云平台任务最大资源使用率预测方法与流程
本发明涉及云计算领域,尤其涉及云平台中一种任务最大资源使用率预测方法。
背景技术:
虽然云计算提供了便捷灵活的资源管理方式,但是现有大多数云平台的资源使用率依然较为低下,比如,twitter云平台千台服务器在一个月内的总cpu使用率始终低于20%,然而预留的资源却达到了总资源的80%;google云平台cpu平均使用率在10%~45%之间波动。预测任务的资源使用状况是提高云平台资源使用率的重要手段之一。但是云平台任务资源使用的动态性、不确定性和突变性使得预测工作变得困难。现有的大部分相关研究都是基于仿真数据而展开的,最终的实验结果缺乏有效的说服性。而针对真实云平台数据集,目前已提出了利用反向传播神经网络模型、随机森林回归模型(breimanl.randomforests[j].machinelearning,2001,45(1):5-32)进行任务负载预测,但是由于这些模型没有充分考虑到云平台任务资源使用的特点,造成预测的性能有待进一步提高。
稀疏自编码模型(andrewng."sparseautoencoder."cs294alecturenotes72.2011(2011):1-19.)可以自动从无标签样本数据中学习特征,可以进一步提升预测模型的准确度。k-medoids聚类方法(parkhs,junch.asimpleandfastalgorithmfork-medoidsclustering[j].expertsystemswithapplications,2009,36(2):3336-3341.)以样本中的数据为中心,对样本中的异常值具有较好的鲁棒性。
技术实现要素:
本发明的目的在于提供一种具有较低的平均绝对误差和较低的改进平均绝对百分比误差的云平台任务最大资源使用率预测方法。
改进的平均绝对百分比误差公式如下所示:
其中,
r表示测试样本数量,a1和a2是两个实参数,且a1<a2,hi表示测试样本集中样本i的目标真实值,hi表示测试样本集中样本i的目标预测值。
为解决上述问题,本发明的云平台任务最大资源使用率预测方法采用了如下技术方案:
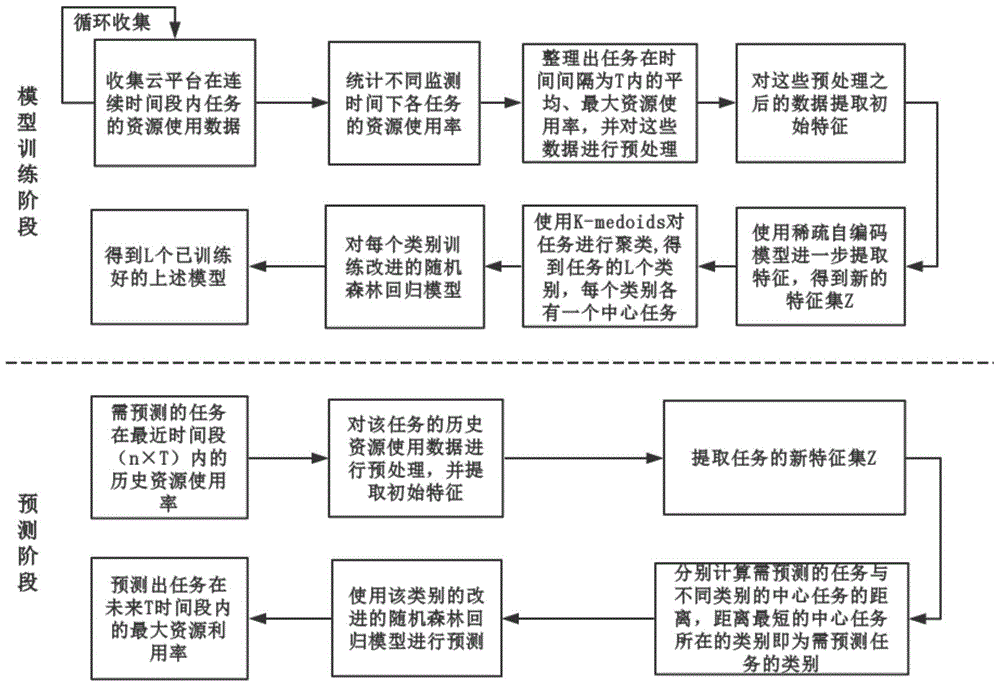
云平台任务最大资源使用率预测方法,包括如下步骤:
s1、先对云平台任务资源使用状况历史数据集中缺失的数据进行填充,然后统计各任务在时间间隔为t内的平均资源使用率和最大资源使用率,其中,平均资源使用率包括平均cpu使用率、平均内存使用率,最大资源使用率包括最大cpu使用率、最大内存使用率;
s2、使用n个连续计时周期,每个计时周期时长为t,基于n个计时周期内任务的最大资源使用率提取任务的加权最大资源使用率和最大资源使用率的公平性指数,其中,加权最大资源使用率包括加权最大cpu使用率、加权最大内存使用率,最大资源使用率的公平性指数包括最大cpu使用率公平性指数、最大内存使用率公平性指数;
s3、将上述n个计时周期内的平均资源使用率和最大资源使用率、基于n个周期的加权最大资源使用率和最大资源使用率的公平性指数、任务的优先级作为样本的特征集z’,并将每个特征在所有任务中的最大值保持在mi中,i为特征的序号且mi≠0,接着对所有任务的每个特征各自进行归一化处理,然后将其结果作为样本的初始数据集;
s4、基于上述样本的特征集和初始数据集,使用稀疏自编码模型进一步提取任务特征,得到新的特征集z={z1,z2,…,zf},结合各任务的这些特征值以及第(n+1)个计时周期内的最大cpu使用率或者最大内存使用率得到新的样本数据集d,其中,第(n+1)个计时周期内的最大cpu使用率或者最大内存使用率是样本的目标变量;
s5、基于步骤s4中得到的样本数据集d,使用k-medoids聚类算法将任务分成l类,得到l个样本数据子集,每一类别都有一个中心任务ci,i=1,2,…,l;
s6、按照一定比例(b1:b2)将每一类样本数据子集分成训练集和测试集两个部分,其中b1、b2为正实数,且b1>b2;这样,就得到l个训练集和测试集的组合;
s7、基于每一类样本数据子集中的训练集数据,使用改进的随机森林回归模型进行训练,得到l个已训练好的改进的随机森林回归模型;
s8、基于对应的测试集数据,使用改进的平均绝对百分比误差对已训练好的改进的随机森林回归模型进行性能评价,改进的平均绝对百分比误差公式如下所示:
其中,
r表示测试样本数量,a1和a2是两个正实参数,且a1<a2,hi表示测试样本集中样本i的目标真实值,hi表示测试样本集中样本i的目标预测值;
s9、给定需预测的任务在最近连续时间段(n×t)内等距离监测点下的最大资源使用率和平均资源使用率,确定该任务的类别;
s10、使用步骤9得到的任务类别对应的已经训练好的改进的随机森林回归模型,对任务进行预测。
进一步的,步骤s1具体包括:
s10:对于云平台任务资源使用状况历史数据集中的缺失数据,先进行填充;
s11:计算时间段t内k个等距离监测点下的任务的平均cpu使用率的算术平均值,作为该时间段t内的任务的平均cpu使用率;
s12:计算时间段t内k个等距离监测点下的任务的平均内存使用率的算术平均值,作为该时间段t内的任务的平均内存使用率;
s13:从时间段t内k个等距离监测点下的任务的最大cpu使用率中取最大值,作为该时间段t内的任务的最大cpu使用率;
s14:从时间段t内k个等距离监测点下的任务的最大内存使用率中取最大值,作为该时间段t内的任务的最大内存使用率。
进一步的,步骤s2具体包括:
s20:基于步骤s1得到的任务在时间段(n×t)内的n个最大cpu使用率,计算任务的加权最大cpu使用率;
s21:基于步骤s1得到的任务在时间段(n×t)内的n个最大内存使用率,计算任务的加权最大内存使用率;
s22:基于步骤s1得到的任务在时间段(n×t)内的n个最大cpu使用率,计算任务的最大cpu使用率的公平性指数;
s23:基于步骤s1得到的任务在时间段(n×t)内的n个最大内存使用率,计算任务的最大内存使用率的公平性指数;
进一步的,步骤s7具体包括:
s70:使用以下的函数作为改进的随机森林回归模型特征值对选择函数:
其中,
其中,xm是当前训练样本集合,nm是当前训练样本集合包含的样本数,i为样本集合中一个样本的编号,k1和k2是两个正实参数,且k1<k2;yi是样本i的目标值,
s71:基于步骤s6得到的每一个训练集,分别使用步骤s70所述的改进的随机森林回归模型进行训练,得到l个不同的改进的随机森林回归模型。
进一步的,步骤s9具体包括:
s90:对于任务在最近连续时间段(n×t)内的最大资源使用率和平均资源使用率,如果存在缺失数据,先进行填充,然后,统计该任务在时间间隔为t内的平均资源使用率和最大资源使用率;
s91:使用步骤s2所述方法,计算该任务的加权最大资源使用率和最大资源使用率的公平性指数;
s92:将步骤3的z’作为该任务的初始特征集,使用步骤3得到的mi对这些特征值各自进行归一化处理;
s93:以步骤4得到的新特征集z={z1,z2,…,zf},作为该任务的新特征集;
s94:基于任务的新特征值,计算该任务分别与步骤5得到的各类中心任务ci的距离,i=1,2,…,l,该任务距离最近的中心任务所在的类别,即为该任务所属的类别。
进一步的,步骤s10具体包括:
s100:根据步骤s9得到的任务类别,选择对应的已训练好的改进随机森林回归模型;
s101:将该任务的新特征值,作为步骤s100确定的改进随机森林回归模型的输入,即可得到任务在未来t时间段内的最大cpu使用率或者最大内存使用率。
本发明云平台任务最大资源使用率预测方法,基于云平台的任务资源使用历史信息,通过上述步骤,较为准确地预测出云平台任务的最大资源使用率,该预测方法具有较低的平均绝对误差和较低的改进平均绝对百分比误差,并为资源的有效管理和调度提供了重要信息。
附图说明
图1为本发明云平台任务最大资源使用率预测方法的处理流程图。
具体实施方式
为了进一步理解本发明,下面结合实施例对本发明优选实施方案进行描述,但是应当理解,这些描述只是为进一步说明本发明的特征和优点,而不是对本发明权利要求的限制。
本发明的基本思想是:首先,对云平台任务的资源使用历史数据进行预处理,将根据云平台任务的资源使用特点提取的任务特征通过稀疏自编码模型进一步提取特征;然后,使用k-medoids聚类算法对任务进行聚类;接着,使用改进的随机森林回归模型分别对不同的样本训练集进行训练,训练完成后,用改进的平均绝对百分比误差评价已训练好的随机森林回归模型的性能;最后,根据要预测任务的类别,选择对应的已训练好的随机森林回归模型来预测任务的最大资源使用率。
为了实现上述方案,在一个实施例中,本发明的方法采用了如下步骤:
步骤1:先对云平台任务资源使用状况历史数据集中缺失的数据进行填充,然后统计各任务在时间间隔为60分钟内的平均资源使用率和最大资源使用率,其中,平均资源使用率包括平均cpu使用率、平均内存使用率,最大资源使用率包括最大cpu使用率、最大内存使用率;
具体步骤如下:
步骤1.1:对于云平台任务资源使用状况历史数据集中的缺失数据,采用向前填充的方法;
步骤1.2:计算60分钟内12个等距离监测点下的任务的平均cpu使用率的算术平均值,作为该60分钟内的任务的平均cpu使用率;
步骤1.3:计算60分钟内12个等距离监测点下的任务的平均内存使用率的算术平均值,作为该60分钟内的任务的平均内存使用率;
步骤1.4:从60分钟内12个等距离监测点下的任务的最大cpu使用率中取最大值,作为该60分钟内的任务的最大cpu使用率;
步骤1.5:从60分钟内12个等距离监测点下的任务的最大内存使用率中取最大值,作为该60分钟内的任务的最大内存使用率;
步骤2:使用6个连续计时周期,每个计时周期时长为60分钟,基于6个计时周期内任务的最大资源使用率提取任务的加权最大资源使用率和最大资源使用率的公平性指数,其中,加权最大资源使用率包括加权最大cpu使用率、加权最大内存使用率,最大资源使用率的公平性指数包括最大cpu使用率的公平性指数、最大内存使用率的公平性指数;
具体步骤如下:
步骤2.1:基于步骤1得到的任务在连续360分钟内的6个最大cpu使用率,计算任务的加权最大cpu使用率g1(x),相应的计算公式如下所示:
其中,x1、x2、…、x6分别表示按时间先后次序排列的最大cpu使用率;
步骤2.2:基于步骤1得到的任务在连续360分钟内的6个最大内存使用率,计算任务的加权最大内存使用率g2(x),相应的计算公式如下所示:
其中,x1、x2、…、x6分别表示按时间先后次序排列的最大内存使用率;
步骤2.3:基于步骤1得到的任务在连续360分钟内的6个最大cpu使用率,计算任务的最大cpu使用率的公平性指数f1(x),相应的计算公式如下所示:
其中,x1、x2、…、x6分别表示按时间先后次序排列的最大cpu使用率;
步骤2.4:基于步骤1得到的任务在连续360分钟内的6个最大内存使用率,计算任务的最大内存使用率的公平性指数f2(x),相应的计算公式如下所示:
其中,x1、x2、…、x6分别表示按时间先后次序排列的最大内存使用率;
步骤3:在预测任务的最大cpu使用率时,将上述6个计时周期内的平均cpu使用率和最大资源使用率、基于6个周期的加权最大cpu使用率和最大cpu使用率的公平性指数、任务的优先级作为样本的特征集z’,而在预测任务的最大内存使用率时,将上述6个计时周期内的平均内存使用率和最大资源使用率、基于6个周期的加权最大内存使用率和最大内存使用率的公平性指数、任务的优先级作为样本的特征集z’,并将每个特征在所有任务中的最大值保持在mi中,i为特征的序号且mi≠0,接着对所有任务的每个特征各自进行归一化处理,然后将其结果作为样本的初始数据集;
步骤4:基于上述样本的特征集和初始数据集,使用稀疏自编码模型进一步提取任务特征,得到新的特征集z={z1,z2,…,zf},结合各任务的这些特征值以及第7个计时周期内的最大cpu使用率或者最大内存使用率得到新的样本数据集d,其中,第7个计时周期内的最大cpu使用率或者最大内存使用率是样本的目标变量;
步骤5:基于步骤4中得到的样本数据集d,使用k-medoids聚类算法将任务分成4类,得到4个样本数据子集,每一类别都有一个中心任务ci,i=1,2,…,4,两个任务之间的距离计算采用动态时间规整算法;
步骤6:按照(8:2)的比例将每一类样本数据子集分成训练集和测试集两个部分,这样,就得到4个训练集和测试集的组合;
步骤7:基于每一类样本数据子集中的训练集数据,使用改进的随机森林回归模型进行训练,得到4个已训练好的改进的随机森林回归模型;
具体步骤如下:
步骤7.1:使用以下的函数作为改进的随机森林回归模型特征值对选择函数:
其中,
其中,xm是当前训练样本集合,nm是当前训练样本集合包含的样本数,i为样本集合中一个样本的编号;yi是样本i的目标值,
步骤7.2:基于步骤6得到的每一个训练集,分别使用步骤7.1所述的改进的随机森林回归模型进行训练,得到4个不同的改进的随机森林回归模型。
步骤8:基于对应的测试集数据,使用改进的平均绝对百分比误差对已训练好的改进的随机森林回归模型进行性能评价,改进的平均绝对百分比误差公式如下所示:
其中,
r表示测试样本数量,hi表示测试样本集中样本i的目标真实值,hi表示测试样本集中样本i的目标预测值;
步骤9:给定需预测的任务在最近连续360分钟内等距离监测点下的最大资源使用率和平均资源使用率,确定该任务的类别;
具体步骤如下:
步骤9.1:对于任务在最近连续360分钟内的最大资源使用率和平均资源使用率,如果存在缺失数据,先进行填充,然后,统计该任务在连续60分钟内的平均资源使用率和最大资源使用率;
步骤9.2:使用步骤2所述方法,计算该任务的加权最大资源使用率和最大资源使用率的公平性指数;
步骤9.3:将步骤3的z’作为该任务的初始特征集,使用步骤3得到的mi对这些特征值各自进行归一化处理;
步骤9.4:以步骤4得到的新特征集z={z1,z2,…,zf},作为该任务的新特征集;
步骤9.5:基于任务的新特征值,计算该任务分别与步骤5得到的各类中心任务ci的距离,i=1,2,…,4,该任务距离最近的中心任务所在的类别,即为该任务所属的类别;
步骤10:使用步骤9得到的任务类别对应的已经训练好的改进的随机森林回归模型,对任务进行预测。
具体步骤如下:
步骤10.1:根据步骤9得到的任务类别,选择对应的已训练好的改进随机森林回归模型;
步骤10.2:将该任务的新特征值,作为步骤10.1确定的改进随机森林回归模型的输入,即可得到任务在未来60分钟内的最大cpu使用率或者最大内存使用率。
以上实施例的说明只是用于帮助理解本发明的方法及其核心思想。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干改进和修饰,这些改进和修饰也落入本发明权利要求的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!