一种基于GIS和免疫算法的最大覆盖双层选址优化方法与流程
本发明涉及一种地理信息数据处理技术、计算机技术、地理学、物联网技术、网络分析和管理科学与工程技术,尤其涉及一种基于gis和免疫算法的最大覆盖双层选址优化方法。
背景技术:
近年来,物流运输产业得到了巨大的发展,而物流技术本身也在不断发展。以现代信息技术、自动化技术、运输技术和管理技术为核心的技术创新与应用,建立了一套快捷的、低成本、高安全的现代物流系统。然而,物流运输系统中,物流中心连接着配送中心和客户点。配送中心的选址不仅影响到配送中心自身的运营成本、运营绩效、竞争战略和未来的发展,还影响到物流中心客户点的物流成本,甚至影响到区域经济发展。
现代选址研究起于1909年,当时alfredweber为解决如何为单个仓库选址使得仓库到多个顾客间的总距离最小的问题,他在欧氏空间里建立了一个1-中位问题模型,就是著名的weber问题。基本选址问题包括p-中位问题、p-中心问题、覆盖问题等。在三个基本选址问题的基础上考虑其他因素就形成了扩展选址问题,一般有固定费用或容量限制的选址问题、截流问题、hub选址问题、选址-分配问题、随机选址问题、动态选址问题等根据不同实际应用需求组合而成的扩展选址问题。
在选址方法上,国内外研究学者提出了很多方法。一些方法在计算上都以两点间的坐标距离来计算运输距离,然而利用两点间的坐标系求得的距离是直线距离,与实际距离相差很大,因此导致选址结果精确性不足;还有一些选址方法例如:模糊评价法、层次分析法、灰色评价法,这些方法主观性较强,会影响实际结果的准确性。
因此,传统的配送中心选址方法存在不足,需要改进。
技术实现要素:
为了解决传统选址方法的不足,本发明提供一种选址效率较高的基于gis的最大覆盖双层选址优化方法,结合了gis技术与免疫算法,考虑了城市道路网的实际分布、物流客户点的实际分布和所选区域的实际物流需求情况。
本发明解决其技术问题所采用的技术方案是:
一种基于gis和免疫算法的最大覆盖双层选址优化方法,包括以下步骤:
1)获取所在城市某个区域的道路网、客户点、待选配送中心点等空间数据,客户点集合i={i1,i2,i3,...in},设待选配送中心点集合j={j1,j2,j3,...jm},将该城市中某个区域道路的路网数据、客户点数据、待选配送中心的数据导入到gis软件中,通过gis软件分析功能得到实际路网中配送中心到客户点的起点-目的地成本矩阵;
2)以所有选定配送中心覆盖客户点的需求量最大和配送中心到客户点之间资源运输的成本最小为目标的目标函数如下:
其中,rij表示配送中心j对客户点i的需求量覆盖比例,qij表示需求点i的需求量,zj为决策变量,如果第j个待选配送中心没有被选中,则取0,反之均取1,cij为配送中心j到客户点i的运输成本,mj为第j个配送中心的库存量;
3)编码:采用二进制0-1编码,染色体长度为候选配送中心的数目m,第i个基因位的值为1表示在第i个点建站,如果第i个点基因位的值为0则表示不在第i点建站;由于基于最大覆盖的选址配送模型对选中的配送中心数目有明确的限制,所以在随机生成的初始染色体中对1的个数量为p;
4)通过步骤1)中的起点-目的地成本矩阵,进一步转化成配送中心到客户点的运输成本cij,按照规定的编码规则随机生成免疫算法中的初始抗体群,将初始抗体群规模设定为n个,免疫操作的交叉概率设定为p1,变异概率设定为p2,最大迭代次数q次,将生成的n个抗体对应的选址结构映射到目标函数式(2)所示的模型中去,对应变量的参数是zj,通过matlab中的linprog()函数进行计算,得到rij;
5)将得到的n个最优值返回到函数式(1)所示的模型中,这个值映射到决策层模型中的参数变量是rij,即得到的n个最优值是在已知配送中心位置和数量的情况下最优的需求量分配;
6)亲和度计算,过程如下:
6.1)为了使得最终的选址方案能够在实际路网的各个需求点上取得最大覆盖度,结合实际路网的网络特征,将抗体与抗原之间的亲和度定义为
6.2)采用海明空间的海明距离表示抗体与抗体之间的亲和力
6.3)计算抗体浓度
7)免疫操作,过程如下:
7.1)选择:采用轮盘赌机制来进行个体的选择,在转轮盘的过程中,具有较大适应度的个体有较大的概率被选择,期望繁殖概率
7.2)交叉:采用单点交叉法进行交叉操作,在染色体编码中只随机挑出一个交叉点,然后在该点交换两个配对父代的染色体;
7.3)变异:采用随机选择变异位的方法进行变异;
8)保留精英:更新记忆库时,先将与抗原亲和度最高的l个个体存入记忆库,再按照期望繁殖概率p将剩余群体中抗体按与抗原的亲和度降序排列,取前h-l个抗体存入记忆库,h为记忆库的大小;
9)输出具有最优亲和度的抗体编码,此时输出的解为运输成本最低客户点需求覆盖率最高的最优选址问题的解,将所得的结果结合gis分析功能得到最终的选址分配方案。
本发明的有益效果主要表现在:本发明结合了gis技术,基于城市道路网的实际分布以及客户点实际分布情况,提出了一种选址精度较高、实用性较强的选址方法。
附图说明
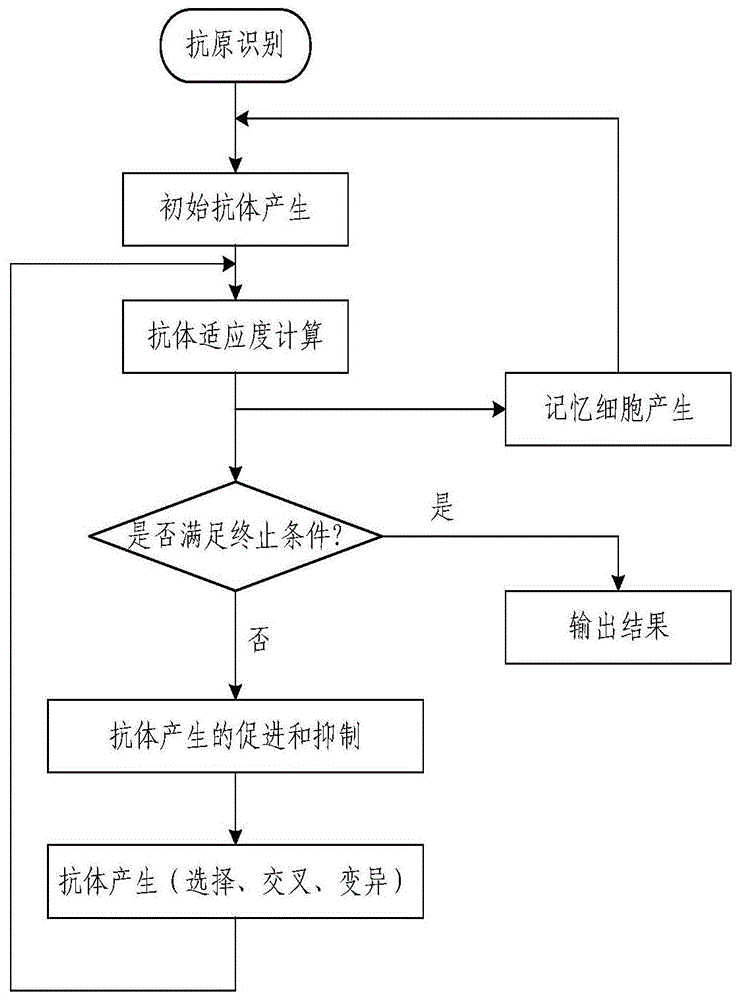
图1是一种基于gis和免疫算法的最大覆盖双层选址优化方法的免疫算法步骤流程图;
图2是区域道路数据、客户点数据、待选配送中心的数据导入到gis软件中生成的数据分布图;
图3是通过gis分析功能获得的选址分配映射图;
图4是通过gis分析功能获得的最优选址分配方案。
具体实施方式
下面结合附图对本发明进一步描述。
参照图1、图2、图3和图4,一种基于gis和免疫算法的最大覆盖双层选址优化方法,包括以下步骤:
1)获取所在城市某个区域的道路网、客户点、待选配送中心点等空间数据,客户点集合i={i1,i2,i3,...in},设待选配送中心点集合j={j1,j2,j3,...jm},将该城市中某个区域道路的路网数据、客户点数据、待选配送中心的数据导入到gis软件中,通过gis软件分析功能得到实际路网中配送中心到客户点的起点-目的地成本矩阵;
2)以所有选定配送中心覆盖客户点的需求量最大和配送中心到客户点之间资源运输的成本最小为目标的目标函数如下:
其中,rij表示配送中心j对客户点i的需求量覆盖比例,qij表示需求点i的需求量,zj为决策变量,如果第j个待选配送中心没有被选中,则取0,反之均取1,cij为配送中心j到客户点i的运输成本,mj为第j个配送中心的库存量;
3)编码:采用二进制0-1编码,染色体长度为候选配送中心的数目m,第i个基因位的值为1表示在第i个点建站,如果第i个点基因位的值为0则表示不在第i点建站;由于基于最大覆盖的选址配送模型对选中的配送中心数目有明确的限制,所以在随机生成的初始染色体中对1的个数量为p;
4)通过步骤1)中的起点-目的地成本矩阵,进一步转化成配送中心到客户点的运输成本cij,按照规定的编码规则随机生成免疫算法中的初始抗体群,将初始抗体群规模设定为n个,免疫操作的交叉概率设定为p1,变异概率设定为p2,最大迭代次数q次,将生成的n个抗体对应的选址结构映射到目标函数式(2)所示的模型中去,对应变量的参数是zj,通过matlab中的linprog()函数进行计算,得到rij;
5)将得到的n个最优值返回到函数式(1)所示的模型中,这个值映射到决策层模型中的参数变量是rij,即得到的n个最优值是在已知配送中心位置和数量的情况下最优的需求量分配;
6)亲和度计算,过程如下:
6.1)为了使得最终的选址方案能够在实际路网的各个需求点上取得最大覆盖度,结合实际路网的网络特征,将抗体与抗原之间的亲和度定义为
6.2)采用海明空间的海明距离表示抗体与抗体之间的亲和力
6.3)计算抗体浓度
7)免疫操作,过程如下:
7.1)选择:采用轮盘赌机制来进行个体的选择,在转轮盘的过程中,具有较大适应度的个体有较大的概率被选择,期望繁殖概率
7.2)交叉:采用单点交叉法进行交叉操作,在染色体编码中只随机挑出一个交叉点,然后在该点交换两个配对父代的染色体;
7.3)变异:采用随机选择变异位的方法进行变异;
8)保留精英:更新记忆库时,先将与抗原亲和度最高的l个个体存入记忆库,再按照期望繁殖概率p将剩余群体中抗体按与抗原的亲和度降序排列,取前h-l个抗体存入记忆库,h为记忆库的大小;
9)输出具有最优亲和度的抗体编码,此时输出的解为运输成本最低客户点需求覆盖率最高的最优选址问题的解,将所得的结果结合gis分析功能得到最终的选址分配方案,最终的分配方案如图4所示。
以杭州市滨江区为例,要从6个候选配送中心选择建立3家物流配送中心,以满足滨江区内40个客户点的配送要求,并且保证资源分配成本最低,覆盖需求量最大。一种基于gis和免疫算法的最大覆盖双层选址优化方法步骤如下:
1)获取所在城市某个区域的道路网、客户点、待选配送中心点等空间数据,客户点集合i={i1,i2,i3,...i40},设待选配送中心点集合j={j1,j2,j3,...j6},将该城市中某个区域道路的路网数据、客户点数据、待选配送中心的数据导入到gis软件中,通过gis软件分析功能得到实际路网中配送中心到客户点的起点-目的地成本矩阵;
2)以所有选定配送中心覆盖客户点的需求量最大和配送中心到客户点之间资源运输的成本最小为目标的目标函数如下:
其中,rij表示配送中心j对客户点i的需求量覆盖比例,qij表示需求点i的需求量,zj为决策变量,如果第j个待选配送中心没有被选中,则取0,反之均取1,cij为配送中心j到客户点i的运输成本,mj为第j个配送中心的库存量;
3)编码:采用二进制0-1编码,染色体长度为候选配送中心的数目m=6,第i个基因位的值为1表示在第i个点建站,如果第i个点基因位的值为0则表示不在第i点建站;由于基于最大覆盖的选址配送模型对选中的配送中心数目有明确的限制,所以在随机生成的初始染色体中对1的个数量为p=3;
4)通过步骤1)中的起点-目的地成本矩阵,进一步转化成配送中心到客户点的运输成本cij,按照规定的编码规则随机生成免疫算法中的初始抗体群,将初始抗体群规模设定为n个,免疫操作的交叉概率设定为p1=0.8,变异概率设定为p2=0.07,最大迭代次数q=120次,将生成的n个抗体对应的选址结构映射到目标函数式(2)所示的模型中去,对应变量的参数是zj,通过matlab中的linprog()函数进行计算,得到rij;
5)将得到的n个最优值返回到函数式(1)所示的模型中,这个值映射到决策层模型中的参数变量是rij,即得到的n个最优值是在已知配送中心位置和数量的情况下最优的需求量分配;
6)亲和度计算,过程如下:
6.1)为了使得最终的选址方案能够在实际路网的各个需求点上取得最大覆盖度,结合实际路网的网络特征,将抗体与抗原之间的亲和度定义为
6.2)采用海明空间的海明距离表示抗体与抗体之间的亲和力
6.3)计算抗体浓度
7)免疫操作,过程如下:
7.1)选择:采用轮盘赌机制来进行个体的选择,在转轮盘的过程中,具有较大适应度的个体有较大的概率被选择,期望繁殖概率
7.2)交叉:采用单点交叉法进行交叉操作,在染色体编码中只随机挑出一个交叉点,然后在该点交换两个配对父代的染色体;
7.3)变异:采用随机选择变异位的方法进行变异;
8)保留精英:更新记忆库时,先将与抗原亲和度最高的l个个体存入记忆库,此处取l=6,再按照期望繁殖概率p将剩余群体中抗体按与抗原的亲和度降序排列,取前h-l个抗体存入记忆库,h为记忆库的大小,此处选h=15;
9)输出具有最优亲和度的抗体编码,此时输出的解为运输成本最低客户点需求覆盖率最高的最优选址问题的解,将所得的结果结合gis分析功能得到最终的选址分配方案。
以上阐述的是本发明给出的一个实施例表现出来的优良效果,显然本发明不仅适合上述实施例,在不偏离本发明基本精神及不超出本发明实质内容所涉及内容的前提下可对其做种种变化加以实施。
- 还没有人留言评论。精彩留言会获得点赞!