一种基于深度神经网络和跳跃连接的无干净标签图像去噪方法与流程
本发明涉及一种基于深度神经网络和跳跃连接的无干净标签图像去噪方法,属于图像处理和计算机视觉技术领域。
背景技术:
由于深度学习,特别是卷积神经网络在图像识别等领域的迅速发展,基于深度学习的图像去噪方法也得到了很好的应用,并且得到了与传统方法相近或更好的效果,这也使得许多科研学者进行了研究。2017年,zhang等提出用较深层的cnn网络实现图像去噪,称为dncnn网络。为了解决网络层数加深导致的梯度弥散效应,dncnn并不对图像进行学习,而是以输出与噪声的l2范数作为损失函数来训练网络。dncnn网络可以看成一个残差学习的过程,这样可以较好的训练网络模型。在该网络中利用了batchnormalization层,实验表明bn层与残差学习共同使用可以提高模型的性能。dncnn在不同噪声水平上训练,得到的结果也优于比较经典的算法的去噪效果,如bm3d等。2018年,zhang等又提出ffdnet,该网络可以看成是dncnn的后续作品,原理是将噪声水平reshape成图片大小并和噪声图像同时送入网络进行训练,改变下采样方式,提升通道数,这样不仅提升了训练速度,还使得网络更加灵活。
然而利用深度学习方法进行图像去噪的时候,通常需要大量的训练图像的样本对,即带噪声的图片和去噪后的清晰图片,然而去噪后的清晰图片往往很难获得。面对这样的问题,提出是否存在一种基于深度学习但不需要清晰图像做标签的去噪方法的疑问,即输入输出都是带有噪声的图像对网络进行训练。
技术实现要素:
针对现有的基于深度学习的降噪方法存在着网络层数深,参数量大,时间性能低,训练时占用大量计算资源的不足,本发明提供了一种基于深度神经网络和跳跃连接的无干净标签图像去噪方法,能显著改善以上问题,并取得不错的降噪效果,对比传统方法降噪效果有显著提升。
本发明的技术方案是:一种基于深度神经网络和跳跃连接的无干净标签图像去噪方法,所述基于深度神经网络和跳跃连接的无干净标签图像去噪方法的具体步骤如下:
step1、选择公用的数据集;
step2、对选择的数据集进行添加噪声处理;
step3、结合图像中的噪声类型,建立u-net++深度卷积神经网络;
step4、将有噪声的图像送入所述的u-net++深度卷积神经网络,得到图像去噪网络模型;
step5、通过求解最小化损失函数的值,学习到网络模型的最优参数,利用训练好的网络模型来对噪声图像进行复原。
进一步地,所述步骤step2的具体步骤如下:
步骤step2.1、对数据集中的每一张图像进行选取和裁剪,使计算设备处于可承担的运算环境;
步骤step2.2、创建不同的噪声模型,根据需求对数据集添加不同的噪声。
进一步地,所述步骤step2.2的具体步骤如下:
step2.2.1、设计四种噪声模型,分别为加性高斯噪声、泊松噪声、乘性伯努利噪声、文本噪声;加性高斯噪声,其中模型参数噪声标准偏差σ∈[0,50];泊松噪声,其中模型参数噪声幅度λ∈[0,50];乘性伯努利噪声,其中用p表示像素损坏概率则设定p∈[0,0.95];文本噪声,其中p∈[0,0.5];
step2.2.2、将从数据集中选取的一张图像送入噪声模型即添加噪声分布,次数为两次,分别得到两张不同的噪声图像,其中一张用作网络模型输入的噪声图像,另一张用作标签图像;
step2.2.3、迭代步骤step2.2.2得到一组经过加噪的训练集。
进一步地,step3具体包括以下步骤:
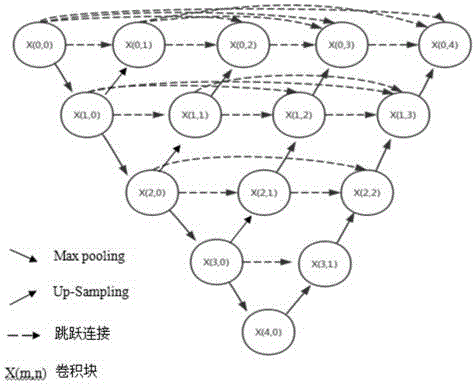
step3.1、使用u-net网络结构改进的u-net++结构;其中从纵向来看继承了u-net的编码器-解码器结构;编码器结构通过堆叠组合卷积层和池化层来产生不同尺度的卷积特征,在卷积特征x(m,n)和卷积特征x(m+1,n)之间采用步长为2的池化层使特征图减小为原来的二分之一,其中,m为网络深度,n为水平宽度;解码器结构通过邻近插值法和一个2*2的卷积层代替反卷积,好处是不会像反卷积丢失过多的细节信息,能达到良好去噪效果的同时较好地保留图像内容;
step3.2、在水平方向采用深层特征和浅层特征结合的方法;x(m,n)卷积特征的信息来自于x(m,1)...x(m,n-1)和x(m+1,n-1),其中在解码阶段,卷积特征不仅用到了深层特征,还用到了同深度的所有的卷积特征,大大丰富了特征信息,而同深度的各个特征结合使用的是跳跃连接,这样不仅利于梯度回传加快训练过程,还能使参数更新分布的更加均匀。
进一步地,步骤step3.1包括:
step3.1.1、网络结构使用的基本单元是一个拥有两层卷积层和一层防止过拟合的dropout层的卷积块,其中卷积层使用3*3的卷积核,激活函数使用relu激活函数;
step3.1.2、网络中的每个节点由卷积块构成,深层卷积块的输入由上一层的卷积块得到的特征图经过maxpooling操作得到。
进一步地,步骤step3.2包括:
step3.2.1、特征块x(m,n)的计算公式:
用h(·)表示一个卷积和激活函数,u(·)表示上采样,[·]表示concatenate操作,m表示网络深度,n表示水平宽度,k表示上一层网络宽度,初始值是0,以x(1,2)为例,它是由x(1,0),x(1,1)和上采样后的x(2,1)拼接之后,再经过一次卷积和relu激活函数得到;
step3.2.2、经过step3.2.1的不断迭代,得到最后一个卷积块的输出,将该输出再做一次卷积,其中卷积核大小和个数分别为1*1和3,最终得到复原后的3通道图像。
进一步地,步骤step5具体包括以下步骤:
step5.1、不同的图像噪声采用不同的loss函数,加性高斯噪声、泊松噪声采用l2损失:
文本噪声采用l1损失:
乘性伯努利噪声采用的loss为:
其中,yi表示实际值,
step5.2、计算输出层的实际值和噪声标签图像之间的偏差,根据反向传播过程,得到每层的误差,根据这些误差调整各层权重参数,完成网络模型的优化;
step5.3、不断迭代步骤step5.2,直至网络收敛。
本发明的有益效果是:
本发明是一种不需要清晰标签图像参与网络模型训练的图像去噪方法,降低了结合深度学习进行图像去噪的数据集获取难度,网络设计中将用于图像分割的u-net++网络进行改进,使其很好的应用于图像去噪领域,并取得显著的效果。同时,采用跳跃连接的u-net++相对于传统的深度卷积网络,时间性能远远领先,减少了大量的模型参数,节约计算资源,降低了训练难度。本发明不需要输入噪声图像对应的清晰图像标签,但是可以达到与输入清晰图像标签训练时相当的效果水平,且显著提高了噪声图像的清晰程度。
附图说明
图1为本发明的方法流程示意图;
图2为本发明的卷积块结构示意图;
图3为本发明的图像降噪的网络结构图。
具体实施方式
实施例1:如图1-3所示,一种基于深度神经网络和跳跃连接的无干净标签图像去噪方法,所述基于深度神经网络和跳跃连接的无干净标签图像去噪方法的具体步骤如下:
step1、选择公用的数据集;本实施例使用了imagenet中的291幅图像最为训练集,使用set14作为测试集;
step2、对选择的数据集进行添加噪声处理;
step3、结合图像中的噪声类型,建立u-net++深度卷积神经网络;
step4、将有噪声的图像送入所述的u-net++深度卷积神经网络,得到图像去噪网络模型;
step5、通过求解最小化损失函数的值,学习到网络模型的最优参数,利用训练好的网络模型来对噪声图像进行复原。
进一步地,所述步骤step2的具体步骤如下:
步骤step2.1、对数据集中的每一张图像进行选取和裁剪,使计算设备处于可承担的运算环境;
步骤step2.2、创建不同的噪声模型,根据需求对数据集添加不同的噪声。
进一步地,所述步骤step2.2的具体步骤如下:
step2.2.1、设计四种噪声模型,分别为加性高斯噪声、泊松噪声、乘性伯努利噪声、文本噪声;加性高斯噪声,其中模型参数噪声标准偏差σ∈[0,50];泊松噪声,其中模型参数噪声幅度λ∈[0,50];乘性伯努利噪声,其中用p表示像素损坏概率则设定p∈[0,0.95];文本噪声,其中p∈[0,0.5];
step2.2.2、将从数据集中选取的一张图像送入噪声模型即添加噪声分布,次数为两次,分别得到两张不同的噪声图像,其中一张用作网络模型输入的噪声图像,另一张用作标签图像;
step2.2.3、迭代步骤step2.2.2得到一组经过加噪的训练集。
进一步地,step3具体包括以下步骤:
step3.1、使用u-net网络结构改进的u-net++结构;其中从纵向来看继承了u-net的编码器-解码器结构;编码器结构通过堆叠组合卷积层和池化层来产生不同尺度的卷积特征,在卷积特征x(m,n)和卷积特征x(m+1,n)之间采用步长为2的池化层使特征图减小为原来的二分之一,其中,m为网络深度,n为水平宽度;解码器结构通过邻近插值法和一个2*2的卷积层代替反卷积,好处是不会像反卷积丢失过多的细节信息,能达到良好去噪效果的同时较好地保留图像内容;
step3.2、在水平方向采用深层特征和浅层特征结合的方法;x(m,n)卷积特征的信息来自于x(m,1)...x(m,n-1)和x(m+1,n-1),其中在解码阶段,卷积特征不仅用到了深层特征,还用到了同深度的所有的卷积特征,大大丰富了特征信息,而同深度的各个特征结合使用的是跳跃连接,这样不仅利于梯度回传加快训练过程,还能使参数更新分布的更加均匀。
进一步地,步骤step3.1包括:
step3.1.1、网络结构使用的基本单元是一个拥有两层卷积层和一层防止过拟合的dropout层的卷积块,其中卷积层使用3*3的卷积核,激活函数使用relu激活函数;
step3.1.2、网络中的每个节点由卷积块构成,深层卷积块的输入由上一层的卷积块得到的特征图经过maxpooling操作得到。
进一步地,步骤step3.2包括:
step3.2.1、特征块x(m,n)的计算公式:
用h(·)表示一个卷积和激活函数,u(·)表示上采样,[·]表示concatenate操作,m表示网络深度,n表示水平宽度,k表示上一层网络宽度,初始值是0,以x(1,2)为例,它是由x(1,0),x(1,1)和上采样后的x(2,1)拼接之后,再经过一次卷积和relu激活函数得到;
step3.2.2、经过step3.2.1的不断迭代,得到最后一个卷积块的输出,将该输出再做一次卷积,其中卷积核大小和个数分别为1*1和3,最终得到复原后的3通道图像。
步骤step3、step4中,使用的深度神经网络结构如图3所示,其中;
x(m,n)代表卷积块。从纵向来看,图像由x(0,0)输入网络,经过卷积块处理后再经一层步长为2的maxpooling池化层,特征图变为原来的一半,接着进入下一层卷积块此时通道数翻倍,如此迭代得到深层的更具抽象的特征图;横向来看,深层次的卷积块通过上采样(邻近差值法+卷积)得到的特征图与上一层的所有卷积块输出进行concatenate操作,深层特征和浅层特征结合大大丰富了特征信息,而同深度的各个特征结合使用的是跳跃连接,这样不仅利于梯度回传加快训练过程,还能使参数更新分布的更加均匀。
进一步地,步骤step5具体包括以下步骤:
step5.1、不同的图像噪声采用不同的loss函数,加性高斯噪声、泊松噪声采用l2损失:
文本噪声采用l1损失:
乘性伯努利噪声采用的loss为:
其中,yi表示实际值,
step5.2、计算输出层的实际值和噪声标签图像之间的偏差,根据反向传播过程,得到每层的误差,根据这些误差调整各层权重参数,完成网络模型的优化;
step5.3、不断迭代步骤step5.2,直至网络收敛。
进一步地,在步骤step5中,使用adam算法(adaptivemomentestimation)即自适应时刻估计方法在训练阶段优化损失函数,通过该算法优化得到的网络最优参数,最后利用网络模型来对输入的噪声图像进行去噪。
本发明通过对当前结合深度学习进行图像去噪方法不足的思考,即考虑不使用清晰的标签图像对噪声图像进行去噪,使用对应用于图像分割的u-net+++改进的网络模型,并结合一种思想:当训练样本足够多时,由于噪声是随机的,u-net++无法学习到输入和输出噪声图像的映射关系,从最小化损失的角度看,网络只能学习到清晰的图像本身即降噪后的图像,原因在于噪声是随机的,网络无法学习到某总噪声的转换规律而使得损失最小化。从而提出了一个性能较好的基于深度神经网络和跳跃连接的无干净标签图像去噪方法。
上面结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!