一种海明空间近似查询方法及存储介质与流程
本发明涉及数据库近似查询领域,尤其涉及一种海明空间近似查询方法及存储介质。
背景技术:
当前基础数据类型的近似查询是数据库领域中的一个基础问题,比如字符串、集合的近似查询,并且已经研究很多年。然而更为复杂的数据类型的近似查询和近似语义查询在数据库领域还没有得到很好的效果。
由于二进制数据的简约型和易于查询,哈希映射函数和海明近似查询相结合的方案已经在很多应用中起到了关键的作用,比如网页搜索,图片查询,以及科学技术库。
在数以亿计的网页中处理近似检测的问题中,谷歌使用一种simhash的哈希技术作为哈希映射函数把每个网页映射到64维度的二进制向量中。海明近似查询用来找到所有近似匹配的网页。在大规模图片搜索中,深度神经网络模型作为哈希映射函数将图片映射成高维度的二进制向量,而海明近似查询能高效地返回与查询图片相似的图片。在生物医学领域中,海明近似查询可以用来找到相似的分子结构,其中哈希映射函数将分子转换成高维度二进制向量,满足海明阈值的分子被返回。在自然语言近似语义搜索中,神经网络模型,比如自编码器,注意力模型,lstm等,封装成哈希映射函数将文本映射成高维度二进制向量。只有数据库中海明距离较小的记录被返回出来作为结果。
然而,现阶段所有的海明空间近似查询方法主要有以下两个缺点:1.现有的方法基于海明查询的过滤下界不紧,这导致了较大的阈值,直接导致很差的运行效率。2.现有的方法对于数据分割的阈值分配是均匀的。数据被假设是均匀分布的,但是在实际中,数据往往都有些倾斜性。我们发现在实际情况下很多真实数据都有或多或少的倾斜性存在,并且数据中列与列之间存在复杂的关联性。所以均匀阈值分布在很多数据集上并不会取得好的效果,不考虑数据的倾斜性导致了低效的查询性能。
技术实现要素:
本发明的目的在于提供一种海明空间近似查询方法及存储介质,以解决上述缺陷。
为达此目的,本发明采用以下技术方案:
一种海明空间近似查询方法,包括步骤:
将原始数据库中的所有记录和查询数据,映射成海明空间中的哈希二进制向量,得到哈希数据库;
对哈希数据库中的二进制数据进行列重排序;
针对列重排序后新生成的数据建立索引结构,索引结构包含柱状图和倒排哈希索引;
解析查询,为各个数据分割分配相应的查询阈值。
可选的,所述哈希数据库的获得方法为:针对每个记录和查询数据,检测当前数据的类型和结构;按照当前数据的类型和结构,从哈希函数集合中选择相应的哈希映射函数;通过所选择的哈希映射函数,将输入数据映射成哈希二进制向量。
可选的,所述对哈希数据库中的二进制数据进行列重排序的方法为:设计基于列重排序的代价模型;对二进制数据进行初始化列分割;在初始化列分割后,进行近似分割。
可选的,所述对二进制数据进行初始化列分割的方法为:初始化一个空的数据分割,选择一个数据列,如果该数据列对于当前数据分割能产生最小的信息熵,就被放入到当前数据分割中;选择下一数据列,重复进行相同处理,直到当前数据分割的大小达到上限,即产生第一个数据分割;之后,重复分割过程,直到所有的数据列被分配到相应的数据分割中。
可选的,所述进行近似分割的方法为:迭代地把当前近似查询效果差距最大的两个数据列进行交换。
可选的,所述为各个数据分割分配相应的查询阈值的方法为:
设计基于阈值分配的代价模型;
根据基于阈值分配的代价模型,采用动态规划算法进行查询阈值分配。
可选的,所述海明空间近似查询方法还包括:根据索引结构抽取候选集,并逐一验证得到最终结果。
可选的,所述根据索引结构抽取候选集,并逐一验证得到最终结果的方法为:
对于查询的每一个列分割及其对应的被分配的查询阈值,枚举所有可能的哈希数值;对于每个哈希数值,分别去预先建立的倒排索引中查找对应的键值,并抽取出对应的倒排表;当所有的倒排表抽取出来之后,去重并用海明距离公式逐一计算它们与查询的海明距离。如果计算的数值小于或等于给定的阈值,就返回作为其中一个结果。
一种存储介质,所述存储介质上存储有计算机程序,该计算机程序被处理器执行时实现如上任一项所述的海明空间近似查询方法。
与现有技术相比,本发明的有益效果为:
1)本发明实施例能够有效地应对不同倾斜度的数据集都能有着高效地查询能力,尤其是对于倾斜度很大的数据集,比如生物分子数据集,大部分现有的方法都失去了过滤能力,只能对数据集中的数据依次扫描验证,从而得到结果。本发明实施例提出的新型鸽巢原理能够很好地利用数据的倾斜性,根据倾斜度进行阈值分配,从而大量过滤掉非结果的数据。
2)本发明实施例有效地根据数据倾斜性进行阈值分配,用动态规划算法使得候选集最优,从而达到最佳的过滤效果。
3)基于柱状图索引结构的海明近似查询,使得只有和查询有关的数据被抽取出来,从而实现高效查询。
4)根据不同的数据的倾斜度进行维度重新排序,将倾斜度大的数据列放在一起,从而更加有效地利用数据的倾斜度,提高近似查询的效率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
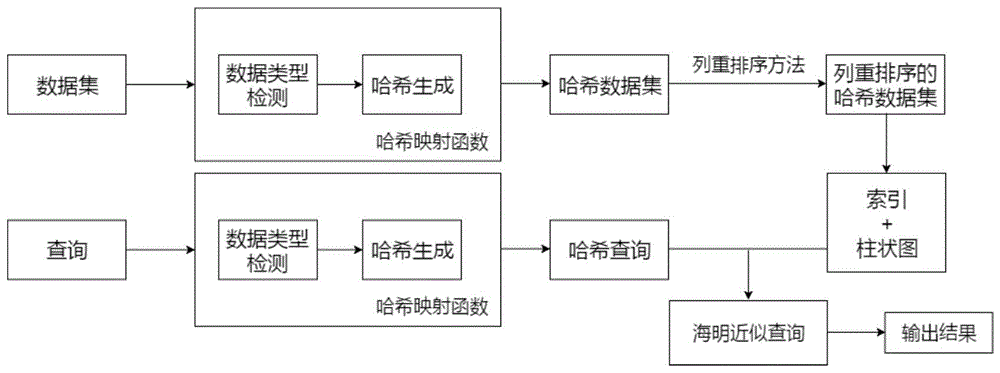
图1为本发明实施例提供的海明近似查询方法逻辑框图。
图2为本发明实施例提供的海明近似查询方法流程图。
具体实施方式
本发明旨在实现多数据类型的近似查询:按照给定的一个查询输入,找到所有数据库中的和查询输入映射在海明距离中的向量小于或等于一个给定阈值的记录。为实现多数据类型的近似查询,本发明分为两大步骤:1.将数据库中数据和查询用给定的映射函数将它们映射到海明空间。2.海明空间下的查询对数据集进行海明近似查询。
为使得本发明的发明目的、特征、优点能够更加的明显和易懂,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,下面所描述的实施例仅仅是本发明一部分实施例,而非全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
本发明实施例提供了一种基于鸽巢原理的海明近似查询方法,请结合图1和图2所示,该方法包括:
步骤10:哈希映射函数。
哈希映射函数实现对任意数据类型映射成哈希二进制向量。该步骤分为两个子步骤:数据类型检测和哈希生成。由于不同数据类型使用不同的哈希映射方法,数据类型检测旨在检测输入数据的类型和结构,从而将它分配给适合它的哈希生成模块。哈希生成模块是一系列哈希函数的集合,比如simhash,minhash,lstm,卷积神经网络模型,自编码器模型等等。它的目的是将输入数据映射到海明空间中的向量。
该步骤10具体包括:步骤101,数据类型检测;步骤102,哈希生成。
哈希映射模块旨在对于数据库中的所有记录和查询数据映射成哈希二进制向量。
步骤20:将哈希数据库中的二进制数据进行列重排序。
为了解决数据的倾斜性和维度之间的关联性,现有的方法都是基于随机排序和减少列聚类的关联性的方法来减少数据的倾斜。他们的目标在于使得每个分割的维度都尽可能均匀分布,这样的话每个分割的阈值分配不会引入大量的候选数据。相比于现有的方法,本发明致力于增大每个列分割的倾斜性,使得海明阈值分配更能发挥效果。
为了实现这个目的,本实施例设计了一个列重排序的代价模型,并且把这个问题转化成一个给予优化查询处理的性能的最优化问题。
步骤201:设计一个基于列重排序的代价模型。
这里预先设计一个查询集q={<q1,τ1>,<q2,τ2>,...,<q|q|,τ|q|>},对于数据集进行m份列分割p,查询优化的代价模型如下:
其中右侧是所有查询集合中的查询和阈值进行近似查询的实际代价之和。这里先忽略查询代价的计算过程,在后面的步骤细讲。有了上述公式,可以将它封装成一个最优化问题:给定一个二进制数据集d,一个查询集合q,本实施例目标找到一个列分割方法p,从而使得达到最小的查询代价,即为
列分割最优化问题是一个np-hard问题。
步骤202:初始化列分割。
由于列分割是一个np-hard问题,本实施例分为两个步骤进行讨论:初始化列分割和近似分割算法。对于近似分割来说只能得到一个本地最优解,所以一个好的初始化对于提升近似算法的效果至关重要。
在初始化列分割中,列之间的相关性起到了关键的作用。不同于以往的方法将数据的所有列分割得尽可能的均匀分布,本实施例的方法目标相反的方法。我们观察如果关联性大的数据列放在同一个分割中,近似查询的性能通常会提高。这是因为本实施例的海明阈值分配方法能够在线地优化每一个查询,并且对高倾斜度的数据有更好的效果。当高度关联的数据列被放在一起,更多的错误会在同一个数据分割中被识别,因此本实施例的阈值分配方法会分配一个较大的阈值给这个分割,从而对其他的分割给更小的阈值。换句话说,本实施例把合适的阈值分配给不同的数据分割。如果数据列被均匀分布,所有的分割有着同样的分布,这样的话很难去优化一些倾斜度很高的分割。
本实施例用信息熵去度量数据列之间的关联度,对于一个数据分割pi,本实施例用
根据公式,较小数值的信息熵说明当前的分割有更强的关联性。整个数据的分割方案p的信息熵是所有数据分割的信息熵的累加和,即为:
本实施例的目标是找到一个初始化分割方案p使得h(p)最小化。为了达到这个目标,本实施例用了一个等分割的贪心方法:在最开始p是一个空的分割方案,本实施例贪心地选择数据列,即为如果该数据列对于当前的分割能产生最小的信息熵,它就被放入到该分割中。这个过程持续操作直到其中一个分割的大小达到的上限,即为
步骤203:近似分割算法。
当初始化数据分割得到之后,需要利用查询集合对分割方案进行精炼。这里本实施例利用一种贪心的策略,即为迭代地把当前近似查询效果差距最大的两个数据列进行交换。
在每次迭代中,随机选择两个数据分割中的数据列,进行交换。之后对于当前交换后的数据集用查询集合运行近似查询,计算出代价cworkload。选择cworkload最小的两个数据列进行交换。这个过程重复执行,直到当前计算最小的cworkload比上一次迭代的cworkload大,则停止算法产生最终的数据分割方案。
步骤30:针对新生成的数据进行建立索引结构。索引结构包含两个部分:柱状图和倒排哈希索引。
柱状图的作用是对于当前的数据收集统计信息。对于每个宽度是d的数据分割,枚举所有的二进制数据,即为2d个数据,和d+1个阈值,即为0,1,2,...d。hist(p,t)表示数据集中与d-bit的分割数据p有海明距离为t的数据的个数。
倒排哈希索引是将所有数据分割中的值作为哈希值,记录的id加入到其倒排表中。
步骤40:查询优化。为了利用新型鸽巢原理去处理查询,如果将阈值分配给各个分割是一个关键的问题。
步骤401:为了更好地优化查询阈值分配,本实施例设计一个近似查询的代价模型如下:
cquery_proc(q,t)=csig_gen(q,t)+ccand_gen(q,t)+cverify(q,t)
其中,csig_gen(q,t),ccand_gen(q,t)和cverify(q,t)分别表示签名生成,候选集生成和验证的代价。
签名生成是指查询数据根据海明阈值生成所有可能的待查的哈希值。候选集生成指查询数据生成的待查哈希值去查询索引结构中的倒排表,抽取出相应的记录,去重之后得到候选集合。验证是指对候选集合中的每一条记录,用海明距离函数去和查询计算海明距离数值,对比给定的阈值输出最终的结果。
在实际应用中,签名生成的代价通常远远小于候选集生成和验证的代价,因为签名生成的时间复杂度是被查询的大小和阈值限制住的。所以本实施例在查询优化的过程中可以忽略掉签名生成的影响。
用cn(qi,τi)表示在第i个分割中对于查询和当前分配的阈值产生的候选集合个数。则对于一个查询和它的阈值分配,抽取出来的倒排表的长度之和是
其中caccess是查询倒排表中一个元素的代价,cverify是验证两个向量的海明距离是否小于等于给定阈值的代价。这两个参数都是预先设定的常量。
有了上述公式,可以正式把阈值分配转化为一个最优化问题:给定一个数据集,查询q和阈值τ,找到一个阈值向量t使得近似查询代价最小,即为
步骤402:阈值分配方法。因为caccess,cverify和α都独立于cn(qi,τi),本实施例可以忽略上述公式中的(caccess+α·cverify),而根据
用opt[i,t]记录对于1到i的数据分割以及当前阈值t的最小近似查询代价,则有如下递归公式:
有了上述递推公式,设计一个动态规划算法来实现阈值分配。在初始阶段,初始化第一个分割的代价,即opt[1,-1],...,opt[1,τ]。之后利用上述公式去计算每个opt[i,t]的最小值。这里带负数的阈值-1也被考虑被分配给其他分割。最后,追踪到达opt[m,τ-m+1]的路径,并且得到最终的阈值分配向量。整个动态规划算法的时间复杂度是o(m·(τ+1)2)。
步骤50:从倒排表中抽取候选集合,去重并逐一验证。
当海明阈值分配确定了之后,对于查询的每一个列分割qi和它对应的被分配的阈值t,枚举所有可能的哈希数值,即为
例子:查询数据的一个列分割是001,t=1。枚举所有可能的查询哈希数值,即为001,101,011,000。
当所有的哈希数值枚举出来之后,他们分别去预先建立的倒排索引中查找对应的键值,并抽取出对应的倒排表。当所有的倒排表抽取出来之后,去重并用海明距离公式逐一计算他们与查询的海明距离。如果计算的数值小于或等于给定的阈值,就返回作为其中一个结果。
综上,本发明实施例提供了一系列哈希映射函数,比如simhash,深度神经网络模型等,作为哈希映射函数,对数据库中的数据及查询数据进行哈希映射为二进制向量;提出了一种更普遍的鸽巢原理来获得更紧的过滤条件,并且有着更灵活的阈值分类方法;设计了一种基于普遍鸽巢原理的,高效的在线查询优化方法来分配阈值,使得分配的方案是最优的;设计了一个线下数据列划分方法来解决数据倾斜和维度关联性导致的划分选择性问题;还设计了一个线下数据列划分方法来解决数据倾斜和维度关联性导致的划分选择性问题。
本领域普通技术人员可以理解,上述实施例的各种方法中的全部或部分步骤可以通过指令来完成,或通过指令控制相关的硬件来完成,该指令可以存储于一计算机可读存储介质中,并由处理器进行加载和执行。
为此,本发明实施例提供一种存储介质,其中存储有多条指令,该指令能够被处理器进行加载,以执行本发明实施例所提供的海明空间近似查询方法中的步骤。
其中,该存储介质可以包括:只读存储器(rom,readonlymemory)、随机存取记忆体(ram,randomaccessmemory)、磁盘或光盘等。
以上所述,以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!