一种读写场景坐标认定方法与流程
本发明涉及图像识别技术领域,具体涉及一种读写场景坐标认定方法。
背景技术:
我国近视人数已超6亿,几乎占到中国总人口数量的50%,近视发病呈现年龄早、进展快、程度深的趋势。据调查报告显示,学生视力不良问题突出。四年级、八年级学生视力不良检出率分别为36.5%、65.3%,其中四年级女生视力中度不良和重度不良比例分别为18.6%、10.4%,男生分别为16.4%、9%;八年级女生视力中度不良和重度不良比例分别为24.1%、39.5%,男生分别为22.1%、31.7%。
实际上,我国青少年的整体视力情况不容不乐观,有数据显示,青少年近视率已经高居世界第一。其中近距离用眼和手机、电脑等电子产品的不间断使用有极大的关系。从近年发展趋势来看,青少年因为学习姿势的不规范以及过早接触电子产品使得近视的风险在逐渐增大,从小便戴上了眼镜。
技术实现要素:
本发明要解决的技术问题是提供一种可以自动识别当前读写场景坐标的方法,以判断使用者的读写姿势以及读写距离是否符合标准。
为实现上述目的,本发明采用如下技术方案:
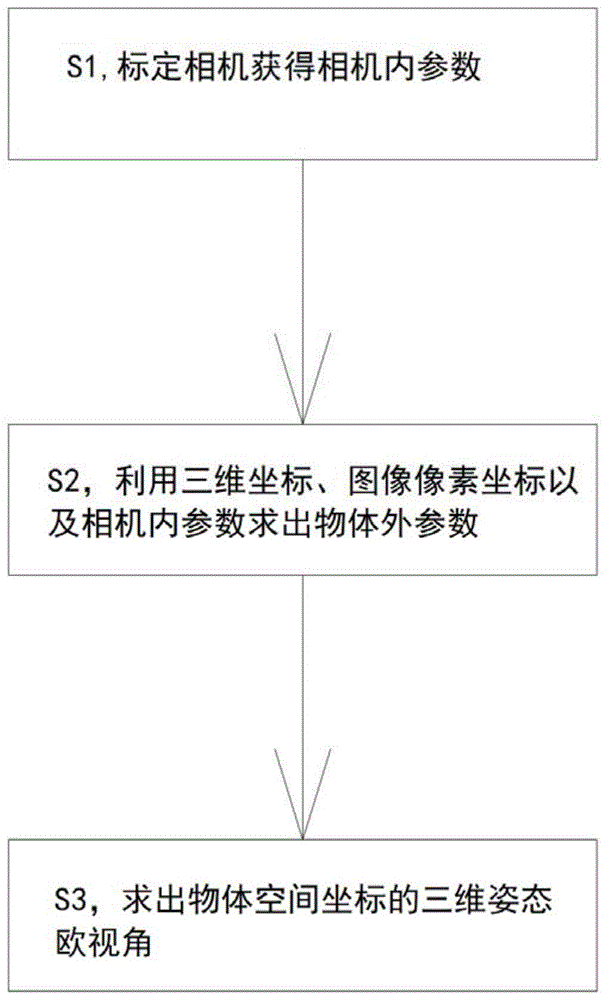
一种读写场景坐标认定方法,其特征在于,步骤包括:
s1,通过相机标定得出相机的内参数;
s2,利用已知物体在三维空间的坐标,在图像上一一对应的图像像素坐标以及相机内参数进而求解出此时相机相对于空间已知物体的外参数,即旋转向量以及平移向量;
s3,对旋转向量进行数据分析处理,求解出此时相机相对于已知物体空间坐标的三维姿态欧视角。
进一步的,所述相机的内参数包括基本参数和畸变系数变量,所述基本参数包括图像光轴主点,x,y方向焦距,所述畸变系数向量包括切向畸变系数和径向畸变系数。
进一步的,采用针孔成像模型计算得出物体的三维坐标,设定一个投影中心,主点为穿过光轴的图像主点,(x,y,z)为空间坐标系下的物体坐标,(x,y,z)为图像像素坐标。
进一步的,采用opencv提供的solvepnp以及solvepnpranssac函数来求解出相对于已知物体的三维空间坐标系的旋转和平移向量。
进一步的,利用相机内参数,相机外参数以及自定义的3d空间坐标点(0.0,0.0,0.0),(1.5,0.0,0.0,),(0.0,0.0,1.5),即分别对应空间原点,空间x轴,空间y轴,空间z轴,求解出一一对应的图像2d坐标点;使用opencv提供的projectpoints函数解算出已知空间轴坐标点对应的图像坐标上的坐标点,最后将对应图像坐标点连在一起即为物体的空间坐标系。
本发明提供的一种读写场景坐标认定方法的有益效果在于:可以有效获取使用者阅读时的体态姿势和距离并对不正确的予以提醒,通过阅读姿势和阅读距离的双重检测判断达到了更佳的检测效果,以及时矫正降低近视眼的发生概率;利用单目相机即可获取准确的三维姿态欧视角,然后通过欧视角的比对进行有效判断,准确率高,且仅使用单目相机成本低,实用性广;设置的单目相机具有一定角度,有效规避了轻微低头和晃动的计算误差。
附图说明
图1为本发明整体流程图;
图2为针孔成像模型的计算示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。本领域普通人员在没有做出创造性劳动前提下所获得的所有其他实施例,均属于本发明的保护范围。
实施例:一种读写场景坐标认定方法。
一种读写场景坐标认定方法,其特征在于,步骤包括:
单目相机采集图片并发送至处理器存储分析;利用单目相机相对于被检测物体平面的三维姿态欧视角,即俯仰角、偏航角、滚轮角;
首先,通过相机标定得出相机的内参数,然后利用已知物体在三维空间的坐标,在图像上一一对应的图像像素坐标以及相机内参数进而求解出此时相机相对于空间已知物体的外参数,即旋转向量以及平移向量,最后对旋转向量进行数据分析处理,求解出此时相机相对于已知物体空间坐标的三维姿态欧视角。
相机标定:在这里,摄像头的成像模型是以针孔成像为准的,但是由于透镜本身以及相机制造工艺等问题,致使成像模型不能百分百的按照针孔成像模型输出图像,输出图像必然存在畸变。因此,需要对相机进行标定,标定的目的是求解出相机内参数,内参数包括相机基本参数(图像光轴主点,x,y方向焦距)以及畸变系数向量(切向畸变系数,径向畸变系数)。
采用棋盘标定法进行相机的标定,棋盘标定法的基本思想是通过三维场景中拍摄同一棋盘标定板在不同方向,不同位置的多张棋盘图片,因为每一张棋盘图片的角点都是等间距的,即棋盘角点的空间三维坐标是已知的(三维空间坐标系相对于每一张棋盘物体而言),然后计算出每张棋盘图像在图像平面的像素坐标,有了每张棋盘图的三维空间坐标以及对应的图像像素平面的二维像素坐标一一对应投影关系,进而求出相机的内参数。
opencv提供calibratecamera()函数进行标定,利用该函数得出相机的内参数,包括相机基本矩阵:
相机姿态估计关键算法是解决n点透视投影问题,也称作pnp(persperctive-n-point)问题,在这里,我们以针孔成像模型为准。o为投影中心,主点(u0,v0)为穿过光轴的图像主点。(x,y,z)为空间坐标系下的物体坐标,这里的参考坐标系为相机的投影中心,(x,y,z)为图像像素坐标,图像像素坐标的原点为左上角。u0
根据上述的针孔投影关系,x=f*(x/z),我们可以容易地得出下列投影关系,使用矩阵形式表示上式,有:
当参考坐标系并不位于相机的投影中心时,如下式所示:
根据公式x=m*[r|t]*x,要求出外参数[r|t],必要知道相机基本矩阵m,以及已知物体在三维空间坐标点x,与之对应的图像像素坐标点x。
三维姿态欧视角解算:引入旋转平移矩阵[r|t],其中r为3*3旋转矩阵,t为3*1平移向量,有下列矩阵:
利用一个旋转矩阵可以表示为上面三个坐标轴矩阵:
为求出旋转角度
其中,atan2(y,x)的做法:当x的绝对值比y的绝对值大时使用atan(y/x);反之使用atan(x/y),保证了数值的稳定性,actan(y/x)是求反三角函数。
旋转矩阵r,三个坐标轴的旋转矩阵:
一个绕x轴旋转
一个绕y轴旋转θ的矩阵:
一个绕z轴旋转φ的矩阵:
相机三维姿态欧视角:偏航角yaw就是绕z轴旋转的角度φ,滚轮角roll就是绕y轴旋转的角度θ,俯仰角pitch就是绕x轴旋转的角度
利用已知的相机内参数(上面通过相机标定得出),以及已知2d图像坐标点(通过提取物体里面的正方形角点特征得出角点坐标),与空间对应的3d空间点(自定义,顺序要与2d角点顺序一直)求解出相机的外参数(即旋转向量,平移向量),本实施例中,使用opencv提供的solvepnp函数求解出外参数,最后利用相机内参数,相机外参数以及自定义的3d空间坐标点(0.0,0.0,0.0),(1.5,0.0,0.0,),(0.0,0.0,1.5),即分别对应空间原点,空间x轴,空间y轴,空间z轴,求解出一一对应的图像2d坐标点;使用opencv提供的projectpoints函数解算出已知空间轴坐标点对应的图像坐标上的坐标点,最后将对应图像坐标点连在一起即为物体的空间坐标系。
通过物体检测算法处理,判断是否有人体;将图片按照规定要求代入训练好的物体训练模型,获得人体的边框位置以及为人体的可信度。根据模型训练结果,人体可信度大于等于0.4的判断有人。其他判断为没人。同时获取桌面或者书本的四个顶点,用于后面计算距离。
人体检测是采用标定好的数据集,对mobilenet-ssd模型,编译protobuf,objectdetectionapi是使用protobuf来训练模型和配置参数。
采用vgg16作为基础模型,将vgg16的全连接层fc6和fc7转换成3*3但dilationrate=6卷积层conv6和1*1卷积层conv7,移除dropout层和fc8层,并新增了卷积层来获得更多的特征图以用于预测offset和confidence。
算法的输入是300*300*3,采用conv4_3(特征图大小38*38),conv7(19*19),conv8_2(10*10),conv9_2(5*5),conv10_2(3*3)和conv11_2(1*1)的输出共提取了6个特征图来预测location和confidence,一共可以预测38*38*4+19*19*6+10*10*6+5*5*6+3*3*4+1*1*4=8732个边界框(defaultbox)。
边界框不同的长宽比:[1,2,3,1/2,1/3],边界框的长、宽和中心的计算公式如下:
人体检测模型读进去的数据是归一化之后的数据,也就是需要把标注的坐标和得到的物体的长和宽除以原始图片的长和宽。
损失函数分为两部分:定位损失和分类损失,对于反例预测框,其定位损失是零。
深度可分离卷积:深度可分离卷积将标准卷积分为深度卷积和一个1*1卷积即逐点卷积。深度卷积针对单个输入通道用单个卷积核进行卷积,得到输入通道数的深度,然后运用一个1*1卷积,来对深度卷积中的输出进行线性结合。
输入特征图卷积核输出特征图
df×df×mdk×dk×m×ndg×dg×n
标准卷积计算量:dk×dk×m×n×df×df
深度可分离卷积计算量:dk×dk×m×df×df+m×n×df×df。
通过人脸检测算法处理,判断是否有人脸;确定图片中有人之后,检测图片是否有脸。。所以人脸将图片按照规定要求代入训练好的模型,获得人眼(左右眼),鼻子,嘴巴(两角)的5个点的位置以及为人脸的可信度。根据模型训练结果,可信度大于等于0.4的判断有人脸。其他判断为没人脸。
人脸检测模型训练是通过mtcnn,multi-taskconvolutionalneuralnetwork(多任务卷积神经网络),将人脸区域检测与人脸关键点检测放在了一起,基于cascade框架的。总体可分为pnet、rnet、和onet三层网络结构。
p-net全称为proposalnetwork,其基本的构造是一个全连接网络。对上一步构建完成的图像金字塔,通过一个fcn进行初步特征提取与标定边框,并进行bounding-boxregression调整窗口与nms进行大部分窗口的过滤。
一般pnet只做检测和人脸框回归两个任务,虽然网络定义的时候input的size是12*12*3,由于pnet只有卷积层,我们可以直接将resize后的图像喂给网络进行前传,只是得到的结果就不是1*1*2和1*1*4,而是m*m*2和m*m*4了。这样就不用先从resize的图上截取各种12*12*3的图再送入网络了,而是一次性送入,再根据结果回推每个结果对应的12*12的图在输入图片的什么位置。
针对金字塔中每张图,网络forward计算后都得到了人脸得分以及人脸框回归的结果。人脸分类得分是两个通道的三维矩阵m*m*2,其实对应在网络输入图片上m*m个12*12的滑框,结合当前图片在金字塔图片中的缩放scale,可以推算出每个滑框在原始图像中的具体坐标。首先要根据得分进行筛选,得分低于阈值的滑框,排除。然后利用nms非极大值抑制,对剩下的滑框进行合并。当金字塔中所有图片处理完后,再利用nms对汇总的滑框进行合并,然后利用最后剩余的滑框对应的bbox结果转换成原始图像中像素坐标,也就是得到了人脸框的坐标。
r-net全称为refinenetwork,其基本的构造是一个卷积神经网络,相对于第一层的p-net来说,增加了一个全连接层,因此对于输入数据的筛选会更加严格。在图片经过p-net后,会留下许多预测窗口,我们将所有的预测窗口送入r-net,
将pnet运算出来的人脸框从原图上截取下来,并且resize到24*24*3,作为rnet的输入。输出仍然是得分和bbox回归结果。对得分低于阈值的候选框进行抛弃,剩下的候选框做nms进行合并,然后再将bbox回归结果映射到原始图像的像素坐标上。所以,rnet最终得到的是在pnet结果中精选出来的人脸框。
o-net全称为outputnetwork,基本结构是一个较为复杂的卷积神经网络,相对于r-net来说多了一个卷积层。o-net的效果与r-net的区别在于这一层结构会通过更多的监督来识别面部的区域,而且会对人的面部特征点进行回归,最终输出五个人脸面部特征点。
将rnet运算出来的人脸框从原图上截取下来,并且resize到48*48*3,作为onet的输入。输出是得分,bbox回归结果以及landmark位置数据。分数超过阈值的候选框对应的bbox回归数据以及landmark数据进行保存。将bbox回归数据以及landmark数据映射到原始图像坐标上。再次实施nms对人脸框进行合并。
mtcnn特征描述子主要包含3个部分,人脸/非人脸分类器,边界框回归,地标定位。
人脸分离的交叉熵损失函数为:
边界框回归通过读写场景坐标认定方法距离计算回归损失:
地标定位通过读写场景坐标认定方法距离计算:
人脸检测模块多个输入源的训练为:
p-netr-net(αdet=1,αbox=0.5,αlandmark=0.5),
o-net(αdet=1,αbox=0.5,αlandmark=0.5),其中n为训练样本数量,αj为任务的重要性,
在训练过程中,
0-0.3:非人脸
0.65-1.00:人脸
0.4-0.65:part人脸
0.3-0.4:地标
训练样本的比例,负样本:正样本:part样本:地标=3:1:1:2。
根据人脸检测算法标定的数据,判断姿态是否符合正确的阅读写作标准;台灯搭载的摄像头距离底座平面15cm,只要台灯摆放在以人为中心的30°至150°范围内,人到摄像头距离80cm范围内,人坐姿端正的情况下,摄像头拍出来的图片都能够包括人的完整头部及清晰的脸部。拍摄出来的图片能够满足人脸识别模型计算的要求。人在正常读写时,双肩放平头部有轻微的低头,为了规避轻微低头导致的计算误差,本台灯搭载的摄像头具有约15°仰角。
本方法判断读写正确姿势的条件为(两个条件必须同时满足):
a.人坐姿端正,没有大幅度歪头、低头
b.眼睛距离桌面大于35厘米
根据人脸模型可以得到三个角度分别为yaw,roll,picth,满足姿势错误的情况有以下几种:
①yaw在[0,30)区间内
②yaw在[30,45)区间内,并且roll小于-10
③yaw大于等于45,并且roll小于0
④yaw在[-10,0)区间内,并且roll小于-3
⑤yaw在[-40,-30)区间内,并且roll小于-5
⑥yaw在[-30,-10)区间内,并且roll小于-10
⑦yaw大于-40,并且roll小于-30
通过距离计算,判断人眼睛与桌面的距离是否大于正确阅读写作的距离;根据物体训练模型返回的桌面或者书本四个顶点坐标,根据四个顶点计算出四边形对角线的交叉点坐标,又根据得到的人眼坐标(左右眼的坐标的中心点)。计算出交叉点到人眼中心点的距离。根据这个距离与相机焦距的比例关系可以算出,人眼到桌面或者书本的实际距离。当这个距离小于35厘米则认为该姿势错误。
判断规定时间内累积的姿势错误和距离错误总和是否大于规定的标准,并依据结果进行语音提醒。
本发明设计的基础原理如下:
fcn(全卷机网络)
全卷积网络就是去除了传统卷积网络的全连接层,然后对其进行反卷积对最后一个卷积层(或者其他合适的卷积层)的featuremap进行上采样,使其恢复到原有图像的尺寸(或者其他),并对反卷积图像的每个像素点都可以进行一个类别的预测,同时保留了原有图像的空间信息。同时,在反卷积对图像进行操作的过程中,也可以通过提取其他卷积层的反卷积结果对最终图像进行预测,合适的选择会使得结果更好、更精细。
iou
对于某个图像的子目标图像和对这个子目标图像进行标定的预测框,把最终标定的预测框与真实子图像的自然框(通常需要人工标定)的某种相关性叫做iou(intersectionoverunion),经常使用的标准为两个框的交叉面积与合并面积之和。
bounding-boxregression:
解决的问题:当iou小于某个值时,一种做法是直接将其对应的预测结果丢弃,而bounding-boxregression的目的是对此预测窗口进行微调,使其接近真实值。
具体逻辑
在图像检测里面,子窗口一般使用四维向量(x,y,w,h)表示,代表着子窗口中心所对应的母图像坐标与自身宽高,目标是在前一步预测窗口对于真实窗口偏差过大的情况下,使得预测窗口经过某种变换得到更接近与真实值的窗口。
在实际使用之中,变换的输入输出按照具体算法给出的已经经过变换的结果和最终适合的结果的变换,可以理解为一个损失函数的线性回归。
nms(非极大值抑制)
顾名思义,非极大值抑制就是抑制不是极大值的元素。在目标检测领域里面,可以使用该方法快速去掉重合度很高且标定相对不准确的预测框,但是这种方法对于重合的目标检测不友好。
soft-nms
对于优化重合目标检测的一种改进方法。核心在于在进行nms的时候不直接删除被抑制的对象,而是降低其置信度。处理之后在最后统一一个置信度进行统一删除。
prelu
在mtcnn中,卷积网络采用的激活函数是prelu,带有参数的带有参数的relu,相对于relu滤除负值的做法,prule对负值进行了添加参数而不是直接滤除,这种做法会给算法带来更多的计算量和更多的过拟合的可能性,但是由于保留了更多的信息,也可能是训练结果拟合性能更好。
以上所述为本发明的较佳实施例而已,但本发明不应局限于该实施例和附图所公开的内容,所以凡是不脱离本发明所公开的精神下完成的等效或修改,都落入本发明保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!