基于深度特征自适应相关滤波的目标跟踪方法与流程
本发明属于图像处理技术领域,更进一步涉及目标跟踪技术领域中的一种基于深度特征自适应相关滤波的目标跟踪方法。本发明可用于对视频监控、机器人导航和定位、无人驾驶机获取的视频序列中的运动目标进行跟踪。
背景技术:
运动目标跟踪的主要任务是,从连续的视频图像序列中检测出运动目标,进而在每一帧图像中确定出运动目标的位置。随着人们对目标跟踪领域的不断深入认识,运动目标跟踪在该领域得到广泛应用和发展,目前已经存在大量的跟踪算法来实现运动目标跟踪。但是,由于遮挡、背景杂乱、外观形变、光照变化、视角变化等客观因素的影响,使得准确地跟踪目标仍然面临极大挑战。
南京邮电大学在其申请的专利文献“一种基于kcf的改进型抗遮挡目标跟踪方法”(专利申请号2017105998427,公开号107657630a)中公开了一种基于kcf的改进型抗遮挡目标跟踪方法。该方法实现的具体步骤是,(1)针对目标尺寸变换问题,建立三个线程,三个线程分别检测待跟踪目标的三个尺度图像,从而自动确定目标尺寸;(2)针对目标遮挡问题,设置预设阈值,判定目标发生严重遮挡时,使用卡尔曼滤波器的预测结果作为目标位置,反之使用kcf跟踪器的预测结果作为目标位置。该方法存在的不足之处是,因为该方法要判定目标是否发生严重遮挡,判定值阈值设置过高或过低导致判定是否遮挡出错,从而当目标发生遮挡、目标模糊时无法实现准确地跟踪。
中国人民解放军理工大学在其申请的专利文献“一种尺度自适应的相关滤波对冲目标跟踪方法”(专利申请号2017100639095,公开号107016689a)中公开了一种尺度自适应的相关滤波对冲目标跟踪方法。该方法实现的具体步骤是,(1)确定视频帧中的待跟踪目标的初始位置和初始尺度,以初始位置为中心,利用深度卷积神经网络分别提取不同层的卷积特征图;(2)对每一层提取的卷积特征图,利用核相关滤波跟踪方法进行跟踪得到跟踪结果;(3)利用自适应对冲算法将所有的跟踪结果组合得到一个最终跟踪结果,作为待跟踪目标的最终位置,以定位视频帧中待跟踪目标;(4)获得待跟踪目标的最终位置后,利用尺度金字塔策略估计待跟踪目标的最终尺度;(5)得到的待跟踪目标的最终位置和最终尺度后,以最终位置为中心,根据最终尺度提取所述待跟踪目标图像块,来重新训练每个核相关滤波跟踪方法,以更新系数和模板。该方法存在的不足之处是,因为该方法先获得待跟踪目标的最终位置再估计待跟踪目标的最终尺度,从而当目标尺度发生变化时,导致每一帧目标跟踪位置不准确,当目标发生形变时无法实现准确地跟踪。
技术实现要素:
本发明的目的是针对上述现有技术的不足,提出一种基于深度特征自适应相关滤波的目标跟踪方法,来解决当目标产生形变、尺度变化或遮挡时无法实现对目标进行准确、有效跟踪的问题。
实现本发明目的的思路是,首先,利用卷积神经网络vgg-net当中的第10、11、12、14、15、16层的输出结果提取待跟踪目标候选区域每个层的特征,其次,分别经过自适应相关滤波器学习得到每个层的特征响应矩阵,最后,对所得到的6个特征响应矩阵加权求和得到最终的特征响应矩阵,从而得到待跟踪目标的位置。
本发明的具体步骤如下:
(1)确定待跟踪目标的初始位置:
(1a)输入含有待跟踪目标的彩色视频图像序列中的第一帧视频图像;
(1b)用第一帧视频图像中待跟踪目标的初始位置和初始位置对应目标的长度和宽度确定一个跟踪目标矩形框,用该矩形框标出第一帧视频图像中的待跟踪目标;
(2)提取第一帧图像的特征:
(2a)在第一帧视频图像中,以待跟踪目标的初始位置为中心,待跟踪目标矩形框长度和宽度均为2.5倍确定一个候选区域矩形框,用该矩形框标出第一帧视频图像中的候选区域图像;
(2b)将候选区域图像输入到训练好的卷积神经网络vgg-net中,分别从卷积神经网络vgg-net的第10、11、12、14、15、16层输出与每层对应的6个图像特征;
(3)利用自适应相关滤波公式,计算自适应相关滤波器参数,生成每个图像特征的第一帧自适应相关滤波器模型;
(4)预测下一帧帧图像的目标位置:
(4a)输入待跟踪视频序列中下一帧彩色视频图像,作为当前帧图像,在当前帧图像中,以上一帧图像待跟踪目标的位置为中心,取出与待跟踪目标的位置相同的,长度和宽度分别是待跟踪目标矩形框长度和宽度均为2.5倍的矩形框,将该矩形框作为当前帧图像的候选区域;
(4b)采用与步骤(2b)相同的方法,得到当前帧图像的候选区域图像对应的6个图像特征;
(4c)按照下式,计算每个图像特征的特征响应矩阵:
其中,rn表示第n个图像特征对应的特征响应矩阵,f-1(·)表示快速傅里叶逆变换操作,f(·)表示快速傅里叶变换操作,
(4d)按照下式,计算当前帧图像的特征响应矩阵:
r=r1+0.2r2+0.2r3+0.02r4+0.03r5+0.01r6
其中,r表示当前帧图像的特征响应矩阵;
(4e)选取当前帧图像的特征响应矩阵中元素的最大值,将该最大值元素的位置作为当前帧图像的待跟踪目标的目标框中心点的位置;
(5)按照下式,更新每个图像特征对应的自适应相关滤波器参数:
其中,wi表示第i个图像特征对应的自适应相关滤波器参数,argmin表示求函数参数的最小值操作,||·||表示求2范数操作,zi表示第i个图像特征,i=1,2,3,4,5,6,yn表示在训练卷积神经网络vgg-net时所使用的训练集中第n个训练样本对应的特征响应,λ1表示取值为1的正则化参数,λ2表示取值为0.5的自适应参数,y0表示假想先验矩阵;
(6)利用标准无参数对冲算法,更新当前帧每个图像特征对应的自适应相关滤波器的权值;
(7)判断当前帧视频图像是否为待跟踪视频图像序列的最后一帧视频图像,若是,则执行步骤(8),否则,执行步骤(4);
(8)结束对待跟踪目标的跟踪。
本发明与现有技术相比具有以下优点:
第一,由于本发明通过分别计算6个图像特征的每个特征响应矩阵,得到当前帧图像的特征响应矩阵,从中选取当前帧图像的特征响应矩阵中元素的最大值,将该最大值元素的位置作为当前帧图像的待跟踪目标的目标框中心点的位置,克服了现有技术中先获得待跟踪目标的最终位置再估计待跟踪目标的最终尺度,从而当目标尺度发生变化时,导致每一帧目标跟踪位置不准确,当目标发生形变时无法实现准确地跟踪的缺点,使得本发明能够更准确、快速地预测待跟踪目标的位置。
第二,由于本发明采用自适应相关滤波器,使得目标响应不仅取决于训练模板的外观信息,还必须考虑到先前的目标运动信息,克服了现有技术中当目标发生遮挡、目标模糊时无法实现准确地跟踪的缺点,使得本发明增强了目标跟踪的准确性和可靠性。
附图说明
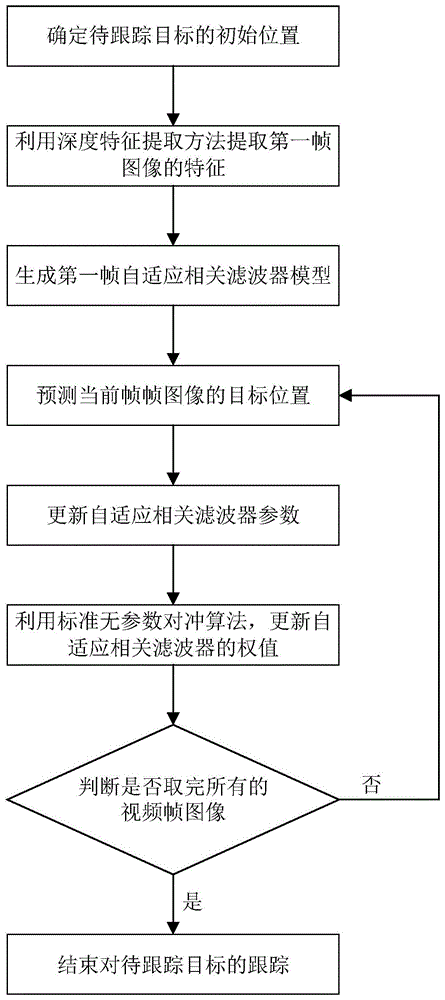
图1为本发明的流程图。
图2为本发明的仿真图。
具体实施方式
下面结合附图对本发明做进一步的描述。
结合附图1,对本发明的具体步骤做进一步的描述。
步骤1,确定待跟踪目标的初始位置。
输入含有待跟踪目标的彩色视频图像序列中的第一帧视频图像,本发明的实施例中,所输入的一段待跟踪视频图像序列的第一帧图像,如图2所示,其中图2为一段一只玩具旅鼠在实验桌子上运动的视频图像序列的第一帧图像,图2中的实线矩形框的位置表示待跟踪目标的初始位置。
用第一帧视频图像中待跟踪目标的初始位置和初始位置对应目标的长度和宽度确定一个跟踪目标矩形框,用该矩形框标出第一帧视频图像中的待跟踪目标。
步骤2,提取第一帧图像的特征。
(2.1)在第一帧视频图像中,以待跟踪目标的初始位置为中心,待跟踪目标矩形框长度和宽度均为2.5倍确定一个候选区域矩形框,用该矩形框标出第一帧视频图像中的候选区域图像。
(2.2)将候选区域图像输入到训练好的卷积神经网络vgg-net中,分别从卷积神经网络vgg-net的第10、11、12、14、15、16层输出与每层对应的6个图像特征。
所述的训练好的卷积神经网络vgg-net,其构建过程如下:
第1步,构建一个由16个卷积层和3个全连接层组成的19层的卷积神经网络vgg-net:其结构依次为:输入层→第1卷积层→第2卷积层→第1池化层→第3卷积层→第4卷积层→第2池化层→第5卷积层→第6卷积层→第7卷积层→第8卷积层→第3池化层→第9卷积层→第10卷积层→第11卷积层→第12卷积层→第4池化层→第13卷积层→第14卷积层→第15卷积层→第16卷积层→第5池化层→第1全连接层→第2全连接层→第3全连接层。
第2步,设置卷积神经网络vgg-net的各层参数如下:
将第1和第2卷积层的卷积核数量均设置为64,训练参数分别设置为(3×3×3)×64和(3×3×64)×64。
将第3和第4卷积层的卷积核数量均设置为128,训练参数分别设置为(3×3×64)×128和(3×3×128)×128。
将第5、第6、第7、第8卷积层的卷积核数量均设置为256,训练参数依次设置为(3×3×128)×256、(3×3×256)×256、(3×3×256)×256、(3×3×256)×256。
将第9、第10、第11、第12卷积层的卷积核数量均设置为512,训练参数依次设置为(3×3×256)×512、(3×3×512)×512、(3×3×512)×512、(3×3×512)×512。
将第13第14第15第16卷积层的卷积核数量均设置为512,训练参数均设置为(3×3×512)×512。
将第1、第2、第3、第4、第5池化层设置均为最大池化。
将第1、第2、第3全连接层参数依次设置为7×7×512、1×1×4096、1×1×4096。
第3步,从imagenet数据集中随机选取130万张图像组成训练集,将训练集输入卷积神经网络vgg-net进行训练,得到训练好的卷积神经网络vgg-net。
步骤3,利用自适应相关滤波公式,计算自适应相关滤波器参数,生成每个图像特征的第一帧自适应相关滤波器模型。
所述自适应相关滤波公式如下:
其中,wi表示第i个图像特征对应的自适应相关滤波器参数,argmin表示求函数参数的最小值操作,||·||表示求2范数操作,zi表示第i个图像特征,i=1,2,3,4,5,6,yn表示在训练卷积神经网络vgg-net时所使用的训练集中第n个训练样本对应的特征响应,λ1表示取值为1的正则化参数。
步骤4,预测下一帧帧图像的目标位置。
输入待跟踪视频序列中下一帧彩色视频图像,作为当前帧图像,在当前帧图像中,以上一帧图像待跟踪目标的位置为中心,取出与待跟踪目标中心位置相同的矩形框,其长度和宽度分别是待跟踪目标矩形框长度和宽度的2.5倍,将该矩形框作为当前帧图像的候选区域。
采用与步骤2中的第(2.2)步相同的方法,得到当前帧图像的候选区域图像对应的6个图像特征。
按照下式,计算每个图像特征的特征响应矩阵:
其中,rn表示第n个图像特征对应的特征响应矩阵,f-1(·)表示快速傅里叶逆变换操作,f(·)表示快速傅里叶变换操作,
所述第n个图像特征对应的自适应相关滤波器的候选区域目标特征和第n个图像特征对应的自适应相关滤波器的候选区域循环特征矩阵是由下式计算得到的:
an=x*⊙yn
bn=x*⊙x
其中,an表示第n个图像特征对应的自适应相关滤波器的候选区域目标特征,bn表示第n个图像特征对应的自适应相关滤波器的候选区域循环特征矩阵,x表示图像中的候选区域特征矩阵的第一行的向量的快速傅里叶变换值,*表示取共轭值操作,⊙表示点乘操作,yn表示在训练卷积神经网络vgg-net时所使用的训练集中第n个训练样本对应的特征响应。
按照下式,计算当前帧图像的特征响应矩阵:
r=r1+0.2r2+0.2r3+0.02r4+0.03r5+0.01r6
其中,r表示当前帧图像的特征响应矩阵。
选取当前帧图像的特征响应矩阵中元素的最大值,将该最大值元素的位置作为当前帧图像的待跟踪目标的目标框中心点的位置。
步骤5,按照下式,更新每个图像特征对应的自适应相关滤波器参数:
其中,wi表示第i个图像特征对应的自适应相关滤波器参数,argmin表示求函数参数的最小值操作,||·||表示求2范数操作,zi表示第i个图像特征,i=1,2,3,4,5,6,yn表示在训练卷积神经网络vgg-net时所使用的训练集中第n个训练样本对应的特征响应,λ1表示取值为1的正则化参数,λ2表示取值为0.5的自适应参数,y0表示假想先验矩阵。
所述的假想先验矩阵是指,在当前帧图像中,随机选取6个平移样本,将每个平移样本分别与自适应相关滤波器进行卷积操作得到6个响应值,将6个响应值组成假想先验矩阵。
步骤6,利用标准无参数对冲算法,更新当前帧每个图像特征对应的自适应相关滤波器的权值。
所述的标准无参数对冲算法如下:
第1步,按照下式,计算每个图像特征对应的自适应相关滤波器在当前帧的决策损失:
li=max(si)-si(x,y)
其中,li表示第i个图像特征对应的自适应相关滤波器在当前帧的决策损失,max表示取最大值操作,si表示第i个图像特征对应的自适应相关滤波器的响应矩阵,s(x,y)表示矩阵(x,y)位置上的元素。
第2步,按照下式,计算每个图像特征对应的自适应相关滤波器在当前帧的遗憾值:
ri=∑wili-li
其中,ri表示第i个图像特征对应的自适应滤波器在当前帧图像的遗憾值,wi表示第i个图像特征对应的自适应滤波器的权值。
第三步,按照下式,计算每个图像特征对应的自适应相关滤波器的权值:
其中,wi表示第i个图像特征对应的自适应滤波器在当前帧的权值,ri表示第i个图像特征对应的自适应相关滤波器第一帧到当前帧的所有遗憾值,[·]+表示求最大值操作,c表示尺度因子。
所述尺度因子是由下式计算得到的:
其中,e表示自然常数。
步骤7,判断当前帧视频图像是否为待跟踪视频图像序列的最后一帧视频图像,若是,则执行步骤8,否则,执行步骤4。
步骤8,结束对待跟踪目标的跟踪。
下面结合仿真实验对本发明的效果做进一步说明。
1.仿真实验条件:
本发明仿真实验的硬件测试平台是:处理器为cpuintelcorei5-6500,主频为3.2ghz,内存4gb。
本发明仿真实验的软件平台为:windows7旗舰版,64位操作系统,matlabr2013a。
2.仿真内容仿真结果分析:
本发明仿真实验是使用本发明所述的目标跟踪方法跟踪objecttrackingbenchmark2015数据库中的一段一名男子在室外旋转走动的视频图像序列。在本发明的仿真实验中将该名男子作为待跟踪的目标,该名男子在室外旋转走动的视频图像序列共有252帧视频图像。
图2(a)为本发明仿真实验中一名男子在室外旋转走动的视频图像序列的第一帧图像,图2(a)中沿着男子身体周围的实线矩形框表示待跟踪目标的初始位置。
图2(b)为本发明仿真实验中一名男子在室外旋转走动时被树遮挡时的跟踪结果示意图。该视频图像中的男子为待跟踪目标,待跟踪目标发生了遮挡。从该视频图像中对图像块的深度特征进行提取,计算每层特征的特征响应,将每层特征所对应响应加权求和,将和作为待跟踪目标最终位置。图2(b)中实线矩形框标注的是待跟踪目标的位置。
图2(c)为本发明仿真实验中输入的待跟踪目标发生外观形变和光照变化时的跟踪结果示意图。该视频图像中的男子为待跟踪目标,待跟踪目标发生了外观形变和光照变化。从该视频图像中对图像块进行特征提取,从该视频图像中对图像块的深度特征进行提取,计算每层特征的特征响应,将每层特征所对应响应加权求和,将和作为待跟踪目标最终位置。图2(c)中实线矩形框标注的是待跟踪目标的位置。
在图2(b)和图2(c)中,实线矩形框的位置表示本发明所述的目标跟踪方法跟踪到的待跟踪目标的位置。由图2(b)和图2(c)可以看出,该实线矩形框准确地框定了目标,说明本发明能够在视频图像序列中目标发生外观形变、遮挡、光照变化的情况下实现准确、有效地目标跟踪。
- 还没有人留言评论。精彩留言会获得点赞!