基于卷积神经网络的接触网关键部件目标检测方法与流程
本发明涉及接触网自动检测技术领域,具体为基于深度卷积神经网络的电气化铁路接触网关键部件的目标检测方法。
背景技术:
接触网系统作为列车动力来源是电气化铁路系统中最重要的部分之一,其沿线架设,由支柱、支持装置、定位装置以及接触悬挂装置组成,其性能的好坏直接影响着列车的运行安全。接触网本身是一个部件众多的复杂系统,不仅受高速运行的受电弓的冲击与振动,并且常年遭受恶劣的自然天气的考验,所以容易发生故障。然而接触网系统沿线架设无备用,一旦发生故障对铁路的安全运行存在巨大的隐患。因此对接触网悬挂状态进行有效的检测与监测具有极其重要的意义。
现阶段接触网支持与悬挂装置的检测,主要采用人工巡视检测和技术人员查看零部件所在区域图像的方式。这种方法劳动强度大,工作效率低,工作周期长,隐患不易发现,而且不能及时发现故障。为对接触网进行有计划地检测以便及时发现隐患、保证电气化铁路安全运营,中国铁路总公司于2012年7月发布实施了《高速铁路供电安全检测监测系统(6c系统)总体技术规范》。其中接触网悬挂状态检测监测系统(4c)通过安装在检测车上的高速工业相机得到接触网高清图像,以此形成维修建议,指导接触网维修。相对于人工巡线的方式,通过查看图像的方式检测装置故障可大大缩短工作周期。然而,通过高清成像系统获得的接触网关键悬挂图像数量巨大,人工查看易发生误检漏检。因此采用自动化的非接触式手段实现接触网关键部件的自动检测与分类是现阶段急需解决的重要问题。
早期接触网自动化检测手段多采用基于图像处理技术来实现接触网关键部位的目标检测,然而在不同环境下接触网悬挂状态检测监测系统(4c)所采集的照片在图像背景、环境噪声、对比度及曝光度方面都有很大的不同,导致基于单一种类的图像处理技术难以实现多场景下的目标检测,且一种图像处理算法只能定位一种部件,多种部件的定位和分类则需要多种图像处理算法共同协作完成,因此存在计算量大、耗时长、泛化能力差、识别精度低等问题,无法从根本上实现接触网关键部件的自动检测。
随着人工智能浪潮的推进,深度学习方法越来越清晰地浮现在人们的视野中。深度学习方法尤其是卷积神经网络这部分在图像识别与处理方面具有着先天优势,基于卷积神经网络的目标识别算法大都采用较高层神经网络实现端到端的目标检测,相比于人工识图和传统图像处理方法,基于卷积神经网络的目标检测模型具有检测速度快、精度高等优点,能够实现有效且快速的目标检测。
技术实现要素:
针对上述问题,本发明提出了一种基于卷积神经网络的接触网关键部件目标检测方法。利用tensorflow框架平台,结合图像数据增强技术与深度学习中的yolov3目标检测模型方法并加以改进,改进后的目标检测模型能够快速定位高速铁路接触网中的关键部件,实现绝缘子及其支座、旋转双耳、定位线夹等关键部件的多目标分类,减少人工检测的环节,提高检测效率。
为实现上述目的,本发明技术方案如下:
基于卷积神经网络的接触网关键部件目标检测方法,包含以下步骤:
步骤1:图像数据采集:采集接触网高清图像,形成原始图像样本集;
步骤2:图像数据增强:对步骤1中所采集的接触网图像样本进行分类和测试,根据不同情景下所拍摄的接触网图像样本采用不同种类的数据增强方式,如灰度变换、加噪/减噪、剪切、旋转、镜像翻转等单一或组合方式,形成图像增强样本集;
步骤3:制作训练样本集:将步骤1中得到的原始图像样本集与步骤2中得到的图像增强样本集汇总组成图像样本库,并在图像样本库中的提取部分数据作为训练集,在剩余的图像数据中提取部分作为验证集和测试集;训练集和测试集均需人工标注多个目标区域,并作相应分类标签;
步骤4:将训练数据运用到基于卷积神经网络的目标检测算法模型yolov3上,利用训练集对该模型进行图像区域识别和关键目标识别与定位的训练,得到接触网关键部件的目标检测模型;
步骤5:将待检测图像输入训练好的模型中,验证接触网关键部件的目标定位及分类准确度。
进一步说明,步骤3具体步骤如下:
(3.1)将图像大小调整至统一像素值;
(3.2)利用图像标注工具对步骤1和步骤2中接触网图像的关键部件进行标注,键入相应部件类别名称,生成标注文件;
(3.3)制作训练数据集。在完成标注的图像数据中提取部分数据作为训练集,剩余的图像数据作为验证集和测试集;将训练集与验证集中的图像数据与相应的标注文件按顺序编号,用于步骤4中yolov3模型的训练和测试。
进一步说明,步骤4具体步骤如下:
(4.1)搭建yolov3网络模型运行环境;
(4.2)配置加载网络的初始权重文件,根据标签种类个数及训练集图片的数量调整网络参数;针对训练集中标记的接触网关键部件种类较少且标签唯一的特点,将yolov3网络模型中全连接层至输出层的损失函数为归一化指数函数形式,使模型在训练过程中能够快速收敛;训练过程中,参数经由全连接层通过损失函数层得到相应的概率,最后经由交叉熵误差函数得到最后输出,损失函数表示为:
全连接层为1*t的向量,其中,aj表示全连接层输入向量中的第j个值,pj为对应值的概率,l为损失,yj是1*t的标签向量中第j个值;标签向量的t个值,其真实标签对应的位置的值为1,其他值均为0;
(4.3)利用训练集进行yolov3网络模型的训练,得到网络模型一;利用网络模型一对测试集和验证集进行测试,根据识别区域数量及准确度,挑选出没有识别到的图像和交并比低于0.75的图像加以标注,标注时仅标注图像中未识别的区域,并以与标注框的大小相等的尺寸剪裁标注图像,除标注区域外的图像均舍弃,之后采用步骤2中图像增强方式增加此类图像样本数量并整理形成错误集,将该错误集添加到训练集中,建立新训练集。
(4.4)统计新训练集中训练样本的类别标签之比,根据新训练集中样本类别标签不均衡度,在原损失函数基础上加入权重比α×pγ,损失函数变为:
l=-α×pγ×log(1-p)
其中,α和γ均为常数,p为每一类别的标签占总标签的比例,l为损失,每次训练集微调时α需作相应调整,即根据训练集中类别的不均衡度取值,根据训练集类别分布情况,此处γ取值范围可为[1,3]。
(4.5)运用新训练集训练网络模型一,得到网络模型二,利用网络模型二对测试集和验证集进行测试,若准确度未达到目标值则重复上述步骤,直至模型平均定位精度高于0.95。
进一步说明,所述步骤2和(4.3)中图像增强方式所采用的灰度变换具体为:
(1)线性变换:用于增强或减少图像对比度、图像反转等操作,线性变换的函数为:
s=k*r+b其中,r是变换前的灰度值,s是变换后的灰度值,k和b为常数。
(2)对数变换:用于对图像中低灰度细节进行增强,对高灰度进行抑制,对数变换的函数为:
s=clog(1+r)
其中,r是变换前的灰度值,s是变换后的灰度值,c为常数。
进一步说明,步骤3中所述人工标注的多个目标区域具体包括:平腕臂绝缘子、斜腕臂绝缘子、腕臂上底座、腕臂下底座、定位器线夹、套管双耳等。
本发明的效果是:基于深度学习中目标检测模型yolov3完成了接触网关键部件目标检测。通过利用图像处理中的方法用于图像数据增强,扩充了用于训练和测试的图像样本,从而弥补图像数据不足等问题,也由此丰富了训练样本的多样性,加强了训练后模型的泛化能力;此外针对模型运用场景,修改了模型内部的部分参数,引入了新的损失函数,使其具有更好的检测精度和泛化性能。本发明中提到的目标检测方法相比人工检测和传统图像处理方法,具有检测速度快、精度高等优点,能够实现有效且快速的目标检测,从而大大减少了人工识别高铁接触网关键部件故障的工作量。
附图说明
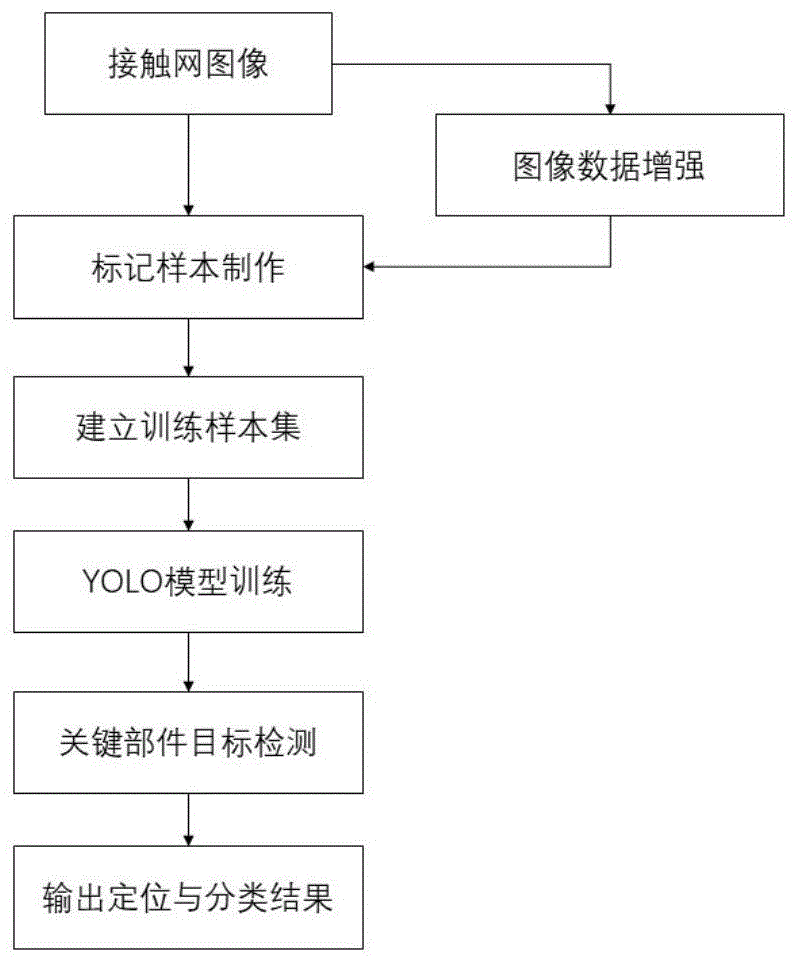
图1为本发明接触网关键部件目标检测方法流程图;
图2为待标记检测的接触网全局图;
图3为接触网关键部件标记示例图;
图4为训练过程中avgloss随迭代次数增加的变化情况图;
图5为本发明接触网关键部件目标定位与分类效果图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步详细说明。
在本实例中,如图1所示,基于卷积神经网络的接触网关键部件目标检测方法,包含以下步骤:
步骤1:图像数据采集:采集由接触网悬挂状态检测监测系统(4c)中的高速线阵ccd相机所拍摄的如图2所示接触网高清图像,形成原始图像样本集,本实施例中原始图像样本集为4000张;
步骤2:图像数据增强:对步骤1中所采集的接触网图像样本进行分类和测试,根据不同情景下所拍摄的接触网图像样本采用不同种类的数据增强方式,如灰度变换、加噪/减噪、剪切、旋转、镜像翻转等单一或组合方式,形成图像增强样本集;经图像数据增强后得到的图像增强样本集共8000张;
步骤2中所采用的灰度变换、加噪/减噪、剪切、旋转、镜像翻转等操作均可使用opencv库中函数实现,采取的灰度变换主要为线性变换和对数变换。具体为:
(1)线性变换:用于增强或减少图像对比度、图像反转等操作,线性变换的函数为:
s=k*r+b
其中,r是变换前的灰度值,s是变换后的灰度值,k和b为常数。
(2)对数变换:用于对图像中低灰度细节进行增强,对高灰度进行抑制,对数变换的函数为:
s=clog(1+r)
其中,r是变换前的灰度值,s是变换后的灰度值,c为常数。
步骤3:建立图像样本库:将步骤1中得到的原始图像样本集与步骤2中得到的图像增强样本集汇总整合成图像样本库,并将图像样本库中的图像数据提取6000张作为训练集,并从剩余的图像数据中各提取50%作为验证集和测试集(各1000张);训练集和测试集均需人工标注多个目标区域,并作相应分类标签;
步骤3制作训练集、测试集和验证集的步骤如下:
(3.1)将图像大小由6600×4400统一调整至448×448像素;
(3.2)如图3所示,利用图像标注工具labelimg对训练样本集和验证样本集中的接触网图像关键部件进行标注,并键入相应部件类别名称;本实施例中选定了接触网中几种较为关键的部件进行标注,分别是平腕臂绝缘子、斜腕臂绝缘子、腕臂上底座、腕臂下底座、定位器线夹、套管双耳等。
(3.3)制作训练数据集。在完成标注的图像数据中提取部分数据作为训练集,剩余的图像数据作为验证集和测试集;将训练集与验证集中的图像数据与相应的标注文件按顺序编号,用于下个步骤中yolov3模型的训练和测试。
步骤4:将训练数据运用到基于卷积神经网络的目标检测算法模型yolov3上,利用训练集对该模型进行图像区域识别和关键目标识别与定位的训练,得到接触网关键部件的目标检测模型;
步骤4具体步骤如下:
(4.1)搭建yolov3网络模型运行环境:利用tensorflow框架搭建yolov3,在python3.5和opencv3.3.0的环境下,以keras为前端,tensorflow为后端搭建yolov3网络模型。
(4.2)配置加载网络的初始权重文件,根据标签种类个数及训练集图片的数量调整网络参数;针对训练集中标记的接触网关键部件种类较少且标签唯一的特点,修改yolov3网络模型中全连接层至输出层的损失函数为归一化指数函数形式,使模型在训练过程中能够快速收敛。训练过程中,参数经由全连接层通过损失函数层得到相应的概率,最后经由交叉熵误差函数得到最后输出。损失函数表示为:
全连接层为1*t的向量,其中,aj表示全连接层输入向量中的第j个值,pj为对应值的概率,l为损失,yj是1*t的标签向量中第j个值;标签向量的t个值,其真实标签对应的位置的值为1,其他值均为0;
(4.3)利用训练集对yolov3模型进行训练,得到网络模型一;利用网络模型一对测试集和验证集进行测试,根据识别区域数量及准确度,挑选出没有识别到的图像和交并比低于70%的图像加以标注,标注时仅标注图像中未识别的区域,并以略大于标注框的大小剪裁标注图像,除标注区域外的图像均舍弃,之后采用步骤2中图像增强方式增加此类图像样本数量并整理形成错误集,将该错误集添加到训练集中,建立新训练集;
(4.4)统计新训练集中训练样本的类别标签之比,根据新训练集中样本类别标签不均衡度,在原损失函数基础上加入权重比α×pγ,损失函数变为:
l=-α×pγ×log(1-p)
其中,α和γ均为常数,p为每一类别的标签占总标签的比例,l为损失,每次训练集微调时α需作相应调整,即根据训练集中类别的不均衡度取值。根据训练集类别分布情况,此处γ取值范围为[1,3],本实施例中取γ=2时,能使定位精度获得一定的提升。损失函数求导得:
(4.5)运用新训练集训练网络模型一,得到网络模型二,利用网络模型二对测试集和验证集进行测试,若准确度未达到目标值则重复上述步骤,直至模型定位精度高于目标值。
训练时使用的硬件参数为cpu:intelxeone5-2650×2,gpu:nvidiageforcegtx10808gb,ram:16gb。软件环境为:python3.5,opencv3.3.0,cuda9.1,cudnn7.0。训练时主要考虑平均损失(avgloss)和iou(intersectionoverunion)这两项数值,当avgloss越接近于0且iou越接近于1时,训练效果就越好。
训练过程中每经过一定的迭代次数时会产生一个权值文件,这些权值文件中保存了当前网络训练产生的所有参数数据,训练结束后选择一个权值文件用于接触网的关键部位的目标检测。为了避免存在标记错误或者过拟合的情况,选择权值文件时需要做多次测试,以达到快速目标定位效果。如图4所示,本实施例中共计迭代了30000次,avgloss降至0.3938,平均iou在98%以上。
步骤5:将待检测图像输入训练好的模型中,验证接触网关键部件的目标定位及分类准确度。最终得到的接触网关键部件目标定位与分类效果图如图5所示。本实施例中所标记的六种关键部件(平腕臂绝缘子、斜腕臂绝缘子、腕臂上底座、腕臂下底座、定位器线夹、套管双耳)均在示例图中被检测出。
实验结果表明,利用本方法对接触网原始图像中关键部件的平均识别率达到了98%以上,跟据硬件配置的不同,对于每张图像中所有部件的识别与定位时间为0.6秒至1.5秒,平均每个部件检测耗时为0.1秒至0.3秒。由此可见本方法对于接触网中关键部件目标检测精度与检测速度相较人工方法有较大提升。
上述实施例为本发明的一种实施方式,但本发明的实施方式并不限定于此,从事该领域的技术人员在未背离本发明精神和原则下所做的任何组合、替换、修改、改进,均包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!