基于难度的个性化习题推荐方法、系统及介质与流程
本发明涉及教育领域的习题推荐技术,具体涉及一种基于难度的个性化习题推荐方法、系统及介质。
背景技术:
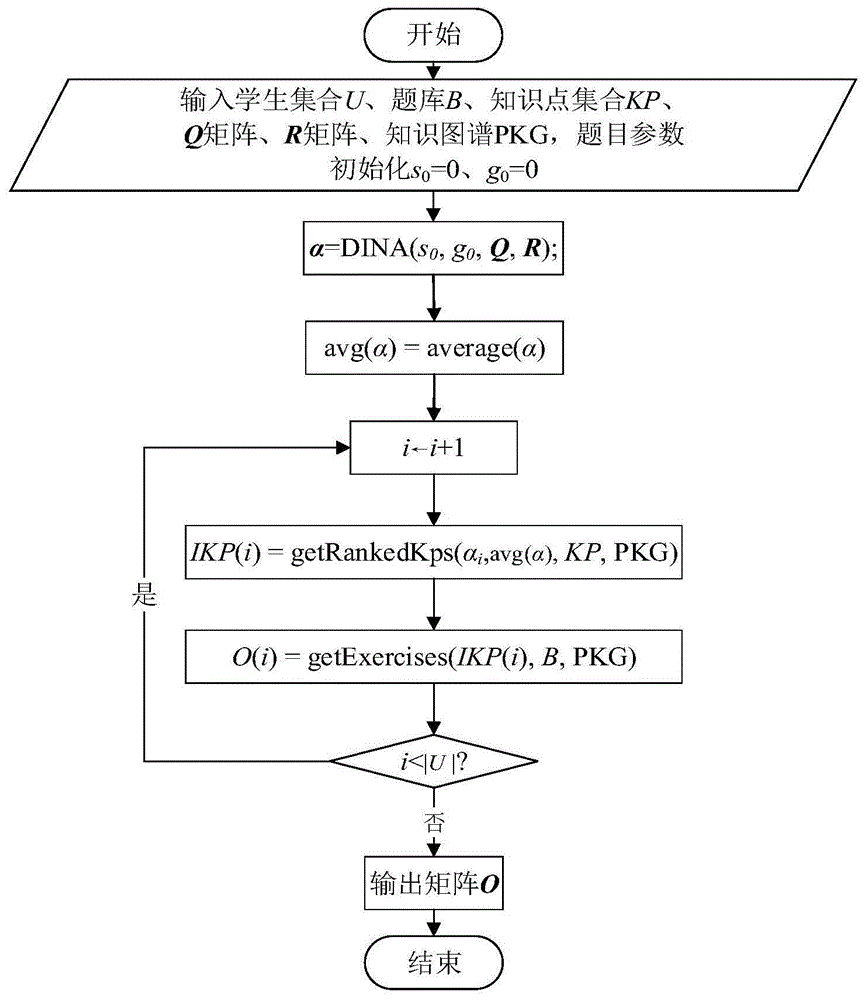
:伴随着大数据和互联网时代的到来,智能教育愈发受到人们重视,呈现出快速发展的态势。习题在智能教育中扮演着举足轻重的角色,是帮助学生在课后巩固课堂所学知识点的重要教学资源。由于当下学生能够获取的习题资源规模庞大,而学生的课后时间有限,因此如何基于学生的知识状态向他们推荐有针对性的个性化习题从而提高学生基于习题的自主学习成效是一个重要的研究问题。目前的个性化习题推荐技术可分为两类:基于协同过滤的推荐技术和基于学生知识状态的推荐技术。其中,基于协同过滤的推荐技术采用了基于近邻的推荐思想或是基于模型的推荐思想以实现个性化推荐。基于近邻的推荐思想首先根据学生们在试题或习题上的答题表现计算学生之间的相似性从而找到与目标学生相似的学生;然后用相似学生在目标习题上的得分来预测目标学生的得分,进而可根据该预测得分向目标学生推荐习题。基于模型的推荐思想以矩阵分解方法应用最为广泛,其思路是通过将学生-习题的得分矩阵分解为两个或多个矩阵的乘积,并利用分解的结果来预测目标学生在目标习题上的得分,进而根据预测的得分进行习题推荐。基于协同过滤的个性化习题推荐技术简单易懂,取得了良好的推荐效果。然而,该类技术在推荐策略设计上只考虑了具有相似学习特征的学生而忽略了学生各自的知识状态,因而存在局限性。为了弥补该不足,学者们提出了基于学生知识状态的个性化习题推荐技术,以基于认知诊断模型的推荐技术为代表。该技术以教育数据挖掘领域的认知诊断理论为基础,通过构建认知诊断模型实现对学生知识状态(即知识点掌握程度)的建模。常见的认知诊断模型有单维连续模型(以项目反应模型irt为代表)和多维离散模型(以dina模型为代表)。其中irt模型基于学生在试题上的得分情况得到学生正确答题的概率分布,并进而利用该概率分布将学生的知识状态建模为一维的能力值。相比于irt模型,dina模型引入了描述习题和知识点之间关联关系的q矩阵作为习题的先验知识,并基于学生的历史答题表现将学生的知识状态描述为一个多维的知识点掌握向量,同时引入习题的猜测参数和失误参数,实现知识点层面的学生知识状态的准确刻画。由于dina模型能够在准确刻画学生知识状态的同时具有比irt模型更优秀的参数可解释性,故被广泛应用于解决个性化习题推荐问题。相比于基于协同过滤的个性化习题推荐技术,基于认知诊断模型的推荐技术虽然成功刻画了单个学生的知识状态,但却不能利用相似学生的共性进行个性化推荐。针对以上不足,近年来朱天宇等人同时结合认知诊断模型和协同过滤思想提出了一种个性化习题推荐技术pmf-cd,通过融合两类技术的优势来弥补各自在习题推荐应用上表现出的不足。pmf-cd技术以学生答题得分矩阵r和习题-知识点关联矩阵q为输入,首先基于dina模型计算学生对各个知识点的掌握程度值,并依此推测学生对习题的掌握程度;其次将学生对习题的掌握程度值作为先验输入应用于概率矩阵分解中,并基于分解的结果预测目标学生对目标习题的潜在答对概率,进而以该潜在答对概率作为目标习题相对于目标学生的难度值;最后基于目标学生给出的习题难度值区间向其推荐个性化习题。由于同时考虑了学生知识状态的个性、学生之间的相似性以及习题的难度特性,pmf-cd技术比其它技术在习题推荐的合理性和有效性方面表现更好。综上所述,个性化习题推荐技术是当下的研究热点并已取得了不少研究成果,然而上述研究均没有充分考虑习题难度给学生认知带来的影响,即只是简单将所得到的推荐习题不分难易顺序地推送给学生。由于人类对新事物的认知是遵循从易到难、由浅人深的客观规律的,因此忽略掉习题间难度区别的个性化习题推荐技术很难帮助学生实现循序渐进地高效自主学习。目前已有学者针对题目难度建模展开了研究。例如loukina等人通过回归模型对听力题的次序与听力题难度间的关系展开了研究。huang等人则以英语阅读题为研究对象,利用神经网络模型设计出英语阅读题难度的统一度量框架,即通过计算阅读文本中每个句子对特定阅读题的难度贡献进而得到每个阅读题的难度预测值。上述研究从题目出现次序以及相关材料对题目的支撑度这两个方面对题目的客观性难度进行了建模量化,却忽略了测试者本身的能力对题目难度带来的主观性影响。因此,也有学者从测试者的知识状态出发去定义题目相对于测试者的主观性难度。例如cadavid等人利用项目反应模型irt对题目相对于学生的主观性难度进行建模,并基于学生历史作答情况通过最大期望算法(em算法)计算题目的难度系数[12]。前述pmf-cd技术将某题目相对于某学生的主观性难度定义为基于认知诊断模型得到的该学生对该题目的潜在答对概率。可见,由题目本身属性决定的题目客观难度以及由测试者本身知识状态决定的题目主观难度是衡量题目难度的两个重要方面,然而现有研究工作对题目难度的度量没能结合这两个重要方面。技术实现要素:本发明要解决的技术问题:针对现有技术的上述问题,提供一种基于难度的个性化习题推荐方法、系统及介质,本发明综合考虑了习题的主观难度和客观难度,以基于学生各自知识状态得到的学生未掌握知识点为作为习题的推荐依据,以基于知识点间的先决依赖关系得到未掌握知识点的难易顺序作为习题的主推荐顺序,并以习题的客观难度值为依据确定每个未掌握知识点相关习题的推荐顺序,最终实现基于难度的个性化习题推荐,具有难度建模有据可依、全面合理的优点,能够提升学生基于习题的自主学习效果的有效性、指导学生由易至难、循序渐进地完成基于习题的自主学习。为了解决上述技术问题,本发明采用的技术方案为:一种基于难度的个性化习题推荐方法,实施步骤包括:1)基于输入的习题-知识点关联矩阵q和学生答题情况矩阵r,利用现有的认知诊断模型dina(s0,g0,q,r)接口计算得到记录了学生集合u中每个学生对所有知识点掌握程度值的矩阵α,其中s0为题目猜测参数的初始值,g0为失误参数的初始值;2)基于矩阵α计算所有学生对每个知识点的平均掌握程度值并记录至一维向量3)遍历选择学生答题情况矩阵r中对应学生集合u中尚未处理的学生ui;4)以一维向量为输入获取学生ui由易到难排序后的未掌握知识点列表ikp(i);5)根据未掌握知识点列表ikp(i)获取学生ui由易到难排列的个性化推荐习题列表o(i);6)判断是否学生集合u中是否仍有未处理的学生,如果仍有未处理的学生,则跳转执行步骤3);否则,跳转执行步骤7);7)将学生集合u中所有学生由易到难排列的个性化推荐习题列表o(i)构建得到学生集合u的个性化推荐习题矩阵o,返回个性化推荐习题矩阵o。可选地,步骤4)的详细步骤包括:4.1)初始化学生ui的未掌握知识点列表ikp(i)为空;4.2)遍历学生ui的知识点掌握程度向量αi中的元素,其中知识点掌握程度向量αi表示知识点掌握矩阵α中的第i行,针对每一个遍历得到的当前元素αik:如果当前元素αik小于一维向量中对应的元素则将当前元素αik对应的知识点kpk加入到学生ui的未掌握知识点列表ikp(i)中;4.3)遍历学生ui的未掌握知识点列表ikp(i)中的每一个知识点,针对每一个遍历得到的当前知识点ikp:初始化pr集合为空,获取当前知识点ikp的所有先决知识点得到先决知识点集合pr,遍历先决知识点集合pr中的每一个先决知识点pr,每一个先决知识点pr的属性优先推荐度score初始化为0,如果先决知识点pr隶属于学生ui的未掌握知识点的列表ikp(i)则将先决知识点pr的属性优先推荐度score加1;4.4)根据优先推荐度score对学生ui的未掌握知识点列表ikp(i)进行降序排序;4.5)返回降序排序后的学生ui的未掌握知识点列表ikp(i)。可选地,步骤4.3)中知识点ikp的所有先决知识点包括在给定的知识图谱pkg上以知识点ikp为起点,所有直接指向和间接指向知识点ikp的知识结点。可选地,步骤5)的详细步骤包括:5.1)遍历学生ui的未掌握知识点列表ikp(i)中的每一个知识点得到当前知识点ikp;5.2)从给定的题库b中获取所有与当前知识点ikp相关的习题序列items,遍历习题序列items中的每一个习题,针对遍历得到的当前习题item,若习题序列items中的某习题除当前知识点ikp之外的所关联的知识点同时不包含在学生ui的未掌握知识点列表ikp(i)中,则将当前习题item加入当前知识点ikp的待推荐习题集o(i)(ikp)中,否则说明该习题还存在相关的其它知识点该学生也没掌握,将该当前习题item加入当前知识点ikp的候选习题集合ocand中;5.3)检查当前知识点ikp的待推荐习题集o(i)(ikp)的习题数量|o(i)(ikp)|,如果习题数量|o(i)(ikp)|不够k个则从当前知识点ikp的候选习题集合ocand中选取所涉及的知识点的平均掌握程度值最大的前k-|o(i)(ikp)|道习题加入到当前知识点ikp的待推荐习题集o(i)(ikp)中;5.4)遍历当前知识点ikp的待推荐习题集o(i)(ikp)的每一个习题,针对遍历得到的当前的习题item1求取客观难度值d(item1);5.5)基于客观难度值d(item1)对当前知识点ikp的待推荐习题集o(i)(ikp)进行升序排序;5.6)检查当前知识点ikp的待推荐习题集o(i)(ikp)的习题数量|o(i)(ikp)|,如果习题数量|o(i)(ikp)|多于k则从中删除那些客观难度值较大的习题;5.7)判断学生ui的未掌握知识点列表ikp(i)中的每一个知识点是否已经遍历完毕,如果尚未遍历完毕,则跳转执行步骤5.1);否则,跳转执行下一步;5.8)针对所有知识点ikp的待推荐习题集o(i)(ikp)由易至难顺序排序,从而得到学生ui由易到难排列的个性化推荐习题列表o(i)。可选地,步骤5.4)中求取客观难度值d(item1)的函数表达式如式(1)所示;式(1)中,d(vj)表示针对习题vj计算得到的客观难度值d(item1),ai为习题vj的第i个相关习题属性,wi表示习题vj的第i个相关习题属性ai的权重值,a(vj)为习题vj的客观难度值量化相关的习题属性集,且d(vj)∈[0,1]。可选地,所述客观难度值量化相关的习题属性集包括下述七种习题属性:题干知识点数量、题干知识点和正确答案知识点在知识图谱pkg中的平均路径距离、干扰选项知识点和正确选项知识点在知识图谱pkg中的平均路径距离、填空的数量、答案字数、每个空备选答案的平均数目、判断题已知条件的知识点和结论知识点在知识图谱pkg中的平均路径距离。此外,本发明还提供一种基于难度的个性化习题推荐系统,包括:主观难度度量程序单元,用于基于输入习题-知识点关联矩阵q和学生答题情况矩阵r,利用现有的认知诊断模型dina(s0,g0,q,r)接口计算得到记录了学生集合u中每个学生对所有知识点掌握程度值的矩阵α,其中s0为题目猜测参数的初始值,g0为失误参数的初始值;主观难度均值计算程序单元,用于基于矩阵α计算所有学生对每个知识点的平均掌握程度值并记录至一维向量α;学生遍历选择程序单元,用于遍历选择学生答题情况矩阵r中对应学生集合u中尚未处理的学生ui;学生未掌握知识点生成程序单元,用于以一维向量为输入获取学生ui由易到难排序后的未掌握知识点列表ikp(i);学生个性化推荐习题列表生成程序单元,用于根据未掌握知识点列表ikp(i)获取学生ui由易到难排列的个性化推荐习题列表o(i);学生遍历判断程序单元,用于判断是否学生集合u中是否仍有未处理的学生,如果仍有未处理的学生,则跳转执行学生遍历选择程序单元;否则,跳转执行输出矩阵构建程序单元;输出矩阵构建程序单元,用于将学生集合u中所有学生由易到难排列的个性化推荐习题列表o(i)构建得到学生集合u的个性化推荐习题矩阵o,返回个性化推荐习题矩阵o。此外,本发明还提供一种基于难度的个性化习题推荐系统,包括计算机设备,该计算机设备被编程或配置以执行所述基于难度的个性化习题推荐方法的步骤。此外,本发明还提供一种基于难度的个性化习题推荐系统,包括计算机设备,该计算机设备的存储介质上存储有被编程或配置以执行所述基于难度的个性化习题推荐方法的计算机程序。此外,本发明还提供一种计算机可读存储介质,该计算机可读存储介质上存储有被编程或配置以执行所述基于难度的个性化习题推荐方法的计算机程序。和现有技术相比,本发明具有下述优点:本发明综合考虑了习题的主观难度和客观难度,以基于学生各自知识状态得到的学生未掌握知识点为作为习题的推荐依据,以基于知识点间的先决依赖关系得到未掌握知识点的难易顺序作为习题的主推荐顺序,并以习题的客观难度值为依据确定每个未掌握知识点相关习题的推荐顺序,最终实现基于难度的个性化习题推荐,具有难度推荐建模科学合理、习题客观难度的量化更有据可依的优点,能够提升学生基于习题的自主学习效果的有效性、指导学生由易至难、循序渐进地完成基于习题的自主学习。附图说明图1为本发明实施例方法的基本流程示意图。图2为本发明实施例方法的实现框架示意图。图3为本发明实施例方法步骤4)的流程示意图。图4为本发明实施例方法步骤5)的流程示意图。图5为本发明实施例中的习题-知识点关联矩阵q。图6为本发明实施例中的包含先决依赖关系的课程知识图谱。图7为本发明实施例中实验一学生前后分数提升情况。图8为本发明实施例中实验二学生前后分数提升情况。图9为本发明实施例中推荐前后平均分的提升情况。图10为本发明实施例中推荐前后学生答题时间的减少情况。具体实施方式为了描述方便,本实施例中涉及的主要符号如表1所示:表1:描述技术涉及的主要符号。符号描述符号描述u学生集合ui第i个学生v习题集合vj第j个习题r学生-习题得分矩阵q习题-知识点关联矩阵kp知识点集合ikp未掌握的知识点集合αi学生ui的知识点掌握程度向量pkg包含先决依赖关系的课程知识图谱如图1所示,本实施例基于难度的个性化习题推荐方法的实施步骤包括:1)基于输入的习题-知识点关联矩阵q和学生答题情况矩阵r,利用现有的认知诊断模型dina(s0,g0,q,r)接口计算得到记录了学生集合u中每个学生对所有知识点掌握程度值的矩阵α,其中s0为题目猜测参数的初始值,g0为失误参数的初始值;2)基于矩阵α计算所有学生对每个知识点的平均掌握程度值并记录至一维向量图1中表示为avg(α)=average(α);3)遍历选择学生答题情况矩阵r中对应学生集合u中尚未处理的学生ui;4)以一维向量为输入获取学生ui由易到难排序后的未掌握知识点列表ikp(i);5)根据未掌握知识点列表ikp(i)获取学生ui由易到难排列的个性化推荐习题列表o(i);6)判断是否学生集合u中(一共|u|个学生)是否仍有未处理的学生,如果仍有未处理的学生,则跳转执行步骤3);否则,跳转执行步骤7);7)将学生集合u中所有c学生由易到难排列的个性化推荐习题列表o(i)构建得到学生集合u的个性化推荐习题矩阵o,返回个性化推荐习题矩阵o。为了描述方便,下文将本实施例基于难度的个性化习题推荐方法简称为redi(recommendationbasedondifficulty)方法。为了对学生知识状态进行建模,本实施例利用认知诊断dina模型计算学生对各个知识点的掌握程度。给定学生集合u={u1,...,ui},习题集合v={v1,...,vj},则记录了学生和习题得分信息的r矩阵可表示为r=[rij]i×j,其中rij=1表示学生ui答对试题vj(rij=0则表示答错)。设习题集合v所考察的知识点集合为kp={kp1,...,kpk},则记录了试题与知识点间的关联关系的q矩阵可表示为q=[qjk]j×k,其中qjk=1表示试题vj考察了知识点kpk(0则表示未考察)。dina模型将学生ui的知识状态描述为一个向量αi={αi1,...,αik},其中αik为学生ui对知识点kpk的掌握程度值,且αik∈[0,1]。在已知αi的情况下,对于学生ui未作答的试题vj,可根据下式计算得到学生ui对试题vj的潜在正确作答情况:上式中,ηij表示学生ui对试题vj的潜在正确作答情况,表示学生ui对试题vj所考察知识点的掌握情况(qjk表示试题vj是否考察知识点k),kp表示知识点集合。ηij取值为0或1:当学生ui掌握了试题vj考察的全部知识点时ui=1,若存在至少一个知识点没有掌握时ui=0。此外,dina模型还引入了题目失误率参数s和猜测率参数g。最终,可基于下式求取学生ui对试题vj的实际正确作答概率:上式中,pj(αi)表示学生ui对试题vj的实际正确作答概率,αi表示学生ui的知识点掌握程度向量,p(rij=1|αi)表示已知αi的前提下学生ui实际答对试题vj的概率,sj表示试题vj的失误率,gj表示试题vj的猜测率,ηij表示学生ui对试题vj的潜在正确作答情况,和表示学生ui实际答对试题vj时猜测率和失误率的参与情况(ηij为1时且表示实际答对的概率只受到失误率的影响)。dina模型利用em算法最大化上述公式的边缘似然值,从而得到学生ui的知识点掌握向量αi。本实施例基于难度的个性化习题推荐方法的实现框架如图2所示,结合图1和图2可知,本实施例基于难度的个性化习题推荐方法的整个实现流程包含三个主要步骤:基于学生知识状态的习题主观难度度量。即一方面以习题-知识点关联矩阵q和学生答题结果矩阵r为输入,利用认知诊断dina模型计算学生对各个知识点掌握程度,从而确定学生未掌握知识点集合。另一方面基于教材、wikipedia及领域专家的经验构建包含知识点间先决依赖关系的课程知识图谱,并基于图谱中表征的知识点间先决依赖关系确定学生未掌握知识点的推荐顺序。这一步骤实际上是以习题所关联的知识点为出发点量化了习题对于学生的主观难度。基于习题属性的客观难度度量。即首先确定影响题目难度的多种题目属性(例如题型、题干知识点数量等),然后基于题库中题目的这些属性整合量化得到题目客观难度的度量方程。基于题目难度的个性化习题推荐。即首先以学生未掌握知识点和未掌握知识点的推荐顺序为输入确定推荐的习题集以及习题集中习题的主推荐顺序,即保证所关联的知识点难度低的习题总体上优先于所关联的知识点难度高的习题进行推荐。然后按题目的客观难度值按由易到难的顺序确定同一知识点的多道习题的推荐顺序。本实施例中,步骤4)具体是采用函数getrankedkps实现。如图3所示,步骤4)的详细步骤包括:4.1)初始化学生ui的未掌握知识点列表ikp(i)为空;4.2)遍历学生ui的知识点掌握程度向量αi中的元素,其中知识点掌握程度向量αi表示知识点掌握矩阵α中的第i行,针对每一个遍历得到的当前元素αik:如果当前元素αik小于一维向量中对应的元素则将当前元素αik对应的知识点kpk加入到学生ui的未掌握知识点列表ikp(i)中;4.3)遍历学生ui的未掌握知识点列表ikp(i)中的每一个知识点,针对每一个遍历得到的当前知识点ikp:初始化pr集合为空,获取当前知识点ikp的所有先决知识点得到先决知识点集合pr,遍历先决知识点集合pr中的每一个先决知识点pr,每一个先决知识点pr的属性优先推荐度score初始化为0,如果先决知识点pr隶属于学生ui的未掌握知识点的列表ikp(i)则将先决知识点pr的属性优先推荐度score加1;4.4)根据优先推荐度score对学生ui的未掌握知识点列表ikp(i)进行降序排序;4.5)返回降序排序后的学生ui的未掌握知识点列表ikp(i)。本实施例中,步骤4.3)中知识点ikp的所有先决知识点包括在给定的知识图谱pkg上以知识点ikp为起点,所有直接指向和间接指向知识点ikp的知识结点。本实施例中,步骤5)具体是采用函数getexercises实现。如图4所示,步骤5)的详细步骤包括:5.1)遍历学生ui的未掌握知识点列表ikp(i)中的每一个知识点得到当前知识点ikp;5.2)从给定的题库b中获取所有与当前知识点ikp相关的习题序列items,遍历习题序列items中的每一个习题,针对遍历得到的当前习题item,若习题序列items中的某习题除当前知识点ikp之外的所关联的知识点同时不包含在学生ui的未掌握知识点列表ikp(i)中,则将当前习题item加入当前知识点ikp的待推荐习题集o(i)(ikp)中,否则说明该习题还存在相关的其它知识点该学生也没掌握,将该当前习题item加入当前知识点ikp的候选习题集合ocand中;5.3)检查当前知识点ikp的待推荐习题集o(i)(ikp)的习题数量|o(i)(ikp)|,如果习题数量|o(i)(ikp)|不够k个则从当前知识点ikp的候选习题集合ocand中选取所涉及的知识点的平均掌握程度值最大的前k-|o(i)(ikp)|道习题加入到当前知识点ikp的待推荐习题集o(i)(ikp)中;5.4)遍历当前知识点ikp的待推荐习题集o(i)(ikp)的每一个习题,针对遍历得到的当前的习题item1求取客观难度值d(item1);5.5)基于每道题的客观难度值d(·)对当前知识点ikp的待推荐习题集o(i)(ikp)进行升序排序;5.6)检查当前知识点ikp的待推荐习题集o(i)(ikp)的习题数量|o(i)(ikp)|,如果习题数量|o(i)(ikp)|多于k则从中删除那些客观难度值较大的习题;5.7)判断学生ui的未掌握知识点列表ikp(i)中的每一个知识点是否已经遍历完毕,如果尚未遍历完毕,则跳转执行步骤5.1);否则,跳转执行下一步;5.8)基于所有知识点ikp的待推荐习题集o(i)(ikp)由易至难的排列顺序,从而得到学生ui由易到难排列的个性化推荐习题列表o(i)。本实施例中影响不同题型难度值的习题属性以及每种习题属性数据的归一化的方法,基于熵值法整合与特定题型相关的所有归一化的习题属性值,从而实现对特定题型习题的客观难度值的量化,具有量化客观准确度高的优点。本实施例中,步骤5.4)中求取客观难度值d(item1)的函数表达式如式(1)所示;式(1)中,d(vj)表示针对习题vj计算得到的客观难度值d(item1),ai为习题vj的第i个相关习题属性,wi表示习题vj的第i个相关习题属性ai的权重值,a(vj)为量化习题vj的客观难度值所用的习题属性集,且d(vj)∈[0,1]。式(1)所采用的熵值法赋权值的基本思路是根据习题属性值离散程度的大小确定习题属性的权重,即习题属性取值离散程度越大则其包含的信息量越大,因此对该属性赋予越大的权重。本实施例中,所述量化习题客观难度值所用的习题属性集包括下述七种习题属性:题干知识点数量、题干知识点和正确答案知识点在知识图谱pkg中的平均路径距离、干扰选项知识点和正确选项知识点在知识图谱pkg中的平均路径距离、填空的数量、答案字数、每个空备选答案的平均数目、判断题已知条件的知识点和结论知识点在知识图谱pkg中的平均路径距离。上述七种习题属性从不同习题类型(包括单选题、多选题、判断题、填空题和主观题)的特点出发,实现了七种影响习题客观难度的题目属性。本实施例中,上述七种习题属性的具体量化方式如下:1)题干知识点数量:习题所考察的知识点数量越多则其难度值越大。令习题vj的题干知识点数量为sj,且假设sj服从泊松分布,即sj~p(λs),则基于题干知识点数量sj刻画的习题vj的难度值nkp(vj)的定义如式(2)所示;nkp(vj)=1-p(p(λs)≥sj)(2)式(2)中,nkp(vj)表示基于题干知识点数量sj刻画的习题vj的难度值,sj表示习题vj的题干包含的知识点数量,p(λs)表示服从数学期望为λs的泊松分布,λs表示泊松分布的数学期望,p(p(λs)≥sj)表示当前泊松分布中取值大于sj的概率。根据式(2)易知,p(p(λs)≥sj)的取值越小,习题vj考察的题干知识点数量sj就越多,则难度值nkp(vj)就越大。2)题干知识点和正确答案知识点在知识图谱pkg中的平均路径距离:对于填空题、选择题和主观题,当题干知识点和正确答案知识点在pkg中的路径越长则说明两个知识点间的联系跨度越大,即中间需要掌握的过渡知识点就越多,则习题难度值也应越大。令习题vj题题干知识点和正确答案知识点在知识图谱pkg中的平均路径距离为xj,且假设xj服从正态分布,即xj~n(μx,σ2x)。则基于题干知识点和正确答案知识点在知识图谱pkg中的平均路径距离xj所刻画的习题vj的难度值dcorrect(vj)的定义如式(3)所示;dcorrect(vj)=1-p(n(μx,σ2x)≥xj)(3)式(3)中,dcorrect(vj)表示基于题干知识点和正确答案知识点在知识图谱pkg中的平均路径距离xj所刻画的习题vj的难度值,xj表示习题vj题干的知识点和其正确答案的知识点在pkg中的平均路径,n(μx,σ2x)表示服从数学期望为μx,标准方差为σ2x的正态分布,p(n(μx,σ2x)≥xj)表示当前正态分布中取值大于xj的概率。根据式(3)易知,p(n(μx,σ2x)≥xj)的取值越小,习题vj的基于题干知识点和正确答案知识点在知识图谱pkg中的平均路径距离xj就越大,则难度值dcorrect(vj)就越大。3)干扰选项知识点和正确选项知识点在知识图谱pkg中的平均路径距离:对于选择题,当干扰选项知识点和正确选项知识点在pkg中的路径越小则说明习题干扰选项的迷惑性越强,即习题难度值应越大。令习题vj的干扰选项知识点和正确选项知识点在知识图谱pkg中的平均路径距离为wj,且假设wj服从正态分布,即wj~n(μw,σ2w)。则基于干扰选项知识点和正确选项知识点在知识图谱pkg中的平均路径距离wj刻画的习题vj的难度值dwrong(vj)的定义如式(4)所示;dwrong(vj)=1-p(n(μw,σ2w)≤wj)(4)式(4)中,dwrong(vj)表示基于干扰选项知识点和正确选项知识点在知识图谱pkg中的平均路径距离wj刻画的习题vj的难度值,wj表示习题vj的干扰选项知识点和正确选项知识点在知识图谱pkg中的平均路径距离,n(μw,σ2w)表示服从数学期望为μw,标准方差为σ2w的正态分布,p(n(μw,σ2w)≤wj)表示当前正态分布中取值大于wj的概率。根据式(4)易知,当p(n(μw,σ2w)≤wj)的取值越小,习题vj考察的基于干扰选项知识点和正确选项知识点在知识图谱pkg中的平均路径距离wj就越小,则难度值dwrong(vj)也就越大。4)填空的数量:填空题的填空数量越多则其难度值越大。令习题vj的填空的数量为fj,且假设填空的数量fj服从泊松分布,即fj~p(λf)。则基于填空的数量fj刻画的习题难度值nblank(vj)的定义如式(5)所示;nblank(vj)=1-p(p(λf)≥fj)(5)式(5)中,nblank(vj)表示基于填空的数量fj刻画的习题难度值,fj表示习题vj的填空的数量,p(λf)表示服从数学期望为λf的泊松分布,p(p(λf)≥fj)表示当前泊松分布中取值大于fj的概率。根据式(5)易知,当p(p(λf)≥fj)的取值越小,习题vj的填空的数量fj就越多,则难度值nblank(vj)也就越大。5)答案字数:对于填空题和主观题而言,其答案字数越多则其难度值越大。令习题vj的答案字数为lj,且假设答案字数lj服从泊松分布,即lj~p(λl)。则基于答案字数lj刻画的习题vj的难度值nword(vj)的定义如式(6)所示;nword(vj)=1-p(p(λl)≥lj)(6)式(6)中,nword(vj)表示基于答案字数lj刻画的习题vj的难度值,lj示习题vj的答案字数,p(λl)表示服从数学期望为λl的泊松分布,p(p(λl)≥lj)表示当前泊松分布中取值大于lj的概率。根据式(6)易知,当p(p(λl)≥lj)的取值越小,习题vj的答案字数lj就越多,则难度值nword(vj)也就越大。6)每个空备选答案的平均数目:填空题每个空的备选答案数目越少则题目的难度越大。令习题vj每个空备选答案的平均数目为tj,且假设每个空备选答案的平均数目tj服从泊松分布,即tj~p(λt)。则基于每个空备选答案的平均数目tj刻画的习题vj的难度值nanswer(vj)的定义如式(7)所示;nanswer(vj)=1-p(p(λt)≤tj)(7)式(7)中,nanswer(vj)表示基于每个空备选答案的平均数目tj刻画的习题vj的难度值,tj表示习题vj每个空备选答案的平均数目,p(λt)表示服从数学期望为λt的泊松分布,p(p(λt)≤tj)表示当前泊松分布中取值大于tj的概率。根据式(7)易知,当p(p(λt)≤tj)的取值越小,习题vj每个空备选答案的平均数目tj就越少,则难度值nanswer(vj)也就越大。7)判断题已知条件的知识点和结论知识点在知识图谱pkg中的平均路径距离:判断题的题干往往会给出一个已知条件和结论,如果已知条件知识点和结论知识点在pkg中的平均路径距离越长,则学生做出正确判断所需掌握的它们之间的跨度知识点就越多,因而判断题越难。令习题vj(判断题)的已知条件的知识点和结论知识点在知识图谱pkg中的平均路径距离为kj,且假设已知条件的知识点和结论知识点在知识图谱pkg中的平均路径距离kj服从正态分布,即kj~n(μk,σ2k)。则基于已知条件的知识点和结论知识点在知识图谱pkg中的平均路径距离kj所刻画的习题vj的难度值djudge(vj)的定义如式(8)所示;djudge(vj)=1-p(n(μk,σ2k)≥kj)(8)式(8)中,djudge(vj)表示基于已知条件的知识点和结论知识点在知识图谱pkg中的平均路径距离kj所刻画的习题vj的难度值,kj表示习题vj(判断题)的已知条件的知识点和结论知识点在知识图谱pkg中的平均路径距离,n(μk,σ2k)表示服从数学期望为μk,标准方差为σ2k的正态分布,p(n(μk,σ2k)≥kj)表示当前正态分布中取值大于kj的概率。根据式(8)易知,当p(n(μk,σ2k)≥kj)的取值越小,习题vj的已知条件知识点和结论知识点在pkg中的路径距离越长,则难度值djudge(vj)也就越大。上述题目属性取值所服从的泊松分布或正态分布的参数值(即泊松分布的λ值、正态分布的μ值和σ值)可基于对题库中题目属性取值的统计信息并利用极大似然估计方法得到。由于量化每种题型的客观难度所用到的题目属性不同,表2用符号①至⑦指代上述七种不同的题目属性,进而给出了和每种题型的客观难度值相关的习题属性。表2:每种题型涉及的习题属性。①②③④⑤⑥⑦单选题√√√多选题√√√判断题√√填空题√√√√√主观题√√√本实施例基于难度的个性化习题推荐方法的算法复杂度分析如下:本实施例方法中最耗时的是基于dina模型计算学生对各个知识点的掌握程度值这部分。且由于dina模型利用em算法进行求解,其时间复杂度是o(|u|*2|kp|*m)(其中|u|是学生数量,|kp|是知识点数量,m是em算法的迭代次数),故本实施例方法的时间复杂度是o(|u|*2|kp|*m)。本实施例方法的空间存储消耗主要来自于存储q矩阵(大小为|kp|*|b|)和r矩阵(大小为|u|*|b|),其中|kp|是知识点的数目,|b|是题库的习题数量。则可知本实施例方法的空间复杂度为o(|kp|+|u|)*|b|)。为了测试本实施例基于难度的个性化习题推荐方法的有效性,本文在基于微信小程序开发的在线教学系统itest中分别实现了本实施例方法(redi推荐技术)和与本文最相关的pmf-cd推荐技术,并基于两门课的真实课堂实验来分析对比这两种推荐技术。其中,pmf-cd技术用其计算得到的习题的潜在答对概率确定每道习题的难度值,并在推荐习题前基于习题的难度值对推荐习题进行由易至难地排序。通过对比pmf-cd技术的推荐习题规模,将本实施例方法(redi推荐技术)中每个未掌握知识点的推荐习题数目k设置为8,从而保证pmf-cd技术和本实施例方法(redi推荐技术)推荐的习题规模大致相当。两次课堂实验的相关信息已在表3中列出。表3:两次课堂实验的相关信息。课程学生类型学生总题数知识点数据库原理本科生508611数据库理论硕士生108611每次课堂实验包括以下三个流程:(1)推荐前测试:全体学生用统一的20道习题进行课堂测试,基于这次测试的结果本实施例方法(redi推荐技术)和pmf-cd技术均可以基于认知诊断dina模型获取学生对各个知识点的掌握程度值;(2)学生基于推荐习题自主学习:将学生随机分为人数相等的两组:一组基于本实施例方法(redi推荐技术)推荐的个性化习题完成自主学习;另一组则基于pmf-cd技术推荐的个性化习题完成自主学习。为了验证由易至难的习题推荐策略是否有助于提高学生基于习题的自主学习效果,自主学习过程中要求学生必须按习题的推荐顺序来逐一完成对推荐习题的学习。两种技术使用的推荐题库相同,均包含46道习题。(3)推荐后测试:当所有学生都完成基于推荐习题的自主学习之后,组织全体学生用统一的另一套包含了20道习题的测试题进行课堂测试,用以检验不同推荐技术对学生自主学习的促进作用。两次课堂实验均采用同样的题库和测试题目,涉及数据库范式理论的11个知识点,分别是:1nf(kp1)、2nf(kp2)、3nf(kp3)、bcnf(kp4)、主属性(kp5)、传递函数依赖(kp6)、决定因素(kp7)、函数依赖(kp8),码(kp9)、部分函数依赖(kp10)和非主属性(kp11)。且推荐前测试和推荐后测试所包含的20道习题和知识点的对应关系均满足如图5所示的描述习题-知识点间关联性的q矩阵,课程的知识图谱如图6所示。下文将从以下两方面进行实验评估和分析:(1)第一方面:对比两种推荐技术在推荐后测试比推荐前测试的分数提升以及推荐后测试比推荐前测试的平均答题时间缩减这两方面的表现,证明本实施例方法(redi推荐技术)对学生自主学习的促进作用优于pmf-cd技术。推荐效果对比如图7~图10所示,其中图7和图8以灰度图的可视化形式对比了两次课堂实验中不同推荐技术对学生个体成绩提升的帮助效果,其中图7是第一次实验结果,图8是第二次实验结果。图中某学生对应方块的灰度越浅则表示该学生先后两次测试的成绩提升幅度越大,反之灰度越深则表示该学生的成绩提升幅度越小。从图可知,两次课堂实验中基于本实施例方法(redi推荐技术)推荐的习题完成自主学习的学生的成绩提升幅度从总体变化趋势上均优于基于pmf-cd技术推荐的习题完成自主学习的学生的成绩提升幅度。图9展示了两次课堂实验中不同推荐技术对学生总体成绩提升的帮助效果。由图可见,课堂实验1中redi组的学生自主学习后的测试平均分是77,较推荐前的测试平均分66提升了17%,是pmf-cd组的学生两次测试的平均分提升率(9.5%)的近两倍。而课堂实验2中本实施例方法(redi推荐技术)的redi组的学生两次测试的平均分提升率(32.2%)是pmf-cd组的学生平均分提升率(6.1%)的5倍。这是因为本实施例方法(redi推荐技术)对习题难度的定义既考虑了习题难度对于学生的主观性又考虑了习题难度的客观性,学生因此可以真正由易至难地基于推荐的习题实现循序渐进的自主学习,提高有限时间内自主学习的效率。此外还观察到实验2由于课堂是小班授课(只包含10名学生),因此教师可以充分参与到学生的自主学习阶段,给两组学生讲解其不会的推荐习题,因而使得本实施例方法(redi推荐技术)基于习题难度进行习题推荐的优越性得到更显著体现。图10对比了两次课堂实验中不同推荐技术的学生组前后两次测试的平均答题时间。由图可知,在两次课堂实验中,本实施例方法(redi推荐技术)的redi组学生第二次测试相对于第一次测试的平均答题时间缩减幅度均大于pmf-cd组学生的平均答题时间缩减幅度。特别地,第二次课堂实验中本实施例方法(redi推荐技术)的redi组学生的平均答题时间缩减幅度(17.6%)是pmf-cd组学生的平均答题时间缩减幅度(1.5%)的近12倍。综合图9和图10的实验结果可知,本实施例方法(redi推荐技术)推荐的个性化学习进行自主学习后,学生对于包含相同知识点测试题的测试成绩有更大幅度的提升,且测试用时有更大幅度的下降。这说明本实施例方法(redi推荐技术)比pmf-cd推荐技术更能帮助学生提高其基于习题的自主学习的效果。(2)第二方面:基于f检验从统计学的角度证明本实施例方法(redi推荐技术)优于pmf-cd技术该结论的有效性。下文将以课堂实验一为例利用f检验对两种推荐技术实验结果的有效性进行分析。具体而言,对每组学生在推荐后测试中的成绩进行方差分析(anovas)进而从统计角度证明“本实施例方法(redi推荐技术)的推荐成效优于pmf-cd技术”该结论的有效性。下面给出原假设h0和备择假设h1,并设置信度为0.05。h0:本实施例方法(redi推荐技术)的redi组学生推荐后的测试分数和pmf-cd组学生推荐后的测试分数不存在显著性差异。h1:本实施例方法(redi推荐技术)的redi组学生推荐后的测试分数和pmf-cd组学生推荐后的测试分数具有显著性差异。表4:学生推荐后的测试分数的相关统计信息。推荐技术学生数分数均值标准差标准误差redi(本实施例方法)2577.008.8981.780pmf-cd2570.6010.9282.186表4给出了推荐后测试中不同推荐技术下的两组学生的测试分数的相关统计信息。通过计算可知对于h0假设的检验结果为:f(1,48)=5.16,mse=99.3,p=0.028。由于检验水平p为0.028因而小于置信度0.05,故拒绝原假设h0,接受备择假设h1。f检验的检验结果说明了本实施例方法(redi推荐技术)redi组学生的推荐后的测试分数相比于pmf-cd组学生推荐后的测试分数具有显著性差异,即证明了“本实施例方法(redi推荐技术)在推荐成效方面优于pmf-cd技术”这个结论的有效性。综上两个方面所述,基于习题练习进行自主学习是学生巩固课堂所学知识点的最主要方式。个性化习题推荐结合学生薄弱知识点推荐习题,能够通过因材施教而有效提高学生自主学习的成效。然而,现有个性化习题推荐技术在推荐习题时没有充分考虑推荐习题的难易顺序排列对推荐成效的影响。鉴于此,本实施例提出了一种基于难度的个性化习题推荐方法,本实施例方法(redi推荐技术)将习题难度建模为相对于学生知识状态的主观难度和由习题属性决定的客观难度,并基于所量化的习题难度实现由易至难、由浅至深的个性化习题推荐策略。多次课堂实验验证了本实施例方法(redi推荐技术)对于提高学生基于习题的自主学习成效的有效性。在习题难度建模方面,本实施例基于难度的个性化习题推荐方法综合考虑了习题的主观难度和客观难度。具体而言,本实施例基于难度的个性化习题推荐方法首先基于学生历史答题数据并利用认知诊断dina模型计算出学生对知识点的掌握程度值作为知识点相对于学生的主观难度值,基于该难度值得到学生未掌握的知识点集合。考虑到知识点之间存在的先决依赖关系会导致不同知识点在难度上存在客观差异。例如在关系数据库理论课程中,二范式(2nf)是三范式(3nf)的先决知识点,即掌握3nf之前需要先掌握2nf,因而知识点3nf的难度比知识点2nf的难度要大。因此为了帮助学生实现对知识点循序渐进的学习,本实施例基于难度的个性化习题推荐方法进而利用当下流行的知识图谱技术,即基于课程知识图谱中所描述的知识点之间的先决依赖关系确定学生未掌握知识点从易至难的推荐顺序。本实施例基于难度的个性化习题推荐方法利用所抽取的习题的属性和课程知识图谱量化一个知识点相关联的每道习题的客观难度值。本实施例基于难度的个性化习题推荐方法以基于学生各自知识状态得到的学生未掌握知识点为作为习题的推荐依据,以基于知识点间的先决依赖关系得到未掌握知识点的难易顺序作为习题的主推荐顺序,并以习题的客观难度值为依据确定每个未掌握知识点相关习题的推荐顺序,最终实现基于难度的个性化习题推荐。总之,本实施例基于难度的个性化习题推荐方法文的主要贡献如下:(1)本实施例设计和提出了综合考虑由题目本身属性造成的题目客观难度和由学生知识状态造成的题目主观难度的习题难度度量方法。特别地,本实施例方法还利用了知识点之间的先决依赖关系和知识图谱技术来提升对题目难度建模的合理性。(2)本实施例方法基于比相关工作更丰富的习题属性集(包括题干知识点数量、题干和正确答案知识点在知识图谱中的平均路径距离等)来量化习题的客观难度值,使对习题客观难度的量化更有据可依。(3)本实施例方法基于以上对习题难度的度量方法设计与实现了基于难度的个性化习题推荐。本实施例方法能够指导学生由易至难、循序渐进地完成基于习题的自主学习。将本实施例方法嵌入实现于在线教学系统itest中,并通过先后组织60名学生参加的两次真实课堂实验来验证本实施例方法对于提升学生基于习题的自主学习效果的有效性。此外,本实施例还提供一种基于难度的个性化习题推荐系统,包括:主观难度度量程序单元,用于基于输入习题-知识点关联矩阵q和学生答题情况矩阵r,利用现有的认知诊断模型dina(s0,g0,q,r)接口计算得到记录了学生集合u中每个学生对所有知识点掌握程度值的矩阵α,其中s0为题目猜测参数的初始值,g0为失误参数的初始值;主观难度均值计算程序单元,用于基于矩阵α计算所有学生对每个知识点的平均掌握程度值并记录至一维向量学生遍历选择程序单元,用于遍历选择学生答题情况矩阵r中对应学生集合u中尚未处理的学生ui;学生未掌握知识点生成程序单元,用于以一维向量为输入获取学生ui由易到难排序后的未掌握知识点列表ikp(i);学生个性化推荐习题列表生成程序单元,用于根据未掌握知识点列表ikp(i)获取学生ui由易到难排列的个性化推荐习题列表o(i);学生遍历判断程序单元,用于判断是否学生集合u中是否仍有未处理的学生,如果仍有未处理的学生,则跳转执行学生遍历选择程序单元;否则,跳转执行输出矩阵构建程序单元;输出矩阵构建程序单元,用于将学生集合u中所有学生由易到难排列的个性化推荐习题列表o(i)构建得到学生集合u的个性化推荐习题矩阵o,返回个性化推荐习题矩阵o。此外,本实施例还提供一种基于难度的个性化习题推荐系统,包括计算机设备,该计算机设备被编程或配置以执行本实施例前述基于难度的个性化习题推荐方法的步骤。此外,本实施例还提供一种基于难度的个性化习题推荐系统,包括计算机设备,该计算机设备的存储介质上存储有被编程或配置以执行本实施例前述基于难度的个性化习题推荐方法的计算机程序。此外,本实施例还提供一种计算机可读存储介质,该计算机可读存储介质上存储有被编程或配置以执行本实施例前述基于难度的个性化习题推荐方法的计算机程序。以上所述仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本
技术领域:
的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1