基于个人计算机电商评论的多粒度观点挖掘方法与流程
本发明属于计算机自然语言处理技术领域,具体涉及一种基于个人计算机电商评论的多粒度观点挖掘方法。
背景技术:
随着网络技术的迅速发展,以及计算机、手机等互联设备的普及,新兴业态快速增长和新商业模式不断涌现,使得人们的消费方式发生了巨大的变革。近年来,网络购物正日益成为一种重要的消费方式,不断推动着电商的蓬勃发展。人们也愈加倾向于借助电商平台来发表自己消费后的感受,于是就产生了大量的网络评论。
网络评论的类型包括新闻评论、图书评论、影视评论以及产品和服务评论,针对电商的网络评论通常是针对某一个商品实体进行描述,并且涵盖较多主观倾向的信息。这其中除了对商品的整体评价之外,通常也会对商品的多个属性方面进行评价,无论对于商家还是消费者,这些细节信息才是他们关注的重点,使用传统的人工方法对评论进行统计、分析和挖掘,已无法满足对海量数据进行快速分析和处理的需求,现有的自动化观点挖掘技术缺乏对电商评论中包含的各个属性方面的反馈信息的挖掘,挖掘这些细粒度的信息,可为消费者作指引,以及商家可以从中得到市场反馈,进而改进服务,提升商品质量。
技术实现要素:
本发明的目的是提供一种基于个人计算机电商评论的多粒度观点挖掘方法,解决了现有技术中存在的无法自动化地挖掘评论中包含的各个属性方面的反馈信息的问题。
本发明所采用的技术方案是,基于个人计算机电商评论的多粒度观点挖掘方法,具体按照以下步骤实施:
步骤1、从网页中获取电商评论,评论中包含评论文本和评论的5分制数字评分,将产品评论按数字评分进行星级划分:将数字评分大于3分的评论定为积极评论,将数字评分小于等于3分的评论定为消极评论,以此作为特征向量类别标注的依据;
步骤2、对步骤1的电商评论进行分词、去除停用词和词性标注操作,得到预处理后的语料;
步骤3、对步骤2得到的预处理后的语料中的每一条评论的每一个单句进行“方面-观点”对的识别,并区分观点词和方面词;
步骤4、提取步骤3识别出的每一个方面的上下文短语,并对方面的上下文短语进行短语级别的情感分析,得到每一个方面的情感倾向度;
步骤5、对于步骤2得到的预处理后语料中的每一条评论,以步骤3中提取出的方面为特征构建特征向量,并训练和测试支持向量机分类器,最后得到商品整体的情感倾向度。
本发明的特点还在于,
步骤1中采用网络爬虫技术将网页上的评论进行抓取,发起请求使用python的request模块向电商评论网页站点发起请求,获取响应内容,并对网页中的网络评论和打分星级进行解析和保存。
步骤2中分词所采用的方法是基于词典的正向最大匹配算法,词性标注采用基于隐马尔可夫模型的词性标注方法。
步骤2中基于词典的正向最大匹配算法具体如下:
词典由python的jieba模块中的词典以及停用词表构成;
首先从网页中获取电商评论中取出一条评论记为字符串s1,并整合台湾大学简体中文情感字典、hownet、dtuir三大现有词典组成情感词典,并构建哈希表;
设情感词典中最大词长为maxlen,从字符串s1的左边开始,取出长度不大于maxlen的子串w,同时在哈希表中搜索子串w是否是一个词,若是,则将子串w输出为一个词,若不是一个词,则从子串w的尾部减去一个字,继续迭代地判断子串w是否在哈希表中,直至子串w为空或者字符串s1为空。
步骤2中基于隐马尔可夫模型的词性标注方法具体如下:
此方法分为三个模块:initialise,induction,backtracingthebesttagging;
首先在模块initialise中统计每个词性出现在语料文本句首的概率,并乘以词性喷射出词的概率得到一个词的score分数;
然后在模块induction中用viterbi算法计算每两个相邻出现的词的score分数,等于这个词性的初始score分数乘以词性间转换的概率乘以词性喷射到这个词的概率;
从最终score分数中选择分数值大的词性值记录在模块backpointer中;
最后在模块backtracingthebesttagging中进行从后往前的回溯,得到词性构成的序列串str2。
步骤3中对单句进行“方面-观点”对的识别所采用的方法是asum模型,使用gibbs采样估计asum模型中的狄利克雷分布参数,然后结合台湾大学简体中文情感字典、hownet、dtuir三大情感词典以及基于word2vec的近义词识别,使用字符串匹配的算法将asum模型识别出的<方面,观点>对中的主题词和观点词进行区分。
步骤4中使用基于语义的方法和句法分析相结合进行短语级别的情感分析,具体如下:
首先根据汉语的句法结构和词性搭配的规则人为构建语义规则和情感权值计算公式,构建的语义规则对应的情感权值计算规则如下:
如果词性搭配为程度副词+情感词,则对应的情感词权值计算为程度副词的权值×情感词权值;
如果词性搭配为否定词+情感词,则对应的情感词权值计算为(-1)×情感词权值;
如果词性搭配为副词+否定词+情感词,则对应的情感词权值计算为程度副词的权值×(-1)×情感词权值;
如果词性搭配为否定词+副词+情感词,则对应的情感词权值计算为(0.5)×程度副词的权值×情感词权值;
如果词性搭配为单句的情感倾向度,则对应的情感权值计算为∑情感词权值;
情感词权值来自于dtuir情感词典,通过匹配语料中单句的词性搭配规则,并对单句的情感权值进行计算,得到每一个方面的情感倾向度。
步骤5中具体为:将提取出的方面作为特征,将方面的情感得分值作为特征权重,将电商评论映射成特征向量,并且使用支持向量机分类器对评论进行文档级的情感分类。
本发明的有益效果是,对个人计算机电商评论先做细粒度的观点挖掘,识别出消费者对于评价实体的多个属性,以及对于各个属性表达出的观点,根据消费者评价属性的不同对电商评论进行单句级别的划分,对每一个属性下的单句做情感分析,得出消费者对于评价实体在各个属性维度上的情感倾向;然后再根据不同属性对于商品的重要程度不同,使用属性做特征,特征权重是属性的情感得分值,将一条电商评论映射成特征向量,并且使用半监督的机器学习算法对评论进行分类,做一个粗粒度的观点挖掘,得到消费者对于商品整体的情感倾向,反馈给消费者和商家做决策。
附图说明
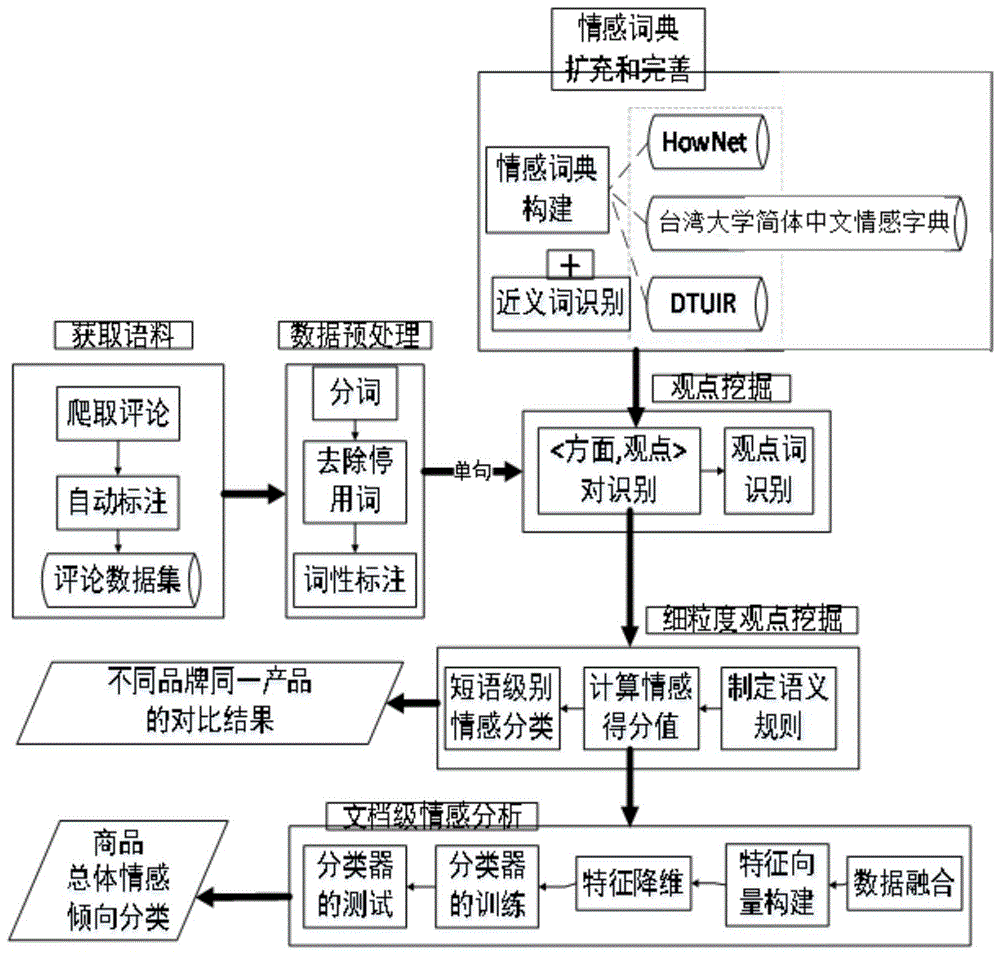
图1是基于个人计算机电商评论的多粒度观点挖掘方法流程图;
图2是基于个人计算机电商评论的多粒度观点挖掘方法中asum模型。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
本发明基于个人计算机电商评论的多粒度观点挖掘方法,流程图如图1所示,具体按照以下步骤实施:
步骤1、从网页中获取电商评论,评论中包含评论文本和评论的5分制数字评分,将产品评论按数字评分进行星级划分:将数字评分大于3分的评论定为积极评论,将数字评分小于等于3分的评论定为消极评论,以此作为特征向量类别标注的依据;
步骤2、对步骤1的电商评论进行分词、去除停用词和词性标注操作,得到预处理后的语料;
步骤3、对步骤2得到的预处理后的语料中的每一条评论的每一个单句进行“方面-观点”对的识别,并区分观点词和方面词;
步骤4、提取步骤3识别出的每一个方面的上下文短语,并对方面的上下文短语进行短语级别的情感分析,得到每一个方面的情感倾向度;
步骤5、对于步骤2得到的预处理后语料中的每一条评论,以步骤3中提取出的方面为特征构建特征向量,并训练和测试支持向量机分类器,最后得到商品整体的情感倾向度。
其中,步骤1中采用网络爬虫技术将网页上的评论进行抓取,发起请求使用python的request模块向电商评论网页站点发起请求,获取响应内容,并对网页中的网络评论和打分星级进行解析和保存。
步骤2中分词所采用的方法是基于词典的正向最大匹配算法,词性标注采用基于隐马尔可夫模型的词性标注方法。
步骤2中基于词典的正向最大匹配算法具体如下:
词典由python的jieba模块中的词典以及停用词表构成;
首先从网页中获取电商评论中取出一条评论记为字符串s1,并整合台湾大学简体中文情感字典、hownet、dtuir三大现有词典组成情感词典,并构建哈希表;
设情感词典中最大词长为maxlen,从字符串s1的左边开始,取出长度不大于maxlen的子串w,同时在哈希表中搜索子串w是否是一个词,若是,则将子串w输出为一个词,若不是一个词,则从子串w的尾部减去一个字,继续迭代地判断子串w是否在哈希表中,直至子串w为空或者字符串s1为空。
步骤2中基于隐马尔可夫模型的词性标注方法具体如下:
此方法分为三个模块:initialise,induction,backtracingthebesttagging;
首先在模块initialise中统计每个词性出现在语料文本句首的概率,并乘以词性喷射出词的概率得到一个词的score分数;
然后在模块induction中用viterbi算法计算每两个相邻出现的词的score分数,等于这个词性的初始score分数乘以词性间转换的概率乘以词性喷射到这个词的概率;
从最终score分数中选择分数值大的词性值记录在模块backpointer中;
最后在模块backtracingthebesttagging中进行从后往前的回溯,得到词性构成的序列串str2。
步骤3中对单句进行“方面-观点”对的识别所采用的方法是asum模型,如图2所示,使用gibbs采样估计asum模型中的狄利克雷分布参数,然后结合台湾大学简体中文情感字典、hownet、dtuir三大情感词典以及基于word2vec的近义词识别,使用字符串匹配的算法将asum模型识别出的<方面,观点>对中的主题词和观点词进行区分。
步骤4中使用基于语义的方法和句法分析相结合进行短语级别的情感分析,具体如下:
首先根据汉语的句法结构和词性搭配的规则人为构建语义规则和情感权值计算公式,构建的语义规则对应的情感权值计算规则如下:
如果词性搭配为程度副词+情感词,则对应的情感词权值计算为程度副词的权值×情感词权值;
如果词性搭配为否定词+情感词,则对应的情感词权值计算为(-1)×情感词权值;
如果词性搭配为副词+否定词+情感词,则对应的情感词权值计算为程度副词的权值×(-1)×情感词权值;
如果词性搭配为否定词+副词+情感词,则对应的情感词权值计算为(0.5)×程度副词的权值×情感词权值;
如果词性搭配为单句的情感倾向度,则对应的情感权值计算为∑情感词权值;
情感词权值来自于dtuir情感词典,通过匹配语料中单句的词性搭配规则,并对单句的情感权值进行计算,得到每一个方面的情感倾向度。
步骤5中具体为:将提取出的方面作为特征,将方面的情感得分值作为特征权重,将电商评论映射成特征向量,并且使用支持向量机分类器对评论进行文档级的情感分类。
本发明基于个人计算机电商评论的多粒度观点挖掘方法中,个人计算机电商评论中的方面包括内存、显卡、容量、驱动、散热、电池、电池、键盘、屏幕、价格、鼠标、速度等。
python的request模块是基于urllib编写的,采用的是apache2licensed开源协议的http库,使用request模块进行爬虫的基本流程包括如下:
(1)发起请求:通过http库向目标站点发起请求,请求可以包含额外的header等信息,等待服务器响应
(2)获取响应内容:如果服务器能正常响应,会得到一个response,response的内容便是所要获取的页面内容,类型可能是html,json字符串,二进制数据(图片或者视频)等类型
(3)解析内容:得到的内容可能是html,可以用正则表达式,页面解析库进行解析,可能是json,可以直接转换为json对象解析,可能是二进制数据,可以做保存或者进一步的处理
(4)保存数据:保存形式多样,可以存为文本,也可以保存到数据库,或者保存特定格式的文件
python的jieba模块是一个中文分词组件,支持简、繁体中文,用户还可以加入自定义词典以提高分词的准确率。jieba自带了一个叫做dict.txt的词典,里面有2万多个词,包含了词条出现的次数和词性。
基于隐马尔可夫模型的词性标注方法分为三个模块:initialise,induction,backtracingthebesttagging;initialise是计算每个词性出现在句首的概率,induction模块是计算每两个相邻的词性共同出现的概率,并将概率值存储在模块backpointer中,backtracingthebesttagging模块是从backpointer中回溯出概率值相乘最大的一条词性序列串。
实施例
首先从京东网页上爬取联想笔记本电脑的评论,从中摘取一条作为语料样本:“外观漂亮,速度还很快哦,最重要的是携带超级方便,电池续航能力很强!就是配送有些慢。”。
根据基于词典的正向最大匹配的算法,从原文中取一条待切分字符串进行分词,此时s1=“外观漂亮,速度还很快哦,最重要的是携带超级方便,电池续航能力很强!配送有些慢。”根据构造的词典确定maxlen为=10,s2初始化为空,将词典构造成哈希表。
从s1的左边选取长度不大于maxlen的子串w=“外观漂亮,速度还很快”,判断w是否为空,不为空,判断w是否是哈希表中的一个词,遍历哈希表,未找到匹配项。将w的右边减少一个字,w=“外观漂亮,速度还很”,继续迭代。直到w减少成“外观”,在哈希表中查找成功,将住宅添加到s2中,s2=“外观/”。s1=“漂亮,速度还很快哦,最重要的是携带超级方便,电池续航能力很强!配送有些慢。”迭代至s1为空时,此时输出s2=“外观/漂亮/,速度/还很/快,/最/重要/携带/超级/方便/,电池/续航能力/很强/!配送/有些/慢/。”
分词之后标记词的词性:首先人工标记一部分语料集的词性,然后用viterbi算法进行训练参数,通过机器学习对剩余的语料集进行自动标注,对未登录词进行平滑处理,对标注后的未登录词进行平滑处理,将正确的语料添加到训练集中继续训练更加可靠的参数。最后输出的语料为“{noun:外观}{adj:漂亮},{noun:速度}{adv:还很}{adj:快},{adv:最}{adj:重要}{v:携带}{adv:超级}{adj:方便},{noun:电池}{noun:续航能力}{adv:很}{adj:强}!{noun:配送}{adv:有些}{adj:慢}”。
按照“,。!;”这些标点符号以及换行符对语料样本进行分割单句:
·{noun:外观}{adj:漂亮},
·{noun:速度}{adv:还很}{adj:快},
·{adv:最}{adj:重要}{v:携带}{adv:超级}{adj:方便},
·{noun:电池}{noun:续航能力}{adv:很}{adj:强}!
·{noun:配送}{adv:有些}{adj:慢}。
使用asum模型识别出每一个单句的<方面,观点>对,如下所示:
·<外观,漂亮>
·<速度,很快>
·<携带,超级方便>
·<电池续航能力,很强>
·<配送,有些慢>
通过结合台湾大学简体中文情感字典、hownet、dtuir三大情感词典以及基于word2vec的近义词识别,对asum模型识别出的<主题,观点>对中的主题词和观点词进行区分,结果如下:
通过汉语的句法结构和词性搭配的规则人为构建语义规则和情感权值计算公式,得出每一个方面的情感得分值,结果如下:
设定阈值为0,大于阈值为积极的情感倾向,小于阈值为消极的情感倾向,得到每一个方面的情感倾向:
最后使用提取出的方面做特征,特征权重是方面的情感得分值,将语料样本映射成特征向量,[0.75,1.25,1.75,1.25,-0.5···],特征的维数由语料中所有评论重提取的方面词的个数决定,并且使用支持向量机分类算法对评论进行文档级的情感分类,输出被评价实体整体和多个属性方面的情感倾向性。
根据本发明的方法成功的得出个人计算机电商评论的整体情感倾向和个人计算机各个属性方面的情感倾向。
本发明通过从个人计算机电商评论中获取消费者对于商品各个属性方面的观点信息,并且分析个人计算机电商评论的情感倾向度,再根据属性对于商品的重要程度不同,将评论整体映射成特征向量,得到商品整体的情感分类结果,可为消费者作指引,以及商家可以从中得到市场反馈,进而改进服务,提升商品质量。
- 还没有人留言评论。精彩留言会获得点赞!