一种基于空间和跨域相关性的感知位置选择方法与流程
本发明涉及信息加工技术领域,具体涉及一种基于空间和跨域相关性的感知位置选择算法。具体地说,为了协调环境监测等应用中数据质量与感知成本二者的关系,分别针对感知数据的空间相关性与跨域相关性进行感知任务位置选择策略的设计,使得在给定成本限定的条件下,获得的数据质量最优。
背景技术:
数据质量和传感成本是环境监测应用的两个重要问题。为了在某个区域获得高质量的传感结果,一个直观的想法是选择更多的传感位置,部署更多的监测站/传感器或招募更多的人群感知参与者,这将导致更高的传感成本。因此,选择要采样的位置可以最准确地估计其他位置的数据是一个挑战。
在传统的监督学习中,标记了训练学习模型所需的数据。通常认为标记的数据越多,标签越精确,并且模型基于训练数据的效率越高。大数据时代为机器学习提供了丰富的原材料来源,使其成为日益重要的角色,并成为最受欢迎的研究领域之一。然而,大数据提供了机遇和严峻挑战,其中最典型的是低质量的数据。手动标记所有数据然后训练模型将耗费大量的人力和资源。不同数据样本对学习模型的贡献是不同的。如果我们可以选择一些最有价值的数据进行标记,则可以仅基于少量数据获得相同的有效模型。要实现这一目标,关键是选择最有价值的数据样本并获取其标签信息。主动学习是研究这个问题的机器学习框架。
由于传统的主动学习算法是基于样本数据是独立且相同分布的假设,而环境监测应用的感知数据一般具有空间相关性和跨域相关性,不能直接应用现有的主动学习算法。因此,我们需要为特定的数据估计算法设计主动采样策略,并使估计算法和主动采样策略之间的最佳拟合。以空气质量为例,空间相关性是指相邻空间中空气质量的相似性。跨域相关性代表气象和交通流量也会影响某个地方的空气质量。现在,在线内容和服务,传感基础设施和其他数据源可以提供丰富的跨域相关信息,从而可以根据某些位置的数据和跨域相关信息推断其他数据。
技术实现要素:
要解决的技术问题
为了协调环境监测等应用中数据质量与感知成本二者的关系,通过采集小部分最有价值的数据,高准确性地推测其余数据,从而以较低感知成本,获得较高的数据质量,本发明提供了一种基于空间和跨域相关性的感知位置选择方法。
技术方案
一种基于空间和跨域相关性的感知位置选择方法,其特征在于步骤如下:
步骤1:利用环境监测站收集污染物浓度信息数据,采集一部分监测站的数据作为标记样本,将数据整理成四元组<监测站id,监测点空间位置,时间,污染指标>的格式;未采集的监测站的数据为未标记样本;使用标记样本对克里金插值模型进行训练,之后对未标记样本进行插值估算;
步骤2:采用下式计算未标记样本的预估误差,将预估误差作为置信度评判的指标:
mse(z0)=σ2{1-rtr-1r+(1-fr-1r)2/ftr-1f}
其中,z0为未标记样本的污染指标估计值,σ2为方差,r称为相关矩阵,由所有已标记样本点之间的半变异函数值组成,r称为相关矢量,由未标记与所有已标记样本点之间的半变异函数值组成,计算公式如下:
f=[1…1]t
γ(xi,xj)为xi与xj之间的半变异函数值,其计算式
其中n是由监测站xi与监测站xj之间的距离分开的成对样本的数量,z(xi)是第i个监测站的污染指标,z(xj)是j个监测站的污染指标;
步骤3:选择预估误差值最大的未标记样本为置信度最低的未标记样本,将其监测站数据加入到插值模型的标记样本集中,同时从未标记样本集中去除该样本;重新训练克里金插值模型,直至满足精度要求、成本要求或数量要求为止;并对未标记样本进行插值估算;
步骤4:对每个监测站点进行建模,具体为以监测站点为中心、半径为30km画圆,并通过指向不同角度的四条线进一步分割为八个区域;然后,根据该站点的地理坐标将其他站点投影到分割的区域,在同一地区汇总跨域数据信息,当一个区域有多个站点时,计算平均数值;因此,每个区域只有一组汇总的跨域数据,将跨域数据输入到回归树模型中训练得到初始模型y,并估算未标记样本的污染指标;
步骤5:将未标记样本添加到标记样本集计算其置信度,当初始模型的均方误差增加且增加的幅度最大或均方误差减少且减少的幅度是最小的,则该样本是最低置信度的未标记样本;所述的置信度计算公式如下:
其中y是初始标记样本的真实污染指标,
重新训练回归树模型,并使用新模型对初始标记样本进行估算;
步骤6:遍历未标记样本集,分别计算v,并选择|v|值最大的未标记样本,主动获取其数据,并将该条数据添加到标记样本集中;重新训练回归树模型,至满足精度要求、成本要求或数量要求为止;并估算未标记样本的污染指标;
步骤7:将步骤3和步骤6分别利用空间和跨域信息生成的估算结果进行存储,最后使用多元回归来动态地整合得到最终的未标记样本估算结果。
有益效果
本发明提出的一种基于空间和跨域相关性的感知位置选择方法,可以更加全面地利用了感知数据的空间相关性与跨域相关性,针对具体的缺失数据推测算法并借鉴经典的主动学习的样例选择策略,进行感知位置选择策略的设计,使两者达到最佳适配。从而协调环境监测等应用中数据质量与感知成本二者的关系,通过采集小部分最有价值的数据,高准确性地推测其余数据,从而以较低感知成本,获得较高的数据质量。
附图说明
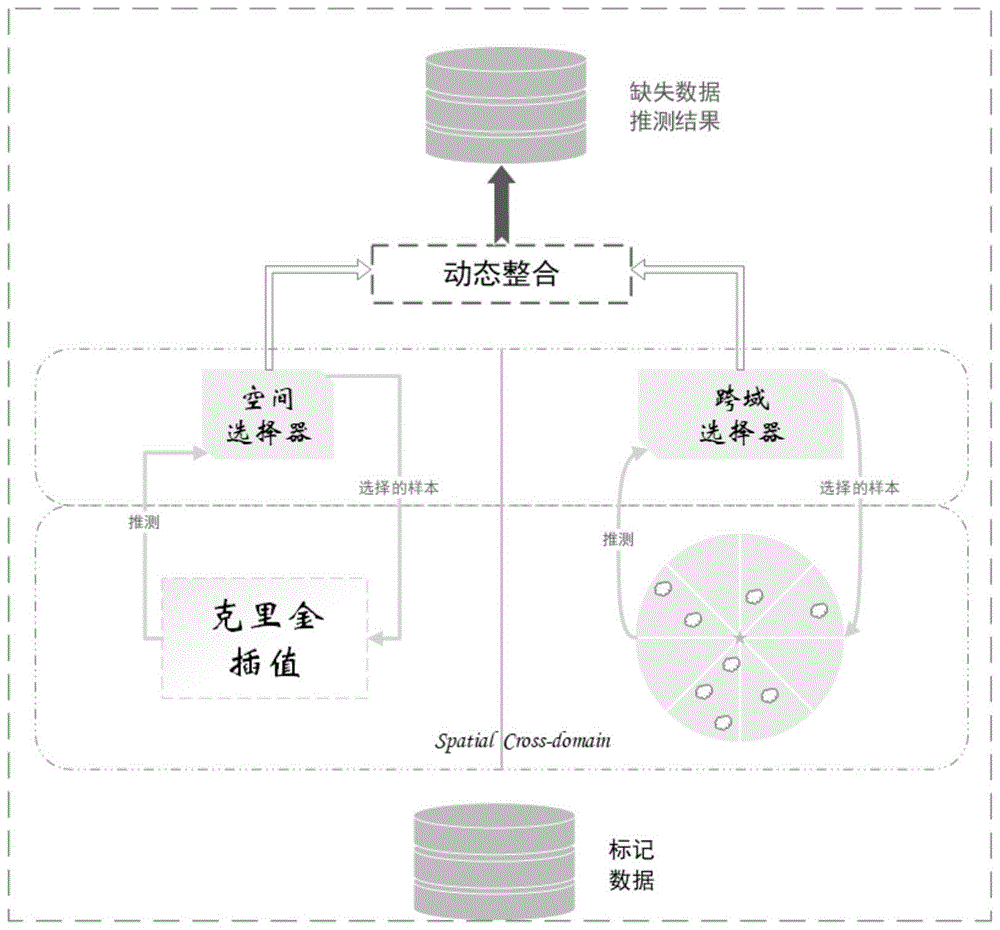
图1为本发明实例中基于空间和跨域相关性的感知位置选择方法整体框架图
图2为基于空间相关性感知位置选择流程图
图3为环境监测站建模图
图4为基于跨域相关性感知位置选择流程图
具体实施方式
现结合实施例、附图对本发明作进一步描述:
本发明首先分别针对空间相关性与跨域相关性对现有的缺失数据推测算法进行适配与改进,然后针对具体的缺失数据推测算法,进行感知任务选择策略的设计(首先设计推测算法标签误差的替代性指标,该指标需能够在真值标签未知时估计不同待标记样例对结果的贡献,然后借鉴经典主动学习的样例选择策略,设计基于样例不确定度或模型不确定度的计算指标),分别实现了利用空间相关性的基于克里金插值的推测器与选择器以及利用跨域相关性的基于回归树的推测器与选择器,最后对空间和跨域信息生成的推测结果进行存储,使用多元回归来动态整合,使得在给定成本限定的条件下,获得的数据质量最优。
参照图1,本发明的具体步骤如下:
步骤1、利用各个城市地区的环境监测站收集环境中污染物浓度信息数据。利用污染物浓度信息数据计算污染指标。
步骤2、将数据整理成四元组<监测站id,监测点空间位置,时间,污染指标>的格式。将监测站分为两部分,收集了数据的监测站为标记样本,其余未收集数据的监测站为未标记样本。使用标记样本对克里金插值模型进行训练,之后对未标记样本进行插值估算。
步骤3、采用以下公式计算对未标记样本的预估误差来作为置信度评判的指标:
mse(z0)=σ2{1-rtr-1r+(1-fr-1r)2/ftr-1f}
其中z0为待标记样本的污染指标估计值,σ2为方差,r称为相关矩阵,由所有已知样本点之间的半变异函数值组成,r称为相关矢量,由未知点与所有已知样本点之间的半变异函数值组成,计算公式如下:
f=[1…1]t
γ(xi,xj)为xi与xj之间的半变异函数值,其计算式为
其中n是由监测站xi与监测站xj之间的距离分开的成对样本的数量,z(xi)是第i个监测站的污染指标,z(xj)是j个监测站的污染指标。
步骤4、直接选择模型对未收集数据的监测站预估值误差最大的点为置信度最低的未标记样本,从插值结果中选择满足置信度要求的未标记样本并主动收集该监测站数据,加入到插值模型的标记样本集中,并从未标记样本集中去除该样本。如图2所示,重新训练克里金插值模型,直至满足精度要求、成本要求或数量要求为止。此时已选取最少的位置进行采样并最大程度准确地推测出了其他位置的污染指标。
步骤5、以空气质量为例,除了相邻位置的空气质量外,位置的空气质量还取决于相关的跨域特性,例如,气象影响一个地方的空气质量。因此可以根据跨域数据估算未标记样本的污染指标。如果直接将所有特征提供给机器学习模型,则随着周围监测站数量的增加,参数的数量将迅速增加,给模型训练和预测带来了麻烦。而且收集到的跨域信息有些是的多余,有时甚至是矛盾的。如果没有适当的聚合,将被混乱的输入相混淆。因此对于跨域数据也要考虑空间相关性。如图3所示,对每个监测站点半径为30km进行建模,并通过指向不同角度的四条线进一步分割为八个区域。然后,根据该站点的地理坐标将其他站点投影到分割的区域。在同一地区汇总跨域数据信息,当一个区域有多个站点时,计算平均数值。因此,每个区域只有一组汇总的跨域数据,这些特征将输入到回归树模型中训练得到初始模型y,并估算未标记样本的污染指标。
步骤6、如果未标记样本中有一个数据,当它被添加到标记样本集时,原始模型的均方误差增加且增加的幅度最大或均方误差减少且减少的幅度是最小的,则该样本是最低置信度的未标记样本,其置信度计算公式如下:
其中y是初始标记样本的真实污染指标,
步骤7、遍历未标记样本集,分别计算v,并选择|v|值最大的未标记样本,主动获取其数据,并将该条数据添加到l=标记样本集。如图4所示,重新训练回归树模型,至满足精度要求、成本要求或数量要求为止。此时已选取最少的位置对跨域数据进行采样并最大程度准确地推测出了未标记样本的污染指标。
步骤8、将分别利用空间和跨域信息生成的推测结果进行存储,最后使用多元回归来动态地整合,最终结果以最少的空间特征采样位置和跨域特征采样位置获得较高精度的未标记样本推测结果。
本发明可以更加全面地利用了感知数据的空间相关性与跨域相关性,针对具体的缺失数据推测算法并借鉴经典的主动学习的样例选择策略,进行感知位置选择策略的设计,使两者达到最佳适配。从而协调环境监测等应用中数据质量与感知成本二者的关系,通过采集小部分最有价值的数据,高准确性地推测其余数据,从而以较低感知成本,获得较高的数据质量。
- 还没有人留言评论。精彩留言会获得点赞!