基于FPGA的实对称矩阵的特征值分解的并行实现方法与流程
本发明属于阵列信号处理领域,具体涉及基于fpga的实对称矩阵的特征值分解的并行实现方法。
背景技术:
近几年来,阵列信号处理理论在地震勘探,雷达通信,方位侦测等领域均发挥着重要的作用。在此领域中矩阵的特征值分解是一个应用广泛的矩阵运算。然而特征值分解算法包含大量的非线性运算,运算时间长,影响了算法的实时性。因此,如何快速的得到所需的特征值和特征向量是fpga实现的难点。
目前,大多数设计者普遍采用了经典的jacobi算法,采用单次扫描的流程,不能够体现jacobi算法的高度并行性。一部分学者提出了一种用于计算n维实矩阵特征值分解的脉动阵列结构,充分体现了jacobi算法的高度并行性。但是,此结构着重于算法的宏观运用,在内部微观还存在改进之处。即,该结构使用固定化的元素交换方式。在迭代过程中绝对值较大的非对角元素的位置不停的变动,使其无法被有效的消除,迭代效率低。
因此,本发明改进了阵列结构的数据交换网络。并且通过在迭代过程中改变阵列结构内部处理单元中的输入输出数据的顺序,提高了迭代运算的效率,使算法能够更快速的收敛。
技术实现要素:
本发明的目的在于提供基于fpga的实对称矩阵的特征值分解的并行实现方法。
基于fpga的实对称矩阵的特征值分解的并行实现方法,该方法包括以下步骤:
步骤1:设数据矩阵a∈rn×n为实对称矩阵,根据矩阵的维数建立特征值分解的阵列结构;
步骤2:对接收的阵元信号进行预处理,将矩阵的复数域运算转换为实数域;
步骤3:根据并行排序规则在数据矩阵an×n中选取对应的数据初始化整个处理单元,并将特征向量矩阵设定为单位阵,即v=en×n,将迭代次数计数器和交换数据计数器初始化为0;
步骤4:根据cordic算法同时计算n/2个对角单元中的旋转角度θ;
步骤5:将旋转角度θ由弧度值转换为角度值,而后通过查表法得到sinθ和cosθ,对角单元纵向和横向传递sinθ和cosθ到非对角处理单元和特征向量计算模块;
步骤6:所有处理单元依据jacobi变换求解旋转后的矩阵元素,并且更新特征向量;
步骤7:判断迭代次数是否达到阈值,若达到阈值,v即为所需的特征向量,若没有达到阈值,进行步骤8;
步骤8:累加迭代次数计数器和交换次数计数器,交换相邻处理单元的数据;
步骤9:判断交换计数器是否大于(n/2-1),若大于,则改变处理单元内部输入输出数据的顺序直至交换计数器等于(n-1),且交换次数计数器等于(n-1)时归零,重复步骤4到步骤9。
步骤1所述的根据矩阵的维数建立特征值分解的阵列结构包括:若n为偶数,即构建(n/4)(n/2+1)个处理单元,其中包括n/2个对角单元,其余为非对角处理单元;每个对角单元包含3个矩阵元素,每个非对角单元包含4个矩阵元素;对角单元首先计算旋转角度,然后向非对角单元传递角度值;每次迭代都会消除n/2个非对角元素,而每轮的清扫需要(n-1)次的迭代;三轮清扫后,特征值分解达到收敛;若n为奇数,可在矩阵边缘添加1行与1列0元素后构建脉动阵列结构。
步骤6所述的jacobi变换过程为:设a∈rn×n为实对称矩阵,则存在正交矩阵g∈rnxn使下式成立:
其中,
矩阵g被称之为givens矩阵,其对角线元素除了gpp=cosθ,gqq=sinθ其他元素都为1,非对角元素除了gpq=-sinθ,gqp=sinθ其他元素都为0;
对于矩阵a中的元素在经过每次旋转后会发生如下变化:
其中,
在迭代过程中,不断得到新的givens矩阵。将此矩阵累乘后就可以得到特征向量,即
步骤8所述的交换相邻处理单元的数据的方法为:根据jacobi矩阵变换的旋转关系,确定阵列结构中的第一行元素和对角线上的元素即可确定整个阵列结构中的元素,所以只需确定变换后的第一行元素和对角元素就可推出其他元素的变换顺序,而且每次迭代的变换顺序是相同的;数据调度规则为:第一行数据中,设位置序号为偶数的序号为c,且c>2;对于序号为偶数的数据向左进行移动,放至序号为c-2的位置;序号为2的元素移动到序号为3的元素,对于序号为奇数数据向右移动,且序号为1的元素保持不变,序号为n-1的元素移动到序号为n的元素的位置;第一行数据的交换方式同样适用于对角元素,只是将左右移动变成了上下移动,其他的矩阵元素可以通过已交换顺序的对角元素和第一行元素分别确定行标和列标;而后对照前后的变换顺序可以快速的得出数据的调度规则,此外,相邻的非对角单元内部将会有一个矩阵元素不与外界交换。
步骤9所述的改变处理单元内部输入输出数据的变换方式为:第一个对角处理单元不需要交换,其余对角单元将输入的app和aqq交换;而与第一个对角单元相邻的同一行非对角单元将api和apj,aqi和aqj交换;其余非对角单元将api和aqj,apj和aqi交换,完成本次迭代后,更新的矩阵元素不能按照原来的顺序输出,也需要改变其输出顺序,其改变方式与输入数据的改变方式相对应,即最终的输出数据的顺序与(n/2-1)次迭代之前相同。
本发明的有益效果在于:
本发明通过处理单元之间数据的传递以及处理单元内部的数据顺序的转换,提高了迭代效率而且运算速度快,应用前景广阔。
附图说明
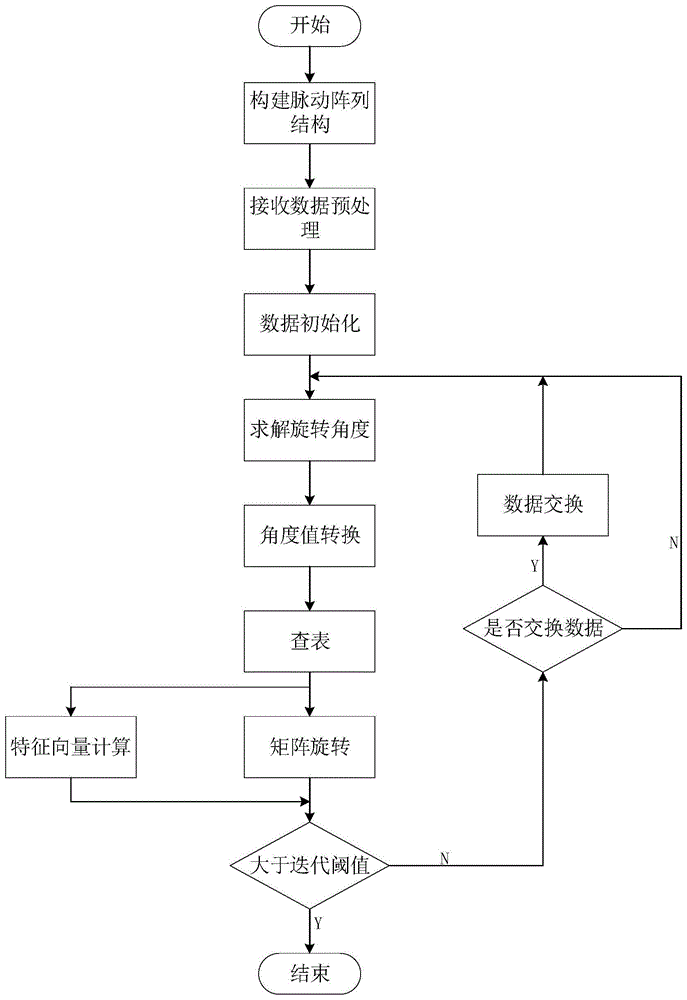
图1为fpga特征值分解算法流程。
图2为jacobi算法的并行排序规则。
图3为8×8实对称矩阵并行分解步骤。
图4为8×8实对称矩阵并行分解阵列结构。
图5为8×8实对称矩阵数据调度规则。
图6为处理单元内部输入数据变换规则。
图7为fpga和matlab的估计误差。
具体实施方式
下面结合附图对本发明做进一步的描述。
本发明具体实现步骤如下:根据阵元数目构建特征值分解的脉动阵列结构,设定所需的处理单元;对接收的阵元信号进行预处理;求解旋转角度并将其转换为角度值;查表得到对应的正弦值和余弦值;更新矩阵元素和特征向量;判断是否达到要求迭代次数;若未达到,在阵列结构中交换矩阵元素为下次迭代做准备;判断是否需要改变处理单元内部的输入输出顺序;若是,则改变输入输出数据的顺序。本方法通过处理单元之间数据的传递以及处理单元内部的数据顺序的转换,提高了迭代效率而且运算速度快,应用前景广阔。
基于fpga的实对称矩阵的特征值分解的并行实现方法,包括以下步骤:
步骤一、设数据矩阵a∈rn×n为实对称矩阵,根据矩阵的维数建立特征值分解的阵列结构。
步骤二、对接收的阵元信号进行预处理,将矩阵的复数域运算转换为实数域。
步骤三、根据并行排序规则在数据矩阵an×n中选取对应的数据初始化整个处理单元,并将特征向量矩阵设定为单位阵,即v=en×n。将迭代次数计数器和交换数据计数器初始化为0。
步骤四、根据cordic算法同时计算n/2个对角单元中的旋转角度θ。
步骤五、将旋转角度θ由弧度值转换为角度值,而后通过查表法得到sinθ和cosθ。对角单元纵向和横向传递sinθ和cosθ到非对角处理单元和特征向量计算模块。
步骤六、所有处理单元依据jacobi变换求解旋转后的矩阵元素,并且更新特征向量。
步骤七、判断迭代次数是否达到阈值。若达到阈值,v即为所需的特征向量,否则进行步骤八。
步骤八、累加迭代次数计数器和交换次数计数器,交换相邻处理单元的数据。
步骤九、判断交换计数器是否大于(n/2-1)。若大于,则改变处理单元内部输入输出数据的顺序直至交换计数器等于(n-1)。且交换次数计数器等于(n-1)时归零。重复步骤四到九。
对于n维矩阵的特征值分解搭建脉动阵列结构:
n为偶数,即构建(n/4)(n/2+1)个处理单元,其中包括n/2个对角单元,其余为非对角处理单元。每个对角单元包含3个矩阵元素,每个非对角单元包含4个矩阵元素。对角单元首先计算旋转角度,然后向非对角单元传递角度值。每次迭代都会消除n/2个非对角元素,而每轮的清扫需要(n-1)次的迭代。三轮清扫后,特征值分解达到收敛。若n为奇数,可在矩阵边缘添加1行与1列0元素后构建脉动阵列结构。
每次迭代结束后交换相邻处理单元数据的方法:
根据jacobi矩阵变换的旋转关系,只要确定阵列结构中的第一行元素和对角线上的元素即可确定整个阵列结构中的元素。所以只需确定变换后的第一行元素和对角元素就可推出其他元素的变换顺序,而且每次迭代的变换顺序是相同的。数据调度规则为:第一行数据中,设位置序号为偶数的序号为c,且c>2。对于序号为偶数的数据向左进行移动,放至序号为c-2的位置。序号为2的元素移动到序号为3的元素。对于序号为奇数数据向右移动,且序号为1的元素保持不变,序号为n-1的元素移动到序号为n的元素的位置。第一行数据的交换方式同样适用于对角元素,只是将左右移动变成了上下移动。其他的矩阵元素可以通过已交换顺序的对角元素和第一行元素分别确定行标和列标。而后对照前后的变换顺序可以快速的得出数据的调度规则。此外,由于对角单元内部只有三个元素,所以相邻的非对角单元内部将会有一个矩阵元素不与外界交换。
当交换次数大于(n/2-1)时,处理单元内部输入输出数据的变换方式:
第一个对角处理单元不需要交换,其余对角单元将输入的app和aqq交换;而与第一个对角单元相邻的同一行非对角单元将api和apj,aqi和aqj交换;其余非对角单元将api和aqj,apj和aqi交换。且完成本次迭代后,更新的矩阵元素不能按照原来的顺序输出,也需要改变其输出顺序,其改变方式与输入数据的改变方式相对应,即最终的输出数据的顺序与(n/2-1)次迭代之前相同。
基于fpga的实对称矩阵的特征值分解的并行实现方法的步骤具体表述为:
a.确定jacobi变换前后矩阵a中元素的变换关系以及特征向量的计算:
a1.jacobi算法变换过程
设a∈rn×n为实对称矩阵,则存在正交矩阵g∈rnxn使得
其中
矩阵g被称之为givens矩阵,其对角线元素除了gpp=cosθ,gqq=sinθ其他元素都为1,非对角元素除了gpq=-sinθ,gqp=sinθ其他元素都为0。
对于矩阵a中的元素在经过每次旋转后会发生如下变化:
其中,
a2.特征向量的计算
在迭代过程中,不断得到新的givens矩阵。将此矩阵累乘后就可以得到特征向量,即
b.构建jacobi并行变换模块
b1、设数据矩阵a∈rn×n为实对称矩阵,n为偶数则根据矩阵维数n搭建特征值分解的脉动阵列结构。即构建(n/4)(n/2+1)个处理单元,其中包括n/2个对角单元。每次迭代都会消除n/2个非对角元素,而每轮的清扫需要(n-1)次的迭代。三轮清扫后,特征值分解达到收敛。若n为奇数,可在矩阵边缘添加1行与1列0元素后构建脉动阵列结构;
b2、设计数据调度规则:第一行数据中,设为位置序号为偶数的序号为c,且c>2。对于序号为偶数数据向左进行移动,放至序号为c-2的位置。序号为2的元素移动到序号为3的元素。对于序号为奇数数据向右移动,且序号为1的元素保持不变,序号为n-1的元素移动到序号为n的元素的位置。第一行数据的交换方式同样适用于对角元素,只是将左右移动变成了上下移动。其他的矩阵元素可以通过已交换顺序的对角元素和第一行元素分别确定行标和列标。而后对照前后的变换顺序可以快速的得出数据的调度规则;
b3、依据并行排序规则将矩阵a中上三角数据赋值到所有处理单元中,完成初始赋值。赋值结束后,传递数据有效标志转入b4;
b4、数据有效后,对角单元利用cordic算法计算旋转角度θ,此时θ为弧度值。传递数据有效标志后进入b5;
b5、将θ转换为角度值,而后利用查表法得到sinθ,cosθ。按照阵列结构并将其传递到相邻的非对角单元,直至遍历整个阵列结构。得到旋转角度后转入b6;
b6、对角单元和非对角单元根据公式gtag,利用查表所得的sinθ和cosθ,按步骤a所示更新矩阵元素。同时完成特征向量的计算。所有处理单元计算完成后转入b7;
b7、判断迭代次数是否达到阈值。若达到阈值,v即为所需的特征向量,否则进行步骤b8;
b8、每一轮计算完成后累加迭代次数计数器和交换次数计数器,并且对相邻处理单元进行数据交换。根据b2所述的调度规则先确定第一行和对角线的矩阵元素,进而确定其他非对角元素。而且每一轮结束后的数据交换规则是相同。因此,只要事先确定好交换规则,就不需要改变。这样降低了程序的复杂度,便于程序的编写;
b9、判断交换计数器是否大于(n/2-1)。若大于,则改变处理单元内部输入数据的顺序。在当前迭代完成后,更新的矩阵元素不能按照原来的顺序输出,也需要改变其输出顺序,其改变方式与输入数据的改变方式相对应。当交换计数器等于(n-1)时,还原输入输出数据的顺序。改变顺序如图6。且交换次数计数器等于(n-1)时归零。重复步骤b4到b9。
实例
阵列模型为8阵元均匀圆阵。信号频率为3ghz窄带远场信号且信源数为1,圆阵半径为0.05m。阵元接收噪声为零均值高斯白噪声,快拍数为64。选用芯片xc7vx690tffg1761-2。
在估计性能包括计算精度、计算速度和资源消耗,具体可用下面指标评价。
1.计算精度
由fpga完成特征值分解将计算的所得噪声子空间导入到matlab中,由matlab完成最终的谱峰搜索。接收的信号方位角和仰角分别为40°和30°。信噪比在2到12之间,在每个参数下仿真100次。通过
2.计算速度
计算消耗的时钟数nclk越小表示计算消耗的时间越少,计算速度越快。
3.资源消耗
触发器消耗资源;lut查找表消耗资源;ram消耗资源,而ram消耗资源反应在lutram和bram上;运算单元dsp48e1消耗资源。
实施方式,具体为以下步骤:
a.仿真信号建模:
a1.music算法对于窄带信号的doa估计的数学模型为:
x(t)=as(t)+n(t)
式中,x(t)为阵列的8×1维快拍数据矢量,n(t)为阵列的8×1维噪声数据矢量,
s(t)为空间信号的1×8维矢量,a为空间阵列的8×1维流型矩阵。
a2.对接收信号进行预处理:
将8阵元均匀圆阵分为两个子阵,其输出分别为x1(t)和x2(t),令
m=re[x1(t)]+re[x2(t)]q=im[x1(t)]+im[x2(t)]
l=im[x1(t)]-im[x2(t)]g=re[x2(t)]-re[x1(t)]
令
b应用本发明对rz进行特征值分解,计算其特征值和特征向量。
b1.数据矩阵rz为8×8矩阵。如附图4根据矩阵维数建立10个pe(processingelement)单元,其中包括6个非对角单元,4个对角单元。
b2.数据调度规则:如附图5,第一行数据中,设为位置序号为偶数的序号为c,且c>2。对于序号为偶数数据向左进行移动,放至序号为c-2的位置。序号为2的元素移动到序号为3的元素。对于序号为奇数数据向右移动,且序号为1的元素保持不变,序号为7的元素移动到序号为8的元素的位置。
b3.根据jacobi并行排序规则,排列矩阵非对角元素的消除顺序。
b4.按照消除顺序初始化pe单元的输入数据,将特征向量初始化为单位阵,即v=en×n。迭代次数计数器和交换数据计数器初始化为0。
b5.由公式
b6.根据查表所得的sinθ和cosθ完成矩阵的旋转和特征向量的计算。并且令迭代计数器和交换数据计数器加1,并判断迭代次数是否超过阈值。未超过阈值则进行b6步骤,否则进行b8步骤。
b7.判断数据交换次数是否达到3次。若达到3次,除pe1以外改变其它的处理单元输入和输出数据的顺序。pe5,pe8,pe10将输入的app和aqq交换;pe2,pe3,pe4将api和apj,aqi和aqj交换;pe6,pe7,pe9将api和aqj,apj和aqi交换。完成本次迭代的矩阵旋转后,再将更新后的矩阵元素交换回原来的顺序。当交换次数达到7次时,停止输入输出数据顺序交换。且交换次数达到7次归零。
也就是说完成一轮迭代后归零。重复b5到b7步骤。
b8.提取特征值所对应的特征向量,分离噪声子空间和信号子空间。
计算速度:nclk=1060
资源消耗:
计算精度:
如附图7,fpga与matlab的估计误差基本一致。而且随着信噪比的增大,估计误差减小。
本发明提供一种基于fpga的实对称矩阵特征值分解的并行实现方法,属于阵列信号处理领域。具体实现步骤如下:根据阵元数目构建特征值分解的脉动阵列结构,设定所需的处理单元;对接收的阵元信号进行预处理;求解旋转角度并将其转换为角度值;查表得到对应的正弦值和余弦值;更新矩阵元素和特征向量;判断是否达到要求迭代次数;若未达到,在阵列结构中交换矩阵元素为下次迭代做准备;判断是否需要改变处理单元内部的输入输出顺序;若是,则改变输入输出数据的顺序。本方法通过处理单元之间数据的传递以及处理单元内部的数据顺序的转换,提高了迭代效率而且运算速度快,应用前景广阔。
- 还没有人留言评论。精彩留言会获得点赞!