一种基于模型迁移的工业数据分类方法与流程
本专利申请属于机器视觉中工业产品表面缺陷检测技术领域,更具体地说,是涉及一种基于模型迁移的工业数据分类方法,也涉及机器学习和深度学习、数据增强、领域自适应、基于模型迁移的工业缺陷检测分类领域。
背景技术:
产品表面缺陷检测是工业制造生产线中极为重要的一个环节,企业每年会投入高昂的费用招聘工人使用人眼进行产品缺陷检测,如焊接缺陷中表面裂纹、表面气孔、咬边、焊瘤等缺陷,这些带缺陷的产品需要准确的被判别出来类别,但实际生产环境中,大多都是通过人工检测的方式,由于通过肉眼检测的方式不仅具有极大的漏检率和误捡率,而且速度较慢,对企业的正常生产运营留下潜在风险,对企业发展质量和效益影响至关重要。
基于机器学习的传统缺陷检测方法,如决策树、支持向量机(svm,supportvectormachine)、最邻近节点算法(knn,k-nearestneighbor)等。例如在jp特开平5-340731号公报(文献1)以及jp特开平8-220013号公报(文献2)中公开有一种检测方法,取得形成有布线图案的基板的多灰度图像,通过对使该多灰度图二值化的二值图像和预先准备的正常基板的二值图像进行比较,从而检测缺陷,又如中国专利cn103808730a中使用图像梯度信息的概率hough变换方法进而对图像去噪,对缺陷区域聚类判定缺陷类型。也有企业使用卷积神经网络通过大量数据的训练对目标进行分类;如中国专利cn108364281a中一种基于卷积神经网络的织带边缘毛疵缺陷检测方法,其采用的技术方案是:a、图像采集及预处理得到样本图片b、对样本进行图像增强得到训练图片,将样本图分为边缘有毛疵缺陷和无毛疵缺陷的样本图,作为训练样本c、构建具有多尺度并行训练结构的卷积神经网络d、进行训练e、利用训练好的网络进行毛疵缺陷检测。
但目前这些方法应用场景单一,不具有通用性,检测算法无法快速迭代,并且需要满足1.训练数据与测试数据分布一致,即产品批次相同,拍摄环境相同;2.训练样本要足够多,但对于每种产品都进行大量数据采集过于劳民伤财。
现有技术所检测的目标样本训练集数量要求过高,每次会消耗过多时间采集大量数据;缺陷分类只能分出有无毛疵,结果较为单一;使用的数据集与检测样本属于同分布的训练集,不具备泛化能力,无法快速复制算法,如果在不同环境或时间使用同一个训练模型预测结果也不尽如人意。
迁移学习是运用已有(源域)知识,对不同但相关领域(目标域)问题进行求解的一种机器学习方法,是一种可以有效解决传统机器学习以上两个问题的方法,其优势在于可以迁移已有的知识来解决目标域中仅有的少量有标签样本数据的学习问题。但迁移学习方法在工业产品各类缺陷检测领域上应用较少。
技术实现要素:
本发明需要解决的技术问题是提供一种基于模型迁移的工业数据分类方法,以解决背景技术中提到的问题。
为了解决上述问题,本发明所采用的技术方案是:
一种基于模型迁移的工业数据分类方法,包括如下步骤(以焊接缺陷为例):
步骤a:收集工业界中不同种类产品的大量焊接缺陷数据集a作为源域数据集,并将他们按焊接缺陷种类分好放入不同文件夹并编号(如:1-表面裂纹2-表面气孔3-咬边4-焊瘤);
步骤b:收集少量待检测产品(几百张)的待分类缺陷数据,作为目标域数据;
步骤c:对源域数据进行数据增强,扩增训练集,增加数据特征密度,避免出现过拟合;
步骤d:构建具有残差结构的卷积神经网络;
步骤e:建立损失函数,以最小化跨域的学习特征协方差的差异,在特征层面通过对齐源域数据和目标域数据分布的二阶统计量来最小化域位移;
步骤f:对模型进行训练;
步骤g:对模型进行预测。
本发明技术方案的进一步改进在于:步骤a中,焊接缺陷种类包括表面裂纹、表面气孔、咬边、焊瘤。
本发明技术方案的进一步改进在于:步骤c中,对源域数据进行数据增强,扩增训练集,是指在源域数据读取过程中进行数据增强,数据增强方式包括:关键点变换、图像缩放、截取填充块、水平镜面翻转、上下翻转、改变图像空间、高斯扰动、灰度处理、最近邻像素中取均值扰动、最近邻中位数扰动、卷积、锐化、浮雕、随机加值、高斯噪声、亮度、随机去掉像素点、像素值翻转、对比度、仿射变换、局部扭曲、移动局部像素的一种或多种。
本发明技术方案的进一步改进在于:步骤d中,构建具有残差结构的卷积神经网络,包括以下步骤:
d1:第一组卷积的输入大小是224x224,构建卷积核为7x7、步长为2的卷积层conv1,之后进行批量标准化bn(batchnormalization)、池化层relu操作,再使用3x3的最大池化层maxpool,步长为2,64通道;
d2:第二层conv2_x使用卷积核为3x3,步长为2的残差结构两次,64通道;
d3:第三层conv3_x使用3x3的卷积核,步长为2的残差结构两次,输出大小28x28x128;
d4:第四层conv4_x使用3x3的卷积核,步长为2的残差结构两次,输出大小14x14x256;
d5:第五层conv5_x使用3x3的卷积核,步长为2的残差结构两次,输出大小为7x7x512;
d6:最终全连接层输出要输出的类别数量,得到的残差网络结构见下表:
本发明技术方案的进一步改进在于:步骤e中,建立损失函数,以最小化跨域的学习特征协方差的差异,包括以下步骤:
e1:将源域数据记为ds={xi},x∈rd,源域标签为:ls={yi},i∈{1,...,l};
e2:将未标记的目标域数据记为dt={ui},u∈rd;
e3:源域数据和目标域数据的数量分别用ns和nt表示,用
e4:将coral损失函数定义为源域数据与目标域数据的二阶统计量之间的距离,公式记为:
其中,lcoral代表coralloss,
e5:源域数据的协方差矩阵为:
e6:目标域数据的协方差矩阵为:
e7:使用以下链式梯度对输入要素进行计算:
e8:使用批处理协方差,网络参数在两个网络之间共享;
e9:建立分类损失函数,采用交叉熵计算网络输出与源域标签的损失;
e10:最终的深层特征需要具有足够的判别力来训练强分类器并且对源域数据和目标域数据之间的差异保持不变,最小化分类损失可能会导致过拟合到源域数据,从而降低目标域的性能,最小化二阶统计量损失函数可能导致特征退化,例如,网络可以将所有源数据和目标数据投影到单个点,使coral损失平均为零,但无法在这些特征上构建强分类器,所以采用分类损失和coral损失的联合训练来使网络学习的特征更好的作用在目标域数据上,公式如下:
其中l表示总损失函数,lclass表示类别损失,t表示深度网络中的coral损失层的数量,λ是用于平衡分类准确度和域适应的一个参数,使lclass和lcoral都不要太大,也可以根据训练情况调节λ,比如经过一定步数后开始增大λ,或者设定一定的比例渐进增长,寻找到最好的预测效果。
由于采用了上述技术方案,本发明取得的有益效果是:由于在工业领域新产品研发阶段,无法有大量的工业数据集供神经网络进行学习,本方法将其他产品型号的类似工业数据集进行训练,在训练的特征层面对少量的目标域数据进行学习特征迁移,作用在目标域上,即在目标数据很少、数据难获取的情况下使用其它相似数据进行学习进行特征迁移进而对目标域进行分类。
本方法以工业焊接表面缺陷检测为例,在工业焊接装配生产线中,使用此算法代替了人工用肉眼判别缺陷,解决了对于采集大量新数据时间、人员消耗的问题,应用了迁移学习的领域自适应方法将其它产品焊接缺陷数据和少量待检测产品缺陷作为数据集,使用深度学习网络进行学习,使机器学会‘举一反三’,在学习到的特征层面进行迁移,进而直接预测待检测焊缝的缺陷,大大减少了企业人力和财力的损失,一定程度上加快了生产周期,有极佳的实用意义。
附图说明
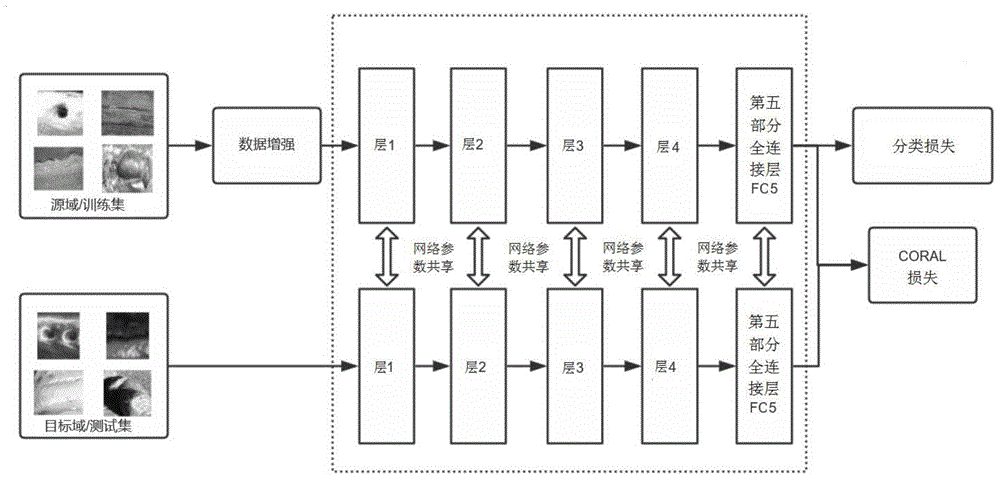
图1为本发明的操作示意图;
图2为本发明步骤d所使用的残差结构图;
图3为本发明与不进行特征迁移的效果对比图。
具体实施方式
下面结合实施例对本发明做进一步详细说明。
本发明公开了一种基于模型迁移的工业数据分类方法,包括如下步骤(以焊接缺陷为例):
步骤a:收集工业界中不同种类产品的大量焊接缺陷数据集a作为源域数据集,并将他们按焊接缺陷种类分好放入不同文件夹并编号(如:1-表面裂纹2-表面气孔3-咬边4-焊瘤);
步骤b:收集少量待检测产品(几百张)的待分类缺陷数据,作为目标域数据;
步骤c:对源域数据进行数据增强,扩增训练集,增加数据特征密度,避免出现过拟合;
步骤d:构建具有残差结构的卷积神经网络;
步骤e:建立损失函数,以最小化跨域的学习特征协方差的差异,在特征层面通过对齐源域数据和目标域数据分布的二阶统计量来最小化域位移;
步骤f:对模型进行训练;
步骤g:对模型进行预测。
在步骤a中,焊接缺陷种类包括表面裂纹、表面气孔、咬边、焊瘤。
在步骤c中,对源域数据进行数据增强,扩增训练集,是指在源域数据读取过程中进行数据增强,数据增强方式包括:关键点变换、图像缩放、截取填充块、水平镜面翻转、上下翻转、改变图像空间、高斯扰动、灰度处理、最近邻像素中取均值扰动、最近邻中位数扰动、卷积、锐化、浮雕、随机加值、高斯噪声、亮度、随机去掉像素点、像素值翻转、对比度、仿射变换、局部扭曲、移动局部像素的一种或多种。
在步骤d中,构建具有残差结构的卷积神经网络,包括以下步骤:
d1:第一组卷积的输入大小是224x224,构建卷积核为7x7、步长为2的卷积层conv1,之后进行批量标准化bn(batchnormalization)、池化层relu操作,再使用3x3的最大池化层maxpool,步长为2,64通道;
d2:第二层conv2_x使用卷积核为3x3,步长为2的残差结构两次,64通道;
d3:第三层conv3_x使用3x3的卷积核,步长为2的残差结构两次,输出大小28x28x128;
d4:第四层conv4_x使用3x3的卷积核,步长为2的残差结构两次,输出大小14x14x256;
d5:第五层conv5_x使用3x3的卷积核,步长为2的残差结构两次,输出大小为7x7x512;
d6:最终全连接层输出要输出的类别数量,如图2所示,当输入数据x通过带有权重参数的卷积层weightlayer-池化层relu操作后,也就是经过一层网络后产生的结果设为f(x),将其与经过跳跃层identity后的原始输入数据x相加,就有输出h(x)=f(x)+x。与传统cnn的输出h(x)=f(x)相比,残差网络是将卷积输出f(x)与输入x相加,相当于对输入x计算了一个微小变化,这样得到的输出h(x)就是x与变化的叠加。
这样,经过梯度传播后,现在传到前一层的梯度就多了一个x的梯度,假设为“1”!正是由于多了这条捷径,来自深层的梯度能直接畅通无阻地通过,去到上一层,使得浅层的网络层参数等到有效的训练
得到的残差网络结构见下表:
在步骤e中,建立损失函数,以最小化跨域的学习特征协方差的差异,包括以下步骤:
e1:将源域数据记为ds={xi},x∈rd,源域标签为:ls={yi},i∈{1,...,l};
e2:将未标记的目标域数据记为dt={ui},u∈rd;
e3:源域数据和目标域数据的数量分别用ns和nt表示,用
e4:将coral损失函数定义为源域数据与目标域数据的二阶统计量之间的距离,公式记为:
其中,lcoral代表coralloss,
e5:源域数据的协方差矩阵为:
e6:目标域数据的协方差矩阵为:
e7:使用以下链式梯度对输入要素进行计算:
e8:使用批处理协方差,网络参数在两个网络之间共享;
e9:建立分类损失函数,采用交叉熵计算网络输出与源域标签的损失;
e10:最终的深层特征需要具有足够的判别力来训练强分类器并且对源域数据和目标域数据之间的差异保持不变,最小化分类损失可能会导致过拟合到源域数据,从而降低目标域的性能,最小化二阶统计量损失函数可能导致特征退化,例如,网络可以将所有源数据和目标数据投影到单个点,使coral损失平均为零,但无法在这些特征上构建强分类器,所以采用分类损失和coral损失的联合训练来使网络学习的特征更好的作用在目标域数据上,公式如下:
其中l表示总损失函数,lclass表示类别损失,t表示深度网络中的coral损失层的数量,λ是用于平衡分类准确度和域适应的一个参数,使lclass和lcoral都不要太大,也可以根据训练情况调节λ,比如经过一定步数后开始增大λ,或者设定一定的比例渐进增长,寻找到最好的预测效果。
本方法使用的数据是工业中最常需要检测的4类缺陷:表面裂纹、表面气孔、咬边、焊瘤。使用时参见图1,源域数据(训练集)经过数据增强、目标域数据(测试集)通过构建具有残差结构的卷积神经网络,过程中各层之间进行分享share,然后建立损失函数classficationloss和coralloss(即分类损失和coral损失),接着对模型进行训练和预测,可以输出结果。
图1中,在源域数据中准备好与目标域数据种类相似的数据集并分好类别,放入两个文件夹内,目标域数据为少量带标签样本。源域数据在网络训练过程中会不断进行数据增强,增加源域数据集样本,在训练过程中使用adam优化器(对梯度的一阶和二阶矩估计综合考虑的一种梯度优化方法)对具有残差结构的卷积神经网络进行梯度优化,进行图1中两个loss(即分类损失和coral损失)的联合训练,其中更新的参数在训练和预测的网络上是共享的。在训练过程中调节损失函数中的λ参数以达到最好的分类效果,比如可以通过测试曲线甄别。当达到满意分类效果后,可以保存并固化模型进行目标域的测试。
结果如图3所示:上面的曲线是使用各类产品上的不同种类缺陷进行学习进而特征迁移到少量目标数据集的预测结果,下面的曲线是不进行特征迁移,直接将以往训练集进行训练,直接对其它类别相似目标集进行预测,可以看出进行迁移后准确率提升了4个百分点,效果明显。
- 还没有人留言评论。精彩留言会获得点赞!