一种文本图像的公式定位方法、图像处理装置、存储介质与流程
本申请涉及图像处理技术领域,特别是涉及一种文本图像的公式定位方法、图像处理装置、存储介质。
背景技术:
随着移动互联网技术的发展,如智能手机、平板电脑等大量手持移动终端走进我们的生活,成为我们生活中不可或缺的一部分。这些手持终端都拥有摄像功能,这为我们能够随时采集文档信息提供了巨大的便利。
而科学公式作为一种特别的信息载体,也广泛的存在文本文档中。在实际应用中,经常需要对科学公式进行定位提取,如何对文本图像中的公式进行定位成为了亟待解决的问题。
技术实现要素:
为解决上述问题,本申请提供了一种文本图像的公式定位方法、图像处理装置、存储介质,能够准确的对文本图像中的公式进行定位。
本申请采用的一个技术方案是:提供一种文本图像的公式定位方法,该方法包括:获取文本行的文本定位信息和注意力信息;根据文本定位信息和注意力信息,计算文本行的公式坐标集和公式边界集;根据公式坐标集和公式边界集,计算文本行中的公式的定位坐标。
其中,根据文本定位信息和注意力信息,计算文本行的公式坐标集和公式边界集的步骤,包括:根据注意力信息,获取目标文本行中目标特殊字符的注意力信息向量;其中,特殊字符为公式中的字符;判断注意力信息向量中最大值对应的索引值是否为0;若是,则将目标特殊字符的毗邻公式信息加入到公式边界集。
其中,该方法还包括:根据目标文本行的文本定位信息,计算目标文本行的宽度值;根据目标文本行的宽度值、注意力信息向量中最大值对应的索引值,计算目标特殊字符的横坐标值;根据目标特殊字符的横坐标值,确定最大横坐标值和最小横坐标值;根据文本定位信息、最大横坐标值和最小横坐标值,计算公式坐标集。
其中,根据目标文本行的文本定位信息,计算目标文本行的宽度值的步骤,包括:采用以下公式计算目标文本行的归一化宽度值:
其中,根据目标文本行的宽度值、注意力信息向量中最大值对应的索引值,计算目标特殊字符的横坐标值的步骤,包括:采用以下公式计算目标特殊字符的横坐标值:
其中,根据目标特殊字符的横坐标值,确定最大横坐标值和最小横坐标值的步骤,包括:根据所述目标特殊字符的初始横坐标值,确定初始最大横坐标值和初始最小横坐标值;在获取到所述目标特殊字符的新的横坐标值时,比较所述新的横坐标值与所述最大横坐标值和所述最小横坐标值的大小;若所述新的横坐标值小于所述最小横坐标值,则更新所述最小横坐标值;若所述新的横坐标值大于所述最大横坐标值,则更新所述最大横坐标值。
其中,根据文本定位信息、最大横坐标值和最小横坐标值,计算公式坐标集的步骤,包括:采用以下公式计算公式坐标集:
其中,根据公式坐标集和公式边界集,计算文本行中的公式的定位坐标的步骤,包括:判断目标行文本的上一行文本是否在公式边界集中;若是,则判断目标行文本是否有毗邻公式信息;若有,则将目标行文本中的第一个公式坐标与上一行文本的最后一个公式坐标进行融合。
其中,该方法还包括:根据公式坐标集,获取目标公式区域的二值化图像;对二值化图像进行纵坐标投影,以得到目标公式的纵坐标;采用目标公式的纵坐标对公式坐标集进行更新。
本申请采用的另一个技术方案是:提供一种图像处理装置,该图像处理装置包括:获取模块,用于获取文本行的文本定位信息和注意力信息;第一计算模块,用于根据文本定位信息和注意力信息,计算文本行的公式坐标集和公式边界集;第二计算模块,用于根据公式坐标集和公式边界集,计算文本行中的公式的定位坐标。
本申请采用的另一个技术方案是:提供一种图像处理装置,该图像处理装置包括处理器以及存储器,存储器用于存储程序数据,处理器用于执行程序数据以实现如上述的方法。
本申请采用的另一个技术方案是:提供一种计算机存储介质,该计算机存储介质用于存储程序数据,程序数据在被处理器执行时,用以实现如上述的方法。
本申请提供的文本图像的公式定位方法包括:获取文本行的文本定位信息和注意力信息;根据文本定位信息和注意力信息,计算文本行的公式坐标集和公式边界集;根据公式坐标集和公式边界集,计算文本行中的公式的定位坐标。通过上述方式,能够利用注意力信息对文本图像中的公式进行定位,从而为后续的公式识别打下基础,进而能够准确的得到公式的图像。
附图说明
为了更清楚地说明本申请实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。其中:
图1是本申请实施例提供的文本图像的公式定位方法的流程示意图;
图2是本申请实施例提供的文本的第一定位坐标示意图;
图3是本申请实施例提供的获取边界集的流程示意图;
图4是本申请实施例提供的获取公式集的流程示意图;
图5是本申请实施例中确定最大横坐标和最小横坐标的流程示意图;
图6是本申请实施例提供的文本的第二定位坐标示意图;
图7是本申请实施例计算公式定位坐标的流程示意图;
图8是本申请实施例提供的文本图像的公式定位方法的逻辑示意图;
图9是本申请实施例提供的获取公式定位坐标集的逻辑示意图;
图10是本申请实施例提供的公式坐标合并的逻辑示意图;
图11是本申请实施例提供的图像处理装置的第一结构示意图;
图12是本申请实施例提供的图像处理装置的第二结构示意图;
图13是本申请实施例提供的计算机存储介质的结构示意图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述。可以理解的是,此处所描述的具体实施例仅用于解释本申请,而非对本申请的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本申请相关的部分而非全部结构。基于本申请中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
本申请中的术语“第一”、“第二”等是用于区别不同对象,而不是用于描述特定顺序。此外,术语“包括”和“具有”以及它们任何变形,意图在于覆盖不排他的包含。例如包含了一系列步骤或单元的过程、方法、系统、产品或设备没有限定于已列出的步骤或单元,而是可选地还包括没有列出的步骤或单元,或可选地还包括对于这些过程、方法、产品或设备固有的其它步骤或单元。
在本文中提及“实施例”意味着,结合实施例描述的特定特征、结构或特性可以包含在本申请的至少一个实施例中。在说明书中的各个位置出现该短语并不一定均是指相同的实施例,也不是与其它实施例互斥的独立的或备选的实施例。本领域技术人员显式地和隐式地理解的是,本文所描述的实施例可以与其它实施例相结合。
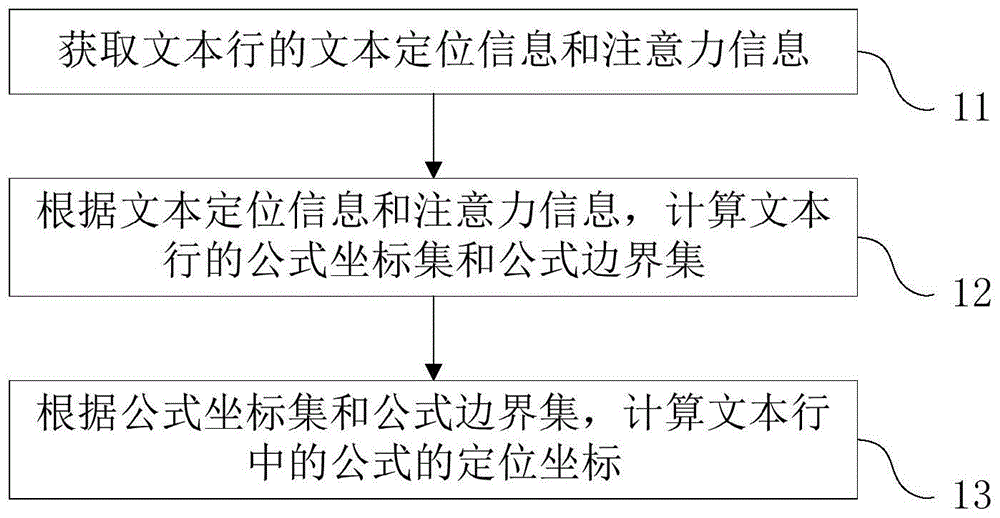
参阅图1,图1是本申请实施例提供的文本图像的公式定位方法的流程示意图,该方法包括:
步骤11:获取文本行的文本定位信息和注意力信息。
文本图像,也叫做文档图像,即图像格式的文档。它是通过某种方式将纸质文档转化为图像格式的文档,以供用户电子阅读。一般的文本图像的格式包括jpg(jpeg)、bmp、png、gif、fsp、tiff、tga、eps等。
可选地,文本定位信息可以是文本的定位坐标。可以理解地,文本一般是以“行”的形式逐行排列,该定位坐标一般是一行文本所在的矩形区域中,左上点和右下点的坐标。
如图2所示,图2是本申请实施例提供的文本的第一定位坐标示意图,其中,a(x1,y1)表示文本行左上角的坐标点,b(x2,y2)表示文本行右下角的坐标点。
在具体的操作中,可以先对文本图像进行灰度处理。
灰度是描述灰度图像内容的最直接的视觉特征。它指黑白图像中点的颜色深度,范围一般从0到255,白色为255,黑色为0,故黑白图像也称灰度图像。灰度图像矩阵元素的取值通常为[0,255],因此其数据类型一般为8位无符号整数,这就是人们通常所说的256级灰度。彩色图像转换为灰度图像时,需要计算图像中每个像素有效的亮度值,其计算公式为:y=0.3r+0.59g+0.11b。
然后,再对文本图像进行去噪声处理。
可选地,可以利用高斯滤波算法对灰度图像进行高斯平滑处理。高斯滤波就是对整幅图像进行加权平均的过程,每一个像素点的值,都由其本身和邻域内的其他像素值经过加权平均后得到。高斯滤波的具体操作是:用一个模板(或称卷积、掩模)扫描图像中的每一个像素,用模板确定的邻域内像素的加权平均灰度值去替代模板中心像素点的值。
其次,再对文本图像进行二值化和反色处理。
图像二值化(imagebinarization)就是将图像上的像素点的灰度值设置为0或255,也就是将整个图像呈现出明显的黑白效果的过程。
反色是与原色叠加可以变为白色的颜色,即用白色(rgb:255,255,255)减去原色的颜色。比如说红色(rgb:255,0,0)的反色是青色(0,255,255)。而对上述步骤34中二值化处理后的图像,即是将灰度值0变为灰度值255,灰度值255变为灰度值0。
最后,可以对文本图像进行边缘计算。
可选地,可以采用canny边缘算法,canny边缘算法的目标是找到一个最优的边缘检测算法,最优边缘检测的含义是:
(1)最优检测:算法能够尽可能多地标识出图像中的实际边缘,漏检真实边缘的概率和误检非边缘的概率都尽可能小;
(2)最优定位准则:检测到的边缘点的位置距离实际边缘点的位置最近,或者是由于噪声影响引起检测出的边缘偏离物体的真实边缘的程度最小;
(3)检测点与边缘点一一对应:算子检测的边缘点与实际边缘点应该是一一对应。
canny边缘算法可以包括以下几个步骤:
(1)找寻图像的强度梯度(intensitygradients);
(2)应用非最大抑制(non-maximumsuppression)技术来消除边误检(本来不是但检测出来是);
(3)应用双阈值的方法来决定可能的(潜在的)边界;
(4)利用滞后技术来跟踪边界。
通过上述的方式对对待校正文本图像进行预处理,则开始获取第一倾斜信息。
可以理解地,通过上述对文本图像的预处理,在通过图像的识别,能够对文本行所在区域的左上角和右下角的点进行识别定位。
ocr(opticalcharacterrecognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程;即,针对印刷体字符,采用光学的方式将纸质文档中的文字转换成为黑白点阵的图像文件,并通过识别软件将图像中的文字转换成文本格式,供文字处理软件进一步编辑加工的技术。
aocr(attentionocr),是一种利用注意力机制对单行文本识别的算法,一般是以cnn(convolutionalneuralnetworks,卷积神经网络)特征作为输入,通过注意力模型对rnn(recurrentneuralnetwork,循环神经网络)的状态和上一状态的注意力权重计算出新一状态的注意力权重。之后将cnn特征和权重输入rnn,通过编码和解码得到结果。
步骤12:根据文本定位信息和注意力信息,计算文本行的公式坐标集和公式边界集。
其中,步骤12可以具体包括两个方面,第一,获取公式边界集;第二,计算公式坐标集。
参阅图3,图3是本申请实施例提供的获取边界集的流程示意图,该方法包括:
步骤31:根据注意力信息,获取目标文本行中目标特殊字符的注意力信息向量;其中,特殊字符为公式中的字符。
可选地,可以对提取的特殊字符进行编码,得到编码特征;对编码特征计算预测概率;使用注意力机制计算不同编码特征的权重,得到编码后的注意力信息向量。
步骤32:判断注意力信息向量中最大值对应的索引值是否为0。
注意力信心向量中按照0,1,2……进行索引排序,其中,若最大值对应的索引值为0,则表示该最大值为向量中的首位,则进一步表示该特殊字符位于文本行的行首。
在步骤32的判断结果为是时,执行步骤33。
步骤33:将目标特殊字符的毗邻公式信息加入到公式边界集。
毗邻公式信息用于表示该殊字符位于文本行的行首,可能上一文本行的行末与该文本行的行首共同形成一个公式。
参阅图4,图4是本申请实施例提供的获取公式集的流程示意图,该方法包括:
步骤41:根据目标文本行的文本定位信息,计算目标文本行的宽度值。
可选地,可以采用以下公式计算目标文本行的宽度值:
其中,w为目标文本行的坐标宽度,h为目标文本行的高度,wm的计算结果是向上取整的,例如wm的计算结果为1.5,那么可以取值为2。
步骤42:根据目标文本行的宽度值、注意力信息向量中最大值对应的索引值,计算目标特殊字符的横坐标值。
可选地,可以采用以下公式计算目标特殊字符的横坐标值:
其中,w为目标文本行的宽度,aidx为注意力信息向量中最大值对应的索引值,wm为目标文本行的宽度值,cw的计算结果是向上取整的。
步骤43:根据目标特殊字符的横坐标值,确定最大横坐标值和最小横坐标值。
可选地,参阅图5,图5是本申请实施例中确定最大横坐标和最小横坐标的流程示意图,该方法包括:
步骤431:根据所述目标特殊字符的初始横坐标值,确定初始最大横坐标值和初始最小横坐标值。
这里的目标特殊字符的横坐标值,即为上述步骤42中计算得到的目标特殊字符的横坐标值cw,这里设最大横坐标值wmax和最小横坐标值wmin。
可选地,可以遍历一次文本行之后得到的目标特殊字符的初始横坐标值,确定初始最大横坐标值和初始最小横坐标值。
步骤432:在获取到所述目标特殊字符的新的横坐标值时,比较所述新的横坐标值与所述最大横坐标值和所述最小横坐标值的大小。
步骤433:若所述新的横坐标值小于所述最小横坐标值,则更新所述最小横坐标值。
若cw比wmin小,则对wmin进行更新,可选地,可以将wmin的值替换为cw的值。
步骤434:若所述新的横坐标值大于所述最大横坐标值,则更新所述最大横坐标值。
若cw比wmax大,则对wmax进行更新,可选地,可以将wmax的值替换为cw的值。
步骤44:根据文本定位信息、最大横坐标值和最小横坐标值,计算公式坐标集。
可选地,可以采用以下公式计算公式坐标集:
其中,x1为公式的横坐标左值,x2为公式的横坐标右值,y1为公式的纵坐标上值,y2为公式的纵坐标下值,bi0为文本定位信息中的横坐标左值,bi1为文本定位信息中的横坐标右值,bi2为文本定位信息中的纵坐标上值,bi3为文本定位信息中的纵坐标下值,wmin为最小横坐标值,wmax为最大横坐标值。
步骤13:根据公式坐标集和公式边界集,计算文本行中的公式的定位坐标。
参阅图6,图6是本申请实施例提供的文本的第二定位坐标示意图,可以理解地,在一些实施例中,需要定位的公式可能不在同一个文本行,例如公式的前一部分位于上一文本行,公式的下一部分位于下一文本行。如图6所示,“示例性文本”中的“示例性”在上一行,“文本”在下一行。
可选地,如图7所示,图7是本申请实施例计算公式定位坐标的流程示意图,该方法包括:
步骤71:判断目标行文本的上一行文本是否在公式边界集中。
在步骤71的判断结果为是时,执行步骤72。
可以理解地,通过步骤71的判断过程,可以知道上一行文本中是否有位于行首或者行尾的公式,这样就有可能与本行的公式是同一个公式。
步骤72:判断目标行文本是否有毗邻公式信息。
其中,该毗邻公式信息是上述步骤33中添加的毗邻公式信息。
在步骤72的判断结果为是时,执行步骤73。
步骤73:将目标行文本中的第一个公式坐标与上一行文本的最后一个公式坐标进行融合。
如图6所示,“示例性文本”中的“示例性”的左上坐标为c(x3,y3),右下坐标为d(x4,y4),“文本”的左上坐标为e(x5,y5),右下坐标为f(x6,y6)。那么,可以根据对坐标进行合并得到整个公式的坐标。
另外,在坐标计算的过程中,可以对纵坐标进行更新,具体为:根据公式坐标集,获取目标公式区域的二值化图像;对二值化图像进行纵坐标投影,以得到目标公式的纵坐标;采用目标公式的纵坐标对公式坐标集进行更新。
区别于现有技术,本实施例提供的文本图像的公式定位方法包括:获取文本行的文本定位信息和注意力信息;根据文本定位信息和注意力信息,计算文本行的公式坐标集和公式边界集;根据公式坐标集和公式边界集,计算文本行中的公式的定位坐标。通过上述方式,能够利用注意力信息对文本图像中的公式进行定位,从而为后续的公式识别打下基础,进而能够准确的得到公式的图像。
下面通过几个详细的步骤对上述实施例进行介绍:
参阅图8,图8是本申请实施例提供的文本图像的公式定位方法的逻辑示意图,该方法包括:
步骤81:输入含公式的文本图像s,每行文本的定位坐标信息集b,aocr对每行文本的识别信息集t,以及每行文本的注意力信息集a。
步骤82a:从t中获取第i行文本信息ti。
步骤82b:对图像s进行二值化得到二值化图像st。
其中,步骤82a和步骤82b可同时执行,也可分先后执行。
步骤83:判断ti文本字符的是否有数学关键字。若是,则执行步骤84,若否,则回到步骤82a。
步骤84:从a中获取对应的注意力信息ai。
步骤85:根据ti、ai以及对应的文本定位坐标信息bi得到第i行文本的公式坐标集ab、公式边界集fb以及对应编号k。
步骤86:利用ab、fb、k和st计算出该行存在的公式定位坐标。
步骤87:输出所有公式集fbl。
参阅图9,图9是本申请实施例提供的获取公式定位坐标集的逻辑示意图,该方法包括:
步骤901:寻找ti的所有数学关键字符。
步骤902:以数学关键字符为中心,向左右搜寻所有非汉字字符,获取对应编号集fs。
步骤903:计算该行文本的宽w和高h,并把宽归一化为wm,设定最小横坐标值wmin和最大横坐标值wmax。
步骤904:遍历fs得到对应的编号fs,提取与fs对应的ai的注意力信息向量a。
步骤905:获取a中最大值对应的索引aidx,并计算出横坐标值cw。
步骤906:查询aidx是否在首位。若是,则执行步骤907,若否,则执行步骤908。
步骤907:将毗邻公式信息加入到fb对应位置中,保留第i行文本对应的编号k。
步骤908:判断cw是否比wmin小。若是,则执行步骤909,若否则执行步骤910。
步骤909:采用cw更新wmin。
步骤910:判断cw是否比wmax大。若是,则执行步骤911,若否则执行步骤912。
步骤911:采用cw更新wmax。
步骤912:返回步骤904,直到fs都处理完。
步骤913:计算当前公式ab,并加入到公式坐标集ab中。
参阅图10,图10是本申请实施例提供的公式坐标合并的逻辑示意图,该方法包括:
步骤101:从ab中获取第j条公式坐标,并从st中截取临时二值化图像tt。
步骤102:利用投影法对tt进行纵坐标投影,得到实际纵坐标,更新第j条公式的纵坐标。
步骤103:返回步骤101,直到左右公式坐标全部处理完,执行下一步。
步骤104:判断k-1编号对应的fb是否存在。若是,则执行步骤105,若否,则执行步骤107。
步骤105:判断第k个fb是否有毗邻公式信息。若是,则执行步骤106,若否,则执行步骤107。
步骤106:把fbl中最后一个公式坐标与当前ab的第一条公式坐标融合成新的公式坐标,并替换fbl中最后一个公式坐标,ab中剩余的公式也加入到fbl中。
步骤107:把当前对应的ab公式坐标集加入到公式集fbl中。
步骤108:输出该行文本的公式坐标集fbl。
可以理解地,上述的逻辑步骤是建立在上述实施例的基础上,其原理和计算方式类似,这里不再赘述。
参阅图11,图11是本申请实施例提供的图像处理装置的第一结构示意图,该图像处理装置110包括获取模块111、第一计算模块112和第二计算模块113。
其中,获取模块111用于获取文本行的文本定位信息和注意力信息;第一计算模块112用于根据文本定位信息和注意力信息,计算文本行的公式坐标集和公式边界集;第二计算模块113用于根据公式坐标集和公式边界集,计算文本行中的公式的定位坐标。
参阅图12,图12是本申请实施例提供的图像处理装置的第二结构示意图,该图像处理装置120包括处理器121以及存储器122,存储器122用于存储程序数据,处理器121用于执行程序数据以实现如下的方法:
获取文本行的文本定位信息和注意力信息;根据文本定位信息和注意力信息,计算文本行的公式坐标集和公式边界集;根据公式坐标集和公式边界集,计算文本行中的公式的定位坐标。
可选地,处理器121还用于执行程序数据以实现如下的方法:根据注意力信息,获取目标文本行中目标特殊字符的注意力信息向量;其中,特殊字符为公式中的字符;判断注意力信息向量中最大值对应的索引值是否为0;若是,则将目标特殊字符的毗邻公式信息加入到公式边界集。
可选地,处理器121还用于执行程序数据以实现如下的方法:根据目标文本行的文本定位信息,计算目标文本行的宽度值;根据目标文本行的宽度值、注意力信息向量中最大值对应的索引值,计算目标特殊字符的横坐标值;根据目标特殊字符的横坐标值,确定最大横坐标值和最小横坐标值;根据文本定位信息、最大横坐标值和最小横坐标值,计算公式坐标集。
可选地,处理器121还用于执行程序数据以实现如下的方法:采用以下公式计算目标文本行的归一化宽度值:
可选地,处理器121还用于执行程序数据以实现如下的方法:采用以下公式计算目标特殊字符的横坐标值:
可选地,处理器121还用于执行程序数据以实现如下的方法:根据所述目标特殊字符的初始横坐标值,确定初始最大横坐标值和初始最小横坐标值;在获取到所述目标特殊字符的新的横坐标值时,比较所述新的横坐标值与所述最大横坐标值和所述最小横坐标值的大小;若所述新的横坐标值小于所述最小横坐标值,则更新所述最小横坐标值;若所述新的横坐标值大于所述最大横坐标值,则更新所述最大横坐标值。
可选地,处理器121还用于执行程序数据以实现如下的方法:采用以下公式计算公式坐标集:
可选地,处理器121还用于执行程序数据以实现如下的方法:判断目标行文本的上一行文本是否在公式边界集中;若是,则判断目标行文本是否有毗邻公式信息;若有,则将目标行文本中的第一个公式坐标与上一行文本的最后一个公式坐标进行融合。
可选地,处理器121还用于执行程序数据以实现如下的方法:根据公式坐标集,获取目标公式区域的二值化图像;对二值化图像进行纵坐标投影,以得到目标公式的纵坐标;采用目标公式的纵坐标对公式坐标集进行更新。
参阅图13,图13是本申请实施例提供的计算机存储介质的结构示意图,该计算机存储介质130中存储有程序数据131,该程序数据131在被处理器执行时,用以实现如下的方法:
获取文本行的文本定位信息和注意力信息;根据文本定位信息和注意力信息,计算文本行的公式坐标集和公式边界集;根据公式坐标集和公式边界集,计算文本行中的公式的定位坐标。
在本申请所提供的几个实施方式中,应该理解到,所揭露的方法以及设备,可以通过其它的方式实现。例如,以上所描述的设备实施方式仅仅是示意性的,例如,所述模块或单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施方式方案的目的。
另外,在本申请各个实施方式中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
上述其他实施方式中的集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)或处理器(processor)执行本申请各个实施方式所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,read-onlymemory)、随机存取存储器(ram,randomaccessmemory)、磁碟或者光盘等各种可以存储程序代码的介质。
以上所述仅为本申请的实施方式,并非因此限制本申请的专利范围,凡是根据本申请说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本申请的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!