一种基于复合神经网络建模的数据挖掘与标注方法与流程
本发明涉及领域,尤其涉及一种基于复合神经网络建模的数据挖掘与标注方法。
背景技术:
人工智能发展到今天,数据的作用被越来越凸显出来。训练好一个神经网络模型,通常需要上百万甚至上亿量级的数据。数据的标注周期和成本直接影响了一个人工智能公司的行业竞争力。
神经网络为解决复杂问题提供了一种相对来说比较有效的简单方法。神经网络具有良好的鲁棒性、自组织、自适应、自学习、并行处理、分布存储和高度容错等特性,能根据新的输入数据自适应调整网络参数。而且神经网络对噪声数据具有较强承受能力,对数据分类准确性高,以及可用各种算法进行规则提取。更重要的是神经网络很容易在并行计算机上实现,可以把它的节点分配到不同的cpu上并行计算。因此,可以借助神经网络来进行数据挖掘。但是在利用神经网络进行数据挖掘过程中,神经网络学习算法不能保证收敛到最理想的结果;神经网络很容易过度训练,从而导致在训练数据上工作地很好,而在检验数据上表现欠佳。而且神经网络的学习时间长短影响其在数据挖掘中的应用,网络的训练时间长短与问题的规模、网络的复杂性以及训练算法相关。此外,如何降低标注数据的标注成本,提高标注的效率和质量,是本技术领域亟需解决的技术问题,为解决上述问题,本申请中提出一种基于复合神经网络建模的数据挖掘与标注方法。
技术实现要素:
(一)发明目的
为解决背景技术中存在的技术问题,本发明提出一种基于复合神经网络建模的数据挖掘与标注方法,提高神经网络对数据库进行挖掘时的效率和提高了输出的结果的标注质量。
(二)技术方案
为解决上述问题,本发明提出了一种基于复合神经网络建模的数据挖掘方法,包括以下步骤:
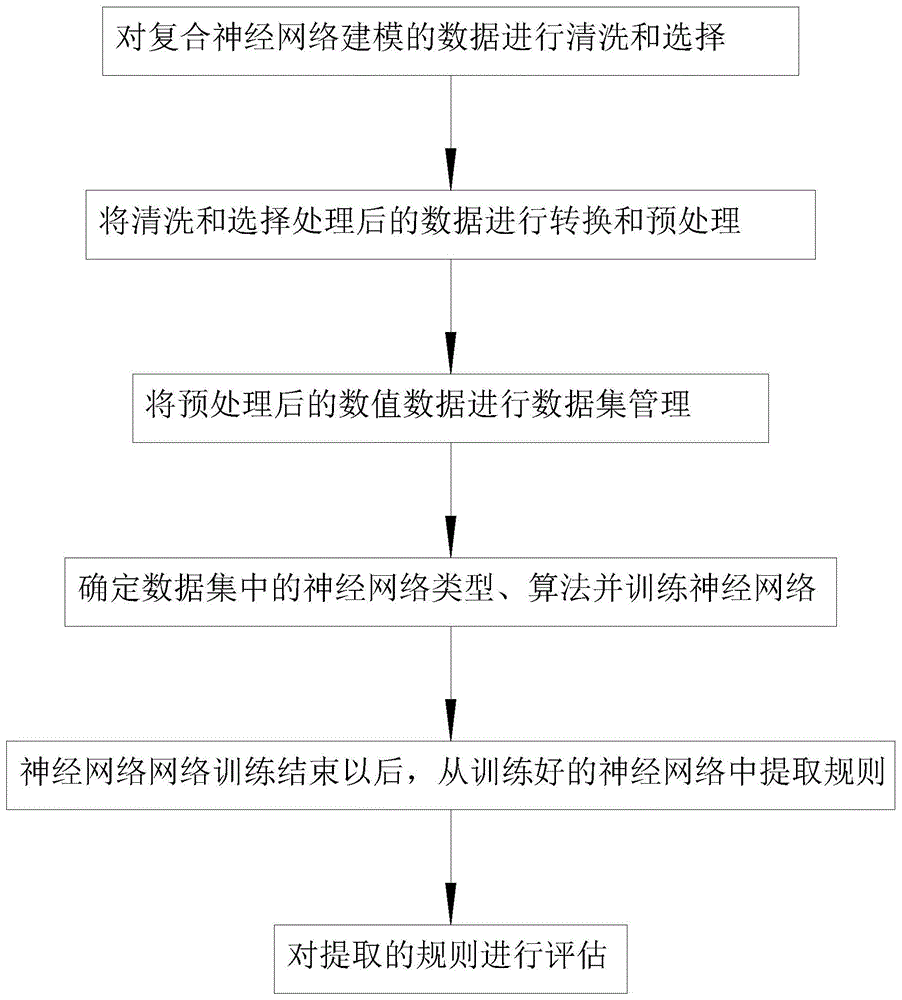
s1、对复合神经网络建模的数据进行清洗和选择;并根据目标和需要进行清洗和选择,剔除不需要的数据;
s2、将清洗和选择处理后的数据进行转换和预处理;将文本数据转换为数值数据进行处理,再对数值型数据采用归一化方法进行预处理;
s3、将预处理后的数值数据进行数据集管理;将预处理后的数值数据随机地分成三个数据集:训练数据集、测试数据集和确认数据集,训练数据集用于训练神经网络,测试数据集用与测试网络的精度,确认数据集用于独立地测试网络;
s4、确定s3中的数据集中的神经网络类型、算法并训练神经网络;神经网络类型采用三层前馈rbf神经网络;
s5、神经网络网络训练结束以后,从训练好的神经网络中提取规则,提取规则采用搜索算法提取规则;
s6、对提取的规则进行评估,对被提取规则用的测试数据集和确认数据集进行测试,验证神经网络数据挖掘的正确性。
优选的,算法采用粗糙集算法训练该神经网络,神经网络输入、输出节点的数目由系统的决策决定,神经网络的输出由模糊推理系统推出正则化输出,隐含层节点的数目由粗糙集算法决定。
优选的,还包括数据标注;数据标注包括以下步骤:
s31、获取待标注的原始数据;
s32、使用整合的算法,对所述原始数据进行分类;
s33、获取数据标注结果,使用整合的算法,对数据标注结果进行自动化审核,筛选出问题标注结果,并对问题标注结果进行标记;具体地,根据历史标注数据库和对比规则,对数据标注结果进行分析,并获取低质量标注结果并标记;
s34、输出经过自动化审核的数据标注结果,数据标注结果中包括数据标注结果和问题标注结果。
优选的,整合算法至少包括聚类算法和标注规则模板。
优选的,对比规则包括相似度对比、聚类分析和有效性检验中的至少一种。
优选的,s32中,筛选问题标准结果的原则是通过判断数据标注结果是否符合人工标注意图所对应的匹配模板,若不匹配,则标记为错误标注结果。
本发明的上述技术方案具有如下有益的技术效果:可以对进行分析、处理、推理、预测,最终根据用户设定的条件,实现最优方案,采用粗糙集算法训练复合神经网络,使复合神经网络在满足精度要求的前提下,减少隐层节点数,从而简化网络结构,加快神经网络的学习速度。以进一步提高神经网络对数据库进行挖掘时的效率,另外,本发明提出的标注方法可以对数据标注结果进行审核,这样就从所有的数据标注结果中找出可能存在问题的问题标注结果,并且将这些问题标注结果标记起来,这样就可以方便对问题标注结果进行审核和修改,极大的方便了找出有问题的标注结果,提高了输出的结果的标注质量。
附图说明
图1为本发明提出的一种基于复合神经网络建模的数据挖掘与标注方法中数据挖掘方法的流程框图。
图2为本发明提出的一种基于复合神经网络建模的数据挖掘与标注方法中数据标注方法的流程框图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明了,下面结合具体实施方式并参照附图,对本发明进一步详细说明。应该理解,这些描述只是示例性的,而并非要限制本发明的范围。此外,在以下说明中,省略了对公知结构和技术的描述,以避免不必要地混淆本发明的概念。
实施例1
如图1和图2所示,本发明提出的一种基于复合神经网络建模的数据挖掘方法,包括以下步骤:
s1、对复合神经网络建模的数据进行清洗和选择;并根据目标和需要进行清洗和选择,剔除不需要的数据;
s2、将清洗和选择处理后的数据进行转换和预处理;将文本数据转换为数值数据进行处理,再对数值型数据采用归一化方法进行预处理;
s3、将预处理后的数值数据进行数据集管理;将预处理后的数值数据随机地分成三个数据集:训练数据集、测试数据集和确认数据集,训练数据集用于训练神经网络,测试数据集用与测试网络的精度,确认数据集用于独立地测试网络;
s4、确定s3中的数据集中的神经网络类型、算法并训练神经网络;神经网络类型采用三层前馈rbf神经网络;
s5、神经网络网络训练结束以后,从训练好的神经网络中提取规则,提取规则采用搜索算法提取规则;
s6、对提取的规则进行评估,对被提取规则用的测试数据集和确认数据集进行测试,验证神经网络数据挖掘的正确性。
在一个可选的实施例中,算法采用粗糙集算法训练该神经网络,神经网络输入、输出节点的数目由系统的决策决定,神经网络的输出由模糊推理系统推出正则化输出,隐含层节点的数目由粗糙集算法决定。
实施例2
根据上述一种基于复合神经网络建模的数据挖掘方法,还包括数据标注,数据标注包括以下步骤:
s31、获取待标注的原始数据;
s32、使用整合的算法,对所述原始数据进行分类;
s33、获取数据标注结果,使用整合的算法,对数据标注结果进行自动化审核,筛选出问题标注结果,并对问题标注结果进行标记;具体地,根据历史标注数据库和对比规则,对数据标注结果进行分析,并获取低质量标注结果并标记;
s34、输出经过自动化审核的数据标注结果,数据标注结果中包括数据标注结果和问题标注结果。
在一个可选的实施例中,整合算法至少包括聚类算法和标注规则模板。
在一个可选的实施例中,对比规则包括相似度对比、聚类分析和有效性检验中的至少一种。
在一个可选的实施例中,s32中,筛选问题标准结果的原则是通过判断数据标注结果是否符合人工标注意图所对应的匹配模板,若不匹配,则标记为错误标注结果。
本发明中,可以对进行分析、处理、推理、预测,最终根据用户设定的条件,实现最优方案,采用粗糙集算法训练复合神经网络,使复合神经网络在满足精度要求的前提下,减少隐层节点数,从而简化网络结构,加快神经网络的学习速度。以进一步提高神经网络对数据库进行挖掘时的效率,另外,本发明提出可以对数据标注结果进行审核,这样就从所有的数据标注结果中找出可能存在问题的问题标注结果,并且将这些问题标注结果标记起来,这样就可以方便对问题标注结果进行审核和修改,极大的方便了找出有问题的标注结果,提高了输出的结果的标注质量。
应当理解的是,本发明的上述具体实施方式仅仅用于示例性说明或解释本发明的原理,而不构成对本发明的限制。因此,在不偏离本发明的精神和范围的情况下所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。此外,本发明所附权利要求旨在涵盖落入所附权利要求范围和边界、或者这种范围和边界的等同形式内的全部变化和修改例。
- 还没有人留言评论。精彩留言会获得点赞!