一种基于Stacking算法的非节假日负荷预测方法与流程
本发明涉及一种基于stacking算法的非节假日负荷预测方法,属于大数据应用、计算机应用、电力系统及其自动化技术领域。
背景技术:
非节假日负荷预测指的是一般工作日、休息日(区别于重大节假日)的日负荷曲线的预测,属于短期负荷预测。短期负荷由于受天气变化、社会活动和节日类型等各种因素的影响,在时间序列上表现为非平稳的随机过程,但是影响系统负荷的各因素中大部分具有规律性,从而为实现有效的预测奠定了基础。目前用于短期负荷预测的方法很多,可以分为经典预测方法、传统预测方法、智能预测方法和组合预测方法等。
经典预测方法主要有回归分析法、时间序列法。回归分法的优点是计算原理和结构形式简单,预测速度快,外推性能好,但是不足的是结构形式过于简单,精度较低。时间序列方法优点是所需数据少,工作量小、计算速度较快,反映负荷近期变化的连续性,但是不足的是对原始时间序列的平稳性要求较高,只适用于负荷变化比较均匀的短期预测,并且没有考虑影响负荷变化的因素,预测误差较大。
传统预测方法主要有负荷求导法、相似日法、卡尔曼滤波法、指数平滑法、灰色预测法。负荷求导法原理清楚,便于理解和应用,但是负荷求导法要求电力负荷的变化率具有稳定性和规律性,并且预测误差有累计效应。相似日法原理简单、应用简便,但是建立合适的评价函数找到相似日比较困难。卡尔曼滤波法在实际应用中难以估计出噪音的统计特性。指数平滑法只对某个单一指标进行预测,方法简单,但是很难反映当今经济、政治和天气等条件因素的影响。灰色系统理论可以应用于任何非线性变化的负荷预测,而不需要考虑特征因素,但是不足之处是要求负荷变化具有指数变化趋势,当不满足要求时预测精度非常差。
智能预测方法主要有专家系统法、模糊预测法、小波分析方法和机器学习方法。专家系统法的优点是可以避免繁杂的数值运算,且具有优越的扩展性能,不足是需要利用高质量的专业知识来对其训练,针对性明显,数学转化能力差。模糊预测法可以描述广泛存在的不确定性,同时具有强大的非线性映射能力,但是单纯的模糊方法由于缺乏学习能力,对于负荷预测精度往往不尽如人意。小波分析方法通过选择合适的小波,对不同性质的负荷进行分类,从而可以针对某种性质的负荷,根据其规律采用相应的预测方法,对分解出的序列分别进行预测,再将预测得到的序列进行重构,得到负荷的预测结果,但是由于重构可能造成误差的累加,因此对各小波系数序列的预测精度要求较高,这也增加了模型的复杂性。
随着短期电力负荷预测技术的发展,对短期电力负荷影响因素考虑的愈发全面,并且影响因素与负荷之间的关系并非简单的线性关系,使得传统和经典的预测方法表现很大的劣势,并且大样本数据的处理对传统和经典的预测方法也是巨大的挑战,而一些机器学习算法凭借其强大的学习能力和自适应能力表现出卓越性能。应用机器学习算法进行负荷预测的实质先假设一个模型,然后通过学习求解使损失函数最小的模型参数,常用的机器学习算法有人工神经网络法、支持向量机法、随机森林、梯度提升决策树(gbdt)、岭回归等,这些方法在电力负荷预测的精度提升上有着显著的表现。
综上所述均为单一负荷预测方法,实际上单一算法总有各自的缺点,可以通过组合预测方法扬长避短。组合预测方法通过加权把不同的算法结合起来,共同完成预测,降低单一算法的敏感度,从而提高负荷预测精度,但是传统的组合预测方法只是获得一个固定权重的线性组合,没有自学习能力和非线性表达能力。
技术实现要素:
本发明要解决的技术问题是,克服现有技术的缺陷,提供一种拥有良好的自学习能力和非线性表达能力,能够提升预测精度和扩大使用范围的基于stacking算法的非节假日负荷预测方法。
为解决上述技术问题,本发明采用的技术方案为:
一种基于stacking算法的非节假日负荷预测方法,包括以下步骤:
s1、获取样本数据,包括电力系统用户短期负荷数据、气象数据和时间因素;
s2、对s1获得的样本数据,做数据预处理,包括缺失值处理和标准化处理;
s3、使用stacking算法对s2已经处理好的样本数据进行负荷预测建模;
s4、使用s3已经建好的模型对待预测点进行负荷预测;
s5、使用平均绝对误差比率和准确度来评估该负荷预测模型的性能。
s1中,获得的样本数据为:{(x1,y1),(x2,y2),…,(xn,yn)},其中xi是第i个特征向量,yi是第i个负荷数据,n代表样本数据的个数,待预测点的特征数据为{xn+1,xn+2,...,xn+m},m代表特征数据的个数,xi=[xi1,xi2,...,xi10],xi1,xi2,...,xi10分别为日最高温度、日平均温度、日最低温度、日降雨量、日相对湿度、日风速、日气象类型、月份类型、日期类型和时刻类型。
s2中使用的缺失值处理方法为:利用分段线性插值方法进行缺失值填充,在每个时间区间[ti,ti+1]上,用1阶多项式逼近
f(t):
s3中具体包括以下步骤:
s31、将样本数据分为训练集train和测试集dev,待预测点的待预测输入集记为test,将训练集t随机分成5折:train1,train2,train3,train4,train5;
s32、建立初级学习器,得到次级学习器的输入,使用的初级学习器有:bp神经网络算法、随机森林算法、gbdt算法、支持向量机算法和岭回归算法,使用的次级学习器为:bp神经网络算法;
s33、使用新的训练集train训练次级学习器bp神经网络算法,得到最终的负荷预测模型m,并且得到训练集准确度,将测试集的数据dev代入模型m得到测试集的预测负荷。
s32具体包括如下步骤:
s321、首先建立初级模型:bp神经网络,
1)使用train2,train3,train4,train5组成的样本数据训练bp神经网络模型m11,用此模型测试train1,得到train1的预测负荷向量p11,用此模型m11测试测试集dev得到dev的预测负荷向量s11,再用此模型m11预测待预测输入集test得到待预测点的预测结果q11;
2)使用train1,train3,train4,train5组成的样本数据训练bp神经网络模型m12,用此模型测试train2,得到train2的预测负荷向量p12,用此模型m12测试测试集dev得到dev的预测负荷向量s12,再用此模型m12预测待预测输入集test得到待预测点的预测结果q12;
3)使用train1,train2,train4,train5组成的样本数据训练bp神经网络模型m13,用此模型测试train3,得到train3的预测负荷向量p13,用此模型m13测试测试集dev得到dev的预测负荷向量s13,再用此模型m13预测待预测输入集test得到待预测点的预测结果q13;
4)使用train1,train2,train3,train5组成的样本数据训练bp神经网络模型m14,用此模型测试train4,得到train4的预测负荷向量p14,用此模型m14测试测试集dev得到dev的预测负荷向量s14,再用此模型m14预测待预测输入集test得到待预测点的预测结果q14;
5)使用train1,train2,train3,train4组成的样本数据训练bp神经网络模型m15,用此模型测试train5,得到train5的预测负荷向量p15,用此模型m15测试测试集dev得到dev的预测负荷向量s15,再用此模型m15预测待预测输入集test得到待预测点的预测结果q15;
6)合并p11、p12、p13、p14和p15,得到p1,平均s11、s12、s13、s14和s15得到s1,平均q11、q12、q13、q14和q15,得到q1;
s3.2.2、同理,可以训练随机森林模型得到p2、s2和q2,训练gbdt模型得到p3、s3和q3,训练支持向量机模型得到p4、s4和q4,训练岭回归模型得到p5、s5和q5;
s323、以p1、p2、p3、p4和p5组成5维的特征矩阵p,仍以原来的负荷数据作为预测目标,新的训练集仍记为train,以s1、s2、s3、s4和s5组成新的测试集的特征矩阵s,仍以原来的负荷数据作为预测目标,新的测试集仍记为dev,以q1、q2、q3、q4和q5组成待预测点的特征输入向量仍记为test。
s4中方法是将待预测点的输入数据test代入模型m得到待预测点的负荷。
s5中使用的平均绝对误差比率公式为:
本发明的有益效果:本发明提供一种基于stacking算法的非节假日负荷预测方法,采用集中预测精度较高的机器学习算法作为初级学习器,一方面弥补了传统预测方法在预测精度和使用范围上有着明显的不足,另一方面提升了对影响负荷的特征因素的提取能力;并且本发明使用新的组合预测方法:stacking集成方法,利用五种单一机器学习模型:人工神经网络法、支持向量机法、随机森林、梯度提升决策树(gbdt)、岭回归,将他们的预测结果作为输入,训练一个次级学习器bp神经网络算法,预测电力系统非节假日负荷曲线,克服了单一模型由于存在某些方面不足而难以取得良好预测效果的难题,另外,新的组合预测方法相比传统组合预测方法,拥有良好的自学习能力和非线性表达能力,进一步提升预测精度和扩大使用范围。
附图说明
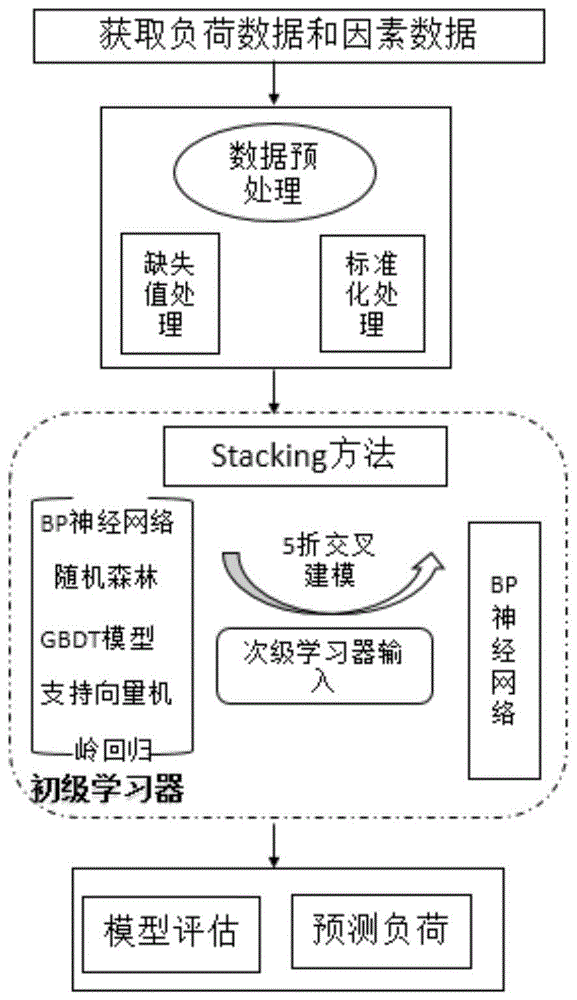
图1为本发明一种基于stacking算法的非节假日负荷预测方法的流程图。
具体实施方式
下面结合附图对本发明作进一步描述,以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
stacking模型融合方法首先训练多个不同的初级学习器,然后把之前训练的各个模型的输出作为一个新的输入来训练一个次级学习器,得到最终模型的输出。stacking模型融合算法的具体流程如下:在训练阶段,直接使用初级学习器的训练样本来训练产生次级训练样本的过拟合风险较大,因此需要进行改进,具体实践中一般采用k折交叉验证或者留一法来产生次级训练样本。本文以k折交叉验证为例来做简要叙述,初始训练集d被随机划分为k个大小相似的集合{d1,d2,...dk},令dj和
如图1所示,本发明提供一种基于stacking算法的非节假日负荷预测方法,一种基于stacking算法的非节假日负荷预测方法,包括以下步骤:
步骤一、获取样本数据,包括电力系统用户短期负荷数据(96点日负荷曲线数据)、气象数据和时间因素。获得的样本数据为:{(x1,y1),(x2,y2),…,(xn,yn)},其中xi是第i个特征向量,yi是第i个负荷数据,n代表样本数据的个数,待预测点的特征数据为{xn+1,xn+2,...,xn+m},m代表特征数据的个数,xi=[xi1,xi2,...,xi10],xi1,xi2,...,xi10分别为日最高温度、日平均温度、日最低温度、日降雨量、日相对湿度、日风速、日气象类型、月份类型、日期类型和时刻类型。
步骤二、对步骤一获得的样本数据,做数据预处理,包括缺失值处理和标准化处理。其中,使用的缺失值处理方法为:利用分段线性插值方法进行缺失值填充,在每个时间区间[ti,ti+1]上,用1阶多项式(直线)逼近f(t):
步骤三、使用stacking算法对步骤二已经处理好的样本数据进行负荷预测建模,具体包括以下步骤:
s31、将样本数据分为训练集train和测试集dev,待预测点的待预测输入集记为test,将训练集t随机分成5折:train1,train2,train3,train4,train5;
s32、建立初级学习器,得到次级学习器的输入,使用的初级学习器有:bp神经网络算法、随机森林算法、gbdt算法、支持向量机算法和岭回归算法,使用的次级学习器为:bp神经网络算法,具体包括如下步骤:
s321、首先建立初级模型:bp神经网络,
1)使用train2,train3,train4,train5组成的样本数据训练bp神经网络模型m11,用此模型测试train1,得到train1的预测负荷向量p11,用此模型m11测试测试集dev得到dev的预测负荷向量s11,再用此模型m11预测待预测输入集test得到待预测点的预测结果q11;
2)使用train1,train3,train4,train5组成的样本数据训练bp神经网络模型m12,用此模型测试train2,得到train2的预测负荷向量p12,用此模型m12测试测试集dev得到dev的预测负荷向量s12,再用此模型m12预测待预测输入集test得到待预测点的预测结果q12;
3)使用train1,train2,train4,train5组成的样本数据训练bp神经网络模型m13,用此模型测试train3,得到train3的预测负荷向量p13,用此模型m13测试测试集dev得到dev的预测负荷向量s13,再用此模型m13预测待预测输入集test得到待预测点的预测结果q13;
4)使用train1,train2,train3,train5组成的样本数据训练bp神经网络模型m14,用此模型测试train4,得到train4的预测负荷向量p14,用此模型m14测试测试集dev得到dev的预测负荷向量s14,再用此模型m14预测待预测输入集test得到待预测点的预测结果q14;
5)使用train1,train2,train3,train4组成的样本数据训练bp神经网络模型m15,用此模型测试train5,得到train5的预测负荷向量p15,用此模型m15测试测试集dev得到dev的预测负荷向量s15,再用此模型m15预测待预测输入集test得到待预测点的预测结果q15;
6)合并p11、p12、p13、p14和p15,得到p1,平均s11、s12、s13、s14和s15得到s1,平均q11、q12、q13、q14和q15,得到q1;
s3.2.2、同理,可以训练随机森林模型得到p2、s2和q2,训练gbdt模型得到p3、s3和q3,训练支持向量机模型得到p4、s4和q4,训练岭回归模型得到p5、s5和q5;
s323、以p1、p2、p3、p4和p5组成5维的特征矩阵p,仍以原来的负荷数据作为预测目标,新的训练集仍记为train,以s1、s2、s3、s4和s5组成新的测试集的特征矩阵s,仍以原来的负荷数据作为预测目标,新的测试集仍记为dev,以q1、q2、q3、q4和q5组成待预测点的特征输入向量仍记为test。
s33、使用新的训练集train训练次级学习器bp神经网络算法,得到最终的负荷预测模型m,并且得到训练集准确度,将测试集的数据dev代入模型m得到测试集的预测负荷。
步骤四、使用步骤三已经建好的模型对待预测点进行负荷预测;s4中方法是将待预测点的输入数据test代入模型m得到待预测点的负荷。
步骤五、使用平均绝对误差比率和准确度来评估该负荷预测模型的性能,使用的平均绝对误差比率公式为:
本发明采用某省2018年历史统调负荷数据,对原始数据进行数据清洗、数据规范化等特征处理后,使用本产品进行训练和预测,为了比较需要,同时使用传统模型和单一的机器学习模型进行训练和预测,得到下面的表1的非节假日负荷预测结果评估。
结果表明:进行非节假日负荷预测时,当样本量较大时,单个机器学习模型的性能是高于传统负荷预测方法的,而stacking方法的性能较单个机器学习模型有明显的提升。本发明对负荷预测做了一段时间的跟踪,得到了待预测点的真实负荷,通过误差计算,得到五个传统模型的准确率为:93.75%、94.21%、94.58%、93.72%、92.91%,五个机器学习模型的准确率为:95.22%、95.38%、95.46%、94.91%、96.18%,而stacking方法的准确率为:97.13%,准确率得到了显著提高,再次验证了stacking方法的性能优于各单一模型的性能。因此,本产品选择stacking方法预测非节假日负荷,经过实践检验是有应用价值的。
表1
本发明采用集中预测精度较高的机器学习算法作为初级学习器,一方面弥补了传统预测方法在预测精度和使用范围上有着明显的不足,另一方面提升了对影响负荷的特征因素的提取能力;并且本发明使用新的组合预测方法:stacking集成方法,克服了单一模型由于存在某些方面不足而难以取得良好预测效果的难题,另外,新的组合预测方法相比传统组合预测方法,拥有良好的自学习能力和非线性表达能力,进一步提升预测精度和扩大使用范围。
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!