一种基于卷积神经网络的微博新闻摘要抽取式生成方法与流程
本发明涉及自然语言处理领域,尤其涉及一种基于卷积神经网络的微博新闻摘要抽取式生成方法。
背景技术:
文本自动生成是自然语言处理领域的一个重要研究方向。文本自动生成技术也有着广泛的应用前景,可应用于智能问答、机器翻译等人机交互操作中;另外,文本自动生成系统也可用于实现新闻稿件的自动撰写、图书馆的检索等。
在自然语言处理和人工智能领域,文本自动生成技术已经有了若干有影响力的成果和应用,例如美联社自2014年7月开始已采用新闻写作软件自动撰写新闻稿件来报道公司业绩,这大大减少了记者的工作量。
文本自动生成技术中关键的技术便是文本摘要生成,通过自动分析给定的文档或文档集,摘取其中的要点信息,最终输出一篇短小的摘要。目前的文本摘要方法主要分为两种方法:生成式和抽取式。抽取式主要基于句子抽取,也就是以原文中的句子作为单位进行评估与抽取。第二种是生成式,生成式方法通常需要利用自然语言理解技术对文本进行语法、语义分析,对信息进行融合,利用自然语言生成技术生成新的摘要句子。
现有的技术文献中,发明专利cn201610232659.9提出的基于深度神经网络的摘要生成系统,以及发明专利cn201811416029.2中提出的基于深度学习和注意力机制的摘要生成系统,均属于生成式。这种生成式的摘要生成方法由于自然语言理解与自然语言生成本身都没有得到很好的解决,生成的摘要中包含了部分关键字,往往无法组成正确的语序,其性能还尽如人意。
技术实现要素:
本发明的目的在于提供一种基于卷积神经网络的微博新闻摘要抽取式生成方法,从而解决现有技术中存在的前述问题。
为了实现上述目的,本发明采用的技术方案如下:
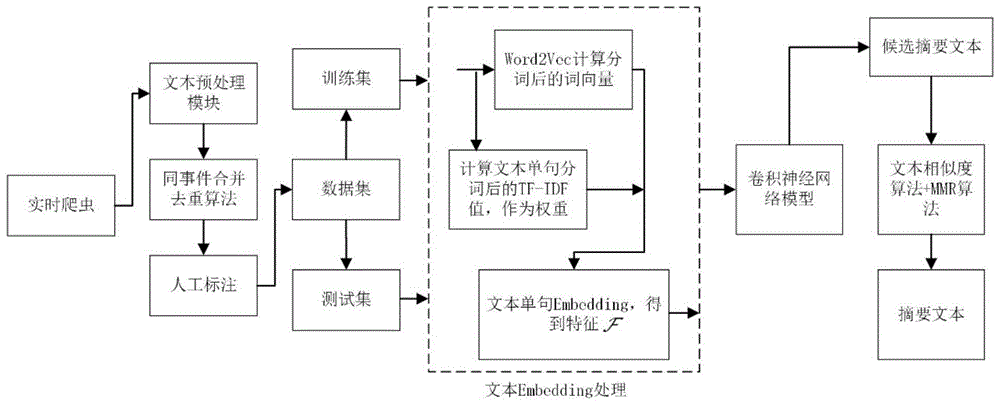
一种基于卷积神经网络的微博新闻摘要抽取式生成方法,包括以下步骤:
s1,利用数据采集模块抓取微博网站内容作为初始新闻数据集q;
s2,对新闻数据集q进行处理,得到数据集q′;
s3,构建卷积神经网络对处理后的新闻数据集q′进行事件元素抽取,得到摘要内容s;
s4,利用文本相似度算法和最大边缘相关模型对摘要内容s进一步处理,得到抽取后的摘要文本summary。
优选地,步骤s2中对新闻数据集q进行处理的方式为过滤、同类合并去重,具体包括:
s21,遍历新闻数据集q的所有样本,去除图片、视频、html标签,得到新闻数据集qtmp;
s22,遍历步骤s21中新闻数据集qtmp的所有样本,提取样本的时间、地点,记为时间地点标记矩阵
s23,遍历上述步骤s22中得到的标记矩阵
优选地,步骤s3具体包括:
s31,遍历新闻数据集q'的所有样本,对样本进行单句切分、人工标注,得到模型数据集
其中lj为样本切分后的文本单句cj的标签,lj∈{时间,地点,事件描述,起因,经过,结果},j=1,2,...,k,k为模型数据集单句总数;
s32,提取模型数据集
s33,构建一个卷积神经网络,记为textcnn,其中textcnn网络结构为卷积层、最大池化层、2个全连接层、softmax层;
s34,将上述模型数据集特征
s35,利用步骤s34中划分好的训练集和验证集对步骤s33中得到的卷积神经网络textcnn进行训练,得到训练好的网络模型model;
s36,利用上述步骤s35得到模型model对步骤s34中的测试集进行摘要抽取,得到仅包括时间、地点、事件描述、经过、起因、结果的文本单句集合,记为摘要内容s。
优选地,步骤s32具体包括:
1).提取模型数据集
其中,δi为文本单句c1的tf-idf特征值,tf-idf特征值对应的词汇表为
2).提取词汇表v的word2vec特征,得到文本单句c1特征矩阵fn×m:
其中fi为词汇表v1中第i个词的word2vec特征向量,m为特征向量维数,m取值为300;
3).利用步骤1)中得到的权值矩阵δ1和步骤2)得到的特征矩阵fn×m,得到文本单句c1特征矩阵f':
4).对上述步骤得到的特征矩阵f'按行进行归一化,得到归一化后的特征矩阵
5).遍历模型数据集
优选地,步骤s4具体包括:
s41,遍历摘要内容s中的所有文本单句,计算文本单句之间的余弦相似度值
s42,过滤掉摘要内容s中余弦相似度值
s43,利用最大边缘相关模型对摘要内容
优选地,步骤s43具体包括:
(1).遍历摘要内容
(2).将上述步骤得到的候选摘要文本s添加到候选摘要集合summary中;
(3).重复步骤(1)~(2)c次,得到候选摘要集合summary,即为抽取后的摘要文本,其中,c为正整数且
优选地,步骤(1)中采用的公式为:
其中,λ取值为0.9,
优选地,步骤s1中的数据采集模块为实时爬虫模块。
本发明的有益效果是:
本发明提出的基于卷积神经网络的微博新闻摘要抽取式生成方法,具有以下优点:
1、本发明提出的基于卷积神经网络的微博新闻摘要抽取式生成方法,对微博新闻内容进行摘要抽取,摘要句子具有更好的可读性,方便新闻工作人员等利用生成的摘要内容进一步快速分析、检索。
2、本发明中的摘要抽取方法,采用了tf-idf加权的word2vec词向量,进一步利用卷积神经网络综合考虑句子的多种特征进行句子重要性的分类,完成对包含新闻六大元素的内容的提取,包括时间、地点、事件描述、经过、起因、结果等六大元素,并进一步完成摘要生成。
3、本发明采用了文本相似度算法去除语义重复内容,并采用了最大边缘相关模型,用以权衡抽取内容的相关性和多样性,得到更加全面、准确的内容摘要。
附图说明
图1是本发明实施例1中摘要抽取式生成方法流程图;
图2是本发明实施例1中卷积神经网络示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施方式仅仅用以解释本发明,并不用于限定本发明。
实施例1
本实施例提供一种基于卷积神经网络的微博新闻摘要抽取式生成方法,如图1所示,包括以下步骤:
s1,利用实时爬虫模块抓取微博网站内容作为初始新闻数据集,记为新闻数据集q={q1,q2,...,qn},其中,qi为新闻数据集中第i个样本,i=1,2,...,n,n为新闻数据集样本总数;
s2,对新闻数据集q进行过滤、同类合并去重,得到数据集q′,具体的步骤为:
s21,遍历新闻数据集q的所有样本,去除图片、视频、html标签,得到新闻数据集qtmp;
s22,遍历步骤s21中新闻数据集qtmp的所有样本,提取样本的时间、地点,记为时间地点标记矩阵
s23,遍历上述步骤s22中得到的标记矩阵
s3,构建卷积神经网络对处理后的新闻数据集q′进行事件元素抽取,得到摘要内容s,具体步骤如下:
s31,遍历新闻数据集q'的所有样本,对样本进行单句切分、人工标注,得到模型数据集
其中lj为样本切分后的文本单句cj的标签,lj∈{时间,地点,事件描述,起因,经过,结果},j=1,2,...,k,k为模型数据集单句总数;
s32,提取模型数据集
1).提取模型数据集
其中,δi为文本单句c1的tf-idf特征值,tf-idf特征值对应的词汇表为
2).提取词汇表v的word2vec特征,得到文本单句c1特征矩阵fn×m:
其中fi为词汇表v1中第i个词的word2vec特征向量,m为特征向量维数,m取值为300;
3).利用步骤1)中得到的权值矩阵δ1和步骤2)得到的特征矩阵fn×m,得到文本单句c1特征矩阵f':
4).对上述步骤得到的特征矩阵f'按行进行归一化,得到归一化后的特征矩阵
5).遍历模型数据集
s33,构建一个卷积神经网络,如图2所示,记为textcnn,其中textcnn网络结构为卷积层、最大池化层、2个全连接层、softmax层;
本实施例中的卷积层中卷积核共256个,卷积核尺寸为5,激活函数为relu函数,全连接层神经元为128个,学习率0.001,随机失活率为0.5;
s34,将上述模型数据集特征
s35,利用步骤s34中划分好的训练集和验证集对步骤s33中得到的卷积神经网络textcnn进行训练,得到训练好的网络模型model;
s36,利用上述步骤s35得到模型model对步骤s34中的测试集进行摘要抽取,得到仅包括时间、地点、事件描述、经过、起因、结果的文本单句集合,记为摘要内容s。
s4,利用文本相似度算法和最大边缘相关模型对摘要内容s进一步处理,得到抽取后的摘要文本summary,步骤s4具体包括:
s41,遍历摘要内容s中的所有文本单句,计算文本单句之间的余弦相似度值
s42,过滤掉摘要内容s中余弦相似度值
s43,利用最大边缘相关模型对上述步骤得到的摘要内容
步骤s43具体包括:
(1).遍历摘要内容
其中,λ取值为0.9,
(2).将上述步骤得到的候选摘要文本s添加到候选摘要集合summary中;
(3).重复步骤(1)~(2)c次,得到候选摘要集合summary,即为抽取后的摘要文本,其中,c为正整数且
通过采用本发明公开的上述技术方案,得到了如下有益的效果:
1、本发明提出的基于卷积神经网络的微博新闻摘要抽取式生成方法,对微博新闻内容进行摘要抽取,摘要句子具有更好的可读性,方便新闻工作人员等利用生成的摘要内容进一步快速分析、检索。
2、本发明中的摘要抽取方法,采用了tf-idf加权的word2vec词向量,进一步利用卷积神经网络综合考虑句子的多种特征进行句子重要性的分类,完成对包含新闻六大元素的内容的提取,包括时间、地点、事件描述、经过、起因、结果六大元素,并进一步完成摘要生成。
3、本发明采用了文本相似度算法去除语义重复内容,并采用了最大边缘相关模型,用以权衡抽取内容的相关性和多样性,得到更加全面、准确的内容摘要。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!