能够减少加噪次数,使记录具有较高的可用性,还能保持记录之间的关联,减少算法运行时间,提高算法效率。
本发明提供的技术方案为:
一种基于差分隐私保护的兴趣点推荐算法,包括如下步骤:
步骤一、将数据集中的数据构建成位置搜索树;
步骤二、从所述位置搜索树中筛选出访问频率大于最小访问频率的记录,组成第一集合;
步骤三、运用指数机制从所述第一集合中选取多项记录,组成第二集合;
步骤四、对所述第二集合中的记录添加拉普拉斯噪声后,组成第三集合;
步骤五、将所述第三集合中的数据构建成位置搜索树,得到添加噪声后的位置搜索树。
优选的是,在所述步骤三中,从所述第一集合中选取访问频率高的k项记录ai,组成第二集合;
其中,被选取的记录ai满足:
其中,pr(ai)表示记录ai被选取的概率;ai·weight表示记录ai的权重;aj表示与所述第一集合相差一条记录的集合中的记录,n表示数据集中频繁模式记录的个数。
优选的是,所述记录ai的权重为:
其中,ε1为选择记录ai所分配的隐私代价;mark(a,ai)为所述第一集合中记录的打分函数;δmark为所述打分函数的全局敏感度。
优选的是,所述第一集合中记录的打分函数为:
mark(a,ai)=q(ai);
其中,q(ai)表示记录ai的访问频率。
优选的是,所述打分函数的全局敏感度为:
其中,q(aj)表示记录aj的访问频率。
优选的是,在所述步骤四中,向第二集合中的记录添加拉普拉斯噪声,添加的噪声服从概率密度函数为
其中,x表示访问频率,μ和λ分别表示x的期望和尺度参数。
本发明的有益效果是:
(1)本发明提供的基于差分隐私保护的兴趣点推荐算法,在传统的推荐算法中加入差分隐私算法,在保证兴趣点推荐效果的同时,能够保护用户的隐私信息,具有良好的可用性和安全性。
(2)本发明采用树的结构来表示位置数据,对位置记录进行加噪处理时,加噪扰动的对象是整个节点,而不是单独的位置记录,能够减少加噪次数,使记录具有较高的可用性,还能保持记录之间的关联,减少算法运行时间,提高算法效率。
附图说明
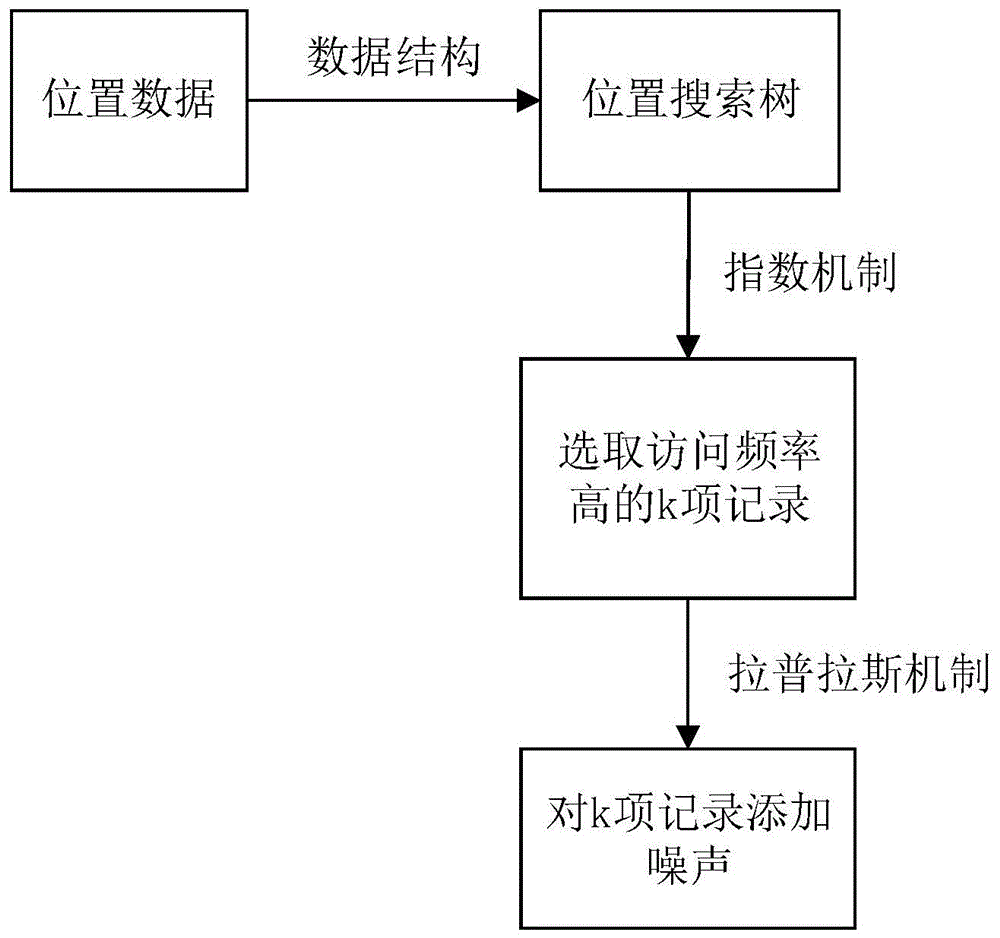
图1为本发明所述的基于差分隐私保护的兴趣点推荐算法设计框图。
图2为本发明所述的位置搜索树示意图。
图3为传统推荐算法和本发明推荐算法的召回率对比图。
图4为传统推荐算法和本发明推荐算法的准确率对比图。
具体实施方式
下面结合附图对本发明做进一步的详细说明,以令本领域技术人员参照说明书文字能够据以实施。
本发明提供了一种基于差分隐私保护的兴趣点推荐算法,差分隐私为一种类似加密的方法,对于数据集的计算结果而言,单个记录是否在数据集中对结果造成的影响可以忽略不计。因此,攻击者无法通过计算得知某条记录是否在数据集中。
存在一个含有n条记录的数据集d,记为d=(x1,x2,...,xn),d中的每个xi都是一条记录,取值均在rd范围内,向量xi的d个元素分别对应记录的d个属性。定义隐私保护算法a的取值范围为t,若算法满足以下不等式,则算法a满足ε-差分隐私
p(a(d)∈s)≤eεp(a(d')∈s)(1)
其中,
差分隐私有两个重要的性质:
(1)若原始数据v是算法a的输出结果,a满足ε-差分隐私,那么关于v的任意函数g(v)的输出结果均满足ε-差分隐私。
(2)对原始数据v使用两个隐私保护算法a1和a2,其中,a1满足ε1-差分隐私,a2满足ε2-差分隐私,那么v的隐私保护参数至多为ε1+ε2。
在推荐系统中,基于地理位置的推荐服务是主要的推荐方式之一。在设计算法的时候,应该在准确推荐的同时考虑到隐私泄露的问题。
如图1所示,本发明提出的基于差分隐私保护的兴趣点推荐算法就是在传统的兴趣点推荐算法中加入地理位置隐私保护算法,以此达到预期目的。地理位置隐私保护算法首先根据数据的相互关系构建位置搜索树,然后采用指数机制挑选出经常访问的k项记录,并对这些记录添加拉普拉斯噪声,最后返回加噪处理后的位置搜索树。
具体过程如下:
(1)将位置数据集d中的所有元素构建成一个完整的位置搜索树lstd。搜索树主要利用数据结构中学习的n叉树的构建方法来建立:首先构建一个根节点,按照树的广度优先搜索方式,将位置数据库中只包含一个兴趣点的记录存入根节点的孩子节点中;接着以同样的方式,将位置数据库中包含两个兴趣点的记录存入上一层节点的孩子节点中。以此类推,直至将位置数据库中的记录全部存入位置搜索树。
(2)遍历搜索树lstd得到所有满足访问频率大于最小访问频率(min-count)的频繁模式记录ai,将该集合记为a。
(3)运用指数机制从集合a的记录ai中挑选出k个满足条件的频繁模式记录,将这些记录表示为bi,由bi构成的集合称为集合b。
指数机制不仅能够筛选出包含用户隐私信息大于最小访问频率(min-count)的位置,而且在每次筛选的时候能够控制隐私泄露情况。
通过指数机制在集合a中选取k个满足
的频繁模式ai,构成集合b。公式(2)中,pr(ai)表示被选取的概率;ai·weight表示ai模式的权重。
集合a为访问频率不小于min-count的频繁模式记录ai的集合,在集合a中选取k个频繁模式ai的具体方法为:
首先计算每一个频繁模式记录的打分函数mark(a,ai);然后根据打分函数计算每个模式ai的权重,并将权重存入降序链表l中;接着计算前k个频繁模式ai被选择的概率;最后根据计算出的概率大小,对频繁模式ai按照降序的方式插入到集合b中。
该算法是在inter(r)core(tm)i5-4210cpu@1.70ghz,内存4gb,磁盘容量512gb的windows7x64旗舰版上进行,所有框架和算法都是使用java1.7进行开发的,其中数据库使用mysql5.6版本,使用eclipse4.2作为ide,算法的科学计算部分由matlabr2012a完成。
具体操作过程包括:
输入:集合a,ε1为选择k个模式所分配的隐私代价。
输出:选出的k个模式组成的集合b。
其中,将打分函数设置为
mark(a,ai)=q(ai)(3)
q(ai)表示ai模式的访问频率;
aj为与ai为至多相差一条记录的数据库,可以将算法的敏感度理解为向数据库中添加或随机删除一条记录之后可能对算法结果产生的最大影响;
q(aj)表示aj模式的访问频率。
(4)对集合b中的k个频繁模式记录bi的访问频率添加拉普拉斯噪声,将该集合记为e;具体方法为:
将集合b中的频繁模式记录bi依次取出,对bi添加大小为
具体操作过程包括:
输入:隐私预算ε2、集合b,查询函数f。
输出:添加拉普拉斯噪声后的top-k个频繁模式集合。
向b中的k个模式添加拉普拉斯噪声,添加的噪声服从概率密度函数为
的拉普拉斯分布,其中x表示访问频率,μ和λ分别表示x的期望和尺度参数;x的方差为2λ2。参数λ由查询算法的敏感度和隐私保护参数ε共同决定,表示为λ=δf/ε。
(5)用构建位置搜索树lstd的方法,将集合e也表示成树的结构,记为nlstd。
(6)输出添加噪声后的位置搜索树nlstd。
在top-k频繁模式挖掘中,应该先在挖掘k个模式之前采用指数机制找出数据集d中所有访问频率大于min-count的频繁模式,然后采用拉普拉斯噪音机制扰动挖掘结果,向挖掘结果中添加适当噪声,则可以保护top-k模式的访问频率不被泄露。
实施例
(1)将某人一个月内访问的poi(兴趣点)做对应编号,具体位置及编号如表所示:
表1位置对应关系
根据表1的编号和每个位置被访问的次数建立位置数据库,如表2所示:
表2位置数据库
根据表2的位置数据库,建立如图2所示的位置搜索树lstd,它包含了位置数据库d中的所有频繁模式。
(2)遍历lstd得到所有满足访问频率大于min-count的频繁模式记录ai,将该集合记为a。
(3)通过指数机制在集合a中选取k个满足
的频繁模式ai,构成集合b。
其中,选取k个频繁模式ai的具体操作过程为:
输入:a为访问频率不小于min-count的频繁模式ai的记录集合,ε1为选择k个模式所分配的隐私代价。
输出:选出的k个模式组成的集合b。
其中,将打分函数设置为
mark(a,ai)=q(ai)
q(ai)表示ai模式的访问频率;
(4)输入:隐私预算ε2、b,查询函数f。
输出:添加拉普拉斯噪声后的top-k个频繁模式集合。
向b中的k个模式添加拉普拉斯噪声,添加的噪声服从概率密度函数为
的拉普拉斯分布,添加拉普拉斯噪声后的集合b记作集合e。
(5)用构建位置搜索树lstd的方法,将集合e也表示成树的结构,记为nlstd;输出添加噪声后的位置搜索树nlstd。
本实施例是在inter(r)core(tm)i5-4210cpu@1.70ghz,内存4gb,磁盘容量512gb的windows7x64旗舰版上进行,所有框架和算法都是使用java1.7进行开发的,其中数据库使用mysql5.6版本,使用eclipse4.2作为ide,算法的科学计算部分由matlabr2012a完成。
试验例
用于算法实验测试的数据来源于foursquare网站,该网站包括从2010年3月份到2011年12月份的所有数据,其中包含18293个用户的基本信息、43186个兴趣点信息以及用户签到所产生的1903909次签到数据。
兴趣点推荐算法主要使用两个指标进行评估,即召回率(r,recall)和准确率。召回率是指推荐算法返回的被标记并加噪的兴趣点数量比上所有被标记的兴趣点数量的百分比,准确率是指推荐算法返回的被标记并加噪的兴趣点数量比上所有被加噪的兴趣点数量的百分比。令集合a表示所有被标记过的兴趣点集合,集合b表示算法返回的加噪后的兴趣点集合,根据上述定义,得出召回率与准确率的公式为:
召回率
准确率
在本次试验中,n表示推荐算法待返回的top-n个值,n的值是不断变化的,在n的所有取值情况下(n=5,10,20,50),将召回率和准确率作为评价算法好坏的指标,比较加入差分隐私保护算法后的本发明推荐算法与传统推荐算法的性能差异。
如图3所示,为在n取值不同的情况下,传统推荐算法和本发明推荐算法的召回率对比图。
如图4所示,为在n取值不同的情况下,传统推荐算法和本发明推荐算法的准确率对比图。
对图3和图4进行分析,可以得出无论是召回率还是准确率,差分隐私保护算法的加入都没有对推荐算法产生非常大的影响。在n的所有取值情况下,传统推荐算法和本发明推荐算法的有效性大体一致,本发明推荐算法从召回率和准确率这两个指标上看与传统推荐锻打的推荐算法基本持平。试验结果印证了我们对差分隐私保护的兴趣点推荐算法优越性的理论分析,使用该算法,既能保护用户的地理位又能起到很好的推荐效果,试验证明所设计的算法完全达到了预期效果。
本发明中首先将数据集中的记录表示成树的结构,方便查找、加躁和发布处理,然后挑选出经常访问的k项记录,并把拉普拉斯噪声添加到这些记录中,最后返回加噪处理的位置搜索树。该地理位置隐私保护算法与传统的位置信息模糊化算法相比,运用了差分隐私保护机制,采用了树的结构来表示位置数据。对位置记录进行加噪处理时,加噪扰动的对象是整个节点,而不是单独的位置记录,这样设计算法不仅能减少加躁次数,使记录具有较高的可用性,还能保持记录之间的关联,减少算法运行时间,提高算法效率。
理论分析与实验结果表明,加入差分隐私保护的兴趣点推荐算法仍具有良好的性能。在试验过程中,该算法具有较高的可用性和安全性,能在很大程度上减少添加的噪声量,从而在达到保护用户隐私信息的目的的同时,具有良好推荐效果。
尽管本发明的实施方案已公开如上,但其并不仅仅限于说明书和实施方式中所列运用,它完全可以被适用于各种适合本发明的领域,对于熟悉本领域的人员而言,可容易地实现另外的修改,因此在不背离权利要求及等同范围所限定的一般概念下,本发明并不限于特定的细节和这里示出与描述的图例。
- 还没有人留言评论。精彩留言会获得点赞!