一种基于请求成功率的自适应休眠时间调节方法与流程
本发明涉及网络搜索爬虫技术,具体是一种基于请求成功率的自适应休眠时间调节方法。
背景技术:
随着网络的迅速发展,网络成为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大的挑战,爬虫在爬取目标网站时,目标网站有时会返回非期待的html文档,这就是目标网站的反爬措施。目标网站根据ip地址的访问频率做出判断,如果某一ip地址在一段时间内访问目标网站的频率过高,目标网站则会在一段时间对该ip地址进行限制,那么该ip地址下的所有用户都会被限制访问,所以要模拟用户在浏览器的操作,例如用户浏览一个页面需要停留5-7秒,那么爬虫程序也要模拟这个间隔时间来进行爬取,这样才不会过多的被目标网站反爬。
如何选取一个合理的间隔时间对爬虫运行的效率极其重要。假设目标网站当前的最佳文档返回的未知间隔时间为x,那么常见的间隔时间选择方法通常有两种:
(1)设置固定时间:通常为了爬虫的稳定,固定的时间会定为比较长,如定为4、5、6秒,也就是模拟用户在浏览器页面停留相应的间隔时间,再继续访问下一个链接。这种方式的优点是目标服务器返回错误页面的概率较小,基本可以获得一个较好的抓取效果,对应的缺点是设置固定的时间间隔,因为程序运行之中,间隔时间不可改变,当目标服务器有较大的负载能力时,如果固定时间大于x,那么爬虫程序没有获得一个最佳的间隔时间,会增加整个爬虫工作的运行时间,非常耗时;
(2)设置随机的动态间隔时间:在每次发起http请求时,使用随机函数ramdom生成一个间隔时间,这种方法的优点是可以根据随机函数的便利减少爬虫工作的时间,将随机函数生成的间隔时间分为三个区间,分别是高、中、低;当生成一个高间隔时间,那么可以缩短一定的时间,但不是最优间隔时间;当生成一个中间隔时间时,那么可以接近间隔时间x,获得一个较佳的间隔时间,这是随机生成动态时间的最佳状态;当生成一个低间隔时间,那么这已经小于目标网站的最佳间隔时间x,服务器可能会返回错误的文档,并记录该ip地址进一步做限制,这种方法的综合优点是可以缩短整个爬虫工作运行的一定时间,缺点是当随机时间较小时,可能会导致目标网站返回过多的错误页面,影响爬虫工作效率。
技术实现要素:
本发明的目的是针对现有技术的不足,而提供一种基于请求成功率的自适应休眠时间调节方法。这种方法能提高爬虫运行的效率。
实现本发明目的的技术方案是:
一种基于请求成功率的自适应休眠时间调节方法,包括如下步骤:
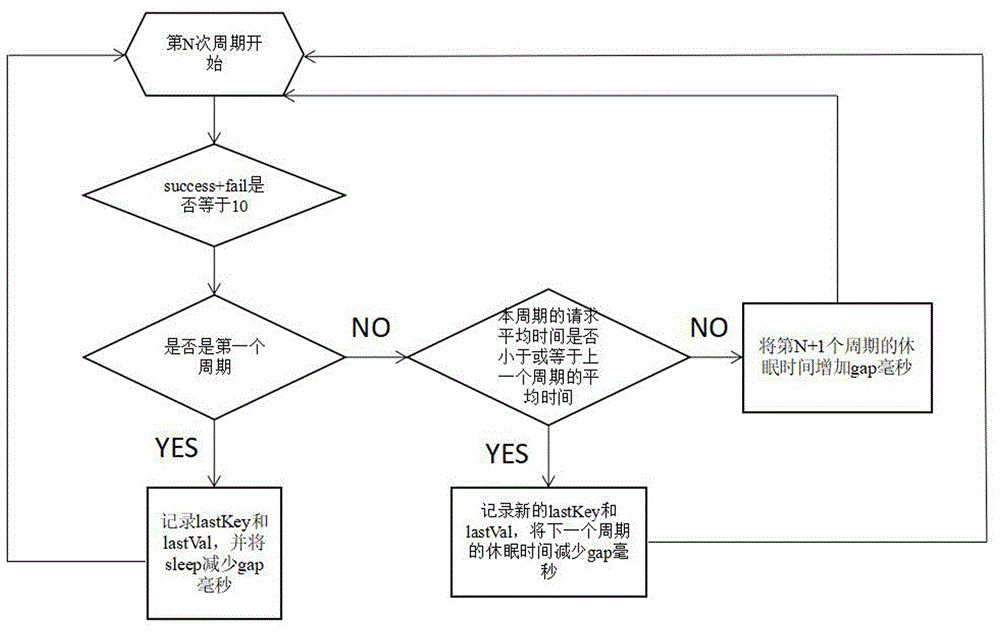
1)在爬虫每完成一次请求时,检查success和fail的和是否为10,如果是,继续到步骤2),如果不是,转到步骤9),其中,success为爬虫某个请求周期请求成功的次数,fail为爬虫某个请求周期请求被反爬的次数,所述的请求周期定义为:每发起10个http请求为1个周期;
2)计算请求周期成功率:所述请求周期的成功率定义为:用户发起http请求时,目标服务器返回期待的html文档的个数为x,那么本周期的请求成功率则为x÷周期发起的http请求数,也就是计算success除以10的结果,结果记为p,继续到步骤3);
3)计算该周期花费的时间:该周期花费的时间为sleeptime×10的结果,结果记为sum,继续到步骤4),其中,sleeptime为当前周期间隔时间;
4)计算该周期的每个成功请求所花费的时间:该周期的每个成功请求所花费的时间即sum÷success的结果,结果记为spendtime,继续到步骤5);
5)如在第一个请求周期内,将lastkey和lastval记录为第一个请求周期的休眠时间值以及平均时间,然后将下一个请求周期的休眠时间设置为第一个请求周期休眠时间减gap毫秒,第一个请求周期结束,返回到步骤1),其中,lastkey为上一周期的间隔时间,lastval为上一周期请求成功的平均所需时间,其中,gap为时间增量;
6)如果是第n个请求周期,则与上一个周期的spendtime进行比较,即与第n-1个周期比较,比较过程见步骤8);
7)如果第n个请求周期的效率值spendtime小于或等于第n-1个周期的平均时间,则该次自适应调节优化成功,更新lastkey和lastval,将下一个n+1周期的休眠时间设置为第n个周期休眠时间减gap毫秒,同时更新lastkey和lastval,本周期结束,返回到步骤1),其中,gap为时间增量;
8)如果第n个周期的效率值spendtime大于第n-1个周期的平均时间,则该次自适应调节优化失败,需要回退到上一个周期的休眠时间,即将下一个n+1周期的休眠时间设置为n-1的休眠时间加gap毫秒,将lastval记录为第n-1个周期的休眠时间,本周期结束,返回到步骤1),其中,gap为时间增量;
9)如果success和fail的和小于10,表明在处于请求周期未完成阶段,继续运行。
本技术方案以n秒为起始休眠时间,将每10个http请求作为一个探测周期,从上至下的探测目标服务器的反应时间,以每m毫秒的时间间距递减,探测一个最合理的休眠时间,在下一个周期以该休眠时间传入请求器,从而达到动态调节性,其中n和m可以由视情况而定。
本技术方案是一种对设置随机的动态间隔时间的方法,可以根据目标网站的实时响应情况,动态的修改间隔时间,得到较理想的间隔时间加速爬虫的工作时间。例如,当目标网站在a时间点时,可接受的响应时间范围是2000-3000毫秒,那么使用动态调节策略,就可以将爬虫设置的初始间断时间进入该目标服务器的响应范围,获取该时间段的最佳的间隔时间;再如,当目标服务器当前接受大量的用户访问,可接受的响应时间范围是4000-5000毫秒,使用动态调节策略,爬虫将从原来的2000-3000毫秒的间隔时间动态的改为4000-5000毫秒范围内,不会因为原来的较小的间隔时间遭到目标服务器的反爬。
这种方法能提高爬虫运行的效率。
附图说明
图1为实施例的方法流程示意图。
具体实施方式
下面结合附图和实施例对本发明的内容作进一步的说明,但不是对本发明的限定。
实施例:
参照图1,一种基于请求成功率的自适应休眠时间调节方法,其特征是,包括如下步骤:
1)在爬虫每完成一次请求时,检查success和fail的和是否为10,如果是,继续到步骤2),如果不是,转到步骤9),其中,success为爬虫某个请求周期请求成功的次数,fail为爬虫某个请求周期请求被反爬的次数,所述的请求周期在本例中定义为每发起10个http请求为1个周期;
2)计算请求周期成功率:所述请求周期的成功率定义为:用户发起http请求时,目标服务器返回期待的html文档的个数为x,那么本周期的请求成功率则为x÷周期发起的http请求数,也就是计算success除以10的结果,结果记为p,继续到步骤3);
3)计算该周期花费的时间:该周期花费的时间为sleeptime×10的结果,结果记为sum,继续到步骤4),其中,sleeptime为当前周期间隔时间;
4)计算该周期的每个成功请求所花费的时间:该周期的每个成功请求所花费的时间即sum÷success的结果,结果记为spendtime,继续到步骤5);
5)如在第一个请求周期内,将lastkey和lastval记录为第一个请求周期的休眠时间值以及平均时间,然后将下一个请求周期的休眠时间设置为第一个请求周期休眠时间减gap毫秒,第一个请求周期结束,返回到步骤1),其中,lastkey为上一周期的间隔时间,lastval为上一周期请求成功的平均所需时间,其中,gap为时间增量;
6)如果是第n个请求周期,则与上一个周期的spendtime进行比较,即与第n-1个周期比较,比较过程见步骤8);
7)如果第n个请求周期的效率值spendtime小于或等于第n-1个周期的平均时间,则该次自适应调节优化成功,更新lastkey和lastval,将下一个n+1周期的休眠时间设置为第n个周期休眠时间减gap毫秒,同时更新lastkey和lastval,本周期结束,返回到步骤1),其中,gap为时间增量;
8)如果第n个周期的效率值spendtime大于第n-1个周期的平均时间,则该次自适应调节优化失败,需要回退到上一个周期的休眠时间,即将下一个n+1周期的休眠时间设置为n-1的休眠时间加gap毫秒,将lastval记录为第n-1个周期的休眠时间,本周期结束,返回到步骤1),其中,gap为时间增量;
9)如果success和fail的和小于10,表明在处于请求周期未完成阶段,继续运行。
本例以n秒为起始休眠时间,将每10个http请求作为一个探测周期,从上至下的探测目标服务器的反应时间,以每m毫秒的时间间距递减,探测一个最合理的休眠时间,在下一个周期以该休眠时间传入请求器,从而达到动态调节性,其中n和m可以由视情况而定。
具体地:
本例在爬虫程序中,以3089条url链接作为测试总数,以3000毫秒的间隔时间启动爬虫程序,得到如表1的测试结果:
表1:
参照表1,可以得出:
(1)状态1:固定间隔时间:当起始间隔时间为3000毫秒,时间增量为0,也就是没有采用本例技术方案时,整个任务完成时间需要26分24秒,请求成功次数为1927次,本次爬取效率为62.38%即请求成功次数÷url总数,每次成功请求所需时间0.8秒即所需时间秒数÷请求成功次数;
(2)状态2:采用本例技术方案之一,即设置起始间隔时间为3000毫秒,时间增量为150毫秒,整个任务完成时间需要24分43秒,相对状态1缩短1分41秒,请求成功次数为1978次,本次爬取效率为64.03%,每次成功请求所需时间0.74秒;
(3)状态2:采用本例技术方案之二即设置起始间隔时间为3000毫秒,时间增量为300毫秒,整个任务完成时间需要15分33秒,请求成功次数为2070次,本次爬取效率为67.01%,每次成功请求所需时间0.45秒;
(4)状态3:采用本例技术方案之三即设置起始间隔时间为3000毫秒,时间增量为250毫秒,整个任务完成时间需要24分09秒,请求成功次数为2414次,本次爬取效率为78.14%,每次成功请求所需时间0.6秒;
间隔时间变化状态:以时间增量为250毫秒为例,下面是在采用本例技术方案,每个周期间隔时间变化的情况,即变量lastkeyarr数组的内容,lastkeyarr为记录所有周期的间隔时间:
[3000,2750,2500,2250,2000,1750,1500,1250,1500,1250,1500,1750,2000,1750,1500,1250,1500,1750,2000,2250,2000,2250,2000,1750,1500,1250,1000,750,500];
对应的成功请求平均时间变化情况,即变量lastvalarr数组的内容,lastvalarr为记录所有周期对应的请求成功的平均所需时间:
[4285.714285714285,3055.5555555555557,2500.0,2500.0,2222.222222222222,1944.4444444444443,1500.0,1562.5,1500.0,1562.5,1666.6666666666667,2187.5,2000.0,1944.4444444444443,1500.0,1562.5,1666.6666666666667,1944.4444444444443,2857.1428571428573,2250.0,2500.0,2500.0,2222.222222222222,1750.0,1500.0,1250.0,1250.0,833.3333333333334,500.0];
结论:经过多次的测试对比,可以看到,采用本例技术方案可以有效的减少爬虫任务的时间,减少1-2分钟,虽然在该测试调节下,时间缩短不明显,但效率均得到较好的提高,当在大规模的爬虫任务时,时间缩短会得到较好的体现,当时间增量为300毫秒时,可以看到时间缩短了10分钟左右,自适应调节策略可以根据目标服务器的响应情况,得到一个很好的加速效果,采用本例技术方案拥有较好的运行结果,可以提高、优化爬虫任务各个方面的指标。
- 还没有人留言评论。精彩留言会获得点赞!