电信网络告警预测方法及系统与流程
本发明涉及一种电信网络告警预测方法及系统。
背景技术:
随着电信网络规模的不断扩大,每天由电信设备故障产生的告警也越来越多,而且一个设备的故障经常会导致另一个设备的故障,从而给维护人员带来很大的麻烦。70年代有人提出利用专家知识建立告警关联规则库来处理电信网络产生的告警,但时至今日,这种依赖专家知识的告警关联工具显然不能很好地应付越来越复杂的网络结构。
由于近年来数据挖掘技术的发展,很多行业都开始使用这项技术来处理各自的业务,并取得了令人瞩目的效果,通信行业也不例外。在告警关联方面,运营商开始尝试使用数据挖掘技术对以往积累的大量告警历史信息进行分析,但复杂的业务逻辑和巨大的数据量给他们带来了很大的挑战。
目前电信网络中的告警关联规则一般是通过专家基于积累的相关经验进行总结提炼,然后讨论决定的。这种人工提取规则的方法,存在效率低、不完整、依赖性强等特点,无法很好适应当前复杂的电信网络结构。
已经有一些使用数据挖掘技术进行告警关联的案例,比较经典的算法是winepi。winepi通过设置固定的时间窗口宽度来提取告警序列,并发现告警在时间上的偏序关系。但由于告警序列通常是一组不均匀的数据,往往在一个短的时间段内密集产生,之后一段时间就恢复平静。且不同时间段内产生的告警事件频率、持续时间也各不相同,如果使用固定的时间窗口宽度来提取告警事务则可能存在很多无效的数据,导致最终提取的关联规则无效。
技术实现要素:
有鉴于此,有必要提供一种电信网络告警预测方法及系统。
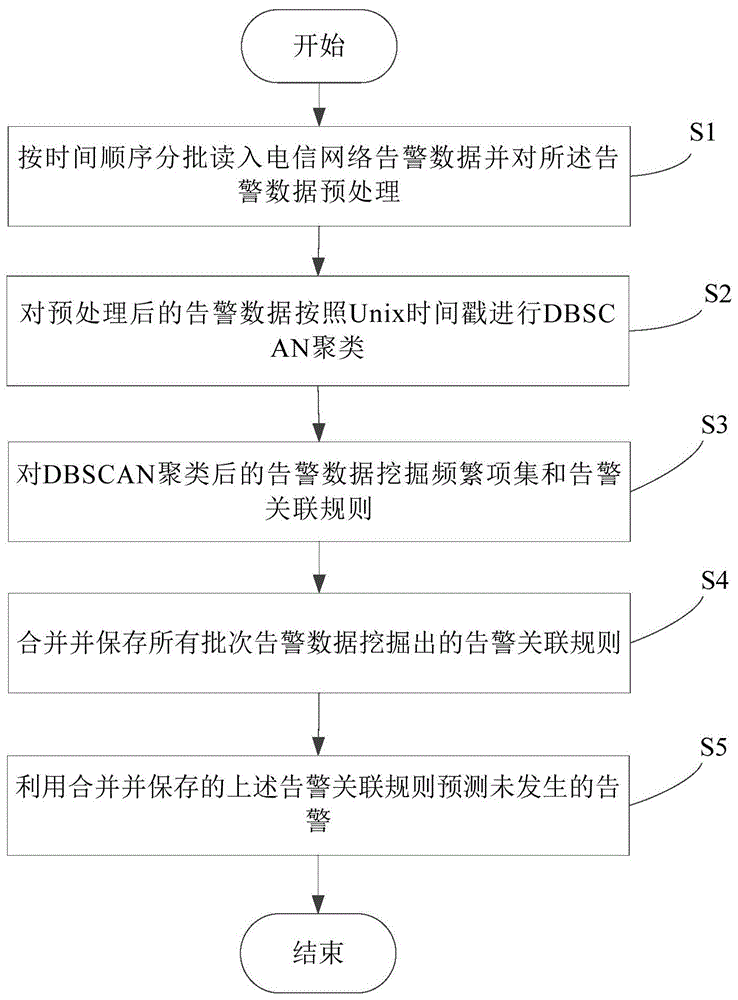
本发明提供一种电信网络告警预测方法,该方法包括如下步骤:a.按时间顺序分批读入电信网络告警数据并对所述告警数据预处理;b.对预处理后的告警数据按照unix时间戳进行dbscan聚类;c.对dbscan聚类后的告警数据挖掘频繁项集和告警关联规则;d.合并并保存所有批次告警数据挖掘出的告警关联规则;e.利用合并并保存的上述告警关联规则预测未发生的告警。
其中,所述的步骤a具体包括:
步骤a1,读取告警记录,对每一条告警记录提取相应特征信息;
步骤a2,检查该条告警故障原因是否存在故障表中,如是,则进入步骤a3;如否,则丢弃并返回步骤a1;
步骤a3,检查数据库中该告警的告警类型字段是否属于“告警清除”类型,如是,丢弃并返回步骤a1;如否,进入步骤a4;
步骤a4,检查内存中是否存在网元、故障原因、故障类型均相同,且故障发生时间绝对值之差小于给定阈值的告警记录,如是,则丢弃并返回步骤a1;如否,进入步骤a5;
步骤a5,将该告警添加进内存;
重复步骤a1到步骤a5,直至该批告警数据全部被处理完。
所述的步骤a1具体包括:
从数据库中读取告警记录,对每一条告警记录提取相应特征信息,组成以下数据格式:{网元、故障原因、故障类型、故障发生时间}。
所述的步骤b具体包括如下步骤:
步骤b1,将告警数据格式中的发生时间字符串转换成unix时间戳;
步骤b2,使用dbscan算法处理时间列数据;
步骤b3,使用轮廓系数评价聚类效果;
步骤b4,将聚类得出的簇标签结果添加到告警数据的最后一列:{网元、故障原因、故障类型、故障发生时间,簇类别};
步骤b5,对事务中的告警按照时间顺序排序,并且去掉重复告警。
所述重复告警指:网元、故障原因、故障类型都相同的告警。
所述的步骤c具体包括如下步骤:
步骤c1,设定最小支持度阈值min_sup,扫描所有聚类后得到的告警事务,对每个项进行计数,剔除出现小于min_sup的项集,得到频繁1-项集,记为l1;
步骤c2,对l1进行迭代,生成候选2-项集,对候选2-项集进行剪枝处理得到c2;
步骤c3,对c2进行支持度计数,将小于min_sup的项集剔除,得到l2;
步骤c4,重复步骤c2和步骤c3,生成l3,l4…lk,直至lk+1为空;
步骤c5,设定最小置信度阈值min_conf,输出提升度大于1的强关联规则;
步骤c6,使用步骤c1到步骤c5的方法,分别单独挖掘告警中网元、故障原因的关联规则。
所述的步骤d具体包括如下步骤:
步骤d1,将第一批告警数据挖掘出的规则读进内存,格式为:{前件,后件,conf,samples};
步骤d2,读进下一批告警数据挖掘出的规则,逐条对比规则是否存在内存当中,若否则添加;若已存在,则更新内存中该规则的conf及samples:
步骤d3,重复步骤d2直至所有规则合并完成,将规则保存为可读写文件。
所述的步骤e具体包括如下步骤:
步骤e1,读取存放规则的文件,将其转换为键值对;
步骤e2,按照时间顺序读入当前发生的告警,判断该告警与上一条读进的告警发生时间之差是否小于规定的阈值,如是,则进入步骤e3;如否,执行步骤e5;
步骤e3,将该告警添加到告警集合中,遍历上述键值对规则表,检查规则表中是否存在一行数据属于当前告警集合的子集,若是,执行步骤e4;若不是,继续执行步骤e2,扩大告警集合;
步骤e4,输出该规则的后件和概率并清空告警集合;
步骤e5,查找单独的属性关联规则表,判断是否存在当前网元和故
障各自对应的后件,若有,进入步骤e6;若无,进入步骤e7;
步骤e6,记其置信度为p1和p2,将网元和故障所对应的后件组合成预测告警,并输出概率p=p1*p2;
步骤e7,预测无故障发生;
清空告警集合,重复步骤e2到步骤e7,继续预测新的告警。
所述的键值对表示为,键为前件,值为后件及置信度:{key:前件,value:[后件,conf]}。
本发明提出了一种电信网络告警预测方案,通过这种方案能实现动态的时间窗口宽度,从而能很好地处理具有突发性特点的告警数据;对于提取出的告警事务数据库,采用apriori算法进行关联规则挖掘;最后通过规则匹配和多维属性概率相乘的方法预测告警。本发明使用时间聚类提高了关联规则的有效性,采用分批处理的思路提高了处理大批量数据的能力,并给出了一种预测告警的方案。
附图说明
图1为本发明电信网络告警预测方法的流程图;
图2为本发明实施例步骤s1对所述告警数据预处理的流程图;
图3为本发明实施例步骤s2对预处理后的告警数据按照unix时间戳进行dbscan聚类的流程图;
图4为本发明实施例步骤s3对dbscan聚类后的告警数据挖掘频繁项集和告警关联规则的流程图;
图5为本发明实施例步骤s4合并并保存所有批次告警数据挖掘出的告警关联规则的流程图;
图6为本发明实施例步骤s5利用合并并保存的上述告警关联规则预测未发生的告警的流程图。
具体实施方式
下面结合附图及具体实施例对本发明作进一步详细的说明。
参阅图1所示,是本发明电信网络告警预测方法较佳实施例的作业流程图。
步骤s1,按时间顺序分批读入电信网络告警数据并对所述告警数据预处理。具体而言,请一并参阅图2:
步骤s11,从数据库中读取若干条告警记录,对每一条告警记录提取相应特征信息,组成以下数据格式:{网元、故障原因、故障类型、故障发生时间}。
步骤s12,检查该条告警故障原因是否存在故障表中,如是进入步骤s13;如否说明该告警可能是记录出错的脏数据,丢弃并回到步骤s11。
步骤s13,检查数据库中该告警的告警类型字段是否属于“告警清除”类型,如是,丢弃并回到步骤s11;如否,进入步骤s14。
步骤s14,检查内存中是否存在网元、故障原因、故障类型均相同,且故障发生时间绝对值之差小于给定阈值的告警记录,如是,说明该告警是重复告警,丢弃并回到步骤s11;如否,进入步骤s15。
步骤s15,将该告警添加进内存。
重复步骤s11到步骤s15,直至该批告警数据全部被处理完。
步骤s2,对预处理后的告警数据按照unix时间戳进行dbscan聚类。具体而言,请一并参阅图3:
步骤s21,将告警数据格式中的发生时间字符串转换成unix时间戳,并将时间列数据单独提取出来。
步骤s22,使用dbscan算法处理时间列数据,算法的参数eps需要调节,min_samples设为2,评价标准使用曼哈顿距离(manhattandistance):distance(ai-aj)=|ti-tj|,其中ti、tj分别代表告警ai,aj发生的时间。
步骤s23,使用轮廓系数(silhouettecoefficient)来评价聚类效果的好坏,对于样本i,轮廓系数的定义如下:
步骤s24,将聚类得出的簇标签结果添加到告警数据的最后一列:{网元、故障原因、故障类型、故障发生时间,簇类别},根据所在类别划分告警事务,同一个类别的告警属于同一事务。
步骤s25,对事务中的告警按照时间顺序排序,并且去掉重复告警。其中所述重复告警指:网元、故障原因、故障类型都相同的告警。
步骤s3,对dbscan聚类后的告警数据挖掘频繁项集和告警关联规则。具体而言,请一并参阅图4:
步骤s31,设定最小支持度阈值min_sup,扫描所有聚类后得到的告警事务,对每个项进行计数,剔除出现小于min_sup的项集,得到频繁1-项集,记为l1。
步骤s32,对l1进行迭代,生成候选2-项集。根据apriori的前提假设:如果一个项集是非频繁集,那么它的所有超集也是非频繁的,因此需要对候选2-项集进行剪枝处理,即剪掉候选2-项集中包含的不频繁1-项集,得到c2。
步骤s33,对c2进行支持度计数,将小于min_sup的项集剔除,得到l2。
步骤s34,重复步骤s32和步骤s33,生成l3,l4…lk,直至lk+1为空。
步骤s35,设定最小置信度阈值min_conf,输出提升度大于1的强关联规则。提升度的计算方式如下:
步骤s36,使用步骤s31到步骤s35的方法,分别单独挖掘告警中网元、故障原因的关联规则。
步骤s4,合并并保存所有批次告警数据挖掘出的告警关联规则。具体而言,请一并参阅图5:
步骤s41,将第一批告警数据挖掘出的规则读进内存,格式为:{前件,后件,conf,samples}。
步骤s42,读进下一批告警数据挖掘出的规则,逐条对比规则是否存在内存当中,若否则添加;若已存在,则更新内存中该规则的conf及samples:
步骤s43,重复步骤s42直至所有规则合并完成,将规则保存为可读写文件。
步骤s5:利用合并并保存的上述告警关联规则预测未发生的告警。具体包括,请一并参阅图6:
步骤s51,读取存放规则的文件,将其转换为键值对,键为前件,值为后件及置信度:{key:前件,value:[后件,conf]}。
步骤s52,按照时间顺序读入当前发生的告警,判断该告警与上一条读进的告警发生时间之差是否小于规定的阈值min_time,如是,则进入步骤s53;如否,执行步骤s55。
步骤s53,将该告警添加到告警集合中,遍历上述键值对规则表,检查规则表中是否存在一行数据属于当前告警集合的子集,若是,执行步骤s54;若不是,继续执行步骤s52,扩大告警集合。
步骤s54,输出该规则的后件和概率并清空告警集合。
步骤s55,查找单独的属性关联规则表(即网元→网元,故障→故障),判断是否存在当前网元和故障各自对应的后件,若有,进入步骤s56;若无,进入步骤s57。
步骤s56,记其置信度为p1和p2,将网元和故障所对应的后件组合成预测告警,并输出概率p=p1*p2。
步骤s57,预测无故障发生。
清空告警集合,重复步骤s52到步骤s57,继续预测新的告警。
虽然本发明参照当前的较佳实施方式进行了描述,但本领域的技术人员应能理解,上述较佳实施方式仅用来说明本发明,并非用来限定本发明的保护范围,任何在本发明的精神和原则范围之内,所做的任何修饰、等效替换、改进等,均应包含在本发明的权利保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!