一种基于CNN-DBN的层次多标签医疗问题分类方法与流程
本发明涉及一种基于cnn-dbn的层次多标签医疗问题分类方法,属于计算机自然语言处理技术领域。
背景技术:
如今网络上存在着巨大数量的文本形式的资源,根据文本的内容将文本分到不同的类别对有效利用文本资源起到了巨大的作用。现实生活中分类问题的输出标签往往以层次结构组织构成层次化多标签分类问题,医疗问答以层次化标签树组织。这棵标签树中的节点分为两类,一类是底层节点,是最细粒度的类别标签,另一类是内部节点,它们最少有一个儿子节点,代表该类别标签下的一个或多个子类别标签。其中,第一层标签包括外科、内科、妇产科、儿科、皮肤性病科、中医科、五官科、其它科室8个类别标签,第二层标签包括普外科、骨科、神经外科、显微外科等57个类别标签,第三层包括肝胆外科、肛肠科、足踝外科等一共202个类别标签。
医层次分类主要使用局部方法和全局方法,局部方法可以使用任何分类器,并且可以组合不同的分类器,但是这种方法的缺点在于,高层次结构的错误随着层次结构向叶子节点遍历向叶子节点传播。相反的,全局方法避免了这种错误传播,并且计算更快,然而,全局方法难于实现并且全局方法不使用局部信息,而局部信息常用于区分类别层次。
医疗问题文本分类属于短文本分类短文本的分类问题相比长文本具有一定的难度,许多在长文本表现较好的方法在短文本上都会出现准确度大大下降的问题。如今针对短文本的分类方法大多都在如何解决文本的特征稀疏性上进行研究,主要方法有通过知识库等对短文本进行同近义词扩充,但其往往会引入一些无关特征,且没有考虑相关词语的语义。除此外还有通过各种方法对文本特征进行选择,抽取等操作,降低文本特征表示维度,这些方法往往只考虑了统计特征,同样忽略了文本的句法语义特征。随着深度学习的发展,深度模型有效地解决了传统机器学习方法存在的特征提取复杂,移植性差,短文本特征表示稀疏等问题。但由于深度模型过强的学习能力,cheng(<wide&deeplearningforrecommendersystems>,2016)指出了深度模型对某些出现频率较低的特征难以学习到有效的特征向量表示,存在过于泛化的问题,浅层模型如svm,线性模型等可以对出现次数较少的特征进行较好的学习,cheng等人将逻辑回归模型与多层的感知机网络结合,提升了谷歌应用商店的软件应用推荐准确率。silla(<asurveyofhierarchicalclassicationacrossdierentapplicationdomains,dataminingandknowledgediscovery>,2010)指出在同一层次上训练多个子分类器容易导致训练是过分关注局部信息而丢失重要的全局信息影响分类的准确性。
技术实现要素:
本发明提供了一种基于cnn-dbn的层次多标签医疗问题分类方法,以用于针对医疗问答语料的特点,使用卷积神经网络结合深度信念网络作为高层节点的分类器以保持高层节点之间的依赖性,逐层训练分类器,避开了局部方法和全局方法的一些缺陷,提高了层次多标签分类的准确率。
本发明的技术方案是:一种基于cnn-dbn的层次多标签医疗问题分类方法,所述方法的具体步骤如下:
step1、首先对医疗问题文本进行预处理,再利用处理好的问题文本构建词向量矩阵,作为卷积网络的输入;
step2、将step1构建好的词向量矩阵导入cnn中构建第一层卷积神经网络分类模型,为了更好地捕捉问题的文本特征,使用2,3,4三种不同长度卷积窗口的卷积核各两个,对词向量矩阵进行卷积计算,卷积核的宽度与词向量的维度相同,这种对句子的卷积操作可以捕获句子的局部特征;通过max-pooling层提取出每个特征中最具有代表性的特征组合后作为softmax函数的输入,输出一个概率的分布,最后选取输出概率最大的三个类别标签作为第一层的分类输出;
step3、在第二层标签分类时为了保持标签的层次信息和问句文本信息,使用step2中第一层的分类输出概率向量拼接cnn抽取出的文本特征向量作为第二层标签分类器dbn的输入,逐层训练得出第二层的分类结果,同样的最后选取输出概率最大的三个类别标签作为第二层的分类输出;
step4、经过step2,step3完成高层结点的分类后,再调用基于svm的底层分类器完成分类,得到最终的分类结果。
进一步地,所述步骤step1的具体步骤如下:
step1.1、对医疗问题文本进行数据清洗,专业领域分词,停用词等预处理。
step1.2、利用step1.1处理好的问题文本构建词向量矩阵,矩阵的行数为句子中词的个数,列数为词向量的维度;
step1.3、利用step1.2中构建的词向量矩阵表示问题文本,作为卷积网络的输入。
进一步地,所述步骤step3的具体步骤如下:
step3.1、使用step2中第一层的分类输出概率向量拼接cnn抽取出的文本特征向量作为第二层标签分类器dbn的输入,保持标签的层次信息和问句文本信息;
step3.2、step3.1输入后,逐层训练得出第二层的分类结果;
step3.3、选取step3.2输出概率最大的三个类别标签作为第二层的分类输出。
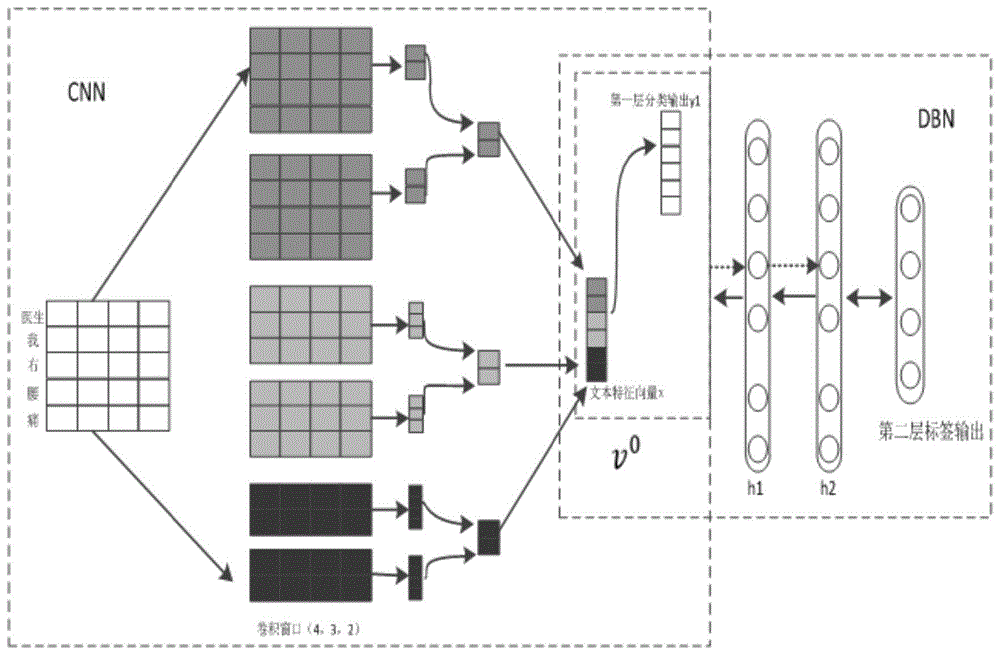
进一步地,所述第一层卷积神经网络分类模型由输入层、卷积层、池化层和softmax输出层组成;所述输入层,卷积网络的输入是用词向量矩阵表示的问句句子,矩阵的行数为句子中词的个数,列数为词向量的维度;所述卷积层,为了卷积出更具代表性的特征,用2,3,4三种不同长度卷积窗口的卷积核各两个,对词向量矩阵进行卷积计算;所述池化层,在池化操作时本发明使用max-pooling操作抽取出最具有代表性的特征;所述softmax输出层,将输入的最终的特征值进行组合后通过全连接的方式输入到softmax层中得到最终的分类结果,并且在全连接部分使用dropout减少过拟合;所述第二层标签分类器dbn使用一个两层rbm构成的深度信念网络作为第二层节点分类器,dbn模型一共有四层,使用卷积神经网络的输出层y1和文本特征向量x结合作为可视层同时也是模型的输入层v0,h1和h2对应模型的两个隐藏层,两个相邻的层被视为一个rbm。
本发明的有益效果是:
1、在高层节点部分,使用卷积神经网络的输出层y1和文本特征向量x结合作为可视层同时也是模型的输入层v0,这样不仅在层次分类时保存了标签之间的层次结构,并且保证了文本局部信息不丢失;
2、针对医疗问答中叶子节点中在某些标签下的样本较多而另一些标签下的样本较少的特点,本发明使用svm作为底层节点的分类器。
综上,这种基于卷积神经网络结合深度信念网络的层次多标签医疗问题分类方法,针对了医疗问答语料的特点,结合深度学习和传统机器各自的优点,通过使用逐层训练分类器的策略,避开了局部方法和全局方法的一些缺陷,与全局方法不同,在第一层使用卷积神经网络作为分类器可以捕获局部信息。除此之外,相较于局部分类器每一个节点都训练一个分类器的方法,我们没有将原始分类问题转化为大量的子分类问题,解决了在同一层次上训练多个子分类器容易导致训练是过分关注局部信息而丢失重要的全局信息影响分类的准确性的问题。最终模型提高了层次多标签问题分类的准确率。
附图说明
图1为本发明模型的结构图;
图2为本发明中医疗问答层次化标签树组织图;
图3为本发明中深度信念网络模型参数分析图。
具体实施方式
实施例1:如图1-3所示,一种基于cnn-dbn的层次多标签医疗问题分类方法,所述方法的具体步骤如下:
step1、首先对医疗问题文本进行预处理,再利用处理好的问题文本构建词向量矩阵,作为卷积网络的输入;
进一步地,所述步骤step1的具体步骤如下:
step1.1、对医疗问题文本进行数据清洗,专业领域分词,停用词等预处理;
本发明对医疗问答语料进行数据清洗,分词,去特殊符号和停用词等预处理,分词时引入专业医疗领域的词库,为了保证模型生成答案的可读性本发明只对问题做停用词处理。
step1.2、利用step1.1处理好的问题文本构建词向量矩阵,矩阵的行数为句子中词的个数,列数为词向量的维度;
为了将文本内容转换成计算机能计算的表示形式,本发明利用word2vec来训练词向量。为每一个文本生成三个类别标签向量,将属于此类别的标记为1,其它标记为0。
step1.3、利用step1.2中构建的词向量矩阵表示问题文本,作为卷积网络的输入。
由于词向量的维度过大会增加词之间的区分度,较小的维度会使得其相关性更大,本发明在词与词之间的区分度和相关性之间进行折中选取,将每个词的词向量设置为200维。
step2、将step1构建好的词向量矩阵导入cnn中构建第一层卷积神经网络分类模型,为了更好地捕捉问题的文本特征,使用2,3,4三种不同长度卷积窗口的卷积核各两个,对词向量矩阵进行卷积计算,卷积核的宽度与词向量的维度相同,这种对句子的卷积操作可以捕获句子的局部特征;通过max-pooling层提取出每个特征中最具有代表性的特征组合后作为softmax函数的输入,输出一个概率的分布,最后选取输出概率最大的三个类别标签作为第一层的分类输出;
本发明的模型使用goole的tensorflow实现,模型参数如下所述,在卷积网络部分,卷积核设置为128个,卷积窗口长度设置为2,3,4三种。模型训练循环迭代次数设置为200次。卷积计算公式为:ci=relu(∑w*x+bias)其中,bias为偏置向,选用relu非线性函数作为激活函数。
本发明通过max-pooling层提取出每个特征中最具有代表性的特征,最后通过softmax全连接层,将输入的最终的特征值进行组合后通过全连接的方式输入到softmax层中得到最终的分类结果,并且在全连接部分使用dropout减少过拟合。softmax函数接收这个特征向量作为输入,输出一个概率的分布。
step3、在第二层标签分类时为了保持标签的层次信息和问句文本信息,使用step2中第一层的分类输出概率向量拼接cnn抽取出的文本特征向量作为第二层标签分类器dbn的输入,逐层训练得出第二层的分类结果,同样的最后选取输出概率最大的三个类别标签作为第二层的分类输出;
进一步地,所述第一层卷积神经网络分类模型由输入层、卷积层、池化层和softmax输出层组成;所述输入层,卷积网络的输入是用词向量矩阵表示的问句句子,矩阵的行数为句子中词的个数,列数为词向量的维度;所述卷积层,为了卷积出更具代表性的特征,用2,3,4三种不同长度卷积窗口的卷积核各两个,对词向量矩阵进行卷积计算;所述池化层,在池化操作时本发明使用max-pooling操作抽取出最具有代表性的特征;所述softmax输出层,将输入的最终的特征值进行组合后通过全连接的方式输入到softmax层中得到最终的分类结果,并且在全连接部分使用dropout减少过拟合;所述第二层标签分类器dbn使用一个两层rbm构成的深度信念网络作为第二层节点分类器,dbn模型一共有四层,使用卷积神经网络的输出层y1和文本特征向量x结合作为可视层同时也是模型的输入层v0,h1和h2对应模型的两个隐藏层,两个相邻的层被视为一个rbm。
进一步地,所述步骤step3的具体步骤如下:
step3.1、使用step2中第一层的分类输出概率向量拼接cnn抽取出的文本特征向量作为第二层标签分类器dbn的输入,保持标签的层次信息和问句文本信息;
本发明使用一个两层rbm构成的深度信念网络作为第二层节点分类器,dbn模型一共有四层,使用卷积神经网络的输出层y1和文本特征向量x结合作为可视层同时也是模型的输入层v0这样不仅在层次分类时保存了标签之间的层次结构并且保证了文本局部信息不丢失,这里标签层是模型的输出层对应模型预测的标签输出。h1和h2对应模型的两个隐藏层,最后一个隐藏层的输出作为softmax函数的输入。w1,w2和w3分别对应层间的连接权重。设置深度信念网络的隐藏层为200维,相同层间的节点间不连接,不同层之间节点全连接,这就对应了医疗分类标签相同层次的类别标签相互独立的特点。隐藏层h和下一个rbm的可视层v1计算公式如下所示:
h1=(w·v0+b)
v1=(wt·h1+a)
隐藏层第j个神经元被开启的概率为
首先产生一个[0,1]上的阈值rj,根据计算的概率分布确定隐藏层神经元
然后我们利用h1重构下一个rbm的可见层,计算公式如下所示:
通过逐层的迭代训练最终可以得到新的权重和偏置如公式如下所示:
b←b+λ[p(h1=1|v0)-p(h2=1|v1)]
a←a+λ[v0-v1]
其中λ为学习率,w为权重向量,a为可见层的偏置向量,b为隐藏层偏置变量。
step3.2、step3.1输入后,逐层训练得出第二层的分类结果;
本发明中dbn可以使用一部分标记数据在训练过程中进行微调,通过全局优化获得更准确的模型。在训练时我们首先充分训练第一个rbn,为了充分利用标签的信息在训练顶层的rbm时,rbm的可视层中除了显性神经元,还设置代表分类标签的神经元一起训练。两个相邻的层被视为一个rbm。逐层训练rbm,上一层rbm的输出作为下一层rbm的输入数据并初始化dbn的网络参数。
最终将rbm的输出作为softmax回归分类器的输入数据,得到最终的输出结果
其中
step3.3、选取step3.2输出概率最大的三个类别标签作为第二层的分类输出。
step4、经过step2,step3完成高层结点的分类后,再调用基于svm的底层分类器完成分类,得到最终的分类结果。
多标签学习系统中的性能评价指标与经典的单标签学习问题中不同,在多标签学习中,评估会更加复杂,常用的评估标准有:
(1)汉明损失(hammingloss)
汉明损失反映了被误分类的样本-标签对的个数。汉明损失定义如下所示:
其中δ代表预测标签集合和真实标签集合的对称差异,实际上就是统计真实标签没有出现在预测标签集中的次数,i为样本索引。hloss的值越小,代表分类器性能越好。
(2)准确率(accuracy):
对于第i个样本来说,
(3)f值(f-measure)
f-measure能较好的平衡分类器对不同类别是精度和召回的调和平均,能比较好地平衡分类器对不同实例在不同类上的表现,因此更适合于不平衡的数据。
f-measure的值越大表明分类器的性能越好。f-measure定义为:
为了验证模型对于医疗问题文本分类的效果,文本通过爬虫从某公开医疗网站上爬取了45769条问题语料,通过对与医疗问答语料的分析可以看出医疗问题文本以层次化的类别标签组织,如图2所示,第一层标签包括外科、内科、妇产科、儿科、皮肤性病科、中医科、五官科、其它科室8个类别标签,第二层标签包括普外科、骨科、神经外科、显微外科等57个类别标签,第三层包括肝胆外科、肛肠科、足踝外科等一共202个类别标签。为了验证本发明所提模型的有效性,在对比实验时引入了层次多标签分类常用的两个数据集enron数据集和revlv2数据集的子集,试验数据集如表1所示:
表1
实验一:为了分析参数设置对深度信念网络模型的影响,对于第二层深度信念网络训练时,隐藏层神经元是否开启由计算得出的概率和阈值参数rj确定,对于参数rj设置其大小在[0,1]区间,设置对比实验参数为{0.0,0.02,0.04,…,1.0},从中选取最优值,实验结果如图3所示。由阈值参数对比可以看出,随着参数rj的逐渐增大平均分类精度逐渐提高经过一个峰值后平均分类精度又逐渐变低,由图可以看出参数rj的最佳区间为[0.54,0.64],实验得出最佳阈值参数rj为0.62。
实验二:对比hcnn,hsvm和cnn-dbn进行层次多标签分类的的效果及优缺点。hsvm:该算法针对每个标签结点训练一个二分类器自上而下训练hsvm模型,得出最后的分类结果;hcnn:该算法针对每层标签训练分类器,自上而下训练hcnn模型得出最后的分类结果。实验结果如下所示:
表2不同算法在所有数据集上的汉明损失对比
表3不同算法在所有数据集上的f-measure值
表4不同算法在所有数据集上的准确率
从表2汉明损失的对比中可以看出除了在医疗问答数据集上本发明所提出的cnn-dbn与hsvm和hcnn差别不大以外,本发明所提出的模型在其它数据集上相较于hsvm和hcnn都有着较好的表现。从表3f-measure值的对比中可以看出,在所有的数据集上本发明所提出的模型都有着最优的表现,hsvm的表现次之。从表4不同算法在所有数据集上的准确率对比中,可以看出在准确率的对比上本发明所提出的模型有着较优的表现。相较于针对每个标签结点训练一个二分类器自上而下训练hsvm模型,本发明所提出的模型简单易于训练。相较于简单堆叠的hcnn,本发明提出的模型在每一层分类都考虑了文本特征信息,因此在所有评价指标上都有着较优表现。
上面结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!