一种卷积神经网络的新闻用户兴趣挖掘方法与流程
本发明涉及一种卷积神经网络的新闻用户兴趣挖掘方法,属于自然语言处理技术领域。
背景技术:
互联网时代,每天都会不断涌现无法预计的大量新闻信息以及新闻活越用户,用户的兴趣同时反映新闻关注度,对新闻用户的兴趣挖掘对分析新闻舆情有一定的积极作用。在新闻平台中,用户的大部分舆情行为是围绕用户的兴趣展开的,例如在新闻点赞的行为、发评论的行为,都在一定程度反映用户的关注点。
研究用户兴趣对企业平台具有举足轻重的意义,例如电商平台,挖掘用户兴趣,进而挖掘用户潜在感兴趣的商品,可用于商品推荐。而在内容消费平台中,从用户的一系列行为中挖掘用户的兴趣偏好,可以直接应用于内容推送,在新闻舆情分析领域中,发掘用户的兴趣有利于发现舆情走势。但是用户兴趣的研究同时也是一个难点。而现阶段,新闻用户兴趣分类主要面临问题是没有兴趣标签数据,在实现上往往依赖于人工标注与简单的关键词计算,准确率不高难以普适化。此外,在对于新闻用户的兴趣建模方面应用研究较少,迫切需求针对新闻用户的兴趣分类技术。
技术实现要素:
本发明的目的在于提供一种卷积神经网络的新闻用户兴趣挖掘方法,以解决现有技术中新闻用户兴趣分类没有兴趣标签数据,往往依赖于人工标注与简单的关键词计算,准确率不高难以普适化的问题。
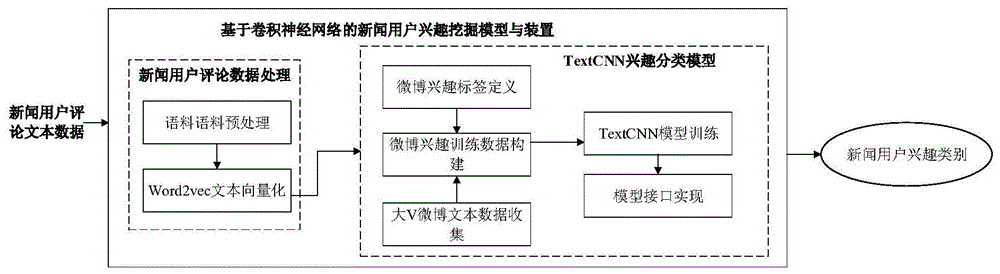
一种卷积神经网络的新闻用户兴趣挖掘方法,包括两方面内容:兴趣标签构建与新闻用户兴趣分类模型的训练;具体如下:
首先、基于微博标签的兴趣挖掘标签数据构建
步骤一:定义兴趣标签
采用微博用户兴趣类别的一阶类别,主要分为11大类,兴趣标签类别分别为财经、体育、军事、教育、法律、科技、社会、时政、文学、游戏和娱乐;
步骤二:训练数据构造
s2.1、选择微博大v,尤其是一些官方微博,从兴趣分类任务出发,选择用户领域性强,标签明确的种子用户;
s2.2、提取这部分种子用户的近三个月的新闻文本作为训练样本;其中,设置有过滤规则,筛掉其中字数小于50字的微博,选取剩余的1000条作为训练数据;
s2.3、对新闻文本进行预处理,采用正则表达式将任何与新闻上下文无关的噪声文本做移除处理;对新闻文本去除标点、url链接、社交媒体实体,并将大段的文本分解为句子;
s2.4、对经步骤s2.3处理后的所有数据按照6:2:2的比例分为训练集、验证集、测试集;准备模型的训练;
其次、分类模型构建与训练
步骤三、词向量的语料收集与词向量训练
词向量的语料收集即词向量语料库构建过程为:收集或者爬取多种来源的新闻语料数据。词向量训练过程为:随机初始化向量,遍历一次词向量训练语料库,调用gensim接口进行词向量训练,最终获得词向量结果。
步骤四、构造word到token的映射和token到word的映射,得到映射表,以备后续模型调用词向量使用。
步骤五、在映射表的基础上,对原始文本进行转换,即将文本转换为机器可识别的编码。其中,文本的长度采取截断处理,以用户微博的平均词数作为截断值,将每篇文本进行截断,对长度不足的文本0向量填充。
步骤六:加载步骤三预训练好的词向量文件,基于训练好的词向量构造一个词典词汇数量vocab_size*词向量维度embedding_size大小的矩阵。
步骤七:完成上述各种预处理后,将带有微博兴趣标签的微博文本数据接入到分类模型进行训练,所述的分类模型采用textcnn模型。本发明的最优textcnn模型是4层卷积结构,每层卷积后加一层池化操作,最后一层是全连接层。
本发明一种卷积神经网络的新闻用户兴趣挖掘方法,其优点及功效在于:本发明实现了一种自动构造新闻用户兴趣标签的方法,首先基于微博兴趣标签分类的用户兴趣数据集的构建,通过在微博数据上实现模型的训练后,把模型应用于新闻文本的用户兴趣分类任务中。通过对新闻用户的评论内容进行逐条兴趣分类,从而缓解噪声词对兴趣词的影响,然后通过用户在微博中的兴趣类别标签分布识别新闻用户的兴趣。
其次,本发明采用textcnn卷积神经网络实现文本分类器。通过构建一个结合连续的语义特征cnn卷积神经网络作为兴趣文本分类器,对用户的新闻评论进行兴趣分类,通过极大似然估计得到用户的兴趣标签类别。
附图说明
图1所示为本发明一种卷积神经网络的新闻用户兴趣挖掘方法流程框图。
图2所示为本发明textcnn模型网络结构简易图。
具体实施方式
下面结合附图和实施例,对本发明的技术方案做进一步的说明。显然,该描述的实例仅仅是本发明的一部分实施举例而不是全部。基于本发明中的实例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例都属于本发明的保护范围。
本发明一种卷积神经网络的新闻用户兴趣挖掘方法,包括两方面内容:兴趣标签构建与新闻用户兴趣分类模型的训练;具体如下(如图1所示):
首先、基于微博标签的兴趣挖掘标签数据构建
步骤一:定义兴趣标签
采用微博用户兴趣类别的一阶类别,主要分为11大类,兴趣标签类别分别为财经、体育、军事、教育、法律、科技、社会、时政、文学、游戏和娱乐。类别标签的设定主要参考了新浪微博的微博找人模块,根据领域标签可以实现对用户的搜索。在本发明中,通过微博标签把用户兴趣归并为11大类,基本也包含大部分微博用户的兴趣领域。
步骤二:训练数据构造
s2.1、选择微博大v,尤其是一些官方微博,从兴趣分类任务出发,选择微博大v等用户领域性强,标签明确的种子用户;
s2.2、提取这部分种子用户的近三个月的新闻文本作为训练样本;由于字数太少的文本语义太稀疏,不利于模型训练,本文设置了过滤规则,筛掉其中字数小于50字的微博,选取剩余的1000条作为训练数据;
s2.3、对新闻文本进行预处理,从开放域爬取得到的新闻的正文往往含有除了表达内容外的其他噪声文字,采用正则表达式将任何与新闻上下文无关的噪声文本做移除处理。对新闻文本去除标点、url链接、社交媒体实体(开头的报道媒体)等,并将大段的文本分解为句子;
s2.4、对经步骤s2.3处理后的所有数据按照6:2:2的比例分为训练集、验证集、测试集;准备模型的训练。
其次、分类模型构建与训练
步骤三、词向量的语料收集与词向量训练
因为分类模型的输入是词向量,所以首先需要训练词向量。
词向量语料库构建过程为:收集或者爬取多种来源的新闻语料数据。为了获得比较优质的词向量训练语料数据,本发明的词向量语料来自于五大门户网站(搜狐、新浪、网易等)的新闻语料。
其训练过程为:随机初始化向量,遍历一次词向量训练的语料库,调用gensim接口进行词向量训练。获得词向量结果。
步骤四、构造word到token的映射和token到word的映射,得到映射表,以备后续模型调用词向量使用。
步骤五、在映射表的基础上,对原始文本进行转换,即将文本转换为机器可识别的编码。其中,文本的长度采取截断处理,以用户微博的平均词数作为截断值,将每篇文本进行截断,对长度不足的文本0向量填充。
步骤六:加载步骤三预训练好的词向量文件,基于训练好的词向量构造一个词典的词汇数量vocab_size*词向量的维度embedding_size大小的矩阵。
步骤七:完成上述各种预处理后,将带有微博兴趣标签的微博文本数据接入到分类模型进行训练,所述的分类模型采用textcnn模型。本发明的最优textcnn模型是4层卷积结构,每层卷积后加一层池化操作,最后一层是全连接层。
模型网络结构简易图如图2所示。
进一步的,本发明方法在训练好上述模型后,进一步提出针对此模型的接口调用,方便用于新闻用户的兴趣挖掘分析;具体如下:
步骤一:模型接口实现方便兴趣分析调用;
步骤二:输入新闻用户的评论文本数据,因为自然语言处理文本对短文本的语义学习能力的不足,本发明建议输入新闻用户的评论数据文本长度在30个字符以上。
步骤三:调用接口输出兴趣标签。
本发明方法重点提出了一种新闻用户的兴趣挖掘方法,由于新闻数据无用户的标签数据,本发明提出从微博兴趣标签构造兴趣分类模型建模的方法。通过在微博数据上实现模型的训练后,把模型应用于新闻文本的用户兴趣分类任务中。基于textcnn的方法能够有效抓取文本的局部特征,多层卷积网络对于语义感受野区间较大,模型具备一定鲁棒性和泛化性能。
为了评估本发明中兴趣分类模型上的性能,本发明在兴趣标签的多分类任务中,采用的评价指标是f1值和正确率(accuracy),其中正确率是衡量分类结果正确性的一个比较直观的评价指标,是分类正确的样本数除以所有样本数。而f1值是对分类器的一个整体评价,受精确率(precision)和召回率(recall)的影响。
在多分类的情况中,对于类别c,分类结果一般都4种情况:
·属于类c的样本被正确分类到类c,记这一类样本数为tp
·不属于类c的样本被错误分类到类c,记这一类样本数为fp
·属于类c的样本被错误分类到除类c的其他类,记这一类样本数为fn
·不属于类c的样本被正确分类到除类c的其他类,记这一类样本数为tn则有,对于类别c的精确率(precision)和召回率(recall)为:
precision=tp/(tp+fp)(1)
recall=tp/(tp+fn)(2)
精确率又叫查准率,计算的是正确分类到类别c的样本数占所有被分类到类别c的比率;而召回率又叫查全率,计算的是正确分类到类别c的样本数占所有属于类别c样本的比率。对于一个分类器来说,既要追求比较高的精确率,同时也要求较高的召回率,而f1值则是用来综合衡量精确率和召回率的统一指标,f1公式如下所示:
由于多分类任务中,类别标签有多个,故将所有类别的f1值计算得到,并且求算术平均值,即为的综合f1值,用于评价整个分类器的效果。
- 还没有人留言评论。精彩留言会获得点赞!