基于数据分析的软件安全需求推荐模型的实现方法与流程
本发明涉及软件安全技术领域,特别是涉及一种软件安全需求推荐模型。
背景技术:
现代社会与经济越来越依赖社区、金融、能源分配和交通等基础设施,而随着信息技术的发展,这些基础设施也越来越依赖于网络信息系统,例如传统的金融服务有赖于银行业务的办理,而现在的金融服务大多依赖于手机或电脑软件产品,再如传统的家用电器一般表现为单个实体产品,其核心为物理感应设备和电设备的结合,而现代的电器多属于物联网的一部分需要通过软件产品进行控制实现人工智能,以达到满足人们生活便捷的需求,因为软件产品已经渗透进入人们生活的最低层,可以说软件正在悄然影响着人们的生活方式。
然而近年来,人们经常可以从新闻上看到软件产品出现安全故障,例如,某大型网站的用户信息被窃取,大量的用户信息被转卖给非法分子,导致使用该网站的用户账户安全、生活隐私均受到威胁,给用户生活上带来很大的不便,以至用户的流失甚至引起法律纠纷。早前,软件工程协会的互联网安全专家中心的统计数据也显示,报告的应用程序漏洞数量从起初的数百个增加到数百万个,引发安全问题的一个重要原因是没有考虑整个系统的安全需求。例如,cardsystemssolutions通过存储黑客可以获得的历史交易的数据,暴露了约4000万张信用卡的详细信息,原因在于数据是系统的一部分,却被没有被列入安全计划中。
为了降低在软件开发过程中维护安全问题的成本,高质量的安全要求对于高质量信息系统的开发极为重要,有必要在软件产品的开发初期尽可能早的分析软件的安全性特征以获得软件的安全性规范需求。在软件开发的需求阶段获取安全需求的重要性已经得到众多研究学者认可,且此项工作被归纳为需求工程,国内外已有很多研究,更为重要的是,“securityrequirementsanalysis,methodandtools”已经于1999年通过国际组织机构的审批计划。更有很多相关会议如:symposiumonrequirementsengineeringforinformationsecurity(sreis),ieeeinternationalrequirementsengineeringconference(re),这些会议在安全需求的分析、描述和验证等方面进行了深层次研究,其研究成果在也在领域内卓有成效,与此同时,也开发了一系列安全标准(iso/iec系列有17799标准、13335标准、15408标准),这些标准用来协助产品的开发者捕获软件软件的安全性要求,使得开发的软件产品具有较高的安全性。现阶段,国内外的研究中已经提出很多获取安全需求的方法,更有甚者,有研究学者对获取安全需求的方法进行了总结,raja等人总结并分析了存在的安全需求获取方法,包括用例、误用例、滥用例、攻击树、anti模型、问题框架、安全模板和威胁建模等等。在这些方法中,大多数方法需要较强的专家知识,并进行详细的分析,从中抽取出关键资产,依据关键资产得到威胁,进一步对应出与威胁相对应的安全目标,最后将安全目标细化到安全需求上。虽然这些方法可以在一定程度上获得安全性要求,但它们需要效率较低,更依赖于专家,而不是普遍的。
技术实现要素:
本发明旨在提出一种基于数据分析的软件安全需求推荐模型的实现方法,主要从安全威胁的角度出发,构建安全威胁和安全需求的关系模型——共现模型,依据该基于语义聚类的共现模型根据产品所收到的威胁推荐相应的安全需求,给研发人员提供全面、合理的安全需求,以保障开发人员对软件的安全开发。
本发明的一种基于数据分析的软件安全需求推荐模型的实现方法,该方法包括以下流程:
步骤一、收集不同软件产品的安全威胁描述:从软件securitytarget文档中手动抽取出安全威胁描述,构建安全威胁描述数据库;依据在securitytarget文档中包含的软件产品的安全威胁,构建每个软件产品和安全威胁描述之间的映射关系,同时,根据软件securitytarget文档中所需的安全需求,构建产品与安全需求之间的映射关系;
步骤二、提取不同软件产品之间的安全威胁的特征:首先,对commoncriteria官网中提供的securitytarget文档进行详细解读,从中抽取出安全威胁描述构成数据集;然后,计算不同产品之间安全威胁的相似度,并将数据集中的安全威胁编码为向量。基于步骤一收集的不同软件产品的安全威胁描述,使用自然语言处理技术中的语义模型skip-thoughts来聚类不同软件产品中安全威胁之间的相似度,并生成一个不同软件产品之间安全威胁的安全威胁相似度特征矩阵,安全威胁相似度特征矩阵表示为
s(pnt'x1,pmt'x2),m∈n,n=1,2,...,n,n≠m,x1∈mn,x2=1,2,...,mm
其中,s表示不同产品之间的安全威胁相似度,pnt’表示产品n编码后的安全威胁向量,n表示产品的编号,m表示安全威胁的数量,mn表示产品n的威胁数量,mm表示产品m的威胁数量;
过滤掉安全威胁相似度特征矩阵的特征值为1、2或3时的安全威胁,继而得到相似安全威胁特征;
步骤三、构建共现模型,即删除中间产品层,为每个软件产品的安全威胁标记安全需求,挖掘新的安全威胁与安全需求映射关系:首先,根据所选类别标记软件产品的安全要求构建当前产品和对应的安全需求的二元组;然后,根据通用标准对安全需求进行预处理和编号;根据软件产品和安全威胁的一对多关系以及软件产品和安全需求之间的一对多关系,删除中间产品层后,获得安全威胁与安全要求之间的映射关系,进而,建立安全威胁-安全需求之间的关系。将安全威胁与安全需求的映射关系表示如下:
{<ti,1,ti,2,···ti,j,···,ti,n>,<sri>}
其中,i表示产品编号,n表示产品i的安全威胁的数量,ti,j表示安全威胁描述,sri表示产品i的安全需求,其包括安全保证组件和安全功能组件;
计算每个软件产品与其他软件产品的共有安全需求,获得n个[n-1,k]的0-1矩阵,k表示当前软件产品所包含的安全需求组件的总数;结合安全威胁相似度矩阵,进一步得到了不同安全威胁之间的共有组件标识矩阵
w(pitncj)=w-1(pitncj)+s(pnti',pmt'x2)
其中,w(pitncj)表示第n个产品的第i个威胁的第j个组件的权重,初始化为0,w-1(pitncj)表示第n个产品的第i个威胁的第j个组件在前一个状态时的权重;
根据步骤二得到的安全威胁相似度特征矩阵,结合标注的安全需求,通过累加权重的方式得到安全威胁与安全需求之间的相关程度矩阵
经过以上处理之后得到了安全威胁与安全需求的共现模型,共现模型的输入为:不同产品之间的安全威胁相似度特征矩阵s、每个安全威胁的安全需求向量集
本发明预期能够达到如下有益效果:
1、在新的软件产品研发的初级阶段,根据软件产品类别,利用已经训练好的安全威胁特征来聚类相似的安全威胁得到安全威胁特征;
2、利用召回率、精准率和f1值对安全需求推荐结果的质量进行评估。另外,还对比了不同类型的产品的推荐结果的精准率,可以看出,本方法推荐的安全需求的精确度较为稳定。
3、在软件开发生命周期的需求阶段为软件产品推荐高质量的安全需求,高质量的安全需求将有助于产生高质量的软件产品,以减少因后期需求忽略的安全问题而造成的经济损,这也将有助于减少后期的维护成本以及bug的修复成本。
附图说明
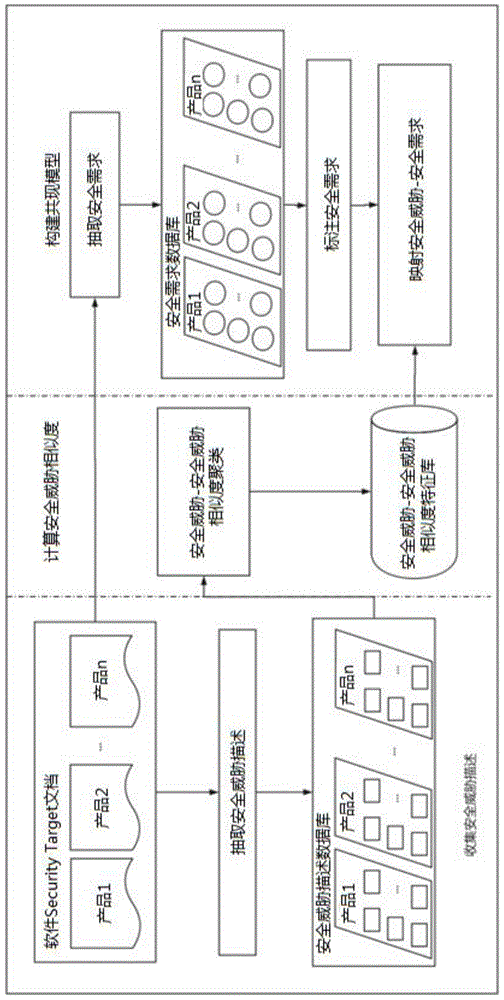
图1为本发明的基于数据分析的软件安全需求推荐模型实现方法的整体流程框架示意图。
具体实施方式
以下结合附图和实施例对本发明技术方案进行详细描述。
本发明的基于大数据分析的安全需求推荐模型实现方法,基于大量的st文档、结合自然语言处理技术中的语义模型skip-thought挖掘安全威胁与安全需求之间的关系,在此基础上,联合眼下存在的协同过滤方法构建安全需求的自动推荐方案,来为给定的新的软件信息系统推荐高质量的安全需求。当给定新的待开发的信息系统时,根据其安全威胁描述,自动为其推荐完备的安全性需求以保证其安全性。其中。st文档被分为训练集和测试集,训练集训练模型然后根据测试集来验证其推荐的安全需求的正确率。
如图1所示,基于大数据分析的安全需求推荐模型实现方法的实现框架由收集安全威胁描述、计算不同产品中安全威胁之间的相似性得到相似度特征、挖掘安全威胁与安全需求之间的关系。
步骤一、收集不同软件产品的安全威胁描述:从软件securitytarget文档中手动抽取出安全威胁描述(基于自然语言处理技术的语义模型来构建软件产品功能描述以及安全威胁描述的匹配规则。从cc官方网站给定的大量的st文档中抽取大量的安全威胁描述和软件产品功能描述。一方面,通过自然语言处理技术分析安全威胁描述中的语言特征,并提取安全威胁描述中的关键字,构建主体库、行为库以及资产库。另一方面,提取功能描述的特征,通过关键字匹配的规则根据功能关键字来构建安全威胁。从而,当给定功能描述的新的软件产品时,根据规则得到安全威胁描述。在研究过程中发现cc中提供的安全需求和需求文档中定义的威胁表达结构是相似的,分为主体,操作和资产。主体通常是指具有某种权限的个人,例如未经授权,授权等。操作通常是指受试者的行为。对象通常是指资源或资产。经仔细阅读文献并进行实验对比,得到的结论是安全要求和安全威胁的结构是相似的,含义是相关的。),构建安全威胁描述数据库(其表述形式为段式文本);依据在securitytarget文档中包含的软件产品的安全威胁,构建每个软件产品和安全威胁描述之间的映射关系,同时,根据软件securitytarget文档中所需的安全需求,构建产品与安全需求之间的映射关系,即为产品标记安全需求。
如表1所示,为本发明实施例的九种类型的产品名称。
表1
步骤二、提取不同软件产品之间的安全威胁的特征:首先,对commoncriteria官网中提供的securitytarget文档进行详细解读与理解,从中提出安全威胁描述;然后,构建安全威胁特征库,并训练出安全威胁的特征向量,安全威胁特征库用作训练集。基于步骤一收集的不同软件产品的安全威胁描述,使用自然语言处理技术中的语义模型skip-thoughts来使用自然语言处理技术中的语义聚类算法来聚类不同产品相似的安全威胁,并生成一个不同软件产品之间安全威胁的相似度特征矩阵,此特征值在1-5之间,其中1表示两个安全威胁不相似,5表示两个安全威胁具有较高的相似度。语义模型skip-thoughts将数据集中的安全威胁编码为向量,是一种通用的无监督学习方法,该模型依赖于连续文本的训练语料库,并且只要训练集足够大,训练集就不会偏向任何特定领域或应用。对于训练好的模型,语义和句法属性相同的句子被映射到类似的向量空间中,该模型包含语义相似度计算方法。将安全威胁相似度计算函数表示为:
s(pnt'x1,pmt'x2),m∈n,n=1,2,...,n,n≠m,x1∈mn,x2=1,2,...,mm
其中,s表示不同产品之间的安全威胁相似度,pnt’表示产品n编码后的安全威胁向量,n表示产品的编号,m表示安全威胁的数量,mn表示产品n的威胁数量,mm表示产品m的威胁数量。
将安全威胁相似度特征矩阵表示为
步骤三、构建共现模型,即删除中间产品层,抽取每个软件产品的安全需求,挖掘安全威胁与安全需求映射关系:首先,根据所选类别标记软件产品的安全要求构建当前产品和对应的安全需求的二元组;然后,根据通用标准对安全需求进行预处理和编号。根据软件产品和安全威胁的一对多关系以及软件产品和安全需求之间的一对多关系,删除中间产品层后,获得安全威胁与安全要求之间的映射关系。删除产品层的具体处理为:cc官方网站上下载的大量经过验证的软件产品抽取安全威胁和安全需求,得到两组关系:产品:安全威胁=(1:n),产品:安全需求=(1:m),表示产品包含若干个安全威胁,安全需求包含若干个安全组件,进而,建立安全威胁-安全需求之间的关系。将安全威胁与安全需求的映射关系表示如下:
{<ti,1,ti,2,···ti,j,···,ti,n>,<sri>}
其中,i表示产品编号,n表示产品si的安全威胁的数量,ti,j表示安全威胁描述,sri表示产品i的安全需求,其包括安全保证组件和安全功能组件。
安全功能组件被编号为1-134,安全保证组件被编号为135-271,接下来,计算每个软件产品与其他软件产品的共有安全需求,获得n个[n-1,k]的0-1矩阵,k表示当前软件产品所包含的安全需求组件的总数。其中,共有组件(包括安全功能组件和安全保证组件)标识为1,其余组件(包括安全功能组件和安全保证组件)标识为0。结合安全威胁相似度矩阵,进一步得到了不同安全威胁之间的共有组件标识矩阵
w(pitncj)=w-1(pitncj)+s(pnti',pmt'x2)
其中,w(pitncj)表示第n个产品的第i个威胁的第j个组件的权重,初始化为0,w-1(pitncj)表示第n个产品的第i个威胁的第j个组件在前一个状态时的权重。
根据步骤二得到的安全威胁相似度特征矩阵,结合标注的安全需求,通过累加权重的方式得到安全威胁与安全需求之间的相关程度矩阵
经过以上处理之后得到了安全威胁与安全需求的共现模型,共现模型的输入为:不同产品之间的安全威胁相似度特征矩阵s、每个安全威胁的安全需求向量集
本发明建模过程的具体实施方式举例描述如下:
(1)环境搭建
本发明使用theano在nvidiateslam40gpu运行,安全威胁之间的相似度计算工具为github上的skip-thoughts模型,skip-thoughts模型为一个句子编码器,训练后的模型可以将语义相似的句子映射到相似的向量空间中,通过足够大的数据集,训练的模型结果不会偏向任何特定的领域或应用,因此,我们使用skip-thoughts中的大型数据集来训练skip-thoughts模型。
(2)数据抽取
数据抽取工作是从securitytarget文档中抽取做实验使用到的数据集。一方面,从securitytarget文档的第五章中抽取安全需求,包括安全功能组件和安全保证组件
其中安全需求表达为安全功能组件和安全保证组件。commoncriteria标准的第二第三部分分别包含了134个安全功能组件和138个安全保证组件,组件的表示形式为“类子类组件号”,故抽取规则分别为f**_###.no和a**_###.no,例如,faugen.1\faugen.1的含义具体如下:
f表示安全功能,au的全称为securityaudit,即安全审计类,安全审计涉及识别、生成日志、存储日志和分析与安全相关活动相关的信息,可以检查生成的审计记录,以确定发生了哪些安全相关活动以及由谁(哪个用户)负责,即fau表示安全功能的安全审计类。gen的全称为securityauditdatageneration,即安全审计数据生成,该系列定义了记录tsf控制下发生的安全相关事件的要求。该系列标识审计级别,列举tsf可审计的事件类型,并确定应在各种审计记录类型中提供的最小审计相关信息集。数字1表示组件的层级,faugen.1表示审计数据生成定义可审计事件的级别,并指定应记录在每个记录中的数据列表,faugen.2表示与用户身份相关,toe安全功能需要把审计事件和个人用户身份关联起来。
另一方面,从给出的securitytarget文档的第三章中抽取安全威胁的描述。
(3)评估参数设定
本发明通过计算测试集的正确率、召回率以及f1值来对模型进行评估。在本模型中正确率表达为针对当前软件产品所推荐出的安全需求为实际安全需求占推荐出的安全需求总数的比例,比例越高,推荐出的安全需求越准确。召回率表达为所推荐出的安全需求为实际安全需求占当前产品中实际安全需求总数的比例,比例越高,推荐出的安全需求涵盖的实际安全需求越全面。f1值,即精确值和召回率的调和均值,f1值越高方法越有效。
正确率计算公式如下:
召回率计算公式如下:
f1值计算公式如下:
其中,tp表示将正类预测为正类的数量;tn表示将负类预测位负类的数量;fp表示将负类预测位正类的数量;fn表示将正类预测为负类的数量。
建模结果:过程中仔细研究了commoncriteria,安全需求以类、族、组件的形式由浅及深,模型使用组件来表达安全需求。此模型需要设置θ为软件产品推荐一组安全需求,θ是安全威胁与安全需求权重以及安全威胁之间的相似度得到的值,其中,相似度与权重值均属于[0,1],所以,θ值基本很小,因此使用等间距的值来观察评估参数的趋势。
随着θ的增长,正确率也会提高,也就是说,增强相似度或组件的权重,所推荐的安全需求的正确率随之升高。这表示安全需求和威胁之间的权重以及我们模型中安全威胁之间的相似度是可信的,但是,随着精确度的增长,推荐的安全需求变得越来越不全面。根据f值的定义可知,f值是大于0.8说明精确度和召回率都是可信的。根据结果,首先,根据精确度的趋势可知训练集中的数据量越多,训练的模型的效果就越好。其次,确保了推荐的安全需求的正确性,这有助于分析师减少安全需求分析的工作量和分析操作的复杂性。
本发明可以用来进一步验证安全需求的正确性。
- 还没有人留言评论。精彩留言会获得点赞!