一种基于传感器融合的图像快速识别方法与流程
本发明涉及组合导航及交通标志识别技术领域,尤其涉及一种基于传感器融合的图像快速识别方法。
背景技术:
随着darpa重启无人车技术研究,并先后于2004年、2005年和2007年举办了三届智能车挑战赛,谷歌大力投入自动驾驶技术研究,近年来全球范围内掀起了自动驾驶技术研究的热潮,自动驾驶领域创业公司也如雨后春笋般应运而生。
自动驾驶技术经过十多年发展,逐渐从实验室研究、到封闭环境技术竞赛、再到固定场景示范应用,虽然取得了长足的进展,但距离实际应用仍有较大距离,只能在封闭场景低速驾驶状态下执行简单确定性任务,并且可靠性较低。并且随着城市化进展及汽车的普及,城市交通拥挤加剧,无人驾驶有可能导致的交通安全问题变得日益突出。
基于计算机视觉的驾驶员支持系统是解决交通安全问题的重要措施之一,主要在交通标志识别、道路识别等领域发挥重要作用。目前,交通标志识别主要是采用计算机视觉系统在没有任何先验信息下的实时检测,然而由于交通标志种类繁多,实时检测情况下抓取的图片背景复杂,光照强度及角度的影响都有可能影响交通标志的正确分类识别;此外实时检测在没有交通标志时也进行识别工作,浪费了大量的计算资源。
技术实现要素:
针对上述不足,本文提供一种基于传感器融合的图像快速识别方法,利用惯导/高精度数字地图导航,预先获取交通标志在图片中的位置,能较为准确地提取交通标志关键特征,解决了传统方法中存在着无交通标志先验信息及计算资源浪费的问题。在预先获取交通标志信息后,再利用机器学习或者深度学习算法,对交通标志进行分类识别。
本发明所采用的技术方案如下:一种基于传感器融合的图像快速识别方法,包括如下步骤:
(1)根据惯导和高精度地图,获得车载惯导和交通标志的经度、纬度高、高度信息,通过姿态矩阵转换和坐标变换,得到相机与交通标志的相对位置和姿态关系;
(2)根据相机坐标系与像平面坐标系的关系,获取交通标志在像平面坐标系的位置,并转换成像素坐标系坐标;
(3)根据交通标志在像素坐标系中位置,提取图片中交通标志重要特征;
(4)对交通标志进行识别。
进一步的,所述步骤(1)具体如下:
(1.1)通过惯导在线解算,获得载体的实时精度ba、维度la、高度ha,据此获得高精度地图中相对应的交通标志及其经度bs、纬度ls、高度hs,并将载体及对应的交通标志的经度、纬度、高度信息分别转换为wgs84地心坐标系的坐标(xia,yia,zia)和(xis,yis,zis);
(1.2)建立以惯导载体中心为原点o,以东向为x轴,北向为y轴,天向为z轴的导航坐标系oan-xanyanzan,通过坐标系转换,得到交通标志位置信息在导航坐标系oan-xanyanzan中的坐标(xan,yan,zan);
(1.3)根据惯导输出的姿态信息:偏航角φab、俯仰角θab和滚转角γab,建立载体姿态矩阵,并将步骤(1.2)中载体导航坐标系oan-xanyanzan转换得到载体本体坐标系oab-xabyabzab,其中传感器中心为原点o,沿纵轴向前为y轴,垂直于纵轴指向右侧为x轴,垂直于o-xy平面向上为z轴,通过姿态矩阵转换得到交通标志位置信息在载体本体坐标系中的坐标(xab,yab,zab);
(1.4)建立以相机光心为原点,光轴为z轴的相机坐标系ocb-xcbycbzcb,通过姿态转换矩阵得到交通标志位置信息在相机坐标系ocb-xcbycbzcb的坐标。
进一步的,所述步骤(2)具体如下:
(2.1)根据相机坐标系ocb-xcbycbzcb-图像平面坐标系o-xy转换关系以及相焦距f,获取交通标志在图像平面坐标系o-xy坐标(x,y);
(2.2)根据图像平面坐标系o-xy-像素坐标系ouv-uv关系,利用转换矩阵及相机解像力rex、rey获取交通标志在像素坐标系坐标(u,v)。
进一步的,所述步骤(3)具体如下:
(3.1)以步骤(2)所确定的交通标志在像素坐标系位置为中心,截取给定范围的尺寸,以准确获取交通标志特征。
进一步的,所述步骤(4)具体如下:
(4.1)采用双三次插值算法或其他算法将采集的训练集原始图片尺寸归一化;
(4.2)对归一化后的图片增强对比度,减少光照强度带来的影响;
(4.3)将处理后的图片及标签存储为tfrecord格式;
(4.4)利用深度学习算法对图片进行识别。
进一步的,所述步骤(4.4)具体如下:
(4.4.1)利用深度学习模型对步骤(4.3)所存储的tfrecords数据进行训练;
(4.4.2)计算模型损失函数,该损失函数采用交叉熵损失函数;
(4.4.3)采用梯度下降法结合滑动平均,以损失函数为目标函数进行迭代计算;
(4.4.4)将训练好的模型存储为ckpt模型,迁移到无人车上对步骤(3)所获取的特征图片进行识别。
进一步的,所述步骤(4.4.1)中的深度学习模型优选自alexnet、squeezenet、goolenet、imagenet、fasterr-cnn、r-fcn、yolo卷积神经网络模型。
本发明的有益效果如下:自动驾驶车辆感知系统中,基于视觉的交通标志图像识别是一项关键技术,但是,由于目前硬件计算资源限制和外界光照条件变化对图像质量的影响,在没有先验知识辅助前提下,难以实现交通标志的准确识别和工程化应用。针对这一问题,本发明提出了一种基于传感器融合的图像快速识别方法。将惯导、卫星导航设备、视觉、高精度地图数据融合,对交通标志图像信息预处理,得到目标区域,通过深度学习模型相处理,实现对交通标志信息识别,在不提高计算量基础之上,大幅提高识别精度,同时,由于通过其他传感器获取到目标区域,可以有效降低光线条件对图像识别的影响,因此,本发明模型鲁棒性好、抗干扰性能强,在光线条件复杂的环境中优势更加明显。
附图说明
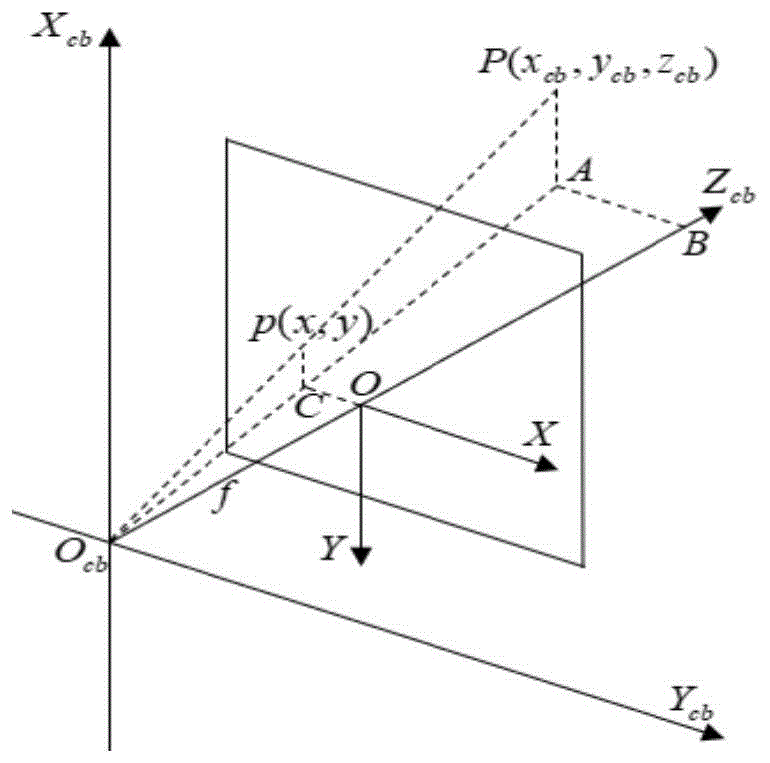
图1为相机坐标系-图像坐标系关系;
图2为图像坐标系-像素坐标系关系;
图3为alexnet网络结构。
具体实施方式
下面通过实施例对本发明做进一步的详细说明。
本发明提供一种基于传感器融合的图像快速识别方法,包括如下步骤:
(1)惯导/高精度地图辅助导航信息解算:
根据惯导和高精度地图,获得车载惯导和交通标志的经度、纬度高、高度信息,通过姿态矩阵转换和坐标变换,得到相机与交通标志的相对位置和姿态关系。当交通标志与相机的距离及与光轴角度满足视觉范围条件时,相机开始工作。
(2)根据相机坐标系与像平面坐标系的关系,获取交通标志在像平面坐标系的位置,并转换成像素坐标系坐标;
(3)训练数据集预处理:对训练数据集进行一系列处理,使其标准化、归一化。
(4)采用机器学习或深度学习模型(本发明以alexnet为例)对步骤(3)处理后的交通标志图像进行训练;
(5)根据步骤(2)获取交通标志在像素坐标系位置为中心,将图片截取为224*224大小,输入到步骤(4)训练好的模型,用来识别交通标志类别。
进一步的,所述步骤(1)具体如下:
(1.1)经纬高与wgs84坐标系转换
假设ha、hs分别代表惯导载体和交通标志的高度;ba、bs分别代表惯导载体和交通标志的经度;la、ls分别代表惯导载体和交通标志的纬度,则惯导载体和交通标志在wgs84地心坐标系下的坐标分别为:
其中
(1.2)wgs84地心坐标系与惯导导航坐标系转换
假设oi-xiyizi为wgs84地心坐标系,oan-xanyanzan为以惯导接收天线为圆点的导航坐标系(东北天),oi-xiyizi到oan-xanyanzan的姿态矩阵
其中λ和
因此交通标志在惯导导航坐标系下的坐标为:
(1.3)惯导导航坐标系与惯导本体坐标系转换
假设oab-xabyabzab为惯导本体坐标系,惯导长轴为y轴,短轴为x轴,原点与惯导导航坐标系oan-xanyanzan重合。oan-xanyanzan到oab-xabyabzab的姿态矩阵
其中φab、θab、γab分别为惯导偏航角、俯仰角和滚转角,由惯导系统输出。
因此求得交通标志在天线本体坐标系下的坐标为:
(1.4)惯导导航坐标系与天线本体坐标系转换
为获取交通标志从惯导本体坐标系oab-xabyabzab到相机本体坐标系ocb-xcbycbzcb的坐标转换关系,需要获取ocb-xcbycbzcb与oab-xabyabzab的三个姿态角和三个平移量。假设:
其中φcb、θcb、γcb、δxcb、δycb、δzcb为相机外参。因此ocb-xcbycbzcb到oab-xabyabzab的姿态转换矩阵
因此求得交通标志在惯导本体坐标系下的坐标为:
进一步的,所述步骤(2)具体如下:
图2为相机坐标系到像平面坐标系的成像投影关系示意图,其中p(x,y)为交通标志p(xcb,ycb,zcb)在像平面坐标系o-xy的投影,f是焦距。根据三角形相似原理,可得:
因此通过式(9)可根据交通标志在相机坐标系的位置求解其在像平面坐标系的位置。
图3为像平面坐标系与像素坐标系的转换关系示意图。像平面坐标系原点o在像素坐标系的位置为(u0,v0),假设相机在水平方向和垂直方向的解像力分别为rex和rey,因此求得交通标志在像素坐标系中的位置为:
式(9)中焦距f与式(10)中u0、v0、rex、rey均为相机内参。
进一步的,所述步骤(4)具体如下:
(4.1)采用双三次插值算法将原始图片尺寸归一化为224*224,便于网络的读取;
(4.2)对归一化后的图片增强对比度,减少光照强度带来的影响;
(4.3)将处理后的图片及标签存储为tfrecord格式,以减少存储空间,加速模型的读写及训练速度。
(4.4)利用深度学习算法对图片进行识别。
进一步的,所述步骤(4.4)具体如下:
(4.4.1)利用深度学习模型(深度学习模型可以采用自alexnet、squeezenet、goolenet、imagenet、fasterr-cnn、r-fcn、yolo卷积神经网络模型等,本实施例中采用alexnet卷积神经网络模型作为示例)对步骤(3)所存储的tfrecords数据进行计算;
(4.4.2)计算模型损失函数,该损失函数采用交叉熵损失函数,具体定义如下:
(4.4.3)采用梯度下降法结合滑动平均,以损失函数为目标函数进行迭代计算;
(4.4.4)将训练好的,模型存储为ckpt模型,迁移到无人车上对步骤(3)所获取的特征图片进行识别,便于持久化和迁移学习。
以上所述仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!