一种图像自动编辑方法与流程
本发明涉及图像处理技术领域,尤其涉及一种图像自动编辑方法。
背景技术:
随着现代生活中科技应用的广泛覆盖,各种可穿戴设备和智能识别设备应用,在我们的生活中随处可见。照片、视频等图像信息在人们生活中扮演者越来越重要的角色,人们开始习惯用相机记录生活,微博、朋友圈也充满了大家拍摄的照片。海量图像信息的出现,也意味着也对于图像信息处理有了更高的需求。每天数以千记的视频和图像在互联网传递,视频跟踪、图像检测、图像分析这些技术词语已经不再局限于高深的科学领域,也随着技术的成熟和推广渗透到了人们的日常生活。监控安防,互联网支付,各种娱乐软件app等,都是需要通过摄像头捕捉图像或者记录视频作为输入数据,再通过算法进行处理后输出需要的结果。这些需求引出了各种基于视觉的处理方式,图像风格化、图像分割、物体检测、虚拟现实和增强现实等等。
对所有图片采用一样的图像编辑技术时,在遇到某些特殊的场景会导致图像处理的效果很差,本发明在对人像抠图的基础上进行图像处理来完成编辑,可以非常显著的提升其编辑效果,例如:图像素描化、图像背景模糊和图像风格化等等。人像抠图是一种识别图像中的人像区域,包括头部、半身和全身位置,并准确预测出人像与背景交界处之间的不透明度,配以不同背景图片、效果进行融合。其主要的性能指标是最小均分误差和梯度误差。大多数人像抠图工具依赖于用户交互来绘制三分图或笔画图的方式来提供颜色样本信息去完成抠图,该过程是繁琐且耗时的,对于一些没有抠图处理知识的专业人士来说,完成一幅满意的抠图需要多次绘制三分图或笔画图,并且这些人像抠图工具无法处理前景与背景对比度小的图像。而无需用户交互的人像分割是对人像的粗略硬分割,这种硬分割造成人像与背景之间没有平滑的过渡以及对复杂结构的前景(头发)分割非常不精准。
技术实现要素:
本发明提供了一种图像自动编辑方法,以解决现有的抠图处理技术效果差的技术问题,从而通过构建两个编码器-解码器结构的全卷积神经网络模型来完成精准抠图,进而实现抠图技术的优化,提高处理效果。
为了解决上述技术问题,本发明实施例提供了一种图像自动编辑方法,包括:
基于编码器-解码器结构,构建第一全卷积神经网络模型,用于标注照片对应的前景、背景和不确定区域的三分图;
获取第一原始图片集并对所述第一原始图片进行图像处理变换,生成相对应的模板图作为第一训练数据;
所述第一全卷积神经网络模型将所述第一训练数据先对原图进行随机旋转、比例缩放和伽马变换处理,再按原始图片和对齐模板图以通道方向合并成图像,输出真实三分图;
基于编码器-解码器结构,构建第二全卷积神经网络模型,用于实现图像抠图;
获取第二原始图片集并对所述第二原始图片进行图像处理合成,生成rgb图作为第二训练数据;
所述第二全卷积神经网络模型将所述第二训练数据中的rgb图进行随机旋转、比例缩放和伽马变换处理,再按原始图片和所述真实三分图以通道方向合并成图像,输出抠图图像。
作为优选方案,所述获取第一原始图片集并对所述第一原始图片进行图像处理变换,生成相对应的模板图作为第一训练数据,包括:
通过画板对获取的第一原始图片进行标注第一预测三分图,再通过数字抠图软件生成表示其图像前景为不透明度的第一抠图图像,形成第一抠图图像集;
将所述第一抠图图像集中的第一抠图图像取平均得到平均模板图;
通过任意人脸关键点算法检测所有第一原始图片中人脸的关键点坐标值并取算数平均得到平均关键点坐标;
通过任意人脸关键点算法对所述第一原始图片检测得到人脸的对应关键点坐标,通过所述平均关键点坐标和所述对应关键点坐标,计算得到仿射变换的单应性矩阵,通过矩阵变换算法将所述单应性矩阵和所述平均模板图进行仿射变换得到对应的模板图。
作为优选方案,所述计算得到仿射变换的单应性矩阵的公式为:
其中:h是一个3×3的单应性矩阵,fmx和fmy分别是平均关键点的x和y坐标点,fcx和fcy分别是当前图像人脸关键点的x和y坐标点;
所述矩阵变换算法的公式为:
其中:h是通过单应性矩阵公式计算得到的单应性矩阵,m是平均模板图,c是当前原始图片的模板图。
作为优选方案,在所述输出真实三分图之后,还包括:
计算所述第一预测三分图与所述真实三分图的交叉熵损失函数值,并对所述交叉熵损失函数值进行反向求导,然后通过优化器更新第一神经网络参数;
重复更新神经网络参数直至达到预设的次数阈值或所述交叉熵损失函数值小于预设阈值时停止;
保存神经网络参数文件,以实现对所述第一全卷积神经网络模型进行优化。
作为优选方案,所述交叉熵损失函数值的计算公式为:
其中,lt为交叉熵损失函数值;
作为优选方案,所述获取第二原始图片集并对所述第二原始图片进行图像处理合成,生成rgb图作为第二训练数据,包括:
通过画板对获取的第二原始图片进行标注第二预测三分图,再通过数字抠图软件生成表示其图像前景为不透明度的第二抠图图像,形成第二抠图图像集;
将所述第二原始图片集中的图片及所述第二抠图图像集中的图像与不重复的多张公开数据集mscoco,作为背景图通过图像线性公式进行合成生成多张rgb图作为第二训练数据;
所述图像线性公式为:ii=αifi+(1-αi)bi,αi∈[0,1];
其中:图像ii的像素点,fi和bi分别是图像的前景和背景,i是图像的索引;αi定义为图像ii在像素点i的前景不透明度,当αi=0时表示完全透明,αi=1时表示完全不透明。
作为优选方案,在所述输出抠图图像之后,还包括:
通过a值回归损失函数公式计算所述真实三分图对应三分图标记的不确定区域的前景不透明度a值的回归损失函数值;
通过图像回归损失函数公式计算所述抠图图像的图像回归损失函数值;
结合所述a值回归损失函数值和所述图像回归损失函数值计算得到损失函数值,并对所述损失函数值进行反向求导,然后通过优化器更新第二神经网络参数;
重复更新第二神经网络参数直至达到预设的次数阈值或所述a值回归损失函数值小于预设阈值时停止;
保存神经网络参数文件,以实现对所述第二全卷积神经网络模型进行优化。
作为优选方案,所述a值回归损失函数公式为:
其中:lα为a值回归损失函数值;
所述图像回归损失函数公式为:
其中:lc为图像回归损失函数值;
所述损失函数值的计算公式为:lo=(βlα+(1-β)lc)δi;
其中:lo为损失函数值;β是个常数;如果像素点i在三分图的未知区域内则δi=1,否则δi=0。
作为优选方案,所述a值回归损失函数公式中的ε值取:ε∈[6,10];所述损失函数值计算公式中的β值取0.5。
作为优选方案,所述第一全卷积神经网络模型将所述第一训练数据对原图进行随机旋转[-30,30]度、[0.8,1.2]比例的缩放和[0.5,0.8,1.2,1.5]伽马变换处理;所述第二全卷积神经网络模型将所述第二训练数据中的rgb图进行随机旋转[-30,30]度、[0.8,1.2]比例的缩放和[0.5,0.8,1.2,1.5]伽马变换处理。
相比于现有技术,本发明实施例具有如下有益效果:
1、本发明通过构建两个编码器-解码器结构的全卷积神经网络模型来完成精准抠图,解决现有的抠图处理技术效果差的技术问题,实现抠图技术的优化,提高处理效果。
2、本实现的抠图方法基于深度学习来完成,无需任何人工交互即可完成,间接地提高了整体图像编辑时间。
附图说明
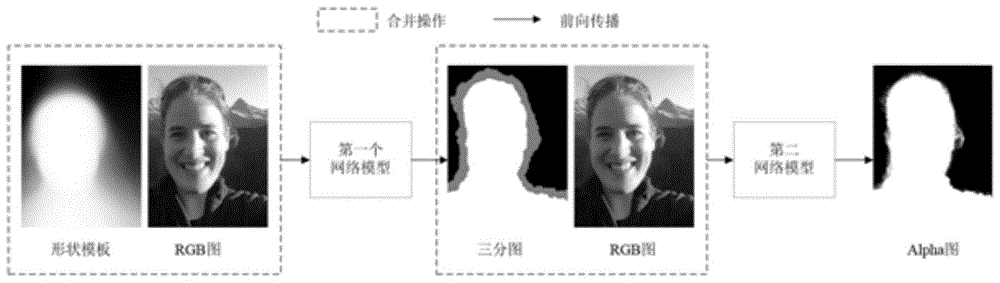
图1:为本发明实施例中的基于两个神经网络模型的人像抠图算法流程图;
图2:为本发明实施例中基于全卷神经网络的三分图标注方法网络结构图;
图3:为本发明实施例中的基于全卷神经网络的图像抠图方法网络结构图;
图4:为本发明实施例中的进行背景替换图像编辑的流程示意图;
图5:为本发明实施例中的图像风格模仿示例的输入图和模仿对象图对比示意图;
图6:为本发明实施例中的图像风格模仿示例的有无alpha图限制图像风格模仿对比示意图;
图7:为本发明实施例中的自动背景虚化示例的图像示意图;
图8:为本发明实施例中的背景替换示例的图像示意图;
图9:为本发明实施例中的抠图算法对比的图像示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参照图1-图3,本发明优选实施例提供了一种图像自动编辑方法,包括:
s1,基于编码器-解码器结构,构建第一全卷积神经网络模型,用于标注照片对应的前景、背景和不确定区域的三分图;
s2,获取第一原始图片集并对所述第一原始图片进行图像处理变换,生成相对应的模板图作为第一训练数据;
s3,所述第一全卷积神经网络模型将所述第一训练数据先对原图进行随机旋转、比例缩放和伽马变换处理,再按原始图片和对齐模板图以通道方向合并成图像,输出真实三分图;
s4,基于编码器-解码器结构,构建第二全卷积神经网络模型,用于实现图像抠图;
s5,获取第二原始图片集并对所述第二原始图片进行图像处理合成,生成rgb图作为第二训练数据;
s6,所述第二全卷积神经网络模型将所述第二训练数据中的rgb图进行随机旋转、比例缩放和伽马变换处理,再按原始图片和所述真实三分图以通道方向合并成图像,输出抠图图像。
对于图像/,人像抠图旨在找到前景f和背景b的最佳线性组合。对于任何像素点i,需满足以下公式:
ii=αifi+(1-αi)bi,αi∈[0,1]公式1
其中:图像ii的像素点,fi和bi是分别图像的前景和背景,i是图像的索引;αi定义为图像ii在像素点i的前景不透明度,0表示完全透明,1表示完全不透明。
本发明的自动人像抠图技术通过构建两个编码器-解码器结构的全卷积神经网络来完成抠图的方法,整个过程如图1所示。使用第一个全卷积神经网络(基于全卷神经网络的三分图标注方法)标注照片对应的前景、背景和不确定区域的三分图作为第二网络的输入,第二个全卷神经网络(基于全卷神经网络的图像抠图方法)用于实现图像抠图的功能,下面将两个全卷积神经网络进行分开说下。
基于全卷神经网络的三分图标注(第一个网络模型)方法步骤如下:
a)对背景较简单且与前景(人)对比度较大的原始图片首先使用画板手动标注三分图(t),再利用matlab版的informationflowmatting生成表示其前景不透明度的alpha(α)图(保存图片为int类型,像素值值域是[0,255])。
b)对所有n张原始图片做a)的相同操作最后生成{ii,ti,ai},(其中i表示原始图片,t表示原始图片对应的三分图,a表示alpha(a)图,i=[0,n])对数据集。
c)将b)中的全部alpha图取平均得到平均模板图mm。
d)使用任意人脸关键点算法检测a)中的所以原始图片中人脸的关键点坐标值并取算数平均得到平均关键点坐标fm。
e)使用任意人脸关键点算法(如dlib函数库,其运行过程为先对图片的人脸进行定位,将定位区域裁剪成人脸图像进行人脸关键点检测)对a)中原始图片检测得到人脸的对应关键点坐标fc。通过平均关键点坐标fm和原始图片的对应人脸关键点坐标fc计算得到仿射变换的单应性矩阵h(如公式2),通过公式3将已知的单应性矩阵h与平均模板图mm代入进行仿射变换得到对应的模板图mc如图2输入所示。
其中:h是一个3×3的单应性矩阵,fmx和fmy分别是平均关键点的x和y坐标点,fcx和fcy分别是当前图像人脸关键点的x和y坐标点
其中:h是通过公式2计算得到的单应性矩阵,m是平均模板图mm,c是当前原始图片ii的模板图mic
f)对a)中的每张原始图片ii进行e)操作,生成相对应的模板图mic。
g)本阶段的神经网络是编码器-解码器结构组成,其中编码器如图2所示,解码器是通过双线性插值做上采样将特征图逐层恢复至网络图像输入大小,整体网络结构如图1所示。
h)本阶段是标注三分图的神经网络。将上述操作准备好的训练数据先对原图进行随机旋转[-30,30]度、[0.8,1.2]比例的缩放和[0.5,0.8,1.2,1.5]伽马变换。然后按原始图片(iij)和对齐模板图mic以通道方向合并成大小为480×360×4的图像,网络目标为输出图像的三分图,其值0是背景,1是不确定区域,2是前景。
i)计算g)预测的三分图
j)根据i)的计算进行反向求导,并使用adam优化器更新神经网络参数。
k)重复g)~j)步骤n次或i)中公式4的函数值小于某个阈值时停止。
i)保存神经网络参数文件。
基于全卷神经网络的图像抠图方法(第二个网络模型)步骤如下:
a)对清晰度极高、背景简单且与前景(任意物体)对比度大的原始图片首先使用画板工具手动标注三分图(t),再利用matlab版的informationflowmatting生成表示其前景不透明度的alpha(α)图(保存图片为int类型,像素值值域是[0,255]。
b)对所有n张原始图片做a)的相同操作最后生成{ii,ti,ai},(其中i表示原始图片,ti表示原始图片对应的三分图,a表示alpha(a)图,i=[0,n])对数据集。
c)将b)中每一张原始图片ii及其前景不透明度的alpha(α)图ai与不重复的100张公开数据集(mscoco)作为背景图通过公式1进行合成生成100张rgb图(ciij)训练集(i表示原始图片ii中的i,j表示合成的rgb图片序号j=[0,100])。
d)本阶段的神经网络是编码器-解码器结构组成,其中编码器如图3所示,解码器是通过可分离卷积做上采样将特征图逐层恢复至网络图像输入大小。
e)本阶段是图像抠图的神经网络。将上述操作准备好的训练数据先对合成图进行随机旋转[-30,30]度、[0.8,1.2]比例的缩放和[0.5,0.8,1.2,1.5]伽马变换。然后按原始图片(iij)和三分图tij以通道方向合并成大小为320×320×4的图像,网络输出是对输入的合成图对应三分图标记的不确定区域的前景不透明度a值的标注,其中α∈[0,1]。
f)计算损失函数lo,其由a值回归损失函数lα和图像回归损失函数lc组成。
lo=(βlα+(1-β)lc)δi公式5
其中:β是个常数,实验中设置为0.5;如果像素点i在三分图的未知区域内则δi=1,否则δi=0。
a值回归损失函数lα:预测的a值的尺寸为1×h×w,其值范围在[0,1],0表示图片完全透明,1表示图片完全不透明。采用预测的a值与真实的a值的均方根误差(rmse):
其中:
图像回归损失组成lc:预测生成的rgb图片的尺寸为3×h×w,其值范围在[0,1]。采用预测生成的rgb图片与合成的真实图片的均方根误差(rmse):
其中:
g)根据f)的计算进行反向求导,并使用adam优化器更新神经网络参数。
h)重复g)~j)步骤n次或f)中的函数值公式6小于某个阈值时停止。
i)保存网络模型。
基于上述实施例中的抠图方法,可以对图像进行编辑,实现图像更优的编辑效果,以下方法全是都是在完成抠图的基础上实现的,并生成了原图对应的alpha图。
(1)背景替换
在已知前景图fi(既原图像)和背景图bi(替换图像),alpha图前景不透明度,利用公式1来完成图像融合。过程如图4所示。
(2)背景虚化
(a)利用已知原图前景不透明度的alpha图,通过公式(1)计算出前景图f和背景图b
(b)对背景图b进行拉普拉斯方差计算得出虚化背景图
(c)在利用公式(1)进行图像融合生成背景虚化图
(3)图像风格模仿
(a)输入需处理的图像/及示例图像e。
(b)分解图像/及示例图像e到多尺度拉普拉斯堆栈,获得图像i和图像e之间的对应关系。
(c)对图像i,e进行抠图,并通过公式(7)使抠图得到人像轮廓更为清晰完整:
(d)根据(b)过程建立的对应关系,将图像e风格转换到图像i,生成新图像。
本发明提出了一种无需多余人工交互的图像编辑技术,该发明在自动人像抠图的基础上运用图像编辑技术生成的图像质量明显高于不基于扣图的算法上。
示例1如下图5和图6所示,在图像风格模仿中,当人物头像和背景的颜色差异很大时(图5左),人物的部分头发和轮廓会消失在背景中,造成图像的部分失真(图6左)。在基于人像抠图上生成alpha图后,我们可以使alpha图(图5左)通过限制拉普拉斯算子使轮廓保存得更好,更加清晰(见图6方框区域)。其中:图5左为输入图,图5右为模仿对象图;图6左为无alpha图限制图像风格模仿图,图6右为有alpha图限制图像风格模仿图。
示例2如下图7所示,无需人工交互既可实现背景虚化。
示例3如下图8所示,只需要输入原图和背景图,即可完成背景替换。
本发明的自动人像抠图基于深度学习来完成,无需任何人工交互即可完成,间接的提高了整体图像编辑时间,并且相对于传统抠图算法,基础学习的抠图算法不会出现抠图后的低频“拖尾”或高频“厚实”伪影。示例如下图9所示,其中,图9左为原图,图9中为传统抠图,图9右为本发明抠图。
以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步的详细说明,应当理解,以上所述仅为本发明的具体实施例而已,并不用于限定本发明的保护范围。特别指出,对于本领域技术人员来说,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!