一种跨模态图文检索方法与流程
本发明涉及跨模态图文检索领域,具体涉及一种基于栈式跨模态自编码器的跨模态图文检索方法。
背景技术:
在大数据时代,海量的多模态数据具有数据类型多样化、数据储量大以及大部分为无标签数据等特点,对于不同模态的数据其含有各自独有的信息,但同时不同模态信息间在某个语义层次上存在较强的关联。如何跨越不同模态数据之间的“异构鸿沟”,构建不同模态数据的共享表示,并提高检索的精确度,是跨模态检索领域的重要技术问题。
技术实现要素:
本发明提供一种基于栈式跨模态自编码器的跨模态图文检索方法,其主要目的是提高跨模态图文检索的精确度。首先,对图像和文本数据进行预处理,得到图像特征和文本特征,再通过两层受限玻尔兹曼机,提取单模态表示;其次,通过构建深层次的栈式跨模态自编码器,挖掘模态间的相关性;最终,训练模型并得到模型文件,在验证集上完成跨模态图文检索任务。本发明在实现了图文检索中常用的两种检索任务(以图检文和以文检图)的基础上,还能实现输入一种模态数据返回多种模态数据,在三个跨模态图文检索数据集上提升了模型检索精确度和泛化能力。
本发明的技术方案主要包括以下步骤:
(1)给定原始跨模态图文检索数据集,其中包括图像和文本两种模态数据,分为训练集、验证集以及测试集。
(2)构建基于栈式跨模态自编码器的图文检索模型:模型第一层选用gaussianrbm和replicatedsoftmaxrbm提取输入的图像数据和文本数据的特征表示,并约减图像特征维度和文本特征维度,进行利用对比散度算法对第一层rbm进行训练,并更新权重参数;将模型第一层输出的单模态特征表示用于第二层输入,模型第二层选用两个原始rbm加深网络的深度,学习深层次的单模态表示,进一步约减不同模态的特征维度到512维;在所述图文检索模型的关联学习阶段,首先,构建包含图像文本对和单模态输入的扩增数据集,作为模型的输入;其次,在自编码器隐藏层之间引入关联误差函数学习模态间的关联信息,使得模型可以更好地建模不同模态间的语义相关性;最终,在训练过程中,采用layer-wise训练策略,通过分层逐步训练跨模态自编码器提升模型的学习能力,从而提升模型的表征能力。
(3)对图片数据和文本数据进行预处理,提取各自的单模态特征表示:利用跨模态数据集中训练集对深度卷积神经网络vgg-16模型进行微调,更新模型参数,并采用交叉验证的方式得到最优模型;利用微调后的所述深度卷积神经网络vgg-16模型提取图像数据的单模态特征表示,将fc7层作为网络的输出,得到4096维的图像特征表示向量。
(4)通过所述4096维的图像特征和文本数据的词袋特征作为所述图文检索模型关联学习阶段的输入,训练模型,并提取图像和文本的最终表示;通过相似性度量函数对图像数据和文本数据间的共享表示计算距离;对获得的结果依照距离从小到大排列,最终得到的排序结果即是跨模态检索结果。
附图说明
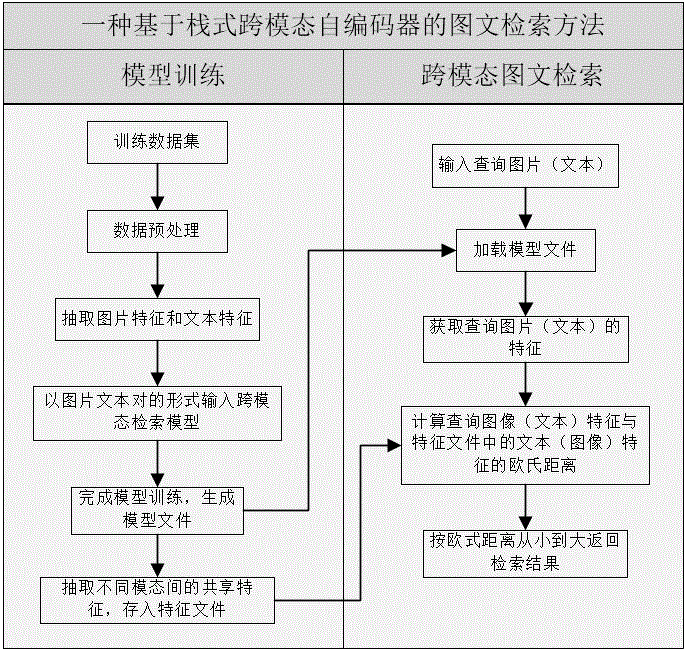
图1为本发明的图文检索流程图。
具体实施方式
下面着重详细地描述本发明的技术方案和技术效果。
一.基于栈式跨模态自编码器的图文检索方法主要包括如下步骤:
(1)给定原始跨模态图文检索数据集,其中包括图像和文本两种模态数据,分为训练集、验证集以及测试集。
(2)对图片数据和文本数据进行预处理,提取各自的单模态特征表示。
(3)利用深度学习工具包deepnet构建基于栈式跨模态自编码器的图文检索模型(stacked-cae);在第一个学习阶段,分别使用两层rbm提取图像和文本特征;第二个学习阶段,采用栈式跨模态自编码器,学习不同模态间的共享表示。
(4)将图文检索数据集中训练集和验证集载入构建的stacked-cae模型中进行训练和验证,并生成相应的模型文件。
(5)调用训练好的模型文件提取测试集中图像和文本的共享表示,完成以图检文和以文检图两种图文检索任务,得到检索结果,评估该模型的泛化能力及检索精确度,并实现输入一种模态数据返回多种模态数据的检索结果。
其中上述步骤(2)中所述的提取单模态特征表示的主要步骤如下:
(1)采用在跨模态数据集上微调的深度卷积神经网络vgg-16模型,提取图片特征表示。
(2)采用词袋模型提取文本特征表示。
二.利用深度卷积神经网络vgg-16模型提取图片特征表示,包括如下步骤:
(1)构建vgg-16网络结构,使用vgg-16网络在imagenet上的预训练权重,初始化模型权重。
(2)利用跨模态数据集中训练集对模型进行微调,并更新模型参数,并采用交叉验证的方式得到最优模型。
(3)利用微调后的模型提取图像数据的单模态特征表示,将fc7层作为网络的输出,得到4096维的图像特征表示向量。
(4)通过vgg-16网络得到4096维的图像特征和文本数据的词袋特征作为图文检索模型(stacked-cae)关联学习阶段的输入,训练模型,并提取图像和文本的最终表示。
(5)通过相似性度量函数对图像数据和文本数据间的共享表示计算距离。
(6)对获得的结果依照距离从小到大排列,图像和文本数据之间越相关,距离越接近,最终得到的排序结果,即是跨模态检索结果。
三.构建基于栈式跨模态自编码器的图文检索模型的结构具体包括以下步骤:
(1)模型的第一层选用gaussianrbm和replicatedsoftmaxrbm提取输入的图像数据和文本数据的特征表示,并约减图像特征维度和文本特征维度,进行利用对比散度(cd)算法对第一层rbm进行训练,并更新权重参数;
(2)将第一层输出的单模态特征表示用于第二层输入,模型第二层选用两个原始rbm加深网络的深度,学习深层次的单模态表示,进一步约减不同模态的特征维度到512维;
(3)在模型的关联学习阶段,本发明提出栈式跨模态自编码器学习模态间的关联关系,首先,构建包含图像文本对和单模态输入的扩增数据集,作为模型的输入;其次,在自编码器隐藏层之间引入关联误差函数学习模态间的关联信息,使得模型可以更好地建模不同模态间的语义相关性;最终,在训练过程中,采用layer-wise训练策略,通过分层逐步训练跨模态自编码器提升了模型的学习能力,从而提升模型的表征能力。
四.本发明的最终检索维度为64维,在以文检图和以图检文两个检索任务上,本发明提供的stacked-cae模型与其他已公开的模型相比,在这三个数据集(训练集、验证集和测试集)上的准确率有显著提升,由于nus-wide-10k数据集的量级最大,所以本发明提供的模型在此数据集上提升最为显著。在三个跨模态图文检索领域数据集上,本发明所提供的模型与已公开的效果最好的模型相比,两种检索任务上性能指标map的平均值分别从0.311、0.297和0.247增加到0.351、0.383和0.284。
以两阶段模型cca为基准,在wikipedia、pascal和nus-wide-10k数据集上,本发明所提供的模型在以图检文任务上的map值分别提高54.9%、87.4%和75.2%;同样在三个数据集上,本发明所提供的模型分别将以文检图任务的map值提高58.3%、46.2%和86.3%。模型在三个不同量级、分布和数据的跨模态检索数据集上检索精度都得到了提升,证明了本发明所提供的模型具有较好的泛化能力。
- 还没有人留言评论。精彩留言会获得点赞!