一种恶意代码家族聚类方法和系统与流程
本发明属于恶意代码分析的技术领域,涉及一种恶意代码家族聚类方法和系统。
背景技术:
k-means算法是经典的聚类算法之一,在利用k-means算法进行聚类时,需要预先设定聚类的类簇个数,即k。然而,在实际应用中数据集往往规模庞大,面对结构分布复杂的数据,人们很难事先确定类簇个数,当预先设定的类簇个数和实际类簇个数差距过大时,聚类效果会大大降低:当选择远小于实际类簇个数的k时,会将不同类的数据点聚类为同一类,导致类簇区分度过低;当选择远大于实际类簇个数的k时,会将同类的数据点聚类为不同类,导致丢失数据点之间的关联。
在现有技术中,确定k值的方法通常从后验信息着手,测试所有可能k值的聚类效果,利用统计分析等技术,分析聚类结果的类内相似度、类间相似度,从大量聚类结果中选择最优聚类效果对应的k值。然而,由于缺乏对数据结构分布的整体把握,面对庞大的数据量,在测试过程中k的可能取值范围一般较大,这导致测试计算量庞大,且耗费大量计算资源。因此,使用一些技术创新方法来寻找和确定最优的k值是非常必要的。
技术实现要素:
本发明的主要目的在于克服现有技术的缺点与不足,提供一种恶意代码家族聚类方法,采用t-sne算法可视化恶意代码家族特征确定家族簇数,然后使用k-means算法对恶意代码家族进行家族聚类,从而缩小k值的取值范围,减少计算开支,增加聚类准确度。
本发明的另一目的在于,提供一种恶意代码家族聚类系统。
为了达到上述第一目的,本发明采用以下技术方案:
本发明提供的一种恶意代码家族聚类方法,包括下述步骤:
采用t-sne算法对原始恶意代码执行序列进行降维可视化,具体包括下述步骤:
使用t-sne算法对每个数据点近邻的分布进行建模,其中近邻是指相互靠近数据点的集合;
构建模型,通过非线性函数变换将数据点映射到相应概率分布上;
对构建的模型进行训练,通过计算低维空间的条件概率,从而计算损失函数的梯度;
使用k-means算法对恶意代码家族进行聚类,具体包括下述步骤:
确定分类个数k和聚类中心;
通过计算对象与聚类中心的距离对所有对象进行簇划分;
重新计算新的聚类中心,判断是否满足中心点不再改变的条件,如果不满足,则返回通过计算对象与聚类中心的距离对所有对象进行簇划分的步骤,如果满足,则找到聚类中心点。
作为优选的技术方案,所述通过非线性函数变换将数据点映射到相应概率分布上的,包括下述步骤:
通过在高维空间中构建数据点之间的概率分布,使得相似的数据点有更高的概率被选择,不相似的数据点有较低的概率被选择;
在低维空间里重构所有数据点的概率分布q,使得这两个概率分布尽可能相似。
作为优选的技术方案,还包括计算相似度的步骤,具体为:
令输入空间是x∈rn,输出空间为y∈rt,t<<n,假设含有m个样本数据{x(1),x(2),…,x(m)},其中x(i)∈x,降维后的数据为{y(1),y(2),…,y(m)},y(i)∈y,sne是先将欧几里得距离转化为条件概率来表达点与点之间的相似度,即首先是计算条件概率pj|i,其正比于x(i)和x(j)之间的相似度,pj|i的计算公式为:
在这里引入了一个参数σi,对于不同的数据点x(i)取值亦不相同,并设置pi|i=0,对于低维度下的数据点y(i),通过条件概率qj|i来刻画y(i)与y(j)之间的相似度,qj|i的计算公式为:
同理,设置qi|i=0。
作为优选的技术方案,如果pi|j=qi|j成立,则通过优化两个分布之间的kl散度构造出的损失函数为:
其中,pi表示在给定高维数据点x(i)时,其他所有数据点的条件概率分布;qi则表示在给定低维数据点y(i)时,其他所有数据点的条件概率分布;从损失函数可以看出,当pj|i较大qj|i较小时,惩罚较高;而pj|i较小qj|i较大时,惩罚较低。
作为优选的技术方案,还包括对损失函数的梯度进行优化的步骤:
首先通过在高维空间中使用高斯分布将距离转换为概率分布,然后在低维空间中,使用更加偏重长尾分布的方式来将距离转换为概率分布,使得高维度空间中的中低等距离在映射后能够有一个较大的距离;
使用t分布替换高斯分布之后qij的变化如下:
此外,随着自由度的逐渐增大,t分布的密度函数逐渐接近标准正态分布,优化后的梯度公式如下:
作为优选的技术方案,步骤(1.3)中,对构建的模型进行训练具体为:
数据准备:{x(1),x(2),…,x(m)},其中x(i)∈rn;
初始化困惑度参数用于求解σ,迭代次数t、学习率η和动量α(t);
开始优化,具体为:
计算高维空间中的条件概率pj|i;
令
使用正态分布
从t=1,2,…,t进行迭代
计算低维空间中的条件概率qij;
计算损失函数c(y(i))对y(i)的梯度;
更新
输出y。
作为优选的技术方案,所述确定分类个数k和聚类中心,具体为:
通过t-sne算法可视化出每一个恶意代码文件的特征,从而确定聚类簇数k,确定聚类簇数k后使用k-means算法进行聚类处理。
作为优选的技术方案,所述通过计算对象与聚类中心的距离对所有对象进行簇划分,具体为:
确定聚类簇数k后,k-means算法就是将n个数据点进行聚类,得到k个聚类,使得每个数据点到聚类中心的距离最小。
为了达到上述第二目的,本发明采用以下技术方案:
本发明提供的一种述恶意代码家族聚类系统,包括降维可视化模块和聚类模块,所述降维可视化模块,用于采用t-sne算法对原始恶意代码执行序列进行降维可视化,所述聚类模块用于使用k-means算法对恶意代码家族进行聚类;
所述降维可视化模块包括数据点处理模块、模型建立模块以及训练模块,
所述数据点处理模块,用于使用t-sne算法对每个数据点近邻的分布进行建模,其中近邻是指相互靠近数据点的集合;
所述模型建立模块,用于构建模型,通过非线性函数变换将数据点映射到相应概率分布上;
所述训练模块,用于对构建的模型进行训练,通过计算低维空间的条件概率,从而计算损失函数的梯度;
所述聚类模块包括分类个数和聚类中心确定模块、簇划分模块以及聚类中心重新计算模块;
所述分类个数和聚类中心确定模块,用于确定分类个数k和聚类中心;
所述簇划分模块,用于通过计算对象与聚类中心的距离对所有对象进行簇划分;
所述聚类中心重新计算模块,用于重新计算新的聚类中心,判断是否满足条件,如果不满足,则返回通过计算对象与聚类中心的距离对所有对象进行簇划分的步骤,如果满足,则得出结论。
作为优选的技术方案,所述模型构建模块包括高维空间处理模块和低维空间处理模块;
所述高维空间处理模块,用于通过在高维空间中构建数据点之间的概率分布p,使得相似的数据点有更高的概率被选择,不相似的数据点有较低的概率被选择;
所述低维空间处理模块,用于在低维空间里重构这些点的概率分布q,使得这两个概率分布尽可能相似。
本发明与现有技术相比,具有如下优点和有益效果:
本发明从数据集的总体分布结构入手,在数据预处理阶段利用t-sne算法对数据集进行可视化,利用数据可视化技术分析数据分布情况,估算类簇个数的大概取值区间,最后用传统测试方法进行k值的选择,通过本发明缩小了k值的取值范围,减少计算开支,增加聚类准确度。
附图说明
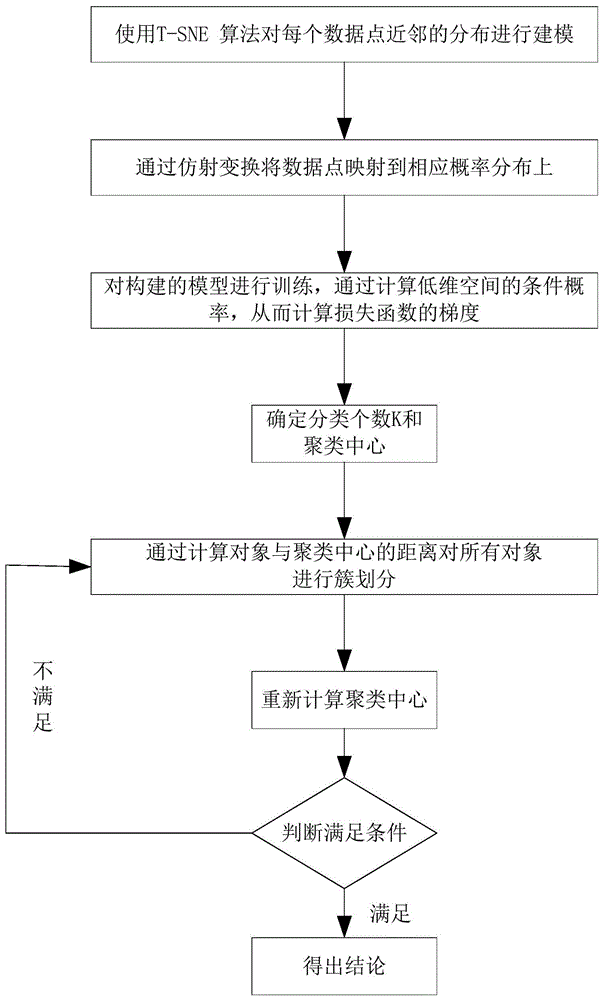
图1是本发明恶意代码家族聚类方法的流程图。
图2是本发明恶意代码家族聚类系统的与方框图。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
实施例
如图1所示,本实施例一种恶意代码家族聚类方法,是一种有效的基于t-sne和k-means算法的恶意代码家族聚类方法,该方法主要将恶意代码执行序列作为原始特征,采用t-sne算法可视化恶意代码家族簇数,然后使用k-means算法对恶意代码家族进行聚类。本发明的方法包括下述步骤:
(1)采用t-sne算法对原始恶意代码执行序列进行降维可视化;包括下述步骤:
(1.1)使用t-sne算法对每个数据点近邻的分布进行建模,其中近邻是指相互靠近数据点的集合;在原始高维空间中,本发明将高维空间建模为高斯分布,而在二维输出空间中,本发明可以将其建模为t分布。该过程的目标是找到将高维空间映射到二维空间的变换,并且最小化所有点在这两个分布之间的差距。与高斯分布相比t分布有较长的尾部,这有助于数据点在二维空间中更均匀地分布。
(1.2)构建模型,通过非线性函数变换将数据点映射到相应概率分布上,主要包括下述两个步骤:
(1.2.1)通过在高维空间中构建数据点之间的概率分布p,使得相似的数据点有更高的概率被选择,不相似的数据点有较低的概率被选择;
(1.2.2)在低维空间里重构这些点(所有数据点,即恶意代码)的概率分布q,使得这两个概率分布尽可能相似。
令输入空间是x∈rn,输出空间为y∈rt,t<<n,假设含有m个样本数据{x(1),x(2),…,x(m)},其中x(i)∈x,降维后的数据为{y(1),y(2),…,y(m)},y(i)∈y,sne是先将欧几里得距离转化为条件概率来表达点与点之间的相似度,即首先是计算条件概率pj|i,其正比于x(i)和x(j)之间的相似度,pj|i的计算公式为:
在这里引入了一个参数σi,对于不同的数据点x(i)取值亦不相同,并设置pi|i=0,对于低维度下的数据点y(i),通过条件概率qj|i来刻画y(i)与y(j)之间的相似度,qj|i的计算公式为:
同理,设置qi|i=0。
如果降维的效果比较好,局部特征保留完整,则有pi|j=qi|j成立,则通过优化两个分布之间的kl散度构造出的损失函数为:
其中,pi表示在给定高维数据点x(i)时,其他所有数据点的条件概率分布;qi则表示在给定低维数据点y(i)时,其他所有数据点的条件概率分布;从损失函数可以看出,当pj|i较大qj|i较小时,惩罚较高;而pj|i较小qj|i较大时,惩罚较低。也就是说,高维空间中两个数据点距离较近时,若映射到低维空间后距离较远,那么将得到一个很高的惩罚;反之,高维空间中两个数据点距离较远时,若映射到低维空间距离较近,将得到一个很低的惩罚值。
t-sne在对称sne的改进是,首先通过在高维空间中使用高斯分布将距离转换为概率分布,然后在低维空间中,使用更加偏重长尾分布的方式来将距离转换为概率分布,使得高维度空间中的中低等距离在映射后能够有一个较大的距离。
使用t分布替换高斯分布之后qij的变化如下:
此外,随着自由度的逐渐增大,t分布的密度函数逐渐接近标准正态分布,
优化后的梯度公式如下:
总的来说,t-sne的梯度更新具有以下两个优势:
(a)对于低维空间中不相似的数据点,用一个较小的距离会产生较大的梯度让这些数据点排斥开来;
(b)这种排斥又不会无限大,因此避免了不相似的数据点距离太远。
(1.3)对构建的模型进行训练,通过计算低维空间的条件概率,从而计算损失函数的梯度;
(1.3.1)数据准备:{x(1),x(2),…,x(m)},其中x(i)∈rn;
(1.3.2)初始化困惑度参数用于求解σ,迭代次数t(500)、学习率η(0.01)和动量α(t);
(1.3.3)开始优化,具体为:
(1.3.3.1)计算高维空间中的条件概率pj|i;
(1.3.3.2)令
(1.3.3.3)使用正态分布
(1.3.3.4)从t=1,2,…,t进行迭代
(1.3.3.5)计算低维空间中的条件概率qij;
(1.3.3.6)计算损失函数c(y(i))对y(i)的梯度;
(1.3.3.7)更新
(1.3.3.8)输出y。
(2)使用k-means算法对恶意代码家族进行聚类,具体包括下述步骤:
(2.1)确定分类个数k和聚类中心;通过t-sne算法可视化出每一个恶意代码文件的特征,从图中就可以确定聚类簇数k,确定聚类簇数k后就可以使用k-means算法进行聚类处理了。t-sne算法只是进行可视化确认恶意代码家族个数,属于k-means算法辅助。
(2.2)通过计算对象与聚类中心的距离对所有对象进行簇划分;在上一步确定聚类簇数k后,k-means算法就是将n个数据点进行聚类,得到k个聚类,使得每个数据点到聚类中心的距离最小。
(2.3)重新计算新的聚类中心,判断是否满足条件(即中心点不再改变),如果不满足,则返回通过计算对象与聚类中心的距离对所有对象进行簇划分的步骤,如果满足,则聚类中心点就已经找到。
在本发明的另一实施例中,如图2所示,提供了一种述恶意代码家族聚类系统,包括降维可视化模块和聚类模块,所述降维可视化模块,用于采用t-sne算法对原始恶意代码执行序列进行降维可视化,所述聚类模块用于使用k-means算法对恶意代码家族进行聚类;
所述降维可视化模块包括数据点处理模块、模型建立模块以及训练模块,
所述数据点处理模块,用于使用t-sne算法对每个数据点近邻的分布进行建模,其中近邻是指相互靠近数据点的集合;
所述模型建立模块,用于构建模型,通过非线性函数变换将数据点映射到相应概率分布上;
所述训练模块,用于对构建的模型进行训练,通过计算低维空间的条件概率,从而计算损失函数的梯度;
所述聚类模块包括分类个数和聚类中心确定模块、簇划分模块以及聚类中心重新计算模块;
所述分类个数和聚类中心确定模块,用于确定分类个数k和聚类中心;
所述簇划分模块,用于通过计算对象与聚类中心的距离对所有对象进行簇划分;
所述聚类中心重新计算模块,用于重新计算新的聚类中心,判断是否满足条件,如果不满足,则返回通过计算对象与聚类中心的距离对所有对象进行簇划分的步骤,如果满足,则得出结论。
所述模型构建模块包括高维空间处理模块和低维空间处理模块;
所述高维空间处理模块,用于通过在高维空间中构建数据点之间的概率分布p,使得相似的数据点有更高的概率被选择,不相似的数据点有较低的概率被选择;
所述低维空间处理模块,用于在低维空间里重构这些点的概率分布q,使得这两个概率分布尽可能相似。
需说明的是,以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。另外,本发明提供的系统实施例附图中,模块之间的连接关系表示它们之间具有通信连接,具体可以实现为一条或多条通信总线或信号线。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!