基于贝叶斯网络的动态数据流分类方法与流程
本发明属于计算机自然语言处理、数据挖掘技术领域,具体涉及一种基于贝叶斯网络的动态数据流分类方法。
背景技术:
随着大数据时代的到来,在线数据大幅增加,实时挖掘海量数据流已成为机器学习领域面临的一大挑战。在线学习方法通过对数据的逐条处理,并利用增量式更新模型的方法实现了海量数据的实时处理,受到了研究人员的广泛关注。在众多专用于数据流分类和在线学习的算法中,naivebayes分类器由于其简单性、在线性以及对时间和内存的低要求成为一种极具吸引力的方法。但朴素贝叶斯分类器并没有检测和处理概念漂移的机制,因此当出现数据非静止情况时会严重影响其分类性能。
技术实现要素:
本发明的目的是提供一种基于贝叶斯网络的动态数据流分类方法,解决了现有技术中存在的朴素贝叶斯分类器处理存在概念漂移和数据转移的动态数据流时分类性能大大降低的问题。
本发明所采用的技术方案是,基于贝叶斯网络的动态数据流分类方法,具体按照以下步骤实施:
步骤1、从互联网应用中采集关于用户点击新闻的批量数据,将所有数据分为若干数据块,每个数据块包含10000条数据,其中每个数据块表示互联网应用中某一时间段采集到的数据,所有数据块d1,d2,...di...,dn以流的形式呈现并留待之后处理,n表示数据块的个数,先在第一个数据块d1上使用朴素贝叶斯算法建立朴素贝叶斯模型,将数据块d1放入数据集d中;
步骤2:针对第i个数据块di,使用步骤1中建立的朴素贝叶斯模型对di进行分类,得到数据块di的10000条数据的类别,采用最大权重计算公式取得数据块di中每条数据的权重,并使用权重衰减的遗忘加权公式校正di中每条数据的权重;
步骤3:将数据块di合并入数据集d,剔除d中权重小于0.1的所有数据,随后在数据集d上基于更新后的权值采用朴素贝叶斯算法建立朴素贝叶斯模型;
步骤4:重复步骤2和步骤3,直到处理完数据流上的最后一个数据块dn,数据流的分类过程完成。
本发明的特点还在于,
步骤2中当处理到第k个数据块dk时,使用步骤1中建立的朴素贝叶斯模型对数据块dk进行分类,得到数据块dk的10000条数据的类别,朴素贝叶斯分类模型如下:
其中,cm表示第m个类别,p(cm|a1,a2,...,af)表示在特征为a1,a2,...,af时类别为cm的概率,p(cm)表示所有样本中类别为cm的概率,f为给定特征个数,aj表示第j个特征,p(aj|cm)表示类别为cm的样本包含特征aj的概率,m表示类别个数。
步骤2中采用最大权重计算公式取得数据块dk中每条数据的权重,因为权重的目的在于提高最近到达的数据块中的实例的重要程度,因此对于来自当前流块dk的所有实例,为其分配最大权值1,最终得到加权后的实例集,最大权重计算公式为
步骤2中使用权重衰减的遗忘加权公式校正数据集dk中每条数据的权重;权重衰减的遗忘加权公式如下:
其中,k表示第k个数据块,
本发明的有益效果是,一种基于贝叶斯网络的动态数据流分类方法,在依据重要性加权后的实例集上构建用于流数据分类的朴素贝叶斯分类器。通过结合处理来自新输入实例和旧实例的方法,得到了一个自适应分类器,可以在存在概念漂移的情况下进行学习。由于对最新实例赋予了最大权重并且逐渐忘记了过时的实例,所以可以自动地适应变化,不需要任何明确的漂移检测器,这是此模型的一个显著优点,避免了选择适当的漂移探测器的问题。
附图说明
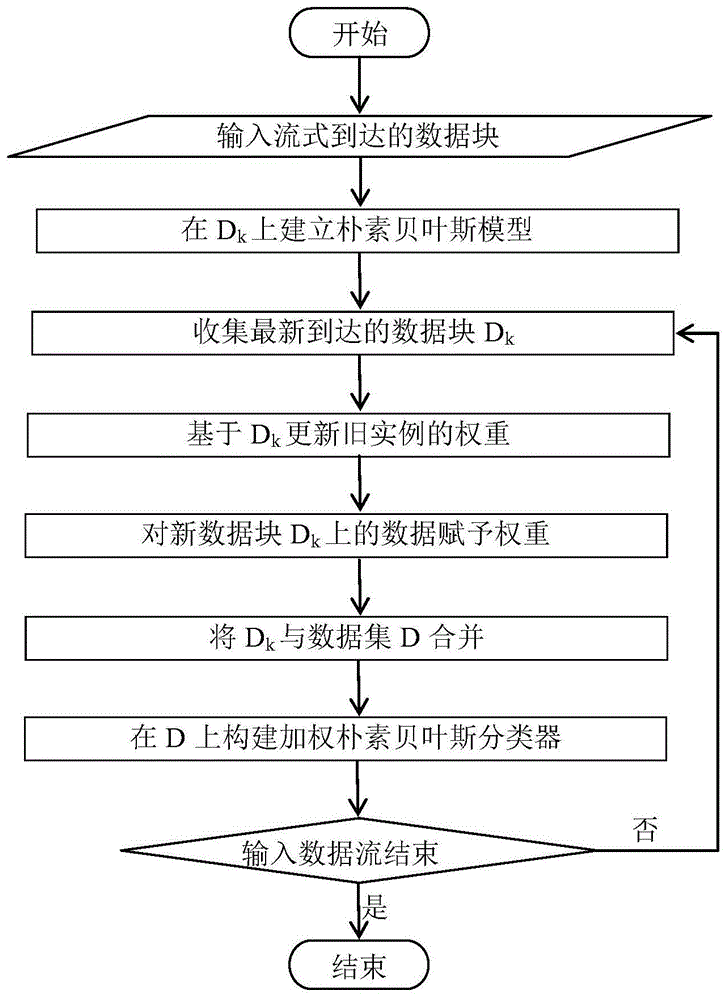
图1是本发明一种基于贝叶斯网络的动态数据流分类方法的流程图。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
本发明基于贝叶斯网络的动态数据流分类方法,流程图如图1所示,具体按照以下步骤实施:
步骤1、从互联网应用中采集关于用户点击新闻的批量数据,将所有数据分为若干数据块,每个数据块包含10000条数据,其中每个数据块表示互联网应用中某一时间段采集到的数据,所有数据块d1,d2,...di...,dn以流的形式呈现并留待之后处理,n表示数据块的个数,先在第一个数据块d1上使用朴素贝叶斯算法建立朴素贝叶斯模型,将数据块d1放入数据集d中;
步骤2:针对第i个数据块di,使用步骤1中建立的朴素贝叶斯模型对di进行分类,得到数据块di的10000条数据的类别,采用最大权重计算公式取得数据块di中每条数据的权重,并使用权重衰减的遗忘加权公式校正di中每条数据的权重,其中,当处理到第k个数据块dk时,使用步骤1中建立的朴素贝叶斯模型对数据块dk进行分类,得到数据块dk的10000条数据的类别,朴素贝叶斯分类模型如下:
其中,cm表示第m个类别,p(cm|a1,a2,...,af)表示在特征为a1,a2,...,af时类别为cm的概率,p(cm)表示所有样本中类别为cm的概率,f为给定特征个数,aj表示第j个特征,p(aj|cm)表示类别为cm的样本包含特征aj的概率,m表示类别个数。
步骤2中采用最大权重计算公式取得数据块dk中每条数据的权重,因为权重的目的在于提高最近到达的数据块中的实例的重要程度,因此对于来自当前流块dk的所有实例,为其分配最大权值1,最终得到加权后的实例集,最大权重计算公式为
步骤2中使用权重衰减的遗忘加权公式校正数据集dk中每条数据的权重;权重衰减的遗忘加权公式如下:
其中,k表示第k个数据块,
步骤3:将数据块di合并入数据集d,剔除d中权重小于0.1的所有数据,随后在数据集d上基于更新后的权值采用朴素贝叶斯算法建立朴素贝叶斯模型;
步骤4:重复步骤2和步骤3,直到处理完数据流上的最后一个数据块dn,数据流的分类过程完成。
在本发明基于贝叶斯网络的动态数据流分类方法中:步骤2的作用是为数据集上的所有实例分别实现加权。采用最大权重计算公式取得最新数据块中各实例的权重,其原理是:通过权重来体现各实例的重要程度,为了提高最近到达的数据块中的实例的重要程度,对于来自当前流块dn的所有对象,为其分配最大权值1。
但是,如果仅为新实例应用此加权方案,就将获得标准的朴素贝叶斯方法,因为所有对象都将具有相同的权重。另外,由于要存储从数据流中提取的所有实例,将会加大对内存的需求,并会导致分类器的泛化能力较差。针对这些问题,可以删除不再代表所分析数据流当前状态的不必要和过时的实例。随着时间的推移,实例的重要程度会逐渐减少,特别是在非静止的环境下,实例的当前特征可能与先前迭代的特征明显不同。基于此,可为加权朴素贝叶斯分类器增加一个遗忘原则。
最简单的方法是从之前或最旧的迭代中删除实例。然而,这样就会丢弃它们所携带的所有信息,即便它们仍然可能对分类有一定的贡献,例如在数据分布变化不快即出现逐渐概念漂移的情况下。因此,可以采用权重衰减的遗忘加权公式校正之前到达的旧数据上所有实例的权重,其优点在于:可以平滑地忘记先前的数据,并且变化的快慢程度可以由用户来控制,漂移速度越快,模型的适应性就会越弱。在每次迭代中,根据遗忘函数减少其权重来惩罚来自先前块的实例,就会逐渐减少旧实例在计算类后验概率时带来的影响。
附图1所示的为基于贝叶斯网络的动态数据流分类方法的流程图,对于各个流式到达的数据块,首先在数据块d1上建立一个朴素贝叶斯模型,并保存于系统中。当dn到达后,基于最新数据块dn对旧实例的权重进行更新,并根据最大权重计算公式对新数据赋予权重。然后将dn与数据集d合并,检查d中所有实例的权重,将低于预先设定阈值的实例丢弃。最后在d上构建加权朴素贝叶斯分类器。将这个过程一直迭代下去,直到输入数据流结束。
实施例
electricity数据集采集自澳洲威尔士电力市场,数据集包含了自1996年5月7日至1997年8月23日的21364条数据,每条数据由8个特征组成。以1000条数据为单位,将所有数据分为20块。
covertype数据描述了森林区域观测情况,包括51个数据特征以及6种森林覆盖类型。数据集包含581000条数据,以1000条数据为单位,将所有数据分为581块。
click-throughrateprediction数据采集自真实的互联网应用,描述了用户点击新闻的具体情况。该数据集采集自15个自然日。经数据预处理后,每天包含20,000条数据,共计300,000条数据,以及100个数据特征。以10000条数据为单位,将所有数据分为30块,其中每个数据块表示互联网应用中某一时间段采集到的数据,所有数据块d1,d2,...di...,d30以流的形式呈现出来并留待之后处理,先在第一个数据块d1上使用朴素贝叶斯算法建立朴素贝叶斯模型,将数据块d1放入数据集d;
针对第i个数据块di,使用步骤1中建立的朴素贝叶斯模型对di进行分类,得到数据块di的10000条数据的类别,采用最大权重计算公式取得数据块di中每条数据的权重,并使用权重衰减的遗忘加权公式校正di中每条数据的权重;
将数据块di合并入数据集d,剔除d中权重小于0.1的所有数据,随后在数据集d上基于更新后的权值采用朴素贝叶斯算法建立朴素贝叶斯模型;
重复前面步骤,直到处理完数据流上的最后一个数据块d30,得到所处理数据流的分类模型。
本发明的方法通过为朴素贝叶斯算法加入基于遗忘机制的加权方案成功地解决了数据流中的概念漂移问题。在依据重要性加权后的实例集上构建用于流数据分类的朴素贝叶斯分类器。通过结合处理来自新输入实例和旧实例的方法,得到了一个自适应分类器,可以在存在概念漂移的情况下进行学习。由于对最新实例赋予了最大权重并且逐渐忘记了过时的实例,所以可以自动地适应变化,不需要任何明确的漂移检测器,这是此模型的一个显著优点,避免了选择适当的漂移探测器的问题。
- 还没有人留言评论。精彩留言会获得点赞!