一种站内搜索系统及方法与流程
本发明属于全文检索技术领域,具体指代一种具备网站传销行为分析的站内搜索系统及方法。
背景技术:
随着互联网技术的发展和迅速普及,网站越来越多,并且每天互联网上的网页数目以千万级别增加,想要在海量的数据资源寻找需要的材料,无异于大海捞针。为了满足人们的搜索需求,搜索引擎应运而生。搜索引擎是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,并将用户检索相关的信息展示给用户的系统。目前大多数搜索引擎均是全网搜索,信息嘈杂不堪,甚至被大量广告所充斥。站内搜索引擎可针对用户关注的网站进行站内全局搜索,大大的提高了信息的相关性。
对于站内搜索引擎的建立,目前的工作量和技术点主要在自然语言处理技术方面和输出结果相关性排序方面,对网页内容的分词方式主要有:1、基于词典的分词算法,基于词典的分词往往依赖于词典和规则库,然而随着互联网的发展,频繁出现新的词汇,导致该方法无法有效的进行分词。2、基于统计的机器学习算法,这种方法不受待处理文本领域的限制,不需要专门的词典,但是需要大量的训练文本,且对常用词的识别精度较差。
由于这些方式单独并不具备完整性,存在差异和缺点,导致实际分词结果往往差强人意,导致搜索引擎搜索出的结果并不是用户想要的数据,或者搜索结果中包含太多的无用信息。由于互联网上的信息太过嘈杂,传销诈骗越来越来,为了提高用户对可靠信息的辨识度,故提出一种具备网站传销行为分析的站内搜索引擎,描述了一种更为可靠的搜索引擎。
技术实现要素:
针对于上述现有技术的不足,本发明的目的在于提供一种站内搜索系统及方法,以解决现有网页内容的分词方式不具备完整性,实际分词结果往往差强人意,导致搜索引擎搜索出的结果并不是用户想要的数据,或者搜索结果中包含太多的无用信息的问题。
为达到上述目的,本发明采用的技术方案如下:
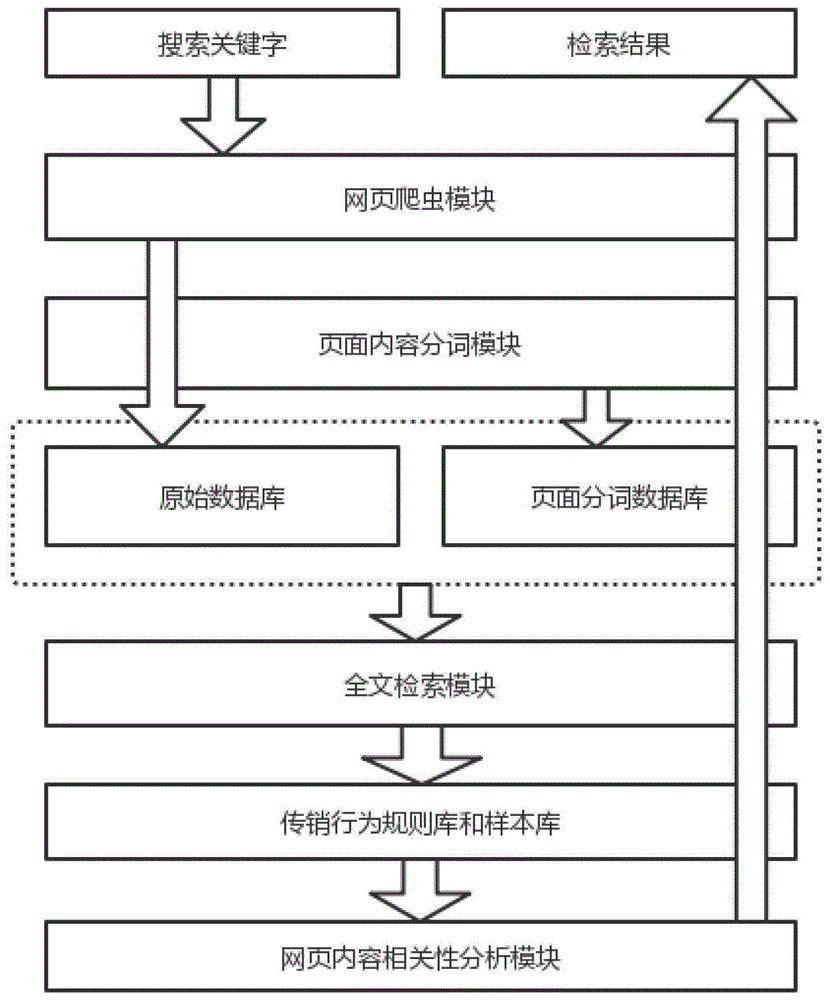
本发明的一种站内搜索系统,包括:
网页爬虫模块,用于获取页面内容,并对页面内容进行数据清洗及页面去重;
页面内容分词模块,用于对上述获取的处理后的页面内容进行分词操作;
网页数据库,其包含原始数据库和页面分词数据库;其中,原始数据库由网页爬虫模块不断获取网页数据来维护,以确保原始数据库保持最新状态;页面分词数据库为由页面内容分词模块对原始数据库中网页内容进行分词操作所维护的数据库;
全文检索模块,用于对原始数据库和页面分词数据库建立索引,以完成查询和输出结果;
传销行为规则库和样本库,包含网络上已公布的传销相关新闻数据和利用该新闻数据分析生成的传销行为的特征规则数据,用于用户检索结果页面的传销行为检测;
网页内容相关性分析模块,对全文检索得出的结果与用户查询关键字进行权重计算页面内容相关性,对输出结果进行重新排序。
进一步地,所述网页爬虫模块采用分布式爬虫系统,结合广度优先遍历算法,获取页面内容。
进一步地,所述全文检索模块包含建立索引和搜索两部分,具体如下:
建立索引:
(1)通过网页爬虫模块获取一系列被索引文件;
(2)被索引文件经过语法分析和语言处理形成一系列词;
(3)经过索引创建形成词典和反向索引表;
(4)通过索引存储将索引写入磁盘;
搜索:
(a)传入查询语句;
(b)对查询语句经过语法分析和语言分析得到一系列词;
(c)通过语法分析得到一个查询树;
(d)通过索引存储将索引读入到内存;
(e)利用查询树搜索索引,从而得到每个词的文档链表,对文档链表进行交、差、并操作得到结果文档;
(f)将搜索到的结果文档对查询相关性进行排序;
(g)返回查询结果给用户。
进一步地,所述网页爬虫模块包含爬虫控制器、任务调度器、过滤器和爬虫监控模块;
爬虫控制器:用于实现爬虫根据种子链接对网络资源抓取的深度、广度以及抓取优先级的策略控制;
任务调度器:用于提高爬虫抓取网络资源的效率和速度,网页爬虫模块采用分布式部署,需要利用任务调度器对爬虫任务的做负载均衡、并行抓取的操作;
过滤器:用于对网络中的无用信息和重复内容,进行过滤,提高资源空间的利用率,以及搜索引擎的运行速度;
爬虫监控模块:用于确保爬虫的高效率的运行,实时监控整个爬虫模块的运行异常的问题,提高整个系统运行的可靠性。
进一步地,所述页面内容分词模块采用条件随机场算法(conditionalrandomfield,crf)对网页内容进行分词操作。
进一步地,所述条件随机场算法具体为:
设有k1个转移特征,有k2个状态特征,k=k1+k2;
式中,转移特征tk是定义在边上的特征函数,依赖于当前位置i和前一个位置i-1;状态特征sl是定义在节点上的特征函数,依赖于当前位置i;l为1至k2个状态特征;x为观测序列,y为状态序列;
对所有在位置i的特征求和:
用wk表示特征fk(y,x)的权值,即:
λk为转移特征tk的权值,μl为状态特征sl的权值;
条件随机场表示为:
式中,p(y|x)为条件随机场,z(x)为规范化因子,是对y的所有可能取值求和。
进一步地,所述网页内容相关性分析模块采用bm25f算法对全文检索得出的结果与用户查询关键字进行权重计算页面内容相关性,对输出结果进行重新排序。
进一步地,所述bm25f算法具体为:
其中,bu表示各个域的长度情况,fiu表示第i单词在各个域中
式中,r表示相关文档的数量,n为文档总数量,di=1表示文档中出现的单词,qi为用户查询的单词,ri为相关文档中出现单词的数量,ni为所有文档中出现单词的数量,k1为经验参数。
本发明可以有效地在互联网上进行信息资料的检索工作,更重要的是能够通过自然语言技术的处理和传销行为规则的研判的介入行为,自动调整分析结果,标识数据来源的可靠性,最终输出最符合用户心中期望的查询结果。适用于诸如工商、公安、市场监管等多种业务基于信息或情报作决策的行业。
如:质疑某些网站存在隐含的传销行为,可使用该搜索引擎,对其站内全搜索,并进行传销行为分析,可快速得出结果;根据报警描述快速对某个网站或论坛进行信息检索和追踪;快速对某个市场主体进行网上舆论调查等。
本发明的一种站内搜索方法,包括步骤如下:
1)输入查询关键词;
2)对关键词进行分词操作;
3)根据关键词的分词结果,抓取相应的网络资源;
4)对爬虫抓取的网络资源进行分词操作,并入库;
5)对新入库数据建立索引,并根据关键词分词结果进行检索;
6)根据全文检索返回的查询结果,结合传销行为规则库和样本库,分析返回结果中的传销行为;
7)对输出结果进行重新排序,提高匹配精确度。
一种计算机可读存储介质,其存储有计算机程序,该程序被处理器执行时实现方法:
1)输入查询关键词;
2)对关键词进行分词操作;
3)根据关键词的分词结果,抓取相应的网络资源;
4)对爬虫抓取的网络资源进行分词操作,并入库;
5)对新入库数据建立索引,并根据关键词分词结果进行检索;
6)根据全文检索返回的查询结果,结合传销行为规则库和样本库,分析返回结果中的传销行为;
7)对输出结果进行重新排序,提高匹配精确度。
本发明的有益效果:
1、精度较高内容检索:crf算法对汉字进行标注即由字构成词(组词),不仅考虑了文字词语出现的频率信息,同时考虑上下文语境,具备较好的学习能力,因此其对歧义词和未登录词的识别都具有良好的效果。
2、可靠性较高的结果排序:与传统的排序算法不同,bm25f算法在对网页进行排序时具有强大的优势,在计算相关性时候,会对文档分割成不同的域来进行加权统计,非常适用于网页搜索,因为在一个网页有标题信息、meta信息、页面内容信息等,而标题信息无疑是最重要的,其次是meta信息,最后才是网页内容,bm25f在计算相关性的,会将网页分为不用的区域,在各个区域分别统计自己的词频。
3、传销行为的识别能力:可以对网站或网页内容进行传销行为分析,提高用户体验。
附图说明
图1为本发明的技术框架图。
图2为全文索引的原理图。
图3为crf算法图模型结构图。
图4为搜索引擎的工作方法。
具体实施方式
为了便于本领域技术人员的理解,下面结合实施例与附图对本发明作进一步的说明,实施方式提及的内容并非对本发明的限定。
广度优先遍历(breadthfirstsearch),广度优先遍历是从根节点开始,沿着树的宽度遍历树的节点,如果所有节点均被访问,则算法终止。是站内搜索引擎的重要环节。
crf(conditionalrandomfield),条件随机场,代表了新一代的机器学习技术分词,其基本思路是对汉字进行标注即由字构词(组词),不仅考虑了文字词语出现的频率信息,同时考虑上下文语境,具备较好的学习能力,因此其对歧义词和未登录词的识别都具有良好的效果。在给定x的条件下,如果每个随机变量yv服从马尔可夫性,即:p(yv|x,yw,w≠v)=p(yv|x,yw,w~v);
bm25f,bm25f是典型bm25的改进算法;bm25在计算相关性时把文档当做总体来考虑,但随着搜索技术的发展。文档慢慢的被结构化数据所取代。每个文档都会被切分成多个独立的域,尤其是垂直化的搜索。比如网页有可能被切分成标题,内容,主题词等域,这些域对文章主题的贡献不能同等对待,所以权重就要有所偏重。bm25没有考虑这点。所以bm25f在此基础上做了一些改进,就是不再单单的将单词作为个体考虑,并且将文档也依照field划分为个体考虑,所以bm25f是每一个单词在各个field中分值的加权求和。
参照图1所示,本发明的一种站内搜索系统,包括:
网页爬虫模块,用于获取页面内容,并对页面内容进行数据清洗及页面去重;
页面内容分词模块,用于对上述获取的处理后的页面内容进行分词操作;
网页数据库,其包含原始数据库和页面分词数据库;其中,原始数据库由网页爬虫模块不断获取网页数据来维护,以确保原始数据库保持最新状态;页面分词数据库为由页面内容分词模块对原始数据库中网页内容进行分词操作所维护的数据库;
全文检索模块,用于对原始数据库和页面分词数据库建立索引,以完成查询和输出结果;
传销行为规则库和样本库,包含网络上已公布的传销相关新闻数据和利用该新闻数据分析生成的传销行为的特征规则数据,用于用户检索结果页面的传销行为检测;
网页内容相关性分析模块,对全文检索得出的结果与用户查询关键字进行权重计算页面内容相关性,对输出结果进行重新排序。
所述网页爬虫模块采用分布式爬虫系统,结合广度优先遍历算法,获取页面内容。
所述全文检索模块包含建立索引(1)-(4)和搜索(a)-(g)两部分,具体如下:
建立索引:
(1)通过网页爬虫模块获取一系列被索引文件;
(2)被索引文件经过语法分析和语言处理形成一系列词;
(3)经过索引创建形成词典和反向索引表;
(4)通过索引存储将索引写入磁盘;
搜索:
(a)传入查询语句;
(b)对查询语句经过语法分析和语言分析得到一系列词;
(c)通过语法分析得到一个查询树;
(d)通过索引存储将索引读入到内存;
(e)利用查询树搜索索引,从而得到每个词的文档链表,对文档链表进行交、差、并操作得到结果文档;
(f)将搜索到的结果文档对查询相关性进行排序;
(g)返回查询结果给用户。
所述网页爬虫模块包含爬虫控制器、任务调度器、过滤器和爬虫监控模块;
爬虫控制器:用于实现爬虫根据种子链接对网络资源抓取的深度、广度以及抓取优先级的策略控制;
任务调度器:用于提高爬虫抓取网络资源的效率和速度,网页爬虫模块采用分布式部署,需要利用任务调度器对爬虫任务的做负载均衡、并行抓取的操作;
过滤器:用于对网络内容充斥大量的无用信息和重复内容,进行过滤,提高资源空间的利用率,以及搜索引擎的运行速度;
爬虫监控模块:用于确保爬虫的高效率的运行,实时监控整个爬虫模块的运行异常的问题,提高整个系统运行的可靠性。
参照图3所示,所述页面内容分词模块采用条件随机场算法(conditionalrandomfield,crf)对网页内容进行分词操作。crf是判别模型以条件概率建模,可以使用任意的权重将对数hmm模型看做crf时,特征函数的权重由于是形式的概率,所以都是小于等于0的,而且概率还要满足相应的限制,但在crf中,每个特征函数的权重可以是任意值,没有这些限制。crf的基本思想是对汉字进行标注即由字构成词(组词),不仅考虑了文字词语出现的频率信息,同时考虑上下文语境,具备较好的学习能力,因此其对歧义词和未登录词的识别都具有良好的效果。
所述条件随机场算法具体为:
在给定随机变量x的条件下,随机变量y的马尔科夫随机场;
设有k1个转移特征,有k2个状态特征,k=k1+k2;
式中,转移特征tk是定义在边上的特征函数,依赖于当前位置i和前一个位置i-1;状态特征sl是定义在节点上的特征函数,依赖于当前位置i;l为1至k2个状态特征;x为观测序列,y为状态序列。
对所有在位置i的特征求和:
用wk表示特征fk(y,x)的权值,即:
λk为转移特征tk的权值,μl为状态特征sl的权值;
条件随机场表示为:
式中,p(y|x)为条件随机场,z(x)为规范化因子,是对y的所有可能取值求和。
其中,所述网页内容相关性分析模块采用bm25f算法对全文检索得出的结果与用户查询关键字进行权重计算页面内容相关性,对输出结果进行重新排序。
其中,参照图2所示,所述bm25f算法具体为:
其中,bu表示各个域的长度情况,fiu表示第i单词在各个域中
式中,r表示相关文档的数量,n为文档总数量,di=1表示文档中出现的单词,qi为用户查询的单词,ri为相关文档中出现单词的数量,ni为所有文档中出现单词的数量,k1为经验参数。
搜索引擎依赖于全文检索建立的快速索引机制,结合crf算法提高索引的准确度,并根据bm25f算法对网页内容相关性计算,重新排序搜索结果顺序,提高用户体验。
本发明可以有效地在互联网上进行信息资料的检索工作,更重要的是能够通过自然语言技术的处理和传销行为规则的研判的介入行为,自动调整分析结果,标识数据来源的可靠性,最终输出最符合用户心中期望的查询结果。适用于诸如工商、公安、市场监管等多种业务基于信息或情报作决策的行业。
如:质疑某些网站存在隐含的传销行为,可使用该搜索引擎,对其站内全搜索,并进行传销行为分析,可快速得出结果;根据报警描述快速对某个网站或论坛进行信息检索和追踪;快速对某个市场主体进行网上舆论调查等。
参照图4所示,本发明的一种站内搜索方法,包括步骤如下:
1)输入查询关键词;
2)对关键词进行分词操作;
3)根据关键词的分词结果,利用网页爬虫模块,抓取相应的网络资源;
4)利用页面内容分词模块对爬虫抓取的网络资源进行分词操作,并入库;
5)利用全文检索模块对新入库数据建立索引,并根据关键词分词结果进行检索;
6)根据全文检索返回的查询结果,结合传销行为规则库和样本库,分析返回结果中的传销行为;
7)利用网页内容相关性分析模块对输出结果进行重新排序,提高匹配精确度。
一种计算机可读存储介质,其存储有计算机程序,该程序被处理器执行时实现方法:
1)输入查询关键词;
2)对关键词进行分词操作;
3)根据关键词的分词结果,抓取相应的网络资源;
4)对爬虫抓取的网络资源进行分词操作,并入库;
5)对新入库数据建立索引,并根据关键词分词结果进行检索;
6)根据全文检索返回的查询结果,结合传销行为规则库和样本库,分析返回结果中的传销行为;
7)对输出结果进行重新排序,提高匹配精确度。
本发明具体应用途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以作出若干改进,这些改进也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!