基于共享表示的多任务语言分析系统及方法与流程
本发明属于语言分析技术领域,具体涉及一种语言分析系统及方法。
背景技术:
但是,目前语言分析技术(如分词、词性标注、实体识别、句法分析、语义分析等)中,每一个任务都是使用不同的方法独立实现的,通过分析结果的传递实现耦合,其间没有进行任何的融合,标注语料知识上得不到共享,分析准确率低。而且每个任务模块都是独立运算的,分析速度慢。
技术实现要素:
本发明是为了解决目前的语言分析方法存在分析速度慢以及分析准确率低的问题。
基于共享表示的多任务语言分析系统,包括:
表示层模型:表示层模型使用的是bert编码器结构的隐层输出,该模型输入中文字序列,输出与字序列等长的向量序列,每个向量对应着相应位置的字的分布式语义表示,将表示层输出统一表示为矩阵r1;
分词模块:针对r1中每个字隐层表示的向量通过一个线性层运算,映射到一个4维的bmes标签空间,使用softmax函数转化为标签概率分布,求出概率最高的标签,并通过标签含义,解码出词序列输出;
以词序列和r1作为输出,将r1中每个词首字位置的隐层表示输出作为该词的分布式表示,统一表示为r2;
分析模块,包括词性标注子模块;每个子模块的输入均为分词模块的输出结果r2;
词性标注子模块:针对r2中每个词隐层表示向量通过一个线性层运算,映射到词性标签空间,使用softmax函数转化为词性概率分布,求出概率最高的词性;
进一步地,所述的分析模块还包括实体识别子模块;
实体识别子模块:针对r2中每个词隐层表示向量通过双向长短时记忆网络进行编码,并通过条件随机场模型在bmeso实体标签空间上进行解码,求出最可能的实体标签序列,并通过标签含义解码出实体片段。
进一步地,所述的分析模块还包括依存句法分析子模块;
句法分析子模块:针对r2中每个词隐层表示向量,通过两个多层感知机将表示映射到作为句法父节点和子节点的不同表示,并将这两种表示通过双线性计算得到相应的句法弧转移矩阵,同样使用双线性方法得到对应句法弧的句法标签;由此即可求出每个词的父节点和标签并输出句法树。
进一步地,所述的分析模块还包括语义角色标注子模块;
语义角色标注子模块:针对r2中每个词隐层表示向量,将对应谓词的隐层表示与所有词表示进行拼接,通过多层双向lstm对其进行编码得到新的表示r3,对r3再次对应谓词的隐层表示与所有词表示进行拼接;并通过一个线性层映射到bio论元空间,使用softmax函数转化为论元标签概率分布,并通过标签含义解码出相应谓词的论元片段。
基于共享表示的多任务语言分析方法,包括以下步骤:
步骤1、表示层模型使用的是bert编码器结构的隐层输出,该模型输入中文字序列,输出与字序列等长的向量序列,每个向量对应着相应位置的字的分布式语义表示,将表示层输出统一表示为矩阵r1;
步骤2、针对r1中每个字隐层表示向量通过一个线性层运算,映射到一个4维的bmes标签空间,使用softmax函数转化为标签概率分布,求出概率最高的标签,并通过标签含义,解码出词序列输出;
步骤3、以词序列和r1作为输出,将r1中每个词首字位置的隐层表示输出作为该词的分布式表示,统一表示为r2;
步骤4、以步骤3的输出结果r2为输入进行分析,包括以下步骤:
针对r2中每个词隐层表示向量通过一个线性层运算,映射到词性标签空间,使用softmax函数转化为词性概率分布,求出概率最高的词性。
进一步地,步骤4所述以步骤3的输出结果r2为输入进行分析的过程还包括以下步骤:
针对r2中每个词隐层表示向量通过双向长短时记忆网络进行编码,并通过条件随机场模型在bmeso实体标签空间上进行解码,求出最可能的实体标签序列,并通过标签含义解码出实体片段。
进一步地,步骤4所述以步骤3的输出结果r2为输入进行分析的过程还包括以下步骤:
针对r2中每个词隐层表示向量,通过两个多层感知机将表示映射到作为句法父节点和子节点的不同表示,并将这两种表示通过双线性计算得到相应的句法弧转移矩阵,同样使用双线性方法得到对应句法弧的句法标签;由此即可求出每个词的父节点和标签并输出句法树。
进一步地,步骤4所述以步骤3的输出结果r2为输入进行分析的过程还包括以下步骤:
针对r2中每个词隐层表示向量,将对应谓词的隐层表示与所有词表示进行拼接,通过多层双向lstm对其进行编码得到新的表示r3,对r3再次对应谓词的隐层表示与所有词表示进行拼接;并通过一个线性层映射到bio论元空间,使用softmax函数转化为论元标签概率分布,并通过标签含义解码出相应谓词的论元片段。
有益效果:
本发明通过共享表示层的方法,使得不同任务模块的大部分模型参数和运算可以共享,这就极大减少了系统资源占用,提高了分析速度。同时共享的表示层能够使得不同任务标注语料知识可以充分的进行融合,相比现有技术在各个任务上分析的准确率更高。
附图说明
图1为基于共享表示的多任务语言分析的流程图;
图2为本发明分词级别表示筛选示意图;
图3为词性标注示意图;
图4为实体识别示意图;
图5为本发明使用流程示意图。
具体实施方式
具体实施方式一:
本实施方式为基于共享表示的多任务语言分析系统,包括:
表示层模型:表示层模型使用的是bert编码器结构(一种基于注意力的层叠结构模型)的隐层输出,该模型输入中文字序列,输出与字序列等长的向量序列,每个向量对应着相应位置的字的分布式语义表示,将表示层输出统一表示为矩阵r1,维度为c*d,c表示句中字的数量,d表示隐层维度;
分词模块:针对r1中每个字隐层表示的向量通过一个线性层运算,映射到一个4维的bmes标签空间(分别代表词开始、词中间、词结尾、单字成词),使用softmax函数转化为标签概率分布,求出概率最高的标签,并通过标签含义,解码出词序列输出;
以词序列和r1作为输出,将r1中每个词首字位置的隐层表示输出作为该词的分布式表示,统一表示为r2,维度为w*d,w表示句中词的数量,d表示隐层维度;
结合图2进行说明,将“我爱中国”(字序列)输入表示层,每个字表达的向量通过一个线性层(linear)和softmax函数,词序列为“我”、“爱”、“中国”,还有一个标点符号“。”,然后以每个词的首字位置的隐层表示作为该词的分布式表示,也就是说“我”、“爱”、“中”的向量表示就是“我”、“爱”、“中国”的表示,对应矩阵的表示为r2;
分析模块,包括词性标注子模块;每个子模块的输入均为分词模块的输出结果r2;
词性标注子模块:针对r2中每个词隐层表示向量通过一个线性层运算,映射到词性标签空间,使用softmax函数转化为词性概率分布,求出概率最高的词性;结合图3进行说明,“我”、“爱”、“中国”对应的向量,通过一个线性层(linear)和softmax函数,词性分为对应为“r(代词)”、“v(动词)”、“ns(地名)”,以及一个“wp(标点符号)”。
具体实施方式二:
本实施方式为基于共享表示的多任务语言分析系统,其中所述的分析模块还包括实体识别子模块;
实体识别子模块:针对r2中每个词隐层表示向量通过双向长短时记忆网络进行编码,并通过条件随机场模型在bmeso实体标签(每个命名实体x对应b-x,m-x,e-x,s-x四种标签,分别表示实体开始,实体中间,实体结尾和单词实体,使用o标签表示该标注词不在任何一个实体中)空间上进行解码,求出最可能的实体标签序列,并通过标签含义解码出实体片段。结合图4进行说明,“张三”、“是”、“全国”、“律协”、“会员”、“。”对应的向量,通过双向长短时记忆网络(bi-lstmlayer)和条件随机场模型(crflayer),在bmeso实体标签空间解码为“s-nh”、“o”、“b-ni”、“e-ni”、“o”、“o”,“s-nh”、“b-ni”、“e-ni”中“-”后面的“nh”为人名,“ni”为机构名。
其他结构与具体实施方式一相同。
具体实施方式三:
本实施方式为基于共享表示的多任务语言分析系统,其中所述的分析模块还包括依存句法分析子模块;
句法分析子模块:针对r2中每个词隐层表示向量,通过两个多层感知机将表示映射到作为句法父节点和子节点的不同表示,并将这两种表示通过双线性计算得到相应的句法弧转移矩阵,同样使用双线性方法得到对应句法弧的句法标签;由此即可求出每个词的父节点和标签并输出句法树。
其他结构与具体实施方式一或二相同。
具体实施方式四:
本实施方式为基于共享表示的多任务语言分析系统,其中所述的分析模块还包括语义角色标注子模块;
语义角色标注子模块:针对r2中每个词隐层表示向量,将对应谓词的隐层表示与所有词表示进行拼接,通过多层双向lstm对其进行编码得到新的表示r3,对r3再次对应谓词的隐层表示与所有词表示进行拼接;并通过一个线性层映射到bio论元空间(每个论元x对应b-x,i-x两种标签,分别表示论元开始,论元继续,使用o标签表示该标注词不在任何一个论元中),使用softmax函数转化为论元标签概率分布,并通过标签含义解码出相应谓词的论元片段。
其他结构与具体实施方式一至三之一相同。
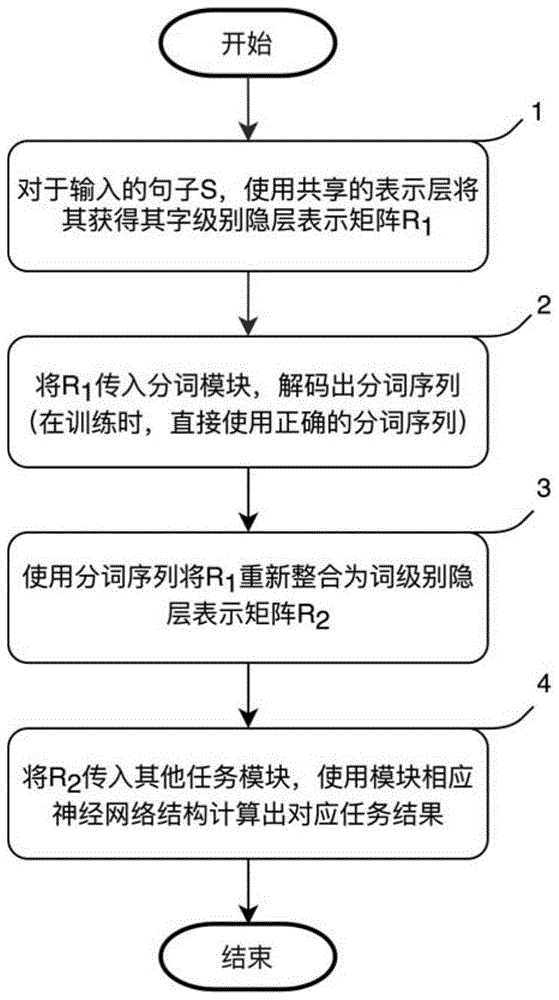
具体实施方式五:结合图1说明本实施方式,
本实施方式为基于共享表示的多任务语言分析方法,包括以下步骤:
步骤1、表示层模型使用的是bert编码器结构(一种基于注意力的层叠结构模型)的隐层输出,该模型输入中文字序列,输出与字序列等长的向量序列,每个向量对应着相应位置的字的分布式语义表示,将表示层输出统一表示为矩阵r1,维度为c*d,c表示句中字的数量,d表示隐层维度;
步骤2、针对r1中每个字隐层表示向量通过一个线性层运算,映射到一个4维的bmes标签空间(分别代表词开始、词中间、词结尾、单字成词),使用softmax函数转化为标签概率分布,求出概率最高的标签,并通过标签含义,解码出词序列输出;
步骤3、以词序列和r1作为输出,将r1中每个词首字位置的隐层表示输出作为该词的分布式表示,统一表示为r2,维度为w*d,w表示句中词的数量,d表示隐层维度;
步骤4、以步骤3的输出结果r2为输入进行分析,包括以下步骤:
针对r2中每个词隐层表示向量通过一个线性层运算,映射到词性标签空间,使用softmax函数转化为词性概率分布,求出概率最高的词性。
具体实施方式六:
本实施方式为基于共享表示的多任务语言分析方法,以步骤3的输出结果r2为输入进行分析的过程还包括以下步骤:
针对r2中每个词隐层表示向量通过双向长短时记忆网络进行编码,并通过条件随机场模型在bmeso实体标签(每个命名实体x对应b-x,m-x,e-x,s-x四种标签,分别表示实体开始,实体中间,实体结尾和单词实体,使用o标签表示该标注词不在任何一个实体中)空间上进行解码,求出最可能的实体标签序列,并通过标签含义解码出实体片段。
其他步骤与具体实施方式五相同。
具体实施方式七:
本实施方式为基于共享表示的多任务语言分析方法,以步骤3的输出结果r2为输入进行分析的过程还包括以下步骤:
针对r2中每个词隐层表示向量,通过两个多层感知机将表示映射到作为句法父节点和子节点的不同表示,并将这两种表示通过双线性计算得到相应的句法弧转移矩阵,同样使用双线性方法得到对应句法弧的句法标签;由此即可求出每个词的父节点和标签并输出句法树。
其他步骤与具体实施方式五或六相同。
具体实施方式八:
本实施方式为基于共享表示的多任务语言分析方法,以步骤3的输出结果r2为输入进行分析的过程还包括以下步骤:
针对r2中每个词隐层表示向量,将对应谓词的隐层表示与所有词表示进行拼接,通过多层双向lstm对其进行编码得到新的表示r3,对r3再次对应谓词的隐层表示与所有词表示进行拼接;并通过一个线性层映射到bio论元空间(每个论元x对应b-x,i-x两种标签,分别表示论元开始,论元继续,使用o标签表示该标注词不在任何一个论元中),使用softmax函数转化为论元标签概率分布,并通过标签含义解码出相应谓词的论元片段。
其他步骤与具体实施方式五至七之一相同。
具体实施方式五、六、七或八对应的模型需要经过如图5所示的流程进行训练和使用,具体包括以下步骤:
a、针对需要训练的任务收集相应的语料,并进行标注。
b、训练神经网络前由预训练好的bert模型隐层初始化共享的隐层表示,预训练使用带遮罩的语言模型和连续句子预测任务在大规模中文文本上进行。对于分词任务语料则将字级别隐层表示矩阵r1传入分词模型执行至步骤2,优化bmes标签序列损失即可停止流程。对于其他任务语料的训练,则根据标注的数据对应的正确分词结果直接执行步骤3、步骤4,优化进行对应任务损失即可。
c、参考流程进行分析预测,收集步骤2中的分词序列结果和步骤4中的全部其他分析结果输出即可。
在多任务训练的过程中,由于不同任务的数据集规模相差较大,这使得小数据量任务往往不能得到有效的训练。在我们训练时,采用了一种下降指数概率采样方法(annealedsampling)在不同任务不同规模的数据集上选择训练样本。该方法在训练前会先对所有数据集数据量进行统计,在训练中,安装概率随机选择一个任务的一批数据样本进行训练,概率的计算公式如下:
其中,pi表示每个训练批次随机选择第i个数据集中的训练数据的概率,ni为第i个数据集规模,e为当前训练轮数,e为训练总轮数。该公式保证了在训练开始时,首先按照正常的数据集比例对模型参数调优,随着训练轮次增加,大数据集任务收敛较为充分时,即可不断地增加小数据集任务样本的学习,从而在不丢失大数据集任务性能的同时,使小数据集任务得到充分的学习,从而更好地提高这些任务的性能。
实施例
本实施例以具体实施方式二的方式进行说明,即分析模块包括词性标注子模块和实体识别子模块;本实施例中采用人民日报数据集作为分词、词性、实体识别标注语料。由于语料原始划分中存在不同任务上训练集与测试集有相同句子的情況,我们对语料进行了重新的划分和筛选,分词词性使用相同划分并将所有测试集中出现的句在训练、开发集中删除。整理后的训练语料如表1所示。
表1多任务实验数据集
本实施例中,将实验分为两个部分进行。第一部分是系统性能试验。我们希望验证多任务学习带来的知识迁移,对各个任务性能,特别是端到端系统的提升;同时,我们希望探究在同样引入额外知识的设置下,比较使用任务级联方式显式増加特征与利用多任务方式使特征在表示层中深度融合两种方法的差异。第二部分是系统效率试验。通过实验实际测试多任务系统通过共享隐层表示计算,带来的分析速度提升和资源占用下降。
使用三种模型设置来进行以上实验。
设置一、独立模型。在此设置下我们独立地对分词,词性和实体识别模型进行模型训练,作为我们对比的基准。独立训练的模型与上文介绍的多任务模型相同,不同的是,任务将独占全部的bert隐层用于优化自身任务指标。
设置二、级联实体识别模型。由于词性标签特征可以有效地提升实体识别任务性能,为了与多任务学习这种通过共享参数的形式隐式融合不同任务特征的方法。我们在这里增加了,使用词性标注模型显式地给实体识别任务模型提供自动词性信息的对比基线设置。在这种设置下,我们使用设置一中训练的词性标注模型,为实体识别数据集进行了词性标注。并使用该自动词性数据集对3.4.3中介绍的词性特征拼接实体识别基线模型进行训练。
设置三、多任务模型。使用以上三个数据集数据对我们的分词、词性标注、实体识别联合模型进行了训练。该设置下也仅对应一个模型,但此模型有三个头部,可以进行分词、词性标注和实体识别的多重任务。
与前面相似,在模型训练时,使用bert-base-chinese预训练参数对隐层表示模型进行了初始化,采用学习率初始化为5e-5的预热adam优化器更新模型参数。由于分词词性训练集与实体识别训练集规模相差过大,这可能导致小数据集难以收敛,我们采用了前文提到的下降指数概率采样方式在不同任务数据集中采样训练数据。
系统性能实验
首先在每个任务各自的测试集上以上三个设置的5个模型进行了独立的测试,这里的词性和实体识别是建立在黄金分词之上的。另外,我们也在实体识别测试集上抽取了未标注的文本,对每个设置下的系统进行了分词、词性实体识别整体流程的端到端测试,来综合评估系统性能。分词任务没有前置任务,端到端性能与直接测试等价;拼接特征模型设置下,系统分词、词性都与独立模型设置等价。以上内容没有进行测试。
系统效率实验
为了验证多任务模型在时间和系统资源占用上的优势。我们模拟多任务语言分析系统生产环境下部署运行的场景,在人民日报实体识别数据集测试集的1000句语料的生文本上,对多任务模型和级联的独立模型进行了运行时间的测试。本系统采用python3语言的pytorch机器学习框架开发。本实验中,我们使用的机器cpu型号为mtel(r)xeon(r)gold5118cpu2.30ghz,装载centos7操作系统,模型在图像卡(gpu)中进行运算,使用的gpu型号为nvidiageforcegm1080ti。
系统性能实验结果与分析
使用前文介绍的三种模型设置分别进行了相关任务测试集测试与实体识别端到端测试。模型性能如表2所示。其中词性使用精确评价,实体识别使用f值进行评价。
表2多任务实验系统性能结果
从实验结果中我们发现,多任务模型相比独立训练的模型在各个任务上以及端到端的测试中均有所提升,在实体识别任务中提升非常明显(+1.42%)。实验结果表明,我们的多任务模型在多任务联合学习的过程中,深度融合了各个任务的标注知识,通过共享参数的形式对其进行了跨任务的迁移,从而使得任务性能得到了有效提升。
拼接词性特征的模型显式的利用了自动的词性信息,相较独立序列的实体识别模型提升了0.37%,这种拼接仅仅是对两种表示进行了简单连接,而多任务学习模型将词性任务特征提供的知识隐式与文本特征表示深度融合,又将性能提升1.05%。可以说,对于上下文相关词表示构建的模型来说,相比对任务进行级联的知识迁移,多任务学习无疑是一种更好的增加任务相关特征信息方法。
系统效率实验结果与分析
我们使用10000句语料对级联的独立模型和多任务模型进行了运行时间测试,表3中展示了在对语料进行分词、词性、实体识别完整预测的所用总体时间,也对其中每一层网络的前向运行时间进行了统计。最终,通过总体预测时间计算了平均分析速度。
表3所任务实验系统时间效率结果
由上表能够发现,多任务模型由于共享了bert表示层计算结果,相比每个任务需要重新计算表示层的独立模型的级联系统所用分析时间更少,多任务分析速度有两倍以上的显著提升。通过对每一层分析时间的分别统计法相,与我们设想的相似,在三个任务组成的多任务系统中,独立模型相比多任务模型在表示层计算使用了近乎3倍时间,在整个系统中这部分又是计算复杂的,占用整体分析时间最多,减少表示层的计算可以有效的降低分析时间,显著提升系统分析效率。
由于深度学习框架内存池技术的系能优化,观测运行时内存难以反映模型具体存储占用情况,我们使用模型参数规模来衡量模型的现骨干层使用的空间。并按照目前常用的压缩模型配置,使用16位浮点数表示模型参数,计算出了不同模型理论空间占用情况,结果见表4所示。
表4多任务实验系统空间占用结果
可以发现,bert表示层包含了模型几乎全部参数,在独立模型级联系统中,由于每个任务都使用了独立的表示,使用参数模型为多任务模型的三倍。多任务模型,使用共享的表示层结构计算所有任务,极大地减少了系统空间占用。
- 还没有人留言评论。精彩留言会获得点赞!