一种基于自编码网络的换衣行人重识别方法及系统与流程
本发明涉及计算机视觉领域,尤其是涉及一种基于自编码网络的换衣行人重识别方法及系统。
背景技术:
行人重识别问题旨在利用目标人物照片作为输入检索出该目标人物在其他时间点、不同摄像头下被拍摄到的历史记录。行人重识别系统因其广泛的应用,如无人超市、目标人物追踪、犯罪预防、搜寻遗失老人及小孩、目标人物活动分析等,在现实生活中有着丰富的应用场景。因此,行人重识别问题近年来在计算机视觉领域引起了广泛的关注。
行人重识别问题是具有挑战性的,主要由于真实的应用场景内存在剧烈的照明变化、行人姿态的变化、摄像机角度变化、遮挡、着装变化等差异性变化。因此,如何在存在大量环境变化的情况下学习一个鲁棒的特征表达是行人重识别人物的基本问题之一。早期的主流行人重识别方法,如shengcailiao等人提出的《personre-identificationbylocalmaximaloccurrencerepresentationandmetriclearning》,通过人工获取的特征来解决行人重识别问题。这些方法中的大部分集中在底层的信息上,如人穿的衣服颜色和纹理信息等。当光照条件发生较大变化或人们更换衣服时,这些底层的特征将会变得十分不可靠。
近年来,随着深度学习方法的兴起以及大规模数据集如cuhk03、market-1501的公布,行人重识别技术得到了繁荣发展。比较突出是利用深度卷积网络自动学习身份敏感和视点不敏感的行人特征进行重新识别的基于分类或排序模型的方法,如weili等人提出的deepreid《deepreid:deepfilterpairingneuralnetworkforpersonre-identification》以及liangzheng等人提出的prw《personre-identificationinthewild》。
尽管基于深度神经卷积网络的方法取得了显著的进展,但一些关键问题仍然没有得到足够的重视,并且阻碍了行人重识别方法的产品化。
首先,现有的公开数据集与真实应用场景间存在巨大的差距,主要体现在照片的拍摄周期较短。大多数数据集中,行人照片是从时长较短的监控视频中获取的,时长通常在数天。因此,在获取的行人图片中,行人很少改变着装、配饰等外貌特征。而这一点与现实世界中的应用场景是不同的。实际使用的行人重识别系统通常由部署在特定区域的摄像机网络组成。这些系统往往长时间在线,同一行人前后两次被拍到的时间间隔可能很长,因此行人大概率会出现着装变化。同时,光照、天气等因素也会有很大的变化空间,进一步增加行人外貌表征的变化。除了公开数据集与真实场景的差异之外,手工标注图片的昂贵成本也阻碍着大规模数据集的收集和标注。尤其在行人换衣的情况下精确的标注将变得更加困难。因此,许多无监督的方法被提出,如hehefan等人提出的pul《unsupervisedpersonre-identification:clusteringandfine-tuning》。然而,这些方法均未考虑到人们换衣这种情况。
其次,现有的大多数行人重识别方法主要利用衣服着装以及配饰的特征作为判别性信息。这些方法在短期的行人重识别任务中表现出色,但是当应用于服装剧烈变化的长期行人重识别场景中时,这些方法效果并不理想。
从以上两点可以归结出,目前阻碍行人重识别方法产品化的另两个关键问题:1、缺乏带有大量行人表征变化的已标记的训练数据;2、缺乏一种对行人表征变化鲁棒的特征学习方法。
技术实现要素:
本发明提供了一种基于自编码网络的换衣行人重识别方法及系统,使得在行人外貌变化丰富的场景下,能够学习得到鲁棒的判别性特征。
一种基于自编码网络的换衣行人重识别方法,包括以下步骤:
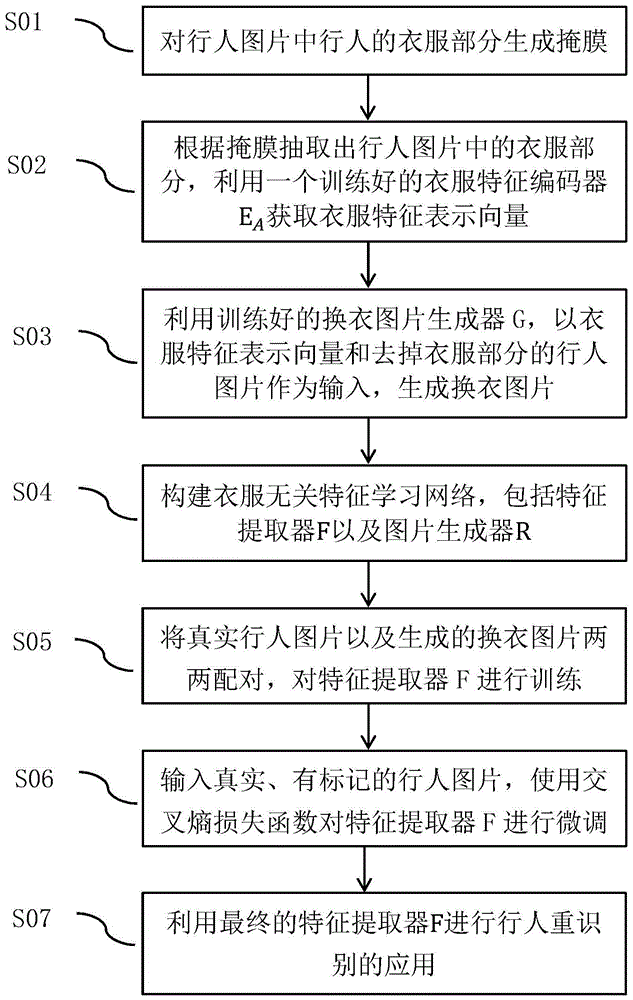
(1)利用行人部位解析器对行人图片中行人的衣服部分生成掩膜;
(2)根据掩膜抽取出行人图片中的衣服部分,利用一个训练好的衣服特征编码器ea获取衣服特征表示向量;
(3)根据掩膜去掉行人图片中的衣服部分,利用训练好的换衣图片生成器g,以衣服特征表示向量和去掉衣服部分的行人图片作为输入,生成换衣图片;
(4)构建基于自编码网络的衣服无关特征学习网络,所述衣服无关特征学习网络包含待训练的特征提取器f以及基于反卷积神经网络的图片生成器r;
(5)将真实行人图片以及利用该图片生成的换衣图片两两配对,对特征提取器f进行训练;
(6)训练收敛后,输入真实、有标记的行人图片,图片生成器根据特征提取器f提取的特征恢复出一张图片,使用交叉熵损失函数对特征提取器f进行微调;
(7)利用最终得到的特征提取器f进行行人重识别的应用。
步骤(2)中,所述衣服特征编码器利用自编码结构进行训练,其损失函数为:
其中,ic是衣服部分的图片,||*||1是l1损失函数。
步骤(3)中,所述的换衣图片生成器g利用对抗性损失函数进行训练,其目标函数为:
其中,ib是去除衣服部分的真实行人图片,cc是指定的待换衣服特征向量,xk是完整的真实行人图片;在训练过程中,cc使用真实行人图片中的衣服特征向量。
所述的换衣图片生成器g包括第二特征提取器和图片合成器,所述第二特征提取器中的第二个卷积模块使用三个不同大小卷积核的卷积层分别对输入图片进行特征提取,并将三个结果连接在一起输入下一层。通过使用不同大小的卷集核,从图片中提取到的低层次信息更为丰富。
步骤(4)中,所述的衣服无关特征学习网络还包括基于神经卷积网络的图片鉴别器dr,所述的图片鉴别器dr用于在训练阶段判别图片生成器r生成的图片与训练的目标图片是否足够接近。
步骤(5)中,对特征提取器f进行训练的具体过程为:
首先利用真实行人图片作为输入,换衣图片作为目标图片,训练时目标函数为图片生成器dr生成图片与目标图片的平均绝对误差(l1loss);然后利用换衣图片作为输入,真实行人图片作为目标图片,对网络进行第二次训练。
其中,特征提取器f训练的优化目标为:
其中,q为行人id集合,d为欧式距离,
本发明还公开了一种基于自编码网络的换衣行人重识别系统,包括基于条件生成式对抗网络的换衣图片模拟合成器(as-gan)和基于自编码网络的衣服无关特征学习框架(aifl);其中,所述的换衣图片模拟合成器包括:
基于自编码网络的衣服特征编码器:用于从输入的衣服图片中提取得到衣服特征表示向量;该编码用于指定换衣图片生成器g应该合成什么样的衣服。
换衣图片生成器g,用于根据衣服特征编码器得到的衣服特征表示向量和去掉衣服部分的行人图片生成换衣图片;
图片判别器d,用于在训练阶段判别换衣图片生成器生成的换衣图片是否足够真实;以此来训练换衣图片生成器g生成更加真实的图片。
所述的衣服无关特征学习网络包括:
待训练的图片特征提取器f,用于提取输入图片的特征;本发明最后的产出即是训练后的图片特征提取器f。产出的f会被用于提取输入目标人物图片的特征,并在历史图片库中检索最相似的人物图片,进而确定目标人物图片的身份信息。
图片生成器r,用于根据图片特征提取器提取得到的特征恢复出一张与输入图片大小相等的图片;使用恢复得到的图片与输入图片通过特定的损失函数计算得到损失,从而对网络进行训练,图片生成器r只在训练阶段使用。
图片鉴别器dr,用于在训练阶段判别图片生成器生成的图片与训练的目标图片是否足够接近。图片鉴别器dr的作用于换衣图片模拟合成器中的图片判别器d作用机制相同。同样只在训练阶段使用,帮助训练图片特征提取器f。
本发明的系统中,换衣图片模拟合成器利用指定的衣服图片和输入的真实行人图片生成换衣合成图片,该合成器的特点是保证了合成图片内行人和输入的真实行人身份前后一致且衣服部分被替换成根据指定的衣服图片合成出的新衣服。
衣服无关特征学习框架利用真实行人图片和对应生成的换衣行人图片组成图片对,通过训练,不断拉近换衣图片和真实行人图片在特征空间中的距离,从而学习到对衣服特征鲁棒的特征表达。
与现有技术相比,本发明具有以下有益效果:
1、本发明提出的换衣图片生成器g是完全无监督训练的,可以解决对标注数据的依赖,利用大量无监督数据生成海量的换衣数据。
2、本发明提出的衣着无关特征学习框架,利用换衣图片生成器g生成的照片,无监督的学习衣着无关特征,不需要依赖于人工标注的训练数据。只需要使用少量的标注样本对模型进行微调。同时,通过巧妙的训练方法设计,能够学习到对衣服特征变化鲁棒的行人特征表达,以解决行人换衣重识别场景中的特征提取器训练问题。
3、本发明相比其他基准线算法,具有更好的模型性能。
附图说明
图1为本发明一种基于自编码网络的换衣行人重识别方法的流程示意图;
图2为本发明实施例的整体流程示意图;
图3为本发明系统中的换衣图片模拟合成器的结构示意图;
图4为本发明实施例中展示的换衣图片生成样本;
图5为本发明换衣图片生成网络中使用多个卷积核组成网络第二层的网络结构示意图;
图6为本发明系统中的衣服无关特征学习框架的结构示意图。
具体实施方式
下面结合附图和实施例对本发明做进一步详细描述,需要指出的是,以下所述实施例旨在便于对本发明的理解,而对其不起任何限定作用。
如图1所示,一种基于自编码网络的换衣行人重识别方法,包括以下步骤:
s01,利用行人部位解析器对行人图片中行人的衣服部分生成掩膜;
s02,根据掩膜抽取出行人图片中的衣服部分,利用一个训练好的衣服特征编码器ea获取衣服特征表示向量;
s03,根据掩膜去掉行人图片中的衣服部分,利用训练好的换衣图片生成器g,以衣服特征表示向量和去掉衣服部分的行人图片作为输入,生成换衣图片;
s04,构建基于自编码网络的衣服无关特征学习框架,所述衣服无关特征学习框架包含待训练的特征提取器f以及基于反卷积神经网络的图片生成器r;
s05,将真实行人图片以及利用该图片生成的换衣图片两两配对,对特征提取器f进行训练;
s06,训练收敛后,输入真实、有标记的行人图片,图片生成器根据特征提取器f提取的特征恢复出一张图片,使用交叉熵损失函数对特征提取器f进行微调;
s07,利用最终得到的特征提取器f进行行人重识别的应用。
如图2所示,为本发明实施例的整体流程示意图,假设有一个待训练的特征提取器模型f。首先将输入图片和指定的衣服图片输入as-gan后可以得到衣服部分被替换成指定衣服的合成图片。合成图片与输入原图形成训练图片对,输入到aifl中,用于训练待训练的特征提取器模型f。在训练完毕后,使用真实的带标注的训练数据对f进行模型微调,流程完毕。
本发明系统的框架主要分为两部分,(a)换衣图片模拟合成器(as-gan)改编自条件式对抗生成网络,添加了衣服编码模块。(b)衣服无关特征学习框架(aifl),改编自自编码网络,加入了图片判别器。
如图3所示,为换衣图片模拟合成器(as-gan)的结构示意图,其中衣服编码是表示衣服图片编码器输出的特征向量,该特征向量会被输入到图片生成器中,在训练阶段使用的是原图中衣服,训练后的使用阶段使用的是随机选取的其他图片中的衣服;
1.利用基于pixel2pixel实现的掩膜生成器对行人图片中行人的衣服部分生成掩膜。
2.根据掩膜抽取出行人图片中的衣服部分,并利用衣服特征编码器对其进行建模,获取衣服特征表示向量。
3.根据掩膜去掉行人图片中的衣服部分,利用换衣图片生成器g,以待换上的衣服特征表示向量和待换衣的去掉衣服部分的行人图片作为输入,生成换衣图片。
本实施例中,生成的换衣图片如图4所示。我们对第二层使用的特殊化处理的卷积层进行了对比实验,从生成图片的质量上可以看出,使用多个大小不同的卷积核组成第二个卷积层能够使得图片生成效果更佳。
图5为本发明中对换衣图片生成器g的特殊处理,换衣图片生成器的图片特征提取器的第二层中使用的卷积核结构示意图。其中1x1convblock表示由一个卷积核大小为1×1的卷积层、一个relu激活函数和一个批标准化层组成的卷积块。
如图6所示,为衣服无关特征学习框架(aifl)的结构示意图,具体执行步骤为:
1.使用待训练的特征提取器f对输入图片提取得到特征向量。
2.利用特征提取器提取得到的特征向量,使用基于反卷积神经网络的图片生成器生成图片。
3.将真实行人图片与利用该图片和随机衣服特征向量生成的换衣行人图片两两配对,分两步对特征提取器进行训练。首先利用真实图片作为输入,换衣行人图片作为目标图片。训练时目标函数为图片生成器生成图片与目标图片的平均绝对误差损失函数(l1loss)。然后利用换衣行人图片作为输入,真实图片作为目标图片,对网络进行第二次训练。
4.训练收敛后,利用真实、有标记的行人图片使用交叉熵损失函数对特征提取器参数进行微调。
为例体现本发明的效果,本发明在两个具有说服力的公开数据集msmt-17和pavis上与其他目前最前沿的行人重识别系统进行对比。pavis是一个有79个id组成的行人重识别数据集,其特点是每个id都具有两组照片,部分id在两组照片中的穿着明显改变。数据集分成三个部分:训练集、验证集、测试集,分别有38、8、35个id。msmt-17是一个大型行人重识别数据集。该数据集使用的监控视频是目前已有公开数据集中视频时长最长的,其周期长到数周。因此,在该数据集中有更为丰富的光照等环境变化。同时,该数据集是目前最大的公开数据集,包含了4101个id共126441张图片。
本发明主要在两大评判指标上进行对比,分别是:map,cmc。与三个目前主流的行人重识别特征提取算法:alignedreid,resnet,densenet进行了对比,另外还有2个模型拆解对比,分别是改变aifl使用的真实-生成图片对的数目,以及对图片判别器的去除实验。
在pavis数据集上的评测结果如表1所示,其中networkstructure表示网络结构;map表示各类别平均准确率;cmc表示累计匹配曲线;alignedreid、resnet-50、densenet-161均为目前state-of-the-art的特征提取网络;baseline表示基准线模型;our表示本发明方法得到的模型。
表1
通过使用本发明方法训练得到的resnet-50和densenet-161模型的表现明显高于基准线网络。
在msmt-17数据集上的评测结果如表2所示,trainingdata表示训练数据集名称,msmt17(extend)表示使用生成图片直接争吵训练模型而不使用aifl框架。
表2
可以看出,直接使用生成图片会导致模型效果下降,这说明了aifl框架的必要性和效果。同时,通过使用我们的方法训练得到的resnet-50和densenet-161模型的表现明显高于基准线网络。
在msmt17数据集上,做了对第二层使用一个大小的卷积核和三个不同大小的卷积核的效果对比实验,结果如表3所示。
表3
其中refined代表使用图5所示的三个不同大小的卷积核组成的卷积层。可以看出,使用三个不同大小的卷积核可以提升生成图片的质量,从而提高模型模型训练效果。
同时,在msmt17上进行了改变真实-生成图片对的数目的实验,结果如表4所示,datavolume表示训练数据量。
表4
其中一个set表示10万个图片对,可以看出,使用越多的真实-生成图片对,对模型训练效果提升越大。
最后,在msmt17上进行了对图片判别器的去除实验,结果如表5所示。
表5
从表5可以看出,使用图片判别器可以提高模型训练的效果。
以上所述的实施例对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的具体实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!